Kafka 进阶必备之控制器
点击蓝色“Java极客技术”关注我哟
加个“星标”,一起快乐成长
这是 Java 极客技术的第 273 篇原创文章
如果你只追一个妹子并且对这个妹子特别用心的话,知道的人一定会说你是个好男人;如果你只是浅尝辄止并且追了大部分妹子的话,知道的人一定会骂你渣男。
做技术也是一样的,如果你对一门技术钻研的特别深的话,那你一定是这个领域不可或缺的人才;如果你每个技术都想学并且遇到一些困难就退缩,那么你就离被替代不远了。
中国现在的社会就像是一剂催化剂,催生的都是快节奏的人。周末我听到了这么一个事情:在我的大学里,有这样一个人,他是班长。家里有些钱,可能接触社会比较早,为人处事比较成熟,和导员关系非常好,可以说好到经常性的不来上课,导员竟然还帮忙写假条;好到同学评价班长的时候,打分60分导员竟然私自帮忙改到80分。我说了一句话:这是社会催化的产物,校园也是一个小社会,很多事情从这个小社会就开始变质了。
我们从来不思考自己得到的是不是合规合法的。我记得我的一个人生导师和我说过这样一句话:好好做人,别总是想寻求捷径。这句话像茶一样,慢慢品才香。
下面回到技术。
如果只是为了开发 Kafka 应用程序,或者只是在生产环境使用 Kafka,那么了解 Kafka 的内部工作原理不是必须的。不过,了解 Kafka 的内部工作原理有助于理解 Kafka 的行为,也利用快速诊断问题。下面我们来探讨一下这三个问题
Kafka 是如何进行复制的
Kafka 是如何处理来自生产者和消费者的请求的
Kafka 的存储细节是怎样的
如果感兴趣的话,就请花费你一些时间,耐心看完这篇文章。
集群成员间的关系
我们知道,Kafka 是运行在 ZooKeeper 之上的,因为 ZooKeeper 是以集群形式出现的,所以 Kafka 也可以以集群形式出现。这也就涉及到多个生产者和多个消费者如何协调的问题,这个维护集群间的关系也是由 ZooKeeper 来完成的。如果你看过我之前的文章(真的,关于 Kafka 入门看这一篇就够了),你应该会知道,Kafka 集群间会有多个 主机(broker),每个 broker 都会有一个 broker.id,每个 broker.id 都有一个唯一的标识符用来区分,这个标识符可以在配置文件里手动指定,也可以自动生成。
Kafka 可以通过 broker.id.generation.enable 和 reserved.broker.max.id 来配合生成新的 broker.id。
broker.id.generation.enable参数是用来配置是否开启自动生成 broker.id 的功能,默认情况下为true,即开启此功能。自动生成的broker.id有一个默认值,默认值为1000,也就是说默认情况下自动生成的 broker.id 从1001开始。
Kafka 在启动时会在 ZooKeeper 中 /brokers/ids 路径下注册一个与当前 broker 的 id 相同的临时节点。Kafka 的健康状态检查就依赖于此节点。当有 broker 加入集群或者退出集群时,这些组件就会获得通知。
如果你要启动另外一个具有相同 ID 的 broker,那么就会得到一个错误 —— 新的 broker 会试着进行注册,但不会成功,因为 ZooKeeper 里面已经有一个相同 ID 的 broker。
在 broker 停机、出现分区或者长时间垃圾回收停顿时,broker 会从 ZooKeeper 上断开连接,此时 broker 在启动时创建的临时节点会从 ZooKeeper 中移除。监听 broker 列表的 Kafka 组件会被告知该 broker 已移除。
在关闭 broker 时,它对应的节点也会消失,不过它的 ID 会继续存在其他数据结构中,例如主题的副本列表中,副本列表复制我们下面再说。在完全关闭一个 broker 之后,如果使用相同的 ID 启动另一个全新的 broker,它会立刻加入集群,并拥有一个与旧 broker 相同的分区和主题。
