统计字典序元音字符串的数目 (回溯/dfs/动态规划/压缩/数学)
一. 原题呈现及解读
原题目:leetcode 1641. 统计字典序元音字符串的数目
给你一个整数 n,请返回长度为 n 、仅由元音 (a, e, i, o, u) 组成且按 字典序排列 的字符串数量。
字符串 s 按 字典序排列 需要满足:对于所有有效的 i,s[i] 在字母表中的位置总是与 s[i+1] 相同或在 s[i+1] 之前。
输入:n = 1
输出:5
解释:仅由元音组成的 5 个字典序字符串为 ["a","e","i","o","u"]输入:n = 2
输出:15
解释:仅由元音组成的 15 个字典序字符串为
["aa","ae","ai","ao","au","ee","ei","eo","eu","ii","io","iu","oo","ou","uu"]
注意,"ea" 不是符合题意的字符串,因为 'e' 在字母表中的位置比 'a' 靠后题目解读
(1)题目的套壳为元音字符,实质即为严格递增序列,那么同样的,{1,2,3,4,5}是和本题目具有相同本质的序列,返回的所有可能数量也是相同的
(2)题目要求选出所有可能的字符串数量,本质是给定输入有规律数据,返回整数,大部分的此类型题目都可进行找规律,或者更进一步总结出数学规律,或者本身是在经典数学问题上编制的题目
(3)本题目只返回所有的可能性,如果答案是返回所有的可能性的集合,那么只有回溯方法适合
(4)因为返回是可能性,那么在题目的解答上,具有多种方法可以解答,且都是经常用到的解法,比较适合当作原型题或者板子题
二. 多方法解答
1.回溯
class Solution {
List> list = new ArrayList<>();
List path = new ArrayList<>();
String[] str = new String[]{"a","e","i","o","u"};
public int countVowelStrings(int n) {
dfs(0,n);
for(List temp : list){
for(String s : temp){
System.out.print(s+" ");
}
System.out.print(" ,");
}
return list.size();
}
public void dfs(int index, int n){
if(path.size() == n){
list.add(new ArrayList<>(path));
return;
}
for(int i = index; i < str.length; i++){
path.add(str[i]);
dfs(i,n);
path.remove(path.size()-1);
}
}
} 结果呈现

回溯经典模板:
public void dfs(参数1,参数2,...,参数n){
//终止条件
if(){
//添加答案
return;
}
//遍历所有可能选项
for(int i = ?; i < ?; i++){
//添加操作
dfs()
//撤回操作,和有可能的第二次dfs()
dfs()
}
}本方法小结:(1)此题是回溯算法的典型应用,因为返回的是可能性,在样本量较大的情况下不适宜用回溯
(2)for循环内,因为需要取本轮,所以从i开始,另外还有从index+1开始,更多可以参考:
Java-算法-回溯<一>
2.DFS
class Solution {
int n;
int ans = 0;
public int countVowelStrings(int n) {
this.n = n;
dfs(0, 0);
return ans;
}
public void dfs(int pos, int index) {
if (pos >= n){
ans++;
return;
}
for (int i = index; i < 5; i++) {
dfs(pos + 1, i);
}
}
}本方法小结:(1)pos可以理解为已经选择的长度,或者在n的长度内已经填充了多少个元素
(2)index可以理解为填充的起始位置,因为可以重复选择,所以可以选自己,即i
3.记忆化搜索
{Ref.[1]}
class Solution {
int[][] memo;
int n;
public int countVowelStrings(int n) {
this.n = n;
memo = new int[n][5];
for(int[] i : memo){
Arrays.fill(i,-1);
}
return dfs(0, 0);
}
public int dfs(int pos, int index) {
if (pos >= n) return 1;
if (memo[pos][index] != -1) return memo[pos][index];
int ans = 0;
for (int i = index; i < 5; i++) {
ans += dfs(pos + 1, i);
}
memo[pos][index] = ans;
return ans;
}
}本方法小结:(1)和dfs方法相比,关键在于理解在备忘录memo中存了什么东西,pos还是可以理解为在长度为n的需要填充的长度中已经填充了pos个,且是以index为结尾的可能性的结果
4.动态规划
class Solution {
public int countVowelStrings(int n) {
int[][] dp = new int[n+1][5+1];
for(int i = 0; i < 5; i++){
dp[1][i] = 1;
}
for(int i = 1; i <= n; i++){
for(int j = 1; j <= 5; j++){
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
int sum = 0;
for(int i = 1; i <= 5; i++){
sum += dp[n][i];
}
return sum;
}
}以 ["a","e","i","o","u"]为基础,我们列出当n=1~6的结果,当n=1时,以各自元音结尾的只有自己,当n=2时,以a结尾的只有“aa”自己,以e结尾的有“ae”和“ee”两个,以此类推,最后只要把n那行做和即可,观察以下矩阵,可总结出以下动态规划转移方程
a e i o u
n = 1: 1 1 1 1 1
n = 2: 1 2 3 4 5
n = 3: 1 3 6 10 15
n = 4: 1 4 10 20 35
n = 5: 1 5 15 35 70
n = 6: 1 6 21 56 126
![]()
可以在设置dp数组时,多设置一列一行,方便计算。当然,这并不是最后的结果,那么,dp[i][j]数组表示,以 j结尾的长度为i的可能组合数,最后需要把i=n的那行加起来即为最后答案。
5.数组压缩
观察上式的动态转移方程,由于,dp[i]只和dp[i-1]有关,所以可以进行压缩
{Ref.[2]}
class Solution {
public int countVowelStrings(int n) {
int[] dp = new int[5];
Arrays.fill(dp, 1);
for (int i = 1; i < n; i++) {
for (int j = 1; j < 5; j++) {
dp[j] += dp[j - 1];
}
}
return Arrays.stream(dp).sum();
}
}6.数学{Ref.[3]}
排列组合公式
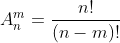
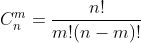
1.首先回顾经典的问题,将 n 个小球放到 m 个盒子里,有多少种方法?
(1)首先考虑盒子不为空的情况,n个小球排成一排,中间放 m - 1 个隔板,相当于把 n 个小球分成了 m 份,盒子不为空,多个隔板不在同一个位置,因此,放隔板的位置有 n - 1 个,我们要放 m - 1 个隔板,即![]()
(2)再考虑盒子可以为空的情况,先拿 m 个新的小球,在 m 个盒子里,每个盒子中扔进去一个小球,再分配原来的这 n 个小球,得到的分配结果,肯定 m 个盒子里都不为空,但此时,我们使用了 n + m 个小球。
(3)把 n 个小球放到 m 个盒子里,盒子可以为空,等价于:把 n + m 个小球放到 m 个盒子里,盒子不能为空,也可以是,先把 n + m 个小球放到 m 个盒子里,盒子不能为空,然后再在每个盒子里拿走 1 个小球,总共拿走了 m 个小球,得到的结果,就是把 n 个小球放到 m 个盒子里,盒子可以为空的解。
2.盒子可以为空,将 n 个小球放到 m 个盒子里,盒子不为空![]() ,将 n 个小球放到 m 个盒子里,盒子可以空
,将 n 个小球放到 m 个盒子里,盒子可以空![]() ,那么可以把问题转换成将 n 个小球放到 5 个盒子里;
,那么可以把问题转换成将 n 个小球放到 5 个盒子里;
class Solution {
public int countVowelStrings(int n) {
return (n + 1) * (n + 2) * (n + 3) * (n + 4) / 24;
}
}参考来源
[1] leetcode ylb [Python3/Java/C++/Go] 一题双解:记忆化搜索 & 动态规划+前缀和
[2] leetcode 官方 统计字典序元音字符串的数目
[3] leetcode liuyubobobo 中学数学科普:n 个小球放到 m 个盒子里