Vivado界面配置选项含义解析
目录
一、前言
二、Project Settings
2.1 基础设置
2.1.1 General
2.1.2 Simulation
2.2 综合与布局布线
2.2.1 Synthesis
2.2.2 Implementation
三、参考资料
一、前言
在使用Vivado进行工程设置时,Settings界面中可进行各个阶段的配置设置,清楚这些配置项的含义有助于我们设计出符合要求的工程,本文将针对这些选项进行基础的解释,其中包含了部分个人理解,如有不到之处,欢迎指出,使用的Vivado 2019.1 。
二、Project Settings
下面将根据流程以及使用频率分3部分来介绍。第一部分包括General,Simulation,Elaboration。第二部分为Synthesis和Implementation,这一部分是最重要的,将重点介绍。第三部分是其他配置选项。
2.1 基础设置
2.1.1 General
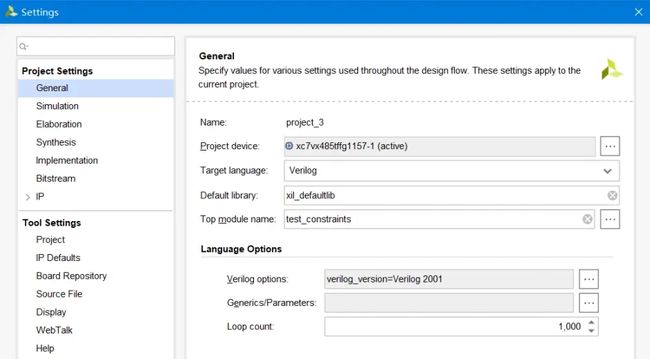
General设置界面如下图,Project device设置器件类型,Target language设置编译语言为Verilog或VHD,Top module name在工程存在多模块时设置顶层入口模块,Language Options中Loop count为设置最大循环次数,默认1000,即在工程中设置类似for循环时,最大循环数为1000。
2.1.2 Simulation
Simulation主要是配置仿真环境,可使用vivado 自带的仿真工具,也可配置为modelsim仿真,相关设置可参考文章:https://blog.csdn.net/zyp626/article/details/128357763?spm=1001.2014.3001.5501
2.2 综合与布局布线
2.2.1 Synthesis
Synthesis的作用是将工程文件转换成网表,网表主要包括单元Cell,引脚pin,端口Port,网线Net。综合阶段的配置选项界面分为4部分:Synthesis,Constraints,Report Options,Options。
Constraints:在工程有多个约束集constraint set时可在Constraints中设置需要的约束集。
Report Options:设置report的策略,使用默认的即可
Options:包含了很多综合相关的策略

Write incremental Synthesis:勾选后采用增量综合,默认不勾选
Strategy:设置综合的总体策略,通过算法,按照面积,性能,运行时间等不同优先级有以下8中策略,也可使用User Defined Strategies用户自己定义策略

Synth Design设置如下:

tcl.pre:用户可自己添加或创建综合前的tcl文件
tcl.post:用户可自己添加或创建综合后的tcl文件
flatten_hierarchy:设置为none时,综合工具不会将设计全部展开,保留了和设计层次相同的属性关系,工具优化最少,消耗的资源也多;设置为Full时,则全部展开,综合后只有顶层模块,子模块的层次结构看不出,优化最多,消耗资源少,设置为rebuilt,则综合工具会适当展开,中途会存在一些优化,但层次结构和RTL会存在些差异。
gated_clock_conversion:控制综合工具是否对门控时钟逻辑进行转换成触发器的使能
bufg:设置使用的bufg数目
fanout:设置进行逻辑复制之前的最大扇出值,只对数据信号的扇出有效,对复位,置位,时钟信号的扇出不起作用
directive:指定综合优化策略,有8种策略,优化的目标主要有运行时间,面积,BRAM,DSP使用等。

