深度强化学习笔记——基本方法分类与一般思路
概要
本文梳理了一下台大李宏毅老师的深度强化学习系列课程内容。该课程主要是对无模型深度强化学习方法的一些大致介绍,将其分为大致三类:基于值函数的、基于梯度的方法、actor-critic的方法。(其他方法还有模仿学习imitation learning与逆强化学习inverse reinforcement learning)

分类方法可以见下图:

本文对三大类方法的基本思路进行阐述,为了写作的方便,文中的图大部分来自课件中的原图。有任何不准确的地方望指正!
1. 基于梯度的方法(Policy-based)
1.1 一般思路
基于梯度的方法可以分为三个步骤:
a. 将神经网络作为actor:
在强化学习中,策略就是从状态到动作的一个映射(确定性策略 a = π ( s ) a=\pi(s) a=π(s))或者是动作的概率分布(随机策略 π ( a ∣ s ) \pi(a|s) π(a∣s)),在深度强化学习中,该映射是通过一个神经网络模型来获取的,该网络的输入是状态(比如在游戏中的某一帧或多帧游戏画面,输出是动作的概率分布)
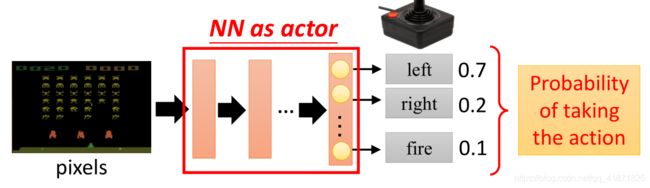
b. 设置损失函数
在深度学习中,神经网络模型的参数更新必须基于某个“标准”,即损失函数的确定,常见的损失函数有交叉熵函数或者均方误差函数等。深度强化学习中的损失函数是多个episodes所获得收益的期望值,并在样本无穷多的假设下,一般用均值来估计该期望值。公式如下:
R ˉ θ = ∑ τ R ( τ ) P ( τ ∣ θ ) ≈ 1 N ∑ n = 1 N R ( τ n ) \bar{R}_{\theta}=\sum_{\tau}R(\tau)P(\tau|\theta)\approx\frac{1}{N}\sum_{n=1}^N R(\tau^n) Rˉθ=τ∑R(τ)P(τ∣θ)≈N1n=1∑NR(τn)
其中, τ = { s 1 , a 1 , r 2 , s 2 , a 2 , r 3 , … , s T , a T , r T + 1 } \tau=\{s_1,a_1,r_2,s_2,a_2,r_3, \dots, s_T,a_T, r_{T+1}\} τ={s1,a1,r2,s2,a2,r3,…,sT,aT,rT+1}代表一个episode产生的轨迹(Trajectory); T T T代表的是到达终止状态的时刻(或者是step); R ( τ ) = ∑ t = 1 T r t R(\tau)=\sum_{t=1}^Tr_t R(τ)=∑t=1Trt代表每一个episode所得到的所有受益之和(不考虑折扣因素);而 P ( τ ∣ θ ) P(\tau|\theta) P(τ∣θ)代表着在给定参数为 θ \theta θ的actor的前提下,生成某一个episode所产生的概率大小,这个值一般是很难准确获取的,所以要通过采样的方法对其进行估计。这里的 N N N 代表的是trajectory的数量或者说是采样的次数,直观来说就是每次智能体与环境交互产生的结果,总共交互 N N N 次,样本也就是可以表达为 { τ 1 , τ 2 , … , τ N } \{\tau^1, \tau^2, \dots, \tau^N\} {τ1,τ2,…,τN}。
c. 根据损失函数更新参数
由于强化学习的基本假设就是最大化智能体的收益,所以基于上一步损失函数就可以用梯度上升(Gradient Ascent)算法进行损失函数的优化,最优的参数可以表示为:
θ ∗ = arg max θ R ˉ θ \theta^*=\argmax_{\theta} \bar{R}_{\theta} θ∗=θargmaxRˉθ
这里先不用其估计值,而用其定义式: R ˉ θ = ∑ τ R ( τ ) P ( τ ∣ θ ) \bar{R}_{\theta}=\sum_{\tau}R(\tau)P(\tau|\theta) Rˉθ=∑τR(τ)P(τ∣θ)。
而梯度上升算法的基本形式是:
θ n e w ← θ o l d + η ∇ R ˉ θ \theta^{new}\leftarrow \theta^{old}+\eta\nabla\bar{R}_{\theta} θnew←θold+η∇Rˉθ