Broker Controller
我们之前在讲 Kafka Rebalance 重平衡的时候,提过一个群组协调器,负责协调群组间的关系,那么 broker 之间也有一个控制器组件(Controller),它是 Kafka 的核心组件。它的主要作用是在 ZooKeeper 的帮助下管理和协调整个 Kafka 集群,集群中的每个 broker 都可以称为 controller,但是在 Kafka 集群启动后,只有一个 broker 会成为 Controller 。既然 Kafka 集群是依赖于 ZooKeeper 集群的,所以有必要先介绍一下 ZooKeeper 是什么,可以参考作者的这一篇文章(ZooKeeper不仅仅是注册中心,你还知道有哪些?)详细了解,在这里就简单提一下 znode 节点的问题。
ZooKeeper 的数据是保存在节点上的,每个节点也被称为znode,znode 节点是一种树形的文件结构,它很像 Linux 操作系统的文件路径,ZooKeeper 的根节点是 /。
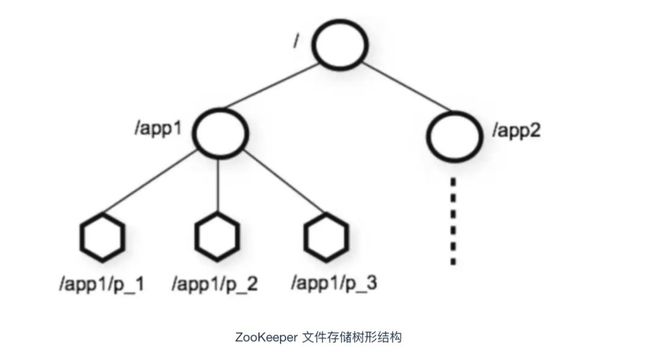
znode 根据数据的持久化方式可分为临时节点和持久性节点。持久性节点不会因为 ZooKeeper 状态的变化而消失,但是临时节点会随着 ZooKeeper 的重启而自动消失。
znode 节点有一个 Watcher 机制:当数据发生变化的时候, ZooKeeper 会产生一个 Watcher 事件,并且会发送到客户端。Watcher 监听机制是 Zookeeper 中非常重要的特性,我们基于 Zookeeper 上创建的节点,可以对这些节点绑定监听事件,比如可以监听节点数据变更、节点删除、子节点状态变更等事件,通过这个事件机制,可以基于 ZooKeeper 实现分布式锁、集群管理等功能。
控制器的选举
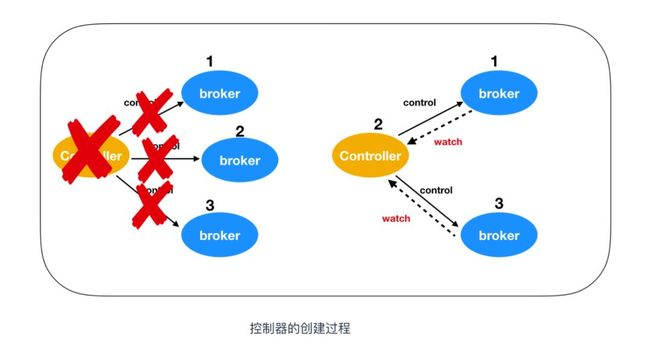
Kafka 当前选举控制器的规则是:Kafka 集群中第一个启动的 broker 通过在 ZooKeeper 里创建一个临时节点 /controller 让自己成为 controller 控制器。其他 broker 在启动时也会尝试创建这个节点,但是由于这个节点已存在,所以后面想要创建 /controller 节点时就会收到一个 节点已存在 的异常。然后其他 broker 会在这个控制器上注册一个 ZooKeeper 的 watch 对象,/controller 节点发生变化时,其他 broker 就会收到节点变更通知。这种方式可以确保只有一个控制器存在。那么只有单独的节点一定是有个问题的,那就是单点问题。
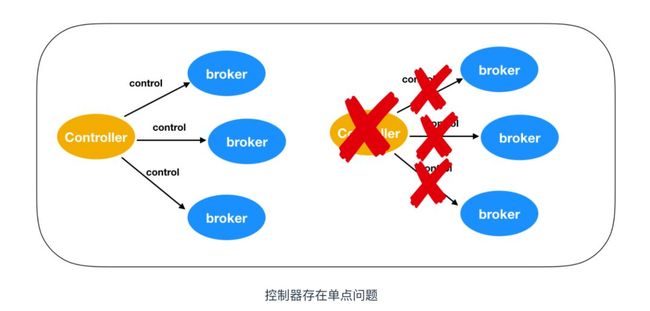
如果控制器关闭或者与 ZooKeeper 断开链接,ZooKeeper 上的临时节点就会消失。集群中的其他节点收到 watch 对象发送控制器下线的消息后,其他 broker 节点都会尝试让自己去成为新的控制器。其他节点的创建规则和第一个节点的创建原则一致,都是第一个在 ZooKeeper 里成功创建控制器节点的 broker 会成为新的控制器,那么其他节点就会收到节点已存在的异常,然后在新的控制器节点上再次创建 watch 对象进行监听。
控制器的作用
那么说了这么多,控制是什么呢?控制器的作用是什么呢?或者说控制器的这么一个组件被设计用来干什么?别着急,接下来我们就要说一说。
Kafka 被设计为一种模拟状态机的多线程控制器,它可以作用有下面这几点
控制器相当于部门(集群)中的部门经理(broker controller),用于管理部门中的部门成员(broker)
控制器是所有 broker 的一个监视器,用于监控 broker 的上线和下线
在 broker 宕机后,控制器能够选举新的分区 Leader
控制器能够和 broker 新选取的 Leader 发送消息
