Elasticsearch能干什么,关于Elasticsearch及实例应用
我的Elasticsearch系列文章,逐渐更新中,欢迎关注
0A.关于Elasticsearch及实例应用
00.Solr与ElasticSearch对比
01.ElasticSearch能做什么?
02.Elastic Stack功能介绍
03.如何安装与设置Elasticsearch API
04.如果通过elasticsearch的head插件建立索引_CRUD操作
05.Elasticsearch多个实例和head plugin使用介绍
06.当Elasticsearch进行文档索引时,它是如何工作的?
07.Elasticsearch中的映射方式—简洁版教程
08.Elasticsearch中的分析和分析器应用方式
09.Elasticsearch中构建自定义分析器
10.Kibana科普-作为Elasticsearhc开发工具
11.Elasticsearch查询方法
12.Elasticsearch全文查询
13.Elasticsearch查询-术语级查询
14.第14篇-Python中的Elasticsearch入门
15.使用Django进行ElasticSearch的简单方法
16.关于Elasticsearch的6件不太明显的事情
17.使用Python的初学者Elasticsearch教程
18.用ElasticSearch索引MongoDB,一个简单的自动完成索引项目
19.Kibana对Elasticsearch的实用介绍
20.不和谐如何索引数十亿条消息
21.使用Django进行ElasticSearch的简单方法
另外Elasticsearch入门,我强烈推荐ElasticSearch入门教程和这篇优秀的REST API设计指南 给你,这两个指南都是非常想尽的入门手册。
简单介绍一下Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎。它可以让你快速和近乎实时地存储、搜索和分析海量的数据。它通常被用作底层引擎/技术,为具有复杂搜索功能和需求的应用程序提供动力。Elasticsearch在Lucene StandardAnalyzer之上提供了一个分布式系统,用于索引和自动类型猜测,并利用基于JSON的REST API来引用Lucene的功能。
Elasticsearch开箱即用,他的默认值已经调整到最优,并把复杂性隐藏起来,不会让初学者看到复杂的内核。它有一个很短的学习曲线来掌握基础知识,所以任何人只要稍加努力,都可以很快掌握它。
- 在消费者从电商网站目录搜索产品信息的情况下,面临着产品信息检索时间长等问题。这导致用户体验不佳,反过来又会错过潜在客户。如今,企业正在寻找替代的方式,将海量的数据存储在这样的方式,以快速检索。
这可以通过采用NOSQL而不是RDBMS(关系型数据库管理系统)存储数据来实现。
ElasticSearch作为一个NOSQL数据库,因为它具有以下特点。
- 开箱即用
- 拥有庞大的用户社区
- 与JSON的兼容性
- 超级多的案例可参考
后端组件
为了更好地了解Elasticsearch及其使用方法,对主要的后台组件有一个大致的了解会有助于你更好的理解它。
节点
节点是一个单一的服务器,它是集群的一部分。节点存储我们的数据,并参与集群的索引和搜索功能。就像集群一样,节点由一个名字来标识,默认情况下,这个名字是一个随机的UUUID,在启动时分配给节点。我们可以根据需要编辑默认的节点名称。
集群
集群是一个或多个节点的集合,这些节点共同承载着你的整个数据,并提供联合索引和搜索功能。可以有N个具有相同集群名称的节点。
Elasticsearch 在分布式环境中运行:通过跨群集复制,一个辅助群集可以作为热备份而自动启动。
索引
索引是一个具有相似特征的文档的集合。例如,我们可以有一个特定客户的索引,另一个索引是针对特定客户,另一个索引是针对产品信息,另一个索引是针对不同类型的数据。在执行索引搜索、更新和删除操作时,一个索引会有一个唯一的名称来标识。在一个集群中,我们可以根据自己的需要定义任意多的索引。索引类似于RDBMS中的数据库。
文档
文档是一个基本的信息单位,可以编制索引。例如,你可以有一个关于你的产品的索引,然后是客户的文档。这个文档是用JSON表示的。
在一个索引中,你可以存储尽可能多的文档,这样,在同一个索引中,你可以有一个单一产品的文档,另一个是单一订单的文档。