下一步就是如何求具体的 ∇ R ˉ θ \nabla\bar{R}_{\theta} ∇Rˉθ的值:
∇ R ˉ θ = ∑ τ R ( τ ) ∇ P ( τ ∣ θ ) = ∑ τ R ( τ ) P ( τ ∣ θ ) ∇ log P ( τ ∣ θ ) ≈ 1 N ∑ n = 1 N R ( τ n ) ∇ log P ( τ n ∣ θ ) \nabla\bar{R}_{\theta}=\sum_{\tau}R(\tau)\nabla P(\tau|\theta)=\sum_{\tau}R(\tau)P(\tau|\theta)\nabla \log P(\tau|\theta)\\\ \approx\frac{1}{N}\sum_{n=1}^NR(\tau^n)\nabla \log P(\tau^n|\theta) ∇Rˉθ=τ∑R(τ)∇P(τ∣θ)=τ∑R(τ)P(τ∣θ)∇logP(τ∣θ) ≈N1n=1∑NR(τn)∇logP(τn∣θ)
接下来是如何计算 P ( τ ∣ θ ) P(\tau|\theta) P(τ∣θ) 和 ∇ log P ( τ ∣ θ ) \nabla \log P(\tau|\theta) ∇logP(τ∣θ)的问题:
P ( τ ∣ θ ) = P ( s 1 , a 1 , r 2 , … , s T , a T , r T + 1 ∣ θ ) = P ( s 1 ) P ( a 1 ∣ s 1 , θ ) P ( s 2 , r 2 ∣ a 1 , s 1 ) … = P ( s 1 ) ∏ t = 1 T P ( a t ∣ s t , θ ) P ( s t + 1 , r t + 2 ∣ s t , a t ) P(\tau|\theta)=P(s_1,a_1,r_2,\dots,s_T, a_T,r_{T+1}|\theta)\\=P(s_1)P(a_1|s_1,\theta)P(s_2,r_2|a_1, s_1)\dots \\ =P(s_1)\prod_{t=1}^TP(a_t|s_t,\theta)P(s_{t+1},r_{t+2}|s_t, a_t) P(τ∣θ)=P(s1,a1,r2,…,sT,aT,rT+1∣θ)=P(s1)P(a1∣s1,θ)P(s2,r2∣a1,s1)…=P(s1)t=1∏TP(at∣st,θ)P(st+1,rt+2∣st,at)
这里需要注意的是: P ( s t + 1 , r t + 2 ∣ s t , a t ) P(s_{t+1},r_{t+2}|s_t, a_t) P(st+1,rt+2∣st,at)是MDP中的动态特性,与智能体的决策(或策略)无关,与之有关的只有 P ( a t ∣ s t , θ ) P(a_t|s_t,\theta) P(at∣st,θ),该概率描述了智能体的策略(也可以将其表示为: π θ ( a t ∣ s t ) \pi_{\theta}(a_t|s_t) πθ(at∣st))
有了概率的表达式,很好计算其对数的梯度:
log P ( τ ∣ θ ) = P ( s 1 ) + ∑ t = 1 T log P ( a t ∣ s t , θ ) + log P ( s t + 1 , r t + 2 ∣ s t , a t ) \log P(\tau|\theta)=P(s_1)+\sum_{t=1}^T\log P(a_t|s_t,\theta)+\log P(s_{t+1},r_{t+2}|s_t, a_t) logP(τ∣θ)=P(s1)+t=1∑TlogP(at∣st,θ)+logP(st+1,rt+2∣st,at) ∇ log P ( τ ∣ θ ) = ∑ t = 1 T ∇ log P ( a t ∣ s t , θ ) \nabla \log P(\tau|\theta)=\sum_{t=1}^T\nabla \log P(a_t|s_t,\theta) ∇logP(τ∣θ)=t=1∑T∇logP(at∣st,θ)
带入到 ∇ R ˉ θ = 1 N ∑ n = 1 N R ( τ n ) ∇ log P ( τ n ∣ θ ) \nabla\bar{R}_{\theta}=\frac{1}{N}\sum_{n=1}^NR(\tau^n)\nabla \log P(\tau^n|\theta) ∇Rˉθ=N1∑n=1NR(τn)∇logP(τn∣θ)可以得到:
∇ R ˉ θ = 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ n ) ∇ log P ( a t n ∣ s t n , θ ) \nabla\bar{R}_{\theta}=\frac{1}{N}\sum_{n=1}^N\sum_{t=1}^{T^n}R(\tau^n)\nabla \log P(a_t^n|s_t^n,\theta) ∇Rˉθ=N1n=1∑Nt=1∑TnR(τn)∇logP(atn∣stn,θ)
从而梯度上升的具体表达式可以写成:
θ n e w ← θ o l d + η 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ n ) ∇ log P ( a t n ∣ s t n , θ ) \theta^{new}\leftarrow \theta^{old}+\eta\frac{1}{N}\sum_{n=1}^N\sum_{t=1}^{T^n}R(\tau^n)\nabla \log P(a_t^n|s_t^n,\theta) θnew←θold+ηN1n=1∑Nt=1∑TnR(τn)∇logP(atn∣stn,θ)
为了避免所得到的收益总和一直是正数,这里可以在公式中加入一个负的baseline(类似bias)
θ n e w ← θ o l d + η 1 N ∑ n = 1 N ∑ t = 1 T n ( R ( τ n ) − b ) ∇ log P ( a t n ∣ s t n , θ ) \theta^{new}\leftarrow \theta^{old}+\eta\frac{1}{N}\sum_{n=1}^N\sum_{t=1}^{T^n}(R(\tau^n)-b)\nabla \log P(a_t^n|s_t^n,\theta) θnew←θold+ηN1n=1∑Nt=1∑Tn(R(τn)−b)∇logP(atn∣stn,θ)
该表达式与深度学习中用交叉熵损失函数训练神经网络是类似的,只不过在梯度前加上了 R ( τ ) R(\tau) R(τ)这个权值。交叉熵的表达式可以写成: f ( y , y ^ ) = − ∑ i = 1 N y i ^ log y i f(y,\hat{y})=-\sum_{i=1}^N\hat{y_i}\log y_i f(y,y^)=−∑i=1Nyi^logyi,这里的 y i ^ \hat{y_i} yi^为样本的真实标签,且一般来说标签都是独热表示,例如 [ 1 , 0 , 0 , … , 0 ] [1,0,0,\dots,0] [1,0,0,…,0]求交叉熵的梯度时与之无关,交叉熵的梯度为:
∇ f ( y , y ^ ) = − ∇ log y i \nabla f(y,\hat{y})=-\nabla\log y_i ∇f(y,y^)=−∇logyi
1.2 具体算法
(受篇幅限制,之后敲一遍代码之后再更新吧)
TRPO (Trust Region Policy Optimization)
近端策略优化PPO (Proximal Policy Optimization)
基本步骤:
Policy Gradient
将On-policy改为Off-policy
Add constraint
PPO2
2. 基于值函数方法(Value-based)
2.1 一般思路
基于值函数的方法学习一个critic, 这个critic不会直接决定智能体的决策,而是起到了如下作用:给定一个智能体采取的策略,并评估其好坏。在获得估算出的值函数之后,智能体会根据该值进行策略的更新。这个过程其实就是广义策略迭代的过程(Generalized Policy Iteration),该类方法分为两个步骤,第一个就是如何评估策略,第二个步骤就是对策略进行贪婪更新,从而在很多步之后达到最优解。
策略评估(Policy Evaluation)
在计算评估策略中,既可以使用状态值函数作为评估对象,也可以使用动作值函数进行评估。在强化学习中,如果环境的模型,即MDP已知,则可以通过动态规划来求解(其评估过程就是用Bellman Equation或者是Bellman Optimality Equation进行状态值或动作值的迭代更新);如果是无模型的情况,就可以通过Monte-Carlo和Temporal Difference的方法进行估计。其中MC方法是获取许多episodes,在每个episode结束之后更新状态或动作值。TD的估算方法如下:

策略改进(Policy Improvement)
在策略评估结束之后,智能体要根据所获取的评估值对其策略进行改进。一般采用的方法就是贪心地选择能够使动作值最大的某个动作:
π ′ ( s ) = arg max a Q π ( s , a ) \pi'(s)=\argmax_{a}Q^{\pi}(s,a) π′(s)=aargmaxQπ(s,a)
这时所得到的
V π ′ ( s ) = max a Q π ( s , a ) ≥ V π ( s ) V^{\pi'}(s)=\max_{a}Q^{\pi}(s,a)\geq V_{\pi}(s) Vπ′(s)=amaxQπ(s,a)≥Vπ(s)
如此更新下去, V π ′ ( s ) V^{\pi'}(s) Vπ′(s)满足贝尔曼最优方程,即所采用的策略 π ′ \pi' π′一定是最优的。
该方法是基于策略改进定理:如果 V π ( s ) ≤ Q π ( s , π ′ ( s ) ) V^{\pi}(s)\leq Q^{\pi}(s,\pi'(s)) Vπ(s)≤Qπ(s,π′(s)),则 V π ′ ( s ) ≥ V π ( s ) V^{\pi'}(s)\geq V^{\pi}(s) Vπ′(s)≥Vπ(s) (这里假设是确定性策略)
证明:
V π ( s ) ≤ Q π ( s , π ′ ( s ) ) = E [ R t + 1 + γ V π ( S t + 1 ) ∣ S t = s , A t = π ′ ( s ) ] = E π ′ [ R t + 1 + γ V π ( S t + 1 ) ∣ S t = s ] ≤ E π ′ [ R t + 1 + γ Q π ( S t + 1 ) ∣ S t = s ] = E π ′ [ R t + 1 + γ R t + 2 + γ 2 V π ( S t + 2 ) ∣ S t = s ] … ≤ E π ′ [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + … ∣ S t = s ] = V π ( s ) V^{\pi}(s)\leq Q^{\pi}(s,\pi'(s))=\mathbb{E}[R_{t+1}+\gamma V^{\pi}(S_{t+1})|S_t =s, A_t=\pi'(s)]= \mathbb{E}_{\pi'}[R_{t+1}+\gamma V^{\pi}(S_{t+1})|S_t =s]\\ \leq \mathbb{E}_{\pi'}[R_{t+1}+\gamma Q^{\pi}(S_{t+1})|S_t =s] \\=\mathbb{E}_{\pi'}[R_{t+1}+\gamma R_{t+2}+\gamma^2 V^{\pi}(S_{t+2})|S_t =s] \\ \dots \\ \leq\mathbb{E}_{\pi'}[R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\dots|S_t=s]\\=V^{\pi}(s) Vπ(s)≤Qπ(s,π′(s))=E[Rt+1+γVπ(St+1)∣St=s,At=π′(s)]=Eπ′[Rt+1+γVπ(St+1)∣St=s]≤Eπ′[Rt+1+γQπ(St+1)∣St=s]=Eπ′[Rt+1+γRt+2+γ2Vπ(St+2)∣St=s]…≤Eπ′[Rt+1+γRt+2+γ2Rt+3+…∣St=s]=Vπ(s)
2.2 具体算法
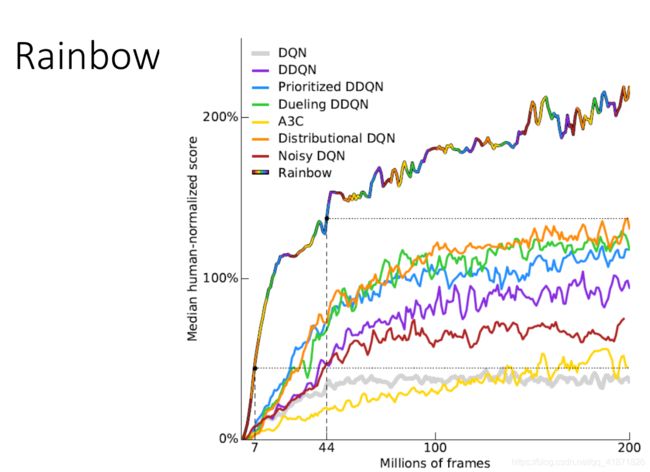
Q-learning及其变体
Q-learning的基本组成元素:
目标网络(Target Network)
ϵ \epsilon ϵ-greedy exploration
经验重放缓冲器(Experience Replay Buffer)
Q-learning使用的七种技巧被总结成了“rainbow”图像。
3. Actor-Critic
3.1 一般思路
