R语言apply函数族
R语言apply函数族
- apply函数
- lapply函数
- sapply函数
- vapply函数
- mapply函数
apply函数
现有数据如下,请求出每一行的最大值,和每一列的最小值
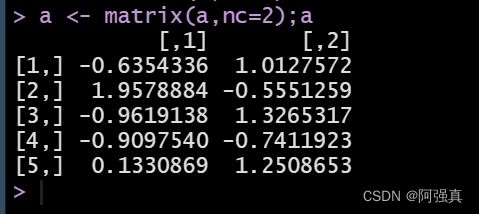
每一行的最大值
apply(a, 1, max)#a是数据,1代表行,max求最大值

每一列的最小值
apply(a, 2, min)

lapply函数
lapply( )不仅适用于向量,也适用于列表。假设我们有一份学生列表:
students <- list( a1 = list(name = "James",
age = 25, gender = "M",
interest = c("reading",
"writing")),
a2 = list(name = "Jenny", age = 23,
gender = "F",
interest = c("cooking")),
a3 = list(name = "David", age = 24,
gender = "M",
interest = c("running", "basketball")))
students
现在,我们想创建一个字符向量,其中每个元素都具有如下形式:
James, 25 year-old man, loves reading, writing.
函数 sprintf( )通过将占位符(例如:%s 对应字符串,%d 对应整数)替换为相应的输入参数来格式化文本。举个例子:
sprintf("Hello, %s! Your number is %d.", "Tom", 3)
输出结果:
[1] “Hello, Tom! Your number is 3.”
返回到我们的问题上来,每次迭代都是作用在列表 students上,并且是相互独立的。换句话说,对 James 的相关操作与 Jenny 无关,以此类推。所以,我们可以使用 lapply( )执行这项工作:
lapply(students, function(s) {
type <- switch(s$gender, "M" = "man", "F" = "woman")
interest <- paste(s$interest, collapse = ", ")
sprintf("%s, %d year-old %s, loves %s.", s$name, s$age, type, interest)})

sapply函数
列表并非总是存储结果的最佳容器。有时,我们希望将结果放在一个向量或者矩阵中。
sapply( )函数可以根据结果的结构将其合理简化。 假设,我们将平方运算应用到1:10的每个元素上。如果使用 lapply( ),返回的结果就是一个包含平方数的列表。实际上,结果列表的所有成分都是一个单值数值向量,所以列表形式的结果就显得笨重而冗长。因此,我们可能希望以向量形式返回同样的结果:
a <- (1:10)
sapply(a,function(i) i^2)
sapply(a,function(i) c(i,i^2)
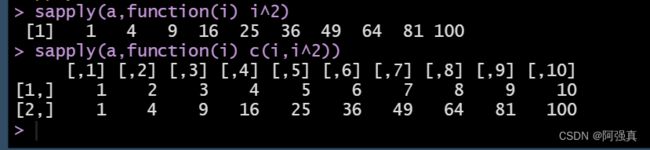
第二个和rbind的作用是一样的

vapply函数



mapply函数


本文参考了r语言编程指南