碎片和副本
Elasticsearch 提供了将你的索引细分为多个碎片的能力。当你创建一个索引时,你可以简单地定义你想要的碎片数量。每个碎片本身就是一个功能齐全且独立的 “索引”,可以托管在集群中的任何节点上。
碎片很重要,因为它允许横向分割你的数据量,也可能在多个节点上进行平行化操作,从而提高性能。碎片也可以通过将你的索引的多个副本变成复制的碎片来使用,这在云环境中可以提供高可用性。
弹性堆栈
虽然搜索引擎的核心是搜索引擎,但用户开始使用Elasticsearch做日志,希望能够方便地摄取和可视化。Elasticsearch、Logstash、Kibana是弹性堆栈的主要组成部分,被称为ELK。
Kibana
Kibana可以让你将Elasticsearch数据可视化,并对Elastic Stack进行导航。你可以通过一个问题开始选择给数据定型的方式,找出交互式可视化将引导你的数据走向。你可以从经典的图表(直方图、折线图、饼状图、太阳图等)开始,也可以设计自己的可视化,在任何地图上添加Geo数据。
你还可以进行高级的时间序列分析,在数据中找到可视化关系,并利用机器学习功能探索异常情况。更多详情请看官方页面。
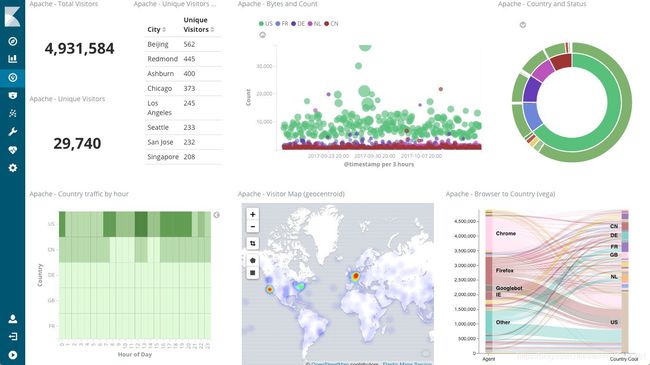
Kinbana控制台
Logstash
Logstash是一个开源的服务器端数据处理流水线,它可以同时从众多的数据源中摄取数据,并对其进行转换,然后发送至收集。
数据往往是分散在许多系统中,或者说是分散在许多系统中的多种格式的数据。在Logstash上可以摄取日志、度量衡、Web应用、数据存储和各种AWS服务的数据,所有这些数据都是以连续流的方式进行摄取。它可以与Netflow等不同的模块一起使用,以获得对网络流量的洞察力。
它通过识别命名的字段来建立结构,动态地转换和准备数据,无论格式如何,它都能动态地转换和准备数据,并将其转换为收敛到一个通用的格式。您可以使用X-Pack中的监控功能来深入了解您的Logstash部署的指标。在概览仪表板中,您可以看到Logstash接收和发送的所有事件,以及关于内存使用情况和正常运行时间的信息。然后,您可以向下钻,查看有关特定节点的统计信息。更多详情请查看官方页面。
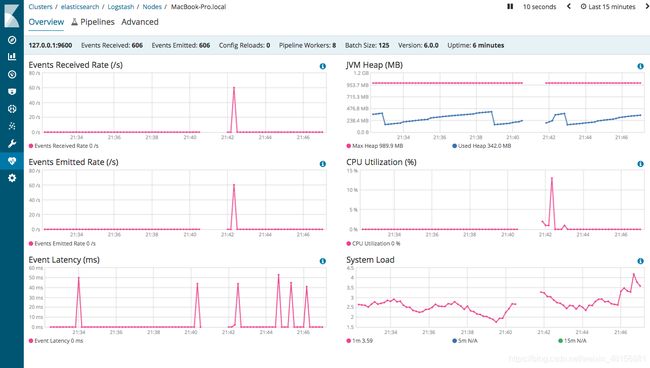 logstash node stats
logstash node stats
主要的数据存储。建立可搜索的目录、文档存储和日志系统。
补充技术:在SQL、mongoDB中添加可视化功能,将索引和搜索投向Hadoop,或者在kafka中添加处理和存储。
补充技术:添加技术。在Elasticsearch中已经有日志的情况下,可以添加度量、监控和分析功能。
Netflix
Netflix的消息传递系统背后使用的是Elasticsearch。消息传递系统分为以下几类。
- 当你加入该服务时,你会收到的消息。
- 一旦人们加入后,他们会收到关于他们可能喜欢的内容或服务器上的新功能的消息。
- 一旦他们通过机器学习算法对你有了更多的了解,他们就会发送更多关于你可能喜欢或喜欢看的内容的个性化消息。
- 如果你决定离开服务,他们会告诉你如何回来。
这都是通过电子邮件、应用推送通知和短信来完成的。为了有效地完成这些工作,他们需要几乎在第一时间知道信息传递过程中可能出现的问题。基于这个原因,Elasticsearch被引入了消息生命周期(之前他们使用的是分布式grep)。
简而言之,每个状态消息都被记录在Elasticsearch上,适当的团队可以通过在Kibana上写一个查询来过滤每个类别。
假设有一部新的电影被推出,在这种情况下,"新标题 "消息必须传递给所有客户。
使用Kibana,他们可以实时看到有多少人收到了新消息的通知,以及消息传递的成功率。他们还可以验证一些消息传递失败的原因。这就引入了调查和处理问题的能力,比如2012年巴西的高信息发送失败率的问题。
通过使用Kibana中的饼状图,他们几乎能够在瞬间发现大量无效的会员失败。通过与国家提供商的跟进,他们发现,7月29日,巴西许多地区的所有现有手机号码的左边都增加了数字9,而不管之前的初始数字是多少,他们都会在7月29日将数字9添加到所有的手机号码中。这一变化是为了增加像圣保罗这样的大都市地区的号码容量,从而消除了该地区长期存在的可用号码短缺问题。