再细分一下可以具体分为如下 5 点
主题管理: Kafka Controller 可以帮助我们完成对 Kafka 主题创建、删除和增加分区的操作,简而言之就是对分区拥有最高行使权。
换句话说,当我们执行kafka-topics 脚本时,大部分的后台工作都是控制器来完成的。
分区重分配: 分区重分配主要是指,kafka-reassign-partitions 脚本提供的对已有主题分区进行细粒度的分配功能。这部分功能也是控制器实现的。Prefered 领导者选举: Preferred 领导者选举主要是 Kafka 为了避免部分 Broker 负载过重而提供的一种换 Leader 的方案。集群成员管理: 主要管理 新增 broker、broker 关闭、broker 宕机数据服务: 控制器的最后一大类工作,就是向其他 broker 提供数据服务。控制器上保存了最全的集群元数据信息,其他所有 broker 会定期接收控制器发来的元数据更新请求,从而更新其内存中的缓存数据。这些数据我们会在下面讨论
当控制器发现一个 broker 离开集群(通过观察相关 ZooKeeper 路径),控制器会收到消息:这个 broker 所管理的那些分区需要一个新的 Leader。控制器会依次遍历每个分区,确定谁能够作为新的 Leader,然后向所有包含新 Leader 或现有 Follower 的分区发送消息,该请求消息包含谁是新的 Leader 以及谁是 Follower 的信息。随后,新的 Leader 开始处理来自生产者和消费者的请求,Follower 用于从新的 Leader 那里进行复制。
这就很像外包公司的一个部门,这个部门就是专门出差的,每个人在不同的地方办公,但是中央总部有一个部门经理,现在部门经理突然离职了。公司不打算外聘人员,决定从部门内部选一个能力强的人当领导,然后当上领导的人需要向自己的组员发送消息,这条消息就是任命消息和明确他管理了哪些人,大家都知道了,然后再各自给部门干活。
当控制器发现一个 broker 加入集群时,它会使用 broker ID 来检查新加入的 broker 是否包含现有分区的副本。如果有控制器就会把消息发送给新加入的 broker 和 现有的 broker。
上面这块关于分区复制的内容我们接下来会说到。
broker controller 数据存储
上面我们介绍到 broker controller 会提供数据服务,用于保存大量的 Kafka 集群数据。如下图
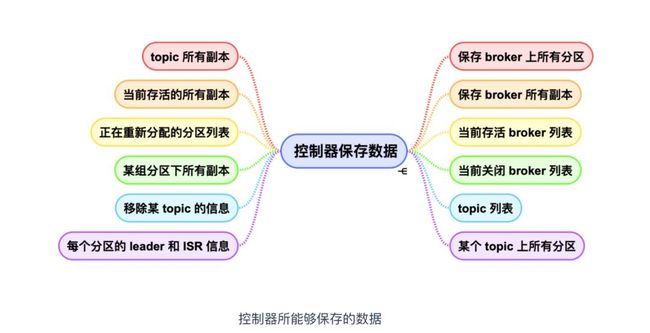
可以对上面保存信息归类,主要分为三类
broker 上的所有信息,包括 broker 中的所有分区,broker 所有分区副本,当前都有哪些运行中的 broker,哪些正在关闭中的 broker 。
所有主题信息,包括具体的分区信息,比如领导者副本是谁,ISR 集合中有哪些副本等。
所有涉及运维任务的分区。包括当前正在进行 Preferred 领导者选举以及分区重分配的分区列表。
Kafka 是离不开 ZooKeeper的,所以这些数据信息在 ZooKeeper 中也保存了一份。每当控制器初始化时,它都会从 ZooKeeper 上读取对应的元数据并填充到自己的缓存中。
broker controller 故障转移
我们在前面说过,第一个在 ZooKeeper 中的 /brokers/ids下创建节点的 broker 作为 broker controller,也就是说 broker controller 只有一个,那么必然会存在单点失效问题。kafka 为考虑到这种情况提供了故障转移功能,也就是 Fail Over。如下图
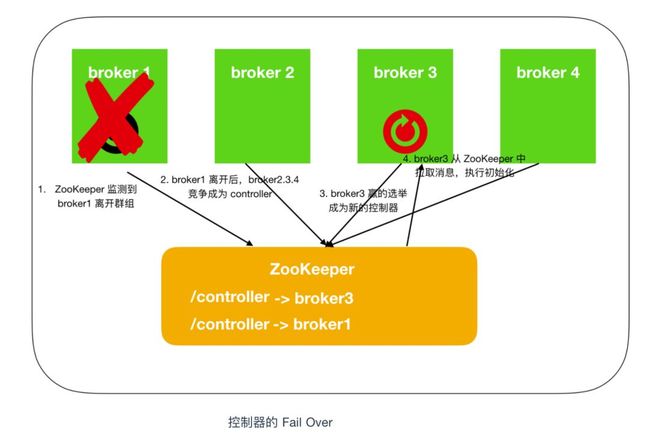
最一开始,broker1 会抢先注册成功成为 controller,然后由于网络抖动或者其他原因致使 broker1 掉线,ZooKeeper 通过 Watch 机制觉察到 broker1 的掉线,之后所有存活的 brokers 开始竞争成为 controller,这时 broker3 抢先注册成功,此时 ZooKeeper 存储的 controller 信息由 broker1 -> broker3,之后,broker3 会从 ZooKeeper 中读取元数据信息,并初始化到自己的缓存中。
注意:ZooKeeper 中存储的不是缓存信息,broker 中存储的才是缓存信息。
broker controller 存在的问题
在 Kafka 0.11 版本之前,控制器的设计是相当繁琐的。我们上面提到过一句话:Kafka controller 被设计为一种模拟状态机的多线程控制器,这种设计其实是存在一些问题的
controller 状态的更改由不同的监听器并发执行,因此需要进行很复杂的同步,并且容易出错而且难以调试。
状态传播不同步,broker 可能在时间不确定的情况下出现多种状态,这会导致不必要的额外的数据丢失
controller 控制器还会为主题删除创建额外的 I/O 线程,导致性能损耗
controller 的多线程设计还会访问共享数据,我们知道,多线程访问共享数据是线程同步最麻烦的地方,为了保护数据安全性,控制器不得不在代码中大量使用ReentrantLock 同步机制,这就进一步拖慢了整个控制器的处理速度。
broker controller 内部设计原理
在 Kafka 0.11 之后,Kafka controller 采用了新的设计,把多线程的方案改成了单线程加事件队列的方案。如下图所示
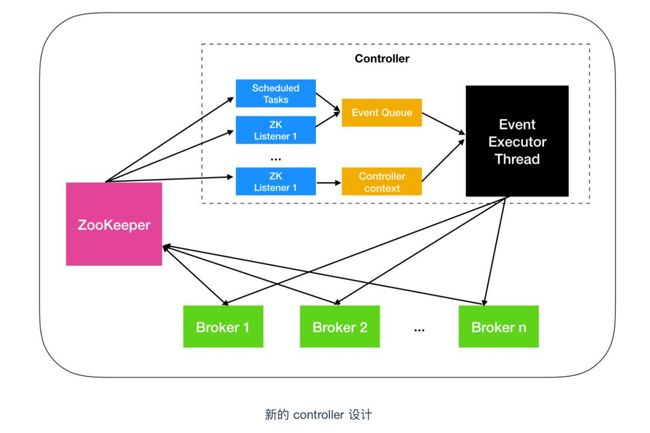
主要所做的改变有下面这几点
第一个改进是增加了一个 Event Executor Thread,事件执行线程,从图中可以看出,不管是 Event Queue 事件队列还是 Controller context 控制器上下文都会交给事件执行线程进行处理。将原来执行的操作全部建模成一个个独立的事件,发送到专属的事件队列中,供此线程消费。
第二个改进是将之前同步的 ZooKeeper 全部改为异步操作。ZooKeeper API 提供了两种读写的方式:同步和异步。之前控制器操作 ZooKeeper 都是采用的同步方式,这次把同步方式改为异步,据测试,效率提升了10倍。
第三个改进是根据优先级处理请求,之前的设计是 broker 会公平性的处理所有 controller 发送的请求。什么意思呢?公平性难道还不好吗?在某些情况下是的,比如 broker 在排队处理 produce 请求,这时候 controller 发出了一个 StopReplica 的请求,你会怎么办?还在继续处理 produce 请求吗?这个 produce 请求还有用吗?此时最合理的处理顺序应该是,赋予 StopReplica 请求更高的优先级,使它能够得到抢占式的处理。
《Kafka 权威指南》
https://blog.csdn.net/u013256816/article/details/80546337
https://learning.oreilly.com/library/view/kafka-the-definitive/9781491936153/ch05.html#kafka_internals
https://www.cnblogs.com/kevingrace/p/9021508.html
https://www.cnblogs.com/huxi2b/p/6980045.html
《极客时间-Kafka核心技术与实战》
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Controller+Redesign
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Controller+Internals
