详解利用Python接受来自浏览器的请求,并返回对应文件内容的简单示例代码
详解利用Python接受来自浏览器的请求,并返回对应文件内容的简单示例代码
示例代码如下:
import http.server
import socketserver
import urllib.parse as urlparse
import os
PORT = 8000
class SimpleHTTPRequestHandler(http.server.BaseHTTPRequestHandler):
def do_GET(self):
url = urlparse.urlparse(self.path)
params = urlparse.parse_qs(url.query)
if 'file' in params:
filename = params['file'][0]
filepath = os.path.join(os.getcwd(), filename)
if os.path.isfile(filepath):
self.send_response(200)
self.send_header('Content-type', 'text/plain')
self.end_headers()
with open(filepath, 'rb') as file:
self.wfile.write(file.read())
else:
self.send_error(404, "File not found")
else:
self.send_error(400, "Missing parameter 'file'")
with socketserver.TCPServer(("", PORT), SimpleHTTPRequestHandler) as httpd:
print("Server started at port", PORT)
httpd.serve_forever()
01-类SimpleHTTPRequestHandler继承自 BaseHTTPRequestHandler 类。
02-类SimpleHTTPRequestHandler定义了一个成员函数,其名字为do_GET
03-下面这条语句的详细解释:
url = urlparse.urlparse(self.path)
在 Python 中,urlparse 模块(即urllib中的parse模块)提供了解析 URL 的函数和类,其中 urlparse.urlparse 函数用于解析 URL 字符串并返回一个 ParseResult 对象,该对象包含 URL 的各个部分(例如协议、主机名、路径、查询参数等)。
关于成员函数urlparse()的详细介绍,可参见博文 https://blog.csdn.net/wenhao_ir/article/details/129852430
在上述代码中,self.path 是 SimpleHTTPRequestHandler 类的一个成员变量,表示请求的路径(path),即 HTTP 请求的 URL 中主机名之后的部分。
关于成员变量path的示例,可参见博文 https://blog.csdn.net/wenhao_ir/article/details/129843007
执行 urlparse.urlparse(self.path) 会将请求的路径解析为一个 ParseResult 对象,该对象包含了请求 URL 的各个部分,例如 scheme 表示协议(http 或 https),hostname 表示主机名,path 表示路径,query 表示查询参数,fragment 表示锚点。
如果请求的URL是:http://example.com/search?q=python
则根据博文的 https://blog.csdn.net/wenhao_ir/article/details/129843007的结果,
self.path的值为字符串:
/search?q=python
url为下面这样的一个对象:

04-对下面这条语句的解释:
params = urlparse.parse_qs(url.query)
上面这条语句的理解请参考博文:https://blog.csdn.net/wenhao_ir/article/details/129853574
05-对下面这条语句的解释:
if 'file' in params:
这行代码是在判断字典对象params中是否有一个名为 file 的参数。如果有,则返回 True,否则返回 False。
具体解释如下:
1 params 是一个字典,其中保存了 URL 查询字符串中所有的参数和它们的值。例如,如果 URL 查询字符串为 ?file=a001.txt&name=Tom,则 params 为 {‘file’: [‘a001.txt’], ‘name’: [‘Tom’]}。
2 if ‘file’ in params 判断字典 params 中是否有一个名为 file 的键。如果有,则条件成立,执行下面的语句块。
综上所述,这行代码的作用是检查字典对象params中是否有一个名为 file 的参数。如果有,则执行下面的代码块,否则跳过。
06-对下面这条语句的解释:
filepath = os.path.join(os.getcwd(), filename)
os.path.join() 方法用于将一个或多个路径组合成一个完整的路径。在这里,os.getcwd() 返回当前工作目录(即 Python 解释器的当前目录),然后使用 os.path.join() 方法将当前目录和文件名 filename 组合成一个完整的路径。
例如,如果当前目录是 /home/user,文件名是 test.txt,则 os.path.join(os.getcwd(), filename) 返回的将是 /home/user/test.txt。
07-对下面这条语句的解释:
if os.path.isfile(filepath):
在这里,if os.path.isfile(filepath): 判断是否存在路径为 filepath 的文件。如果该文件存在,执行后续代码,否则不执行。
08-对下面这条语句的解释:
with open(filepath, 'rb') as file:
with open(filepath, ‘rb’) as file: 是 Python 的文件操作语句,用于打开指定路径下的文件,并以二进制方式读取文件内容。
其中:
with open() 是 Python 的上下文管理语句,会在执行完其中的代码后自动关闭打开的文件,不需要手动关闭。
filepath 是需要打开的文件的路径。
‘rb’ 是打开文件的模式,其中 ‘r’ 表示读取模式,‘b’ 表示二进制模式。如果不指定模式,默认以文本模式打开文件。
as file 将打开的文件对象赋给变量 file,从而可以使用 file 变量操作文件。
因此,with open(filepath, ‘rb’) as file: 的含义是打开路径为 filepath 的二进制文件,并将打开的文件对象赋给变量 file。执行完该语句后,文件内容已经被读取到了内存中,并保存在变量 file 中。
09-对下面这条语句的解释:
self.wfile.write(file.read())
在这行代码中,self.wfile 是在 BaseHTTPRequestHandler 类中定义的一个对象,用于处理 HTTP 响应。它代表着在 HTTP 连接中,服务器向客户端发送响应的输出流。而 file.read() 则是读取文件内容。因此,这行代码的作用是将打开的文件内容写入 HTTP 响应的输出流中,从而将文件内容返回给客户端。
wfile对象是在 BaseHTTPRequestHandler 的 finish() 方法中创建的。在 BaseHTTPRequestHandler 的 handle() 方法中,调用了 self.finish() 方法,从而触发了 wfile 对象的创建。wfile 对象是一个可写的套接字对象,用于向客户端发送数据。在 self.wfile.write() 中,数据会被写入到 wfile 对象中,从而发送给客户端。
至此,上面的示例代码就彻底理解清楚了,接下来,我们运行上面的代码,运行后cmd的截图如下:

然后我们在与代码相同的文件下,新建一个名字为100.txt的文件,内容随意,如下图所示:


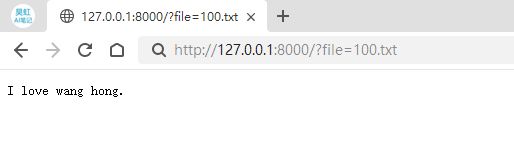
然后我们在浏览器中访问下面这个URL,
http://127.0.0.1:8000/?file=100.txt
运行结果如下: