Python爬虫 | 碰到动态页面如何爬取?处理思路分享
页面可以分为三种:
- 静态页面:就是数据不会变动的页面;
- 动态页面:就是数据会随时变动的页面,数据是js生成的;
- 需要登录的静态/动态页面,有些页面还需要各种验证码;
说到爬网页,我们一般的操作是先查看源代码或者审查元素,找到信息所在节点,然后用 beautifulsoup/xpth/re 来获取数据,这是我们对付静态网页的常用手段。
但现在的网页大多都是动态的了,即数据是通过js渲染加载的,对付静态网页那一套在这根本不讨好,所以,掌握爬取动态加载数据的方法就显得十分必要了。
先来梳理一下爬取的流程:
1、先引入需要的包,可以边写边引入,用到哪个包就引入哪个包 from xxx import xxx
2、按F12,选择network选项,找到type为document或js或XHR的页面,把header内容取出来。headers = {…}
3、把url也取出来,等待解析 url = xxx
4、用requests 解析地址,获取页面代码 res = requests.get(url, headers=headers) html = res.text
5、用BeautifulSoup解析html页面,获取我们需要的包含标签的soup对象 soup = bs(html, ‘html.parser’)
6、筛选我们需要爬取的内容标签,内容在哪个标签里,就把那个标签选出来 div = soup.select(‘selector’) 这一步的selector可以用右击标签,选择copy里面的copy selector来获取。(这里获取到的div是若干div对象)
7,遍历div,把div对象转换出div标签 for div in divs: …
8,把获取的内容加入进excel表格
我们在爬取今日头条页面时会发现今日头条随着我们手指上滑其页面会无限制的上拉加载更多,也就是常说的瀑布流,其爬取的核心主流思路是动态页面逆向分析爬取和模拟浏览器行为爬取。
动态页面逆向分析爬取
以这种方式进行动态页面的爬取实质就是对页面进行逆向分析,其核心就是跟踪页面的交互行为 JS 触发调度,分析出有价值、有意义的核心调用(一般都是通过 JS 发起一个 HTTP 请求),然后我们使用 Python 直接访问逆向到的链接获取价值数据。
下面来看一下关于动态渲染页面
javascript动态渲染页面的方式不止ajax一种,如echart官网的许多图表都是经过javascript执行特定算法生成的,且对于淘宝这种页面,其ajax请求中含有很多加密参数,我们也很难直接分析出它的规律。
我们可以直接使用模拟浏览器运行的方式来实现,对于一些JavaScript 动态渲染的页面来说,使用Selenium库这种抓取方式非常有效。

