运筹系列67:大规模TSP问题的EAX遗传算法
1. 算法介绍
EAX是edge assembly crossover 算子的缩写。本算法有Y nagata教授公布,目前在VLSI最大的几个案例上获得了best的成绩。另外目前MonoLisa 100K问题的最优解也是由其公布,若能得到更优解,可以获得1000美元奖励。
算法步骤如下:
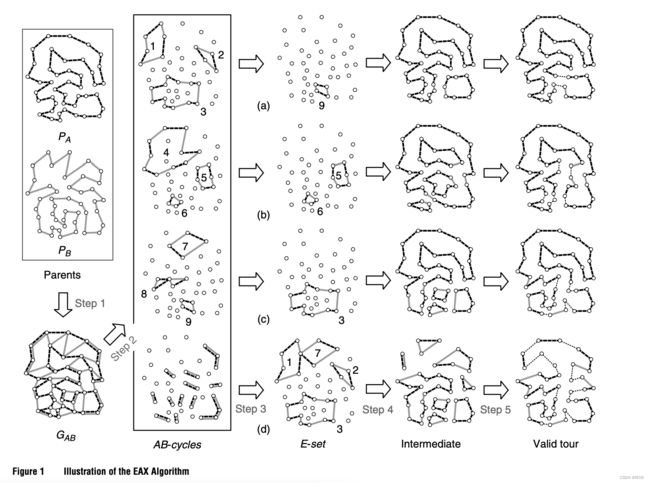
- 获得一系列初始解,选取两条路径A和B进行重叠
- 拆解重叠后的路径形成一系列子路径,每一条子路径都是偶数条边,其中A和B交叉,称为AB-cycle
- 按照一定的规则(随机或者启发式)选取边,称为E-set
- 使用A和E-set中的边进行反向增删,得到一系列Intemidiate结果
- 使用启发式算法将Intemidiate结果构建成soild结果。
2. 代码分析
参考代码https://github.com/nagata-yuichi/GA-EAX(原版)
以及https://github.com/wlsgusjjn/EAX-TSP.git (简化版)
2.1 概述
原版文件清单如下:
main.cpp
- The main function
env.cpp, env.h
- Main procedure of the GA
kopt.cpp kopt.h
- Local search with the 2-opt neighborhood
cross.cpp cross.h
- Edge assembly crossover,核心程序
evaluator.cpp evaluator.h
- Pre-processing procedures to the TSP instance
indi.cpp, indi.h
- An individual (tour)
rand.cpp, rand.h
- Procedures for generating a random number and permutation etc
sort.cpp, sort.h
- Procedures for sorting
***.tsp
- Several TSP instances (TSPLIB format)
2.2 使用方法
编译:g++ -o jikken -O3 main.cpp env.cpp cross.cpp evaluator.cpp indi.cpp rand.cpp kopt.cpp sort.cpp -lm
运行:./jikken
比如:./jikken 10 DATA 100 30 rat575.tsp
参数说明:
- = number of trials
- = filename to which results are written
- = number of population (300 is recommended if N > 10,000)
- = number of offspring solutions (30 is recommended)
- = instance filename (the instance must conform with TSPLIB format)
如果string1位DATA,则会生成两个结果文件:
DATA_Result和DATA_BestSol
-
DATA_Result:存储迭代信息,格式如下:
0 6773 173 0 3
1 6773 174 0 3
2 6773 166 0 3
3 6773 173 0 3
4 6773 173 0 3
5 6773 171 0 3
6 6773 182 0 3
7 6773 168 0 3
8 6773 173 0 3
9 6773 173 0 3- 1st column: trial number
- 2nd column: best tour length obtained in each run
- 3rd column: the number of generations in each run
- 4th column: the execution time (sec) for generating the initial population
- 5th column: the execution time (sec) for each run of the GA
*DATA_BestSol:存储每一轮的最优结果
575 6773
1 24 25 26 27 28 29 52 50 51 74 73 72 49 48 47 70 71 93 94 116 …
- 1st line: number of cities, tour length
- 2nd line: a solution representing a sequence of the cities
如果想记录每一轮的所有路径,将main.cpp中的gEnv->WritePop()开启,结果会写入DATA_POP_*
随后可以将这个文件作为初始路径传给程序继续执行优化:./jikken 10 DATA2 100 30 rat575.tsp DATA_POP_0
2.3 自定义修改
还可以做一些自定义算法配置,主要在env。cpp里面的TEnvironment::Init() 可以修改搜索参数:
Example1: Default setting
fStage = 1; /* Stage I */
fFlagC[ 0 ] = 4; /* Diversity preservation: 1:Greedy, 3:Distance, 4:Entropy */
fFlagC[ 1 ] = 1; /* Eset Type: 1:Single-AB, 2:Block2 */
Example2: Only Stage II is performed using EAX with the Block2 strategy
fStage = 2; /* Stage I */
fFlagC[ 0 ] = 4; /* Diversity preservation: 1:Greedy, 3:Distance, 4:Entropy */
fFlagC[ 1 ] = 2; /* Eset Type: 1:Single-AB, 2:Block2 */
Example3: The greedy selection is used instead of the entropy-preserving selection.
fStage = 1; /* Stage I */
fFlagC[ 0 ] = 1; /* Diversity preservation: 1:Greedy, 3:Distance, 4:Entropy */
fFlagC[ 1 ] = 1; /* Eset Type: 1:Single-AB, 2:Block2 */
TerminationCondition() 里可以修改停止条件
3. 2013年新版本的改进
参考文章:https://sci-hub.se/10.1287/ijoc.1120.0506,主要想法就是第一步将EAX的操作局部化,随后再执行正常的EAX算子。
3.1 GA整体流程
每一阶段的GA算法架构如下,其中Npop个初始解使用的是greedy local search +2-opt neighborhood。注意下面有两个参数Npop和Nch。