多亏了Elasticsearch,他们才有能力在近乎实时的情况下发现所有这些故障,并及时与供应商跟进。
Tinder
这是一个大型科技公司与Elasticsearch社区相互合作的例子。
Tinder的核心是一个搜索引擎。它的搜索查询很复杂,有两位数的事件,有上百个国家,有50多种语言。
大多数用户的交互都会触发Elasticsearch查询。
根据地域的不同,Tinder有不同的交互方式。例如在亚洲,他们也会把它作为语言交流或搜索导游的方式。
由于这个原因,Tinder中的查询是非常复杂的。他们必须是。
- 个性化:机器学习算法在这方面也得到了应用。
- 基于位置:根据你在某个时间点上的位置来寻找匹配。
- 双向性:要知道哪些用户会在对方身上扫码,基本上是匹配的。
- 实时性:就是实时性。整个交互必须在几毫秒内发生,来自于海量的用户,并且每一个用户都有很多变量关联。
考虑到所有这些功能,后端现实是非常复杂的,从数据科学和机器学习,到双向排名和地理定位,都是非常复杂的。Elasticsearch的基石是让这些组件以一种非常有效的方式共同工作。
在这种情况下,性能是一个障碍。为此,他们一直在与Elasticsearch团队合作,对很多参数进行微调,解决BUG。通过这种方式,他们一直在支持Elasticsearch社区,在改善Tinder本身的用户体验的同时,也帮助提升了整个Elastic stack产品的性能。
思科商业交付平台
Elasticsearch是在2017年推出的,当时他们升级了商业平台。他们从RDBMS切换到Elasticsearch,原因如下。
- 添加容错工作在主动/主动模式下工作。RDBMS不是分布式的,不具有容错性。
- 基于排名和类型超前 搜索来自多个数据库的数据,在30/40个属性上搜索,以获得亚秒级响应。
- 全局搜索:如果在搜索中没有指定特定对象,搜索引擎将针对多个对象查找结果。
思科情报部
一言以蔽之,思科情报部或Cisco Talos就是防止恶意软件和垃圾邮件在 "互联网管道 "中过度饱和的部门。
在思科,每天都会查看超过150万个恶意软件样本。恶意有效载荷和垃圾邮件占所有电子邮件流量的86%(每天超过6000亿封电子邮件)。Talos的情报团队是发现网络上新的全球范围内的漏洞并找出真正的坏人的人。
他们通过分析ssh终端和路由器蜜罐的流量模式,收集异常行为,如使用蛮力攻击来猜测用户和密码的企图登录等,来检测新的漏洞。通过这种方式,他们记录了攻击者登录后使用的命令,记录了攻击者在登录后使用的命令,记录了他们从服务器上下载和上传的文件(虽然很难相信,但互联网上的大多数凭证都是像行密码和用户名admin这么简单)。
就是他们在2015年阻止了所谓的SSHPsychos组织。这个组织通过从特定类别的IP产生SSH蛮力登录尝试,在整个互联网上产生大量的扫描流量,这是众所周知的。一旦他们能够以root身份进入服务器,他们就在下载并安装DDoS根基程序。
自2017年以来,他们使用logstash和kibana来检测和分析可能的全球规模线程。
结论
Elasticsearch是一个分布式、RESTful和分析性搜索引擎,能够解决各种问题。
许多公司都在切换到它,并将其集成到当前的后端基础设施中,因为:
- 它允许使用聚合功能放大到你的数据,并对数十亿条日志线进行分析。
- 它结合了不同类型的搜索:结构化搜索、非结构化搜索、Geo搜索、应用搜索、安全分析、度量衡和日志。
- 它的速度非常快,它可以在你的笔记本电脑上以同样的方式运行,只需一个节点,也可以在有数百台服务器的集群上运行,使得原型设计非常容易。
- 它使用标准的RESTful APIs和JSON。社区还用Java、Python、.NET、SQL、Perl、PHP等多种语言构建和维护客户端。
- 通过使用Elasticsearch-Hadoop(ES-Hadoop)连接器,可以将Elasticsearch的实时搜索和分析功能应用到你的大数据上。
- 像Kibana和Logstash这样的工具可以让你通过使用图表和执行颗粒化搜索,以非常简单和直接的方式让你的数据变得有意义。
在这篇文章中,我们只是简单介绍了Elasticsearch的能力和用例,以及能够解决的各种业务挑战。如果你有兴趣了解更多,或者想测试一下,请看一下他们的产品页面和教程。如果你想了解如何从零搭建Elasticsearch,推荐你看这篇教程,写的很全面。