retiming:重定时功能,勾选后启用,启用后可通过在组合门或LUT之间移动寄存器进行时序优化。
fsm_extraction:设置状态机的编码方式,设置为off时,状态机将通过逻辑实现,设置为auto时,会自动选择最佳的编码方式。

keep_equivalent_registers:设置是否保留相同逻辑输入(时钟端口和数据端口)的寄存器,为off则不保留,进行合并。
resource_sharing:实现对算术运算的资源共享,只有加法和乘法资源,可设置为auto,off,on。设置为auto时由软件根据时序自动选择是否进行资源共享。
control_set_opt_threshold:触发器的控制集门限设置,可以降低控制集的个数,控制集由时钟信号,复位信号,置位信号,使能信号组成,触发器只有控制中的信号都相同时才能放置在同一个Slice中,优化之后需要多占用LUT资源。同时,control_set_opt_threshold的值也是控制信号的扇出个数。通常,当设计的控制集大于芯片控制集的15%时,就必须进行优化降低控制集数目。
no_lc:控制综合是否进行LUT组合,主要针对两个LUT的输入端口并集数小于等于5时可合并到一个LUT6来实现,该操作可节省面积资源,但可能导致布线拥塞或时序变差。
no_srlextract:勾选后表示阻止综合工具用LUT来实现移位寄存器。
shreg_min_size:设置移位寄存器的最小长度,默认为3,当移位寄存器的长度小于等于设置值时,将用触发器级联来实现,大于设置值时,用触发器和LUT来实现,相比只用触发器来实现时,使用LUT可以节省触发器资源,但LUT的时延更大,时序效果差一些,优先级不如no_srlextract。

max_bram:设计中允许使用的BRAM最大数量,默认值-1为不限制使用数量,综合工具可使用所有BRAM。
max_uram:设计中允许使用的URAM最大数量,默认值-1为不限制使用数量,综合工具可使用所有URAM。
max_dsp:设计中允许使用的DSP最大数量,默认值-1为不限制使用数量,综合工具可使用所有DSP。
max_bram_cascade_height:设计中允许BRAM级联的最大长度,默认值-1为不限制级联长度。
max_uram_cascade_height:设计中允许URAM级联的最大长度,默认值-1为不限制级联长度。
cascade_dsp:控制dsp输出和的实现方式,有auto,tree,force三种方式,auto为使用块内置加法器实现,

assert:断言,如果遇到严重错误时将停止进一步的综合操作,有告警则打印告警信息。
More Options:设置一些组合配置,如输入-max_bram 2 -max_dsp 3即同时设置两个选项。
2.2.2 Implementation
实现是将逻辑网表映射到赛灵思器件上的过程,包含了逻辑优化,逻辑单元布局,布线 3个部分。
实现过程中的配置选项分为Constraints,Report Options,Options三个部分。

Constraints:设置实现过程中使用的约束集
Report Options:设置报告策略,可设置的策略有下图5种

Incremental implementation:实现的方式采用增量的形式
Strategy:设置实现的策略,侧重点有性能,面积,布线拥塞,时间等
Description:针对Strategy的选项进行说明
Design Initialization
tcl.pre:设计初始化时添加或创建实现前的tcl文件
tcl.post:设计初始化时添加或创建实现后的tcl文件
2.2.2.1 Opt Design
is_enable:勾选后可选择性的运行
verbose : 控制是否查看所有的执行的逻辑优化

directive :