每个阶段的终止条件:如果最近的1500/Nch次迭代都没有改进,则令G=当前迭代总次数。继续迭代,直至连续G/10次迭代都没有改进
3.2 边交换算法
- 首先是筛选AB-cycle:在$G_{AB} 上随机游走,直至所有路径都已游走完毕。过程中一旦发现 A B − c y c l e ,立即保存并从 上随机游走,直至所有路径都已游走完毕。过程中一旦发现AB-cycle,立即保存并从 上随机游走,直至所有路径都已游走完毕。过程中一旦发现AB−cycle,立即保存并从G_{AB} $中删除。
- AB-cycle筛选出一部分的集合叫做E-set。
- 使用A和E-set给出一个新的路径(可能有subtour),然后按照一定的规则消除subtour,生成新的路径
- 将新路径放入offspring集合中,直至没有新的offspring生成。
3.3 构筑E-set规则
3.2节中构造E-set时,局部EXA规则目前有两种:
1.随机策略:每个AB-cycles有0.5的概率选上
2.单个策略:随机在剩余的AB-cycles中选一个
subtour消除规则为:
1.每次都从最小的subtour开始,遍历所有待删除的边e
2.另一条待删除的边,需满足其中至少有一个点在e的最近10个点中
全局EXA规则有三种
1.K-multiple策略:随机选取K个AB-cycles,代码中K=5
2.block策略:主要思想是选取位置相近的AB-cycles
3.block2策略:首先定义A-vertex为连接A中两条边的点;B-vertex为连接B中两条边的点;C-vertex为连接A和B中各一条边的点,如下图。其中a和b的差别在于,b中对c-vertex做了精简。

在intermediate solution中,A-blocks和B-blocks被c-vertex隔开,且c-vertex的数量肯定是偶数。c-vertex的计算比subtour的计算要快。使用tabu-search选取E-set,规则为:
- 初始化Tabu[i] = 0
- 选一个较大的AB-cycle作为center AB-cycle然后从剩下的里面随机选取AB-cycle,每一个至少和AB-cycle都有一个接触点
- 在每次迭代过程中,当前E-set都会转移到临近的tabu解以外的c-vertex最小的subtour中,直至LS个阶段没有改进(这里令其为20)。

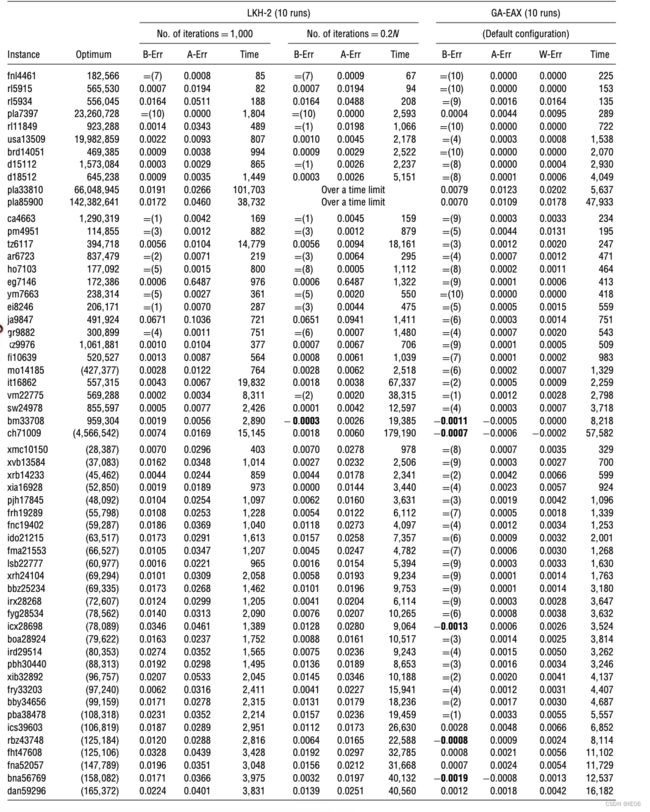
4. 一些对比结果
如下,其中B-err是best solution error,如果是=的话,后面括号中表示获得最优值的次数。A-err是average,W-error则是worst。