【Linux】文件系统与inode、软硬链接
目录
一、磁盘结构
二、文件系统
2.1 文件系统的区域划分
2.2 文件系统分区介绍
2.3 文件名与inode
三、软硬链接
3.1 软链接
3.2 硬链接
一、磁盘结构
理解文件系统前首先我们要来先了解一下磁盘结构。
接下来我们看看以水平、垂直角度来看看磁盘结构,并将其区域进行划分。
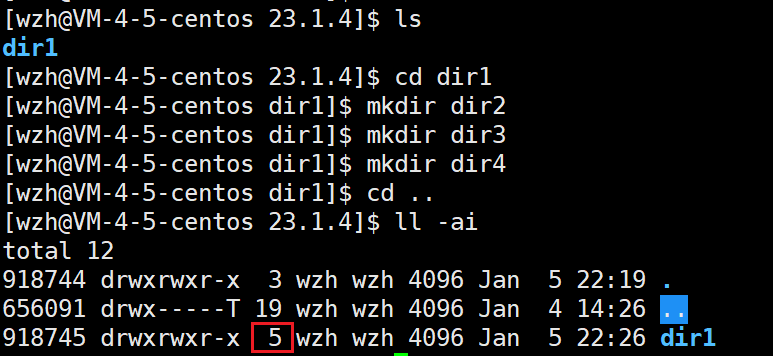
磁盘的垂直分布 (此图最上面的一面和最下面的一面无磁头,则不存储数据):
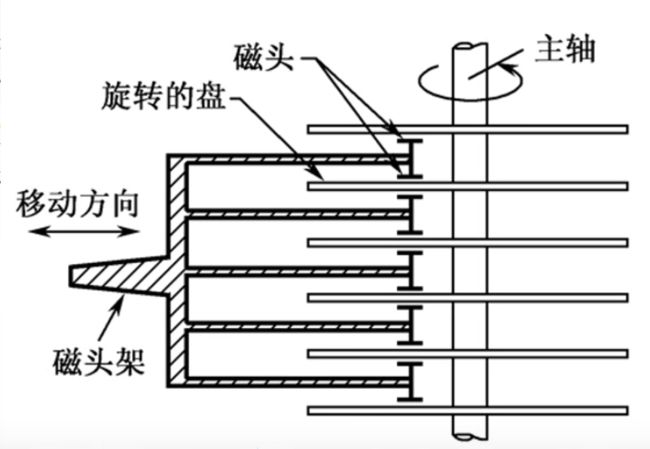
此时我们来看看磁盘区域的划分以及其概念:
- 磁头数:磁头就是在盘片上进行读/写的设备,有几个磁头就表示该磁盘有几个记录面用于存储数据。
- 柱面数:因为磁盘是垂直叠加盘片的,磁盘上的磁道可以看作垂直的圆柱,磁道即半径逐渐缩小的圆,柱面数表示该磁盘一个盘片上有几圈磁道。
- 扇区数:扇区则是将一个盘片进行等比例切分成扇形区域,表示每一条磁道上的扇区数。
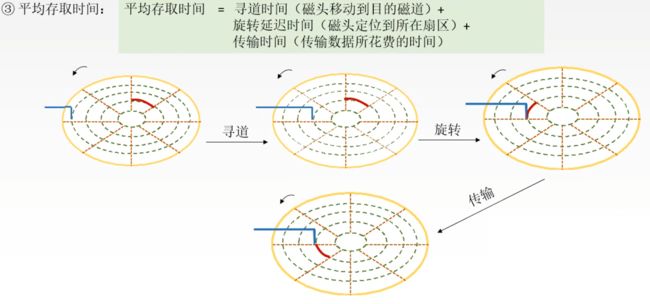
所以当我们想读取到一块扇区中的数据,我们的步骤是
- 先寻找在哪个面上(对应是哪一个磁头)
- 在该面哪一圈磁道上
- 位于该磁道的哪一块扇区中
- 然后进行寻道、旋转、读取(传输)
二、文件系统
2.1 文件系统的区域划分
以上是我们在磁盘上进行物理寻址的过程,但是对于操作系统而已,其内部还要进行逻辑寻址的过程。
操作系统将磁盘抽象为数组的形式: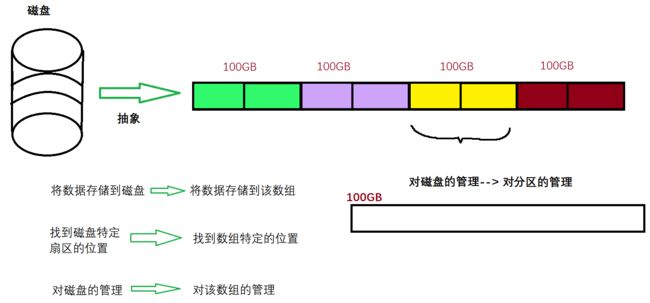
此时系统对数据管理方式就会从物理管理方式转变为逻辑管理方式
- 将数据存储到磁盘----> 将数据存储到该数组
- 找到磁盘特定扇区的位置----> 找到数组特定的位置
- 对磁盘的管理----> 对该数组的管理
但是100GB的空间仍然不好管理,此时操作系统再进行划分。如下:
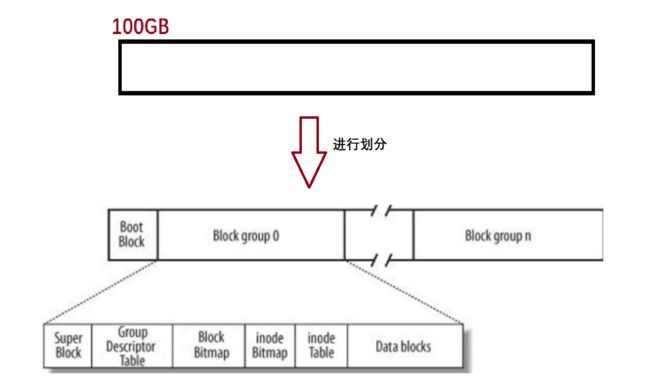
2.2 文件系统分区介绍
提前须知:
虽然磁盘的基本单位是扇区(512字节),但操作系统(文件系统)和磁盘进行IO的基本单位是:4KB(8*512byte),此4KB被称为block大小,所以磁盘被称为块设备。
为什么不用512字节为单位作为IO的基本单位呢?
1.因为512太小了,有可能会导致多次IO,进而导致效率的降低!