对policy gradient做了简单的修改,引入了Advantage Function,也就是将其中的总收益 R ( τ n ) R(\tau^n) R(τn)改为由critic评估的动作值与状态值的差值:
R ( τ n ) − b → Q π θ ( s t , a t ) − V π θ ( s t ) R(\tau^n)-b \quad \to \quad Q^{\pi_{\theta}}(s_t, a_t)-V^{\pi_{\theta}}(s_t) R(τn)−b→Qπθ(st,at)−Vπθ(st)
如果按以上的表达式进行修改,那么actor-critic算法中可能需要涉及两个网络的训练,但其实可以通过动作值与状态值的关系: Q π ( s , a ) = ∑ s ′ , r p ( s ′ , r ∣ s , a ) ( r + V π ( s ′ ) ) Q^{\pi}(s,a)=\sum_{s',r}p(s',r|s,a)(r+V^{\pi}(s')) Qπ(s,a)=∑s′,rp(s′,r∣s,a)(r+Vπ(s′))粗略地化简上式中动作值与状态值的差值,以实现对一个网络进行训练,即
Q π θ ( s t , a t ) − V π θ ( s t ) → r t n + V π θ ( s t + 1 ) − V π θ ( s t ) Q^{\pi_{\theta}}(s_t, a_t)-V^{\pi_{\theta}}(s_t)\to r_t^n+V^{\pi_{\theta}}(s_{t+1})-V^{\pi_{\theta}}(s_{t}) Qπθ(st,at)−Vπθ(st)→rtn+Vπθ(st+1)−Vπθ(st)
那么梯度上升的部分就变成了:
θ n e w ← θ o l d + η 1 N ∑ n = 1 N ∑ t = 1 T n ( r t n + V π θ ( s t + 1 ) − V π θ ( s t ) ) ∇ log P ( a t n ∣ s t n , θ ) \theta^{new}\leftarrow \theta^{old}+\eta\frac{1}{N}\sum_{n=1}^N\sum_{t=1}^{T^n}(r_t^n+V^{\pi_{\theta}}(s_{t+1})-V^{\pi_{\theta}}(s_{t}))\nabla \log P(a_t^n|s_t^n,\theta) θnew←θold+ηN1n=1∑Nt=1∑Tn(rtn+Vπθ(st+1)−Vπθ(st))∇logP(atn∣stn,θ)
通过以上的公式也就将基于策略的与基于值函数的方法融合在了一起,也就是actor-critic的一般思路。

3.2 具体算法
A2C (Advantage Actor-Critic)

A3C(Asynchronous Advantage Actor-Critic)

Pathwise Derivative Policy Gradient
(类似于交替训练两个网络的GAN网络)
4. 模仿学习(Imitation Learning)
IL又称为learning by demonstration或者apprenticeship learning,本质上其实是监督学习的一种。大致的过程就是一个专家(可以是人也可以是好的训练数据)演示如何完成某个任务,之后机器根据专家的“演示”进行学习。该方法适用于收益函数很难定义的情况。IL有两种方法:行为克隆(Behavior Cloning)和逆强化学习(Inverse Reinforcement Learning)。
行为克隆(Behavior Cloning)
该方法属于监督学习,因为有已知的训练数据。

可能遇到的问题:
在机器的学习能力有限的情况下,在学习过程中机器可能会选择错误的行为。并且在该算法过程中训练数据和测试数据不一定满足独立同分布的假设。
逆强化学习(Inverse Reinforcement Learning)
思路:首先获取专家的演示数据或轨迹,经过逆强化学习过程中与环境的交互之后,推导出收益函数,并且用该收益函数,再基于强化学习的方法找到最优的策略。

具体的逆强化学习模型算法一般是由两个网络组成,一个是专家网络,一个是actor网络,类似于GAN, actor和expert两个网络产生的收益函数不断做对比,最后生成一个近乎一样好的收益函数。