使用Selenium库
在使用Selenium之前,要根据电脑上已安装的chrome游览器的版本选择合适的版本下载chromedriver;
来看一段使用selenium通过googledriver唤醒chrome自动进行测试的例子:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_element_located((By.ID, 'content_left')))
print(browser.current_url)
# 输出当前的cookie
print(browser.get_cookies())
# 输出网页源代码
print(browser.page_source)
finally:
browser.close()
上述代码在游览器中造成的效果是先打开https://www.baidu.com百度页面,向里面输入Python,按回车确认搜索,游览器的搜索结果就出来了。
游览器渲染出页面后selenium会马上抓取游览器此时相关的实时数据,如网页源码,cookie等。
selenium支持很多游览器,如Chrome,Firefox,Opera和Edge等,还支持Andriod,BlackBerry等手机端的游览器,另外还支持无界面游览器PhantomJS。
访问页面
使用get()方法来请求网页。
from selenium import webdriver
browser =webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()
查找节点
Selenium可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。
比如,我们想要完成向某个输入框输入文字的操作,总需要知道这个输入框在哪里吧?而Selenium提供了一系列查找节点的方法,我们可以用这些方法来获取想要的节点,以便下一步执行一些动作或者提取信息。
单个节点
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
# 根据id查找节点
input_first = browser.find_element_by_id('q')
# 根据css选择器查找节点
input_second = browser.find_element_by_css_selector('#q')
# 根据xpath字符串查找节点
input_third = browser.find_element_by_xpath('//*[@id="q"]')
# 得到的节点都是WebElement类型
print(input_first, input_second, input_third)
browser.close()
# /*******----- 输出: ------********\
#
除了上述通过id,css选择器,xpath表达式查找节点外,selenuim还提供了其他各种根据类名,标签名查找节点的方法:
- find_element_by_id()
- find_element_by_name()
- find_element_by_xpath()
- find_element_by_link_text()
- find_element_by_partial_link_text()
- find_element_by_tag_name()
- find_element_by_class_name()
- find_element_by_css_selector
另外,selenium还提供了一个通用的查找节点的方法find_element(),它需要两个参数,查找方式By和查找信息:
from selenium import webdriver
from selenium import webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
# find_element(By.ID, 'q')其实等价于find_element_by_id('q')
input_first = browser.find_element(By.ID, 'q')
print(input_first)
browser.close()
多个节点
如果符合条件的节点有多个,则再使用find_element()系列的方法就只能得到匹配列表中第一个符合条件的节点了,要想拿到所有匹配成功的节点,则需要使用find_elements()系列的方法。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
可见,find_elements()系列方法得到的是一个列表,其中每个节点都是WebElement类型
print(lis)
browser.close()
# /*******----- 输出: ------********\
# [, , , , , , , , , , , , , , , ]
可见,find_elements()系列方法除了加了个-s外,其他方面与find_element()的使用没有什么不同。
模拟执行javascript
对于有些操作,selenium并没有提供相应的实现方式,如下拉进度条。
from selenium import webdriver
browser =webdriver.Chrome()
browser.get('http://www.zhihu.com/explore')
# 模拟执行javascript将进度条拉到最底层
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# javascript弹窗
browser.execute_script('alert("To Bottom")')
获取节点信息
事实上,使用selenium的page_source拿到网页的源代码后我们就可以使用解析库进行分析了,但selenium中也提供了关于节点的操作。
获取属性
使用get_attribute()获取节点属性。
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.zhihu.com/explore'
browser.get(url)
logo = browser.find_element_by_id('zh-top-link-logo')
print(logo)
# 使用get_attribute(attriName)得到属性的属性值
print(logo.get_attribute('class'))
# /*******----- 输出: ------********\
#
# zu-top-link-logo
获取文本值
直接使用text属性可获得节点的内部文本信息。
获取id,位置,标签名和大小
id,location,tag_name和size属性分别用于获取id,位置,标签名和大小这几个属性的值。
我们知道,网页中有一种节点叫作iframe,也就是子Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。
Selenium打开页面后,它默认是在父级Frame里面操作,而此时如果页面中还有子Frame,它是不能获取到子Frame里面的节点的。这时就需要使用switch_to.frame()方法来切换Frame。
延时等待
在Selenium中,get()方法会在网页框架加载结束后结束执行,此时如果获取page_source ,可能并不是浏览器完全加载完成的页面.
如果某些页面有额外的Ajax请求,我们在网页惊代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来。
等待的方式有两种,一是隐式等待,另一个是显示等待。
- 隐式等待的效果其实并没有那么好,因为我们只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。
- 显示等待则指定要查找的节点,然后指定一个最长等待时间。如果在规定时间内加载出来了这个节点,就返回查找的节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。

例子:在百度中搜索成语词典,需要爬取所有的成语词汇。
我们可以点击下一页查看,有经验的同学一眼就可以看出这里是使用javascript异步加载的,在网页源码上是找不到的。

1.点击鼠标右键–>审查元素
2.选择Network按钮
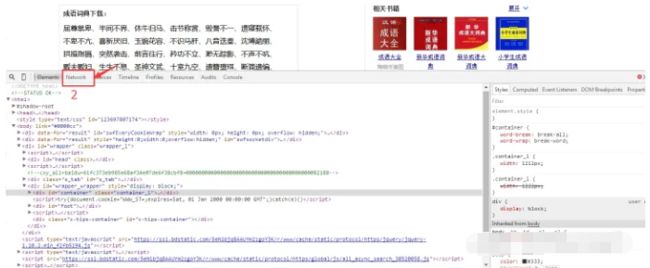
3.选择下一页按钮。得到的如下图,我们可以发现出现两个网址:

为了清楚显示我们想要的东西,我们选择js按钮

4.将鼠标放在网址那,点击右键选择open link in new tab

5.以上四步便可以得到大致是一个json格式的内容,做到这一步,算是完成了一大部分的工作,为了方便解析内容,需要将网站稍作修改,这一步大家需要去尝试。
在此我将这部分(&cb=jQuery1102011321965302340686_1450094493974)去掉后,内容变成纯的json格式文档,接下来的和爬取静态网页的方法一样了。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
点此免费领取:CSDN大礼包:《python学习路线&全套学习资料》免费分享
Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

入门学习视频

Python实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