Explore: 运行多通道优化
ExploreArea:运行多通道优化,着重减少组合逻辑
AddRemap: 运行默认的逻辑优化流程,包括LUT重映射来减少逻辑级数
ExploreSequentialArea:运行多通道优化,着重减少寄存器和相关联的组合逻辑
RuntimeOptimized:运行最少通道优化,用性能来换取更少的运行时间
NoBramPowerOpt:运行所有除了块RAM功率优化外的其他优化
ExploreWithRemap:相比Explore策略少了重映射优化
Default:使用默认的设置
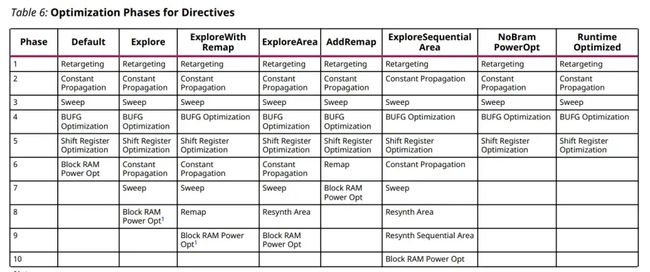
各策略具体的通道优化如下表
2.2.2.2 Place Design
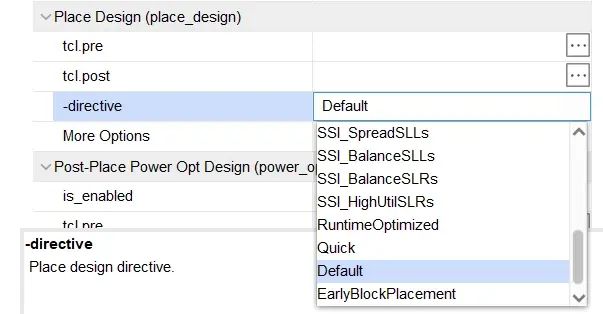
Explore:侧重详细布局和后布局阶段优化。
WLDrivenBlockPlacement:根据线长布局RAM和DSP块,取代以时序来布局。
EarlyBlockPlacement:根据时序来布局RAM和DSP块,在布局流程的早期确定位置。
ExtraNetDelay_high:增加高扇出和长线的时延估算,可以改善关键路径的时序,但可能由于过于理想的估算时延导致布线阶段时序违例,保守估算等级分为高低两级,ExtraNetDelay_high采用最高等级
ExtraNetDelay_low:同ExtraNetDelay_high,区别才用最低等级。
SSI_SpreadLogic_high:将逻辑分散到SSI 上来避免产生拥塞区域,支持高低两个等级,采用高等级,分散程度高
SSI_SpreadLogic_low:将逻辑分散到SSI 上来避免产生拥塞区域,支持高低两个等级,采用低等级,分散程度低
AltSpreadLogic_high:将逻辑分散到器件来避免产生拥塞区域,支持三个等级:高,中,低
AltSpreadLogic_medium:同上,区别为采用中等级的分散程度
AltSpreadLogic_low: 同上,采用低等级的分散程度
ExtraPostPlacementOpt:优化主要在后布局阶段
ExtraTimingOpt:在布局后期使用一组算法以时序为主进行布局
SSI_SpreadSLLs:局部通过SLRs并且为高连接性的区域分配额外的面积
SSI_BalanceSLRs:局部通过SLRs来平衡SLRs的数目
SSI_HighUtilSLRs:在每一个SLR中强制布局器将逻辑布局更紧凑
RuntimeOptimized:用更高的性能换取更快的运行时间
Quick:对于一个合理的设计,不考虑时序,性能,只保证运行时间
Default:使用默认设置
2.2.2.3 Route Design

Explore:允许布线器在初始化的布线中寻找不同的关键路径布局
AggressiveExplore:在保持最初的时序允许下,让布线器进行更深入地查找关键路径
NoTimingRelaxation:不运行布线器牺牲时序来完成布线
MoreGlobalIterations:在各个阶段都是用详细的时序分析,运行更多的全局迭代来提升时序
HigherDelayCost:调整布线器的内部函数来换取更好的性能
RuntimeOptimized:运行最少的迭代,用性能换取运行时间
AlternateCLBRouting:用更多的布线算法来解决布线拥塞的问题
Quick:最快的编译时间,不考虑时序,性能
Default:运行默认的布线设置
三、参考资料
1、书籍《基于Xilinx Vivado的数字逻辑实验教程》
2、官网文档《ug904-vivado-implementation-en-us-2022.2.pdf》