2.硬件与软件的IO访问大小不同,可以将硬件和软件(OS)之间的关系解耦合。比如磁盘的规格后序会不断变化,但是不影响系统的IO访问大小。
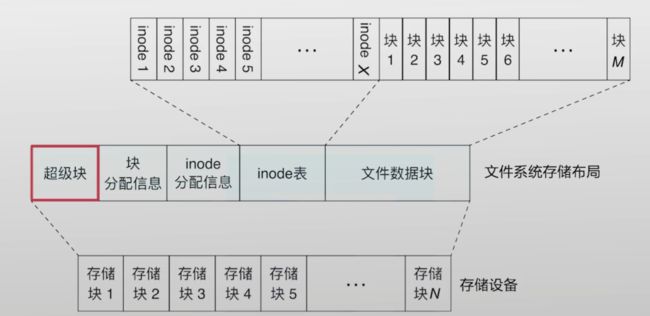
各种分区的作用:
Super Block:文件系统的整体的属性信息,整个分区,有多少个快组,哪些快组已经存满,哪些数据块可以被写,inode的使用数量、未使用的数量。
Data blocks:多个4KB大小的集合,保存的都是特定文件的内容。
inode:inode 是一个一般大小为128字节的空间,用来保存对应文件的属性。
一个文件对应一个inode。
inode Table:该块组内,所有文件的inode空间的集合,可以理解为一个inode结构体数组。其中每一个inode,都有下标进行映射为inode编号。
一般而言,一个文件,一个inode,有一个inode编号。
Inode Bitmap:假设有1w+个inode节点,则有1w+个比特位,比特位和特定的inode是一一对应的,其后bitmap中比特位为1,代表该inode被占用,反之表示可用。
Block Bitmap:假设该分组中有1w+个blocks,则有10000+个比特位,
比特位和特定的block是一一对应的,其中比特位为1,代表block被占用,反之表示可用。
Group Descriptor Table:快组描述符,用来描述这个快组有多大、使用了多少个inode、使用了多少block。
分区中有了这些描述信息,我们能让一个文件的信息可追溯,可管理!
格式化:
此时将块组分割成为上面的内容,并且写入相关的管理数据,每一个块组都进行这样的操作,此时整个分区就被写入至了文件系统,这种行为就叫做格式化。
在格式化后可用磁盘空间会变少一些,原因在于:
一部分磁盘区域被inode表等元数据所占用了,所以留给文件数据的磁盘块就变少了。
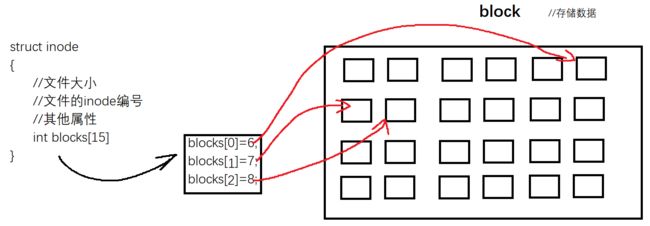
有了一个文件的inode编号,我们就可以找到文件。 其实inode本质就是一个结构体,其中记录了对应存储文件数据的块区编号。形式图如下:
如果对inode想有更深层次的了解,可以看以下视频进行了解:
- linux中的iNode介绍
- 基于inode的文件系统:如何从文件名找到磁盘块
2.3 文件名与inode
既然inode的一个文件的唯一标识,那为什么不能使用inode号作为文件号?
- inode号难记,我们不可能将每一个文件的inode号记录下来。
- inode号是与文件系统相关的,一个文件从一个磁盘复制到另一个磁盘,inode号就变了,也可能导致文件失去唯一标识。
所以,在windows与linux中,文件名是一个我们可以自由改变的字符串,那字符串是怎么和文件绑定的呢?
答案:通过目录
其实在操作系统中,目录也是一种文件。
文件系统中的目录记录了文件名到inode号之间的映射,目录的结构就像一个大数组,每一项都包含了一个字符串和inode号。
目录文件在其 inode 中增加了一个类型字段,目录文件和普通文件各自具有不同的类型。
目录也可以拥有字符串的名字,这个名字记录在上一级目录中,所以目录具有了层次,形成了一颗目录树,从而更加方便人们的使用,这个目录数的根,就是我们熟悉的根目录: "/"。
举例:操作系统是如何查找到 "/bin/ls" 这个文件的呢?
- 文件系统首先找到根目录的inode,位置通常在inode表的第一个。
- 找到根目录inode中保存的根目录数据的磁盘块ID。
- 根据磁盘块ID读取磁盘块,搜索 "bin" 字符串,并找到后面对应的inode号
- 根据bin的inode号找到bin中保存的数据磁盘块ID。(重复执行2-4步)
- 然后在磁盘块id中找到 "ls" 字符串,取到其中的inode号,最终定位到保存ls文件数据的所有磁盘块。
1.创建文件,系统做了什么?
在特定分组中,分配一个未被使用的inode,再建立 inode Table与inode BitMap的映射关系,再将inode与文件名的映射关系写入到所在目录中,如果向文件中写入内容,则往inode指向的block中写入数据。
2. 创建文件,系统做了什么
删除文件并不是真的删除了文件,而是将inode BitMap中对应位置进行清零,标识该inode无效,让下一次写入的文件进行覆盖。
3. 查看文件,系统做了什么
首先从目录中取出文件名对应的inode编号,从inode中的block块数组读出指向block块中的数据。
三、软硬链接
在ls命令中,添加-i选项,可以打印文件对应的inode编号。

我们先来看看软硬链接的命令("ln")以及选项,然后再来解释。
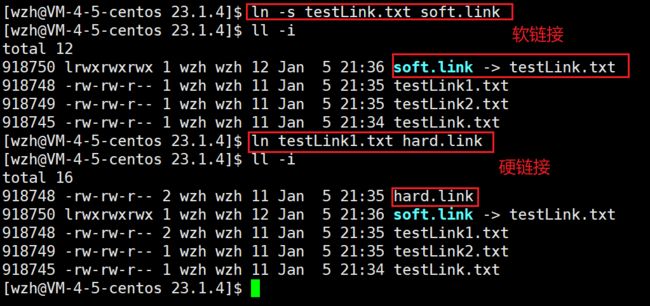
这时我们来观察其变化。
首先是软链接,我们进行软链接之后,新建的软链接具有独立的inode,硬链接数的值没有变化。
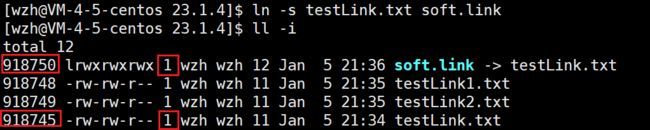
然后我们观察硬链接,新建的硬链接 inode与被链接的文件inode编号不同,并且引用计数的值发生了变化。
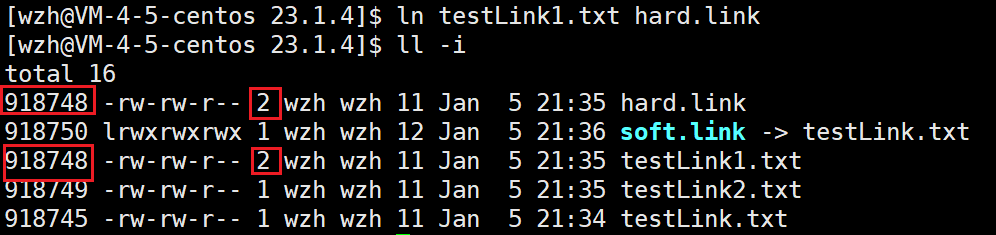
软硬连接的本质区别:有没有独立的inode。
所以:软链接是一个独立的文件;硬链接不是一个独立的文件。
3.1 软链接
软链接的特性:软链接的文件内容,是指向文件的对应路径。
软链接的作用:相当于windows中的快捷方式,可以跳转执行目标文件。
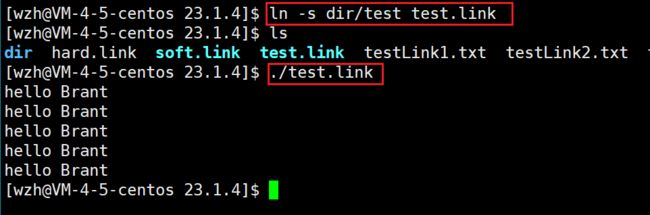
接下来我们来创建并使用软链接。以下是不使用软链接执行test文件:
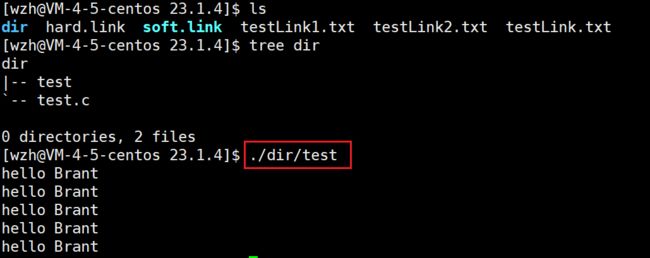
创建软链接,并使用软链接执行该文件:
3.2 硬链接
创建硬链接,不是真正的创建文件,因为其并没有独立的inode。
硬链接的作用:就是在指定目录下,建立了文件名与指定inode的映射关系,可理解为起别名。
硬链接的特性:
inode是唯一的,而文件名并不是唯一的,其关系是1:n。所以我们怎么知道有多少文件名与inode是相关的?
此时便引出了引用计数算法(类似于C++智能指针),当删除一个文件时,并不是把这个文件的inode直接删除,而是将这个文件的inode中的引用计数器 --。当引用计数为0时,这个文件才算是真正的删除。
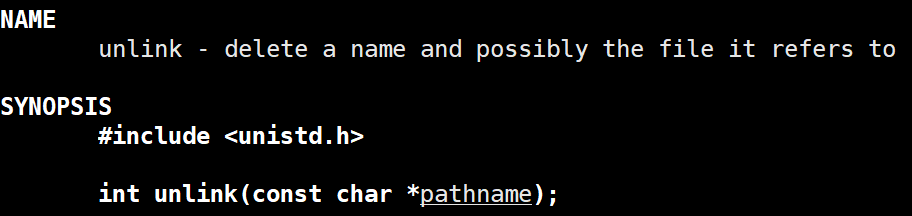
所以系统中除了rm命令,还可以使用unlink来解除关联,从而删除文件,这个命令还是系统调用接口,可以在我们C语言中进行调用。
那这个引用计数(硬链接数)有什么用呢?我们接下来往下看:
为什么新建的目录,其硬链接数是2呢?
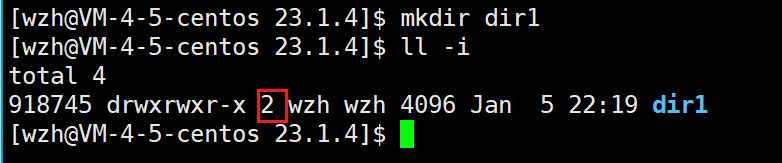
首先,dir1这个文件名与inode是一组映射关系,然后其内部有一个".",也表示dir1,这个点也是一个文件名,所以这也是一组映射关系。
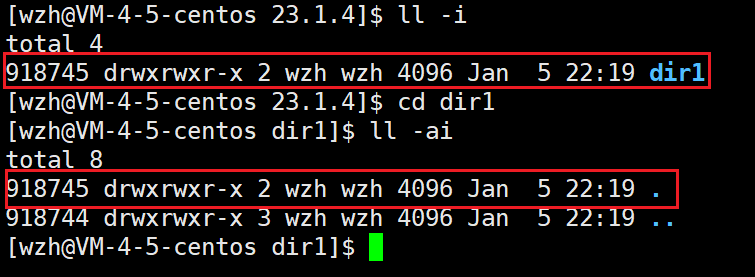
在了解了硬链接数之后,我们就可以在不进入目录的情况下,就知道该目录下有几个目录了(n-2)
因为子目录下有".."指向父目录,有几个子目录就有几组映射关系。