【DevOps】GitOps 初识(下) - 让DevOps变得更好
实践GitOps的五大难题
上一篇文章中,我们介绍了GitOps能为我们带来许多的好处,然而,任何新的探索都将不会是一帆风顺的。在开始之前,如果能了解实践GitOps通常会遇到的挑战,并对此作出合适的应对,可能会使我们使用GitOps的旅程更加的顺利。
1. 代码的自动提交造成的代码冲突
在GitOps实践中,CD过程中的自动更新对于适应快节奏的发布至关重要。然而,在一个团队中,可能会有多个CI流水线正在进行自动化测试、构建和部署应用程序。当这些CI流程请求将更新发布到测试环境时,它们可能会涉及到相同的文件,因为这些文件是应用程序和基础设施的关键部分。由于Git不支持自动更新,这些CI流水线可能会同时尝试向同一存储库发起PR,而它们之间没有同步,因此可能会出现冲突。Git将不知道如何自动解决这些冲突,因此需要手动进行解决。如果冲突没有得到及时解决,可能会导致应用程序无法正确部署或运行,进而导致生产中的问题。此外,冲突可能会导致CI流程被阻塞,从而导致工作停滞。为了解决这个问题,可以考虑为不同的CI流水线设置不同的代码仓库或分支。
2. 过多的Git代码仓库
当引入新的环境或应用程序时,GitOps 存储库的数量通常会增加,这也会增加存储库管理的负担。每个存储库都需要相同的访问权限,并与各个集群上的同步代理连接。配置和设置这些存储库可能需要大量的开发时间,从而降低开发效率。
为了缓解这个问题,一种方法是使用较少的 Git 存储库,例如每个集群只使用一个存储库。这样可以减少存储库的数量,但也会增加每个存储库的工作量,包括拉取请求和访问控制管理等方面。
另一种解决方法是使用命名空间对不同环境中的对象进行分组,而不是为每个环境创建单独的存储库。例如,对于 Kubernetes 环境,可以在同一个 Git 存储库中使用不同的目录来表示不同的命名空间。这样可以减少存储库的数量,同时也可以更好地组织和管理环境中的对象。
除了上述方法之外,还可以使用 Git 的子模块(Git Submodules)或子树(Git Subtrees)等现有工具来管理多个存储库之间的关系。例如,可以使用子模块将一个存储库嵌套在另一个存储库中,从而创建一个“超级存储库”,包含多个子存储库的内容。这样可以更好地管理多个存储库之间的依赖关系和版本控制。
总之,选择正确的存储库管理方法可以提高 GitOps 工作流的效率和可靠性,从而使开发团队更好地管理基础设施和应用程序。
3. 可视化程度有限
在 GitOps 工作流程中,可视化意味着可以在任何时候查看系统的当前状态和所做的更改。例如,在 Kubernetes 环境中,可见性可以包括以下内容:
- 集群中所有的资源对象,如 Pod、Service、Deployment 等
- 资源对象的状态信息,例如容器的运行状态、服务的 IP 地址等
- 所有部署、升级和回滚操作的记录,包括操作者、操作时间和操作结果等
- 监控和日志数据,可以帮助识别问题并进行故障排除
通过提供这些信息,GitOps 工作流程可以提高开发和运维团队的效率和可靠性,以及保证系统的安全和稳定性。GitOps 可以将所有环境中的状态数据存储在 Git 中,以纯文本的方式提供对所有内容的可视化。但这种方法仅适用于相对简单的环境设置,例如少量存储库中可管理的配置文件数量。在大型企业环境中,通常会存在许多 GitOps 存储库和配置文件,这使得仅凭纯文本文件进行查找变得不切实际。为了提高 GitOps 的可见性,团队可以采用各种工具和方法。例如,自动化配置管理工具可以帮助团队更好地管理配置文件和存储库,提高效率并减少错误。另一种方法是使用可视化控制面板,可以以可视化和直观的方式查看各个环境的状态和更改历史记录。例如:
- 自动化配置管理工具:如 Ansible、Terraform 和 Puppet,可以帮助团队更好地管理配置文件和存储库,从而提高效率和减少错误。
- 可视化控制面板:例如 Weave Cloud、Argo CD 和 Jenkins X,可以提供直观和可视化的方式来查看各个环境的状态和更改历史记录。
- 监控和日志工具:例如 Prometheus 和 ELK Stack,可以帮助团队监控各个环境的状态,并记录日志以便于故障排除。
- 管理工具:例如 GitLab 和 GitHub,可以提供管理 GitOps 存储库和配置文件的工具和接口。
4. 不能集中管理机密信息
在复杂的企业环境中,需要一种解决方案来管理 CI/CD 流程之外的机密信息。例如,某些应用程序可能需要使用敏感 API 密钥或数据库密码。在这种情况下,存储这些机密信息在 Git 存储库中是不安全的。因此,需要使用一种安全的、集中化的数据存储方式来保存这些机密信息。可以使用一些工具来实现这一目的,例如 HashiCorp Vault 或者 Kubernetes 的 Secret 对象。
虽然 GitOps 并不会阻止您使用这些工具来集中管理机密信息,但它也没有专门为此提供任何特殊支持。另外需要注意的是,将机密信息存储在 Git 存储库中是不安全的,因为 Git 历史记录会永久记住这些机密信息,这会给企业带来安全风险。
因此,在复杂的企业环境中,需要一种综合的、安全的解决方案来管理机密信息。这样的解决方案应该提供严格的访问控制、审计记录和加密功能,以确保机密信息得到最大程度的保护。
5. 不完备的审计功能
Git 存储库的优势之一是其具备完整的状态变更历史记录,这对于审计流程非常有用。例如,在企业环境中,审计人员可以使用 Git 存储库检查每个环境中的资源状态,以确保所有配置都是按照标准规范进行的。
尽管如此,有的其他信息想要通过Git来获取就比较困难了。例如,在运维团队中,有时需要确定某个应用程序已经部署了多少次。这个问题可能需要在 Git 历史记录中查找,或者需要遍历 Git 存储库中的所有文本文件并计算。这些过程可能会比较繁琐且容易出错。
GitOps实践举例
假设开发人员已经使用Git来管理应用程序的源代码。所有更改(包括应用程序和基础架构层面的更改)都通过Git进行自动化处理,且将Git仓库作为系统状态检测的唯一信源。GitOps控制器将会双向地对比Git中声明的期望状态和实际系统状态,同时也会检测集群中不属于由Git提交引起的更改。
下面让我们来看一下在基于Kubernetes的系统中, GitOps的基本工作流程:
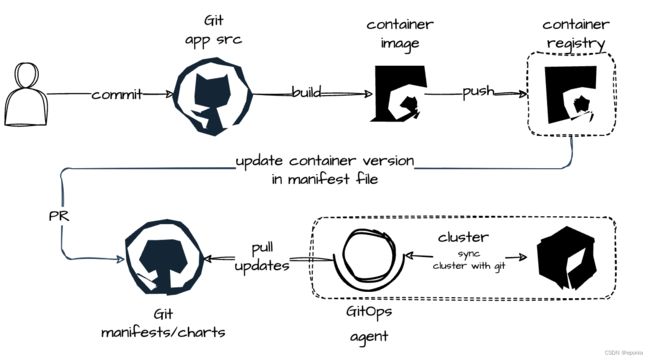
1. 应用代码提交触发CI
每个业务代码仓库中存储的都是开发团队编写的应用源代码用于构建应用程序。对于应用开发而言,开发团队仍然可以像以前一样工作。每当有新的代码提交都会触发一个CI流水线,得到一个构建产物,在容器化部署的场景下,这个产物通常就是一个容器镜像,然后,这个镜像会被推送到容器仓库中去。
2. 向独立的应用配置仓库提交PR
在 Kubernetes 中,所谓的配置,包括描述deployment及其相关变更的manifests(yaml
文件),其中包括如何映射外部端口、目录、服务、环境变量和镜像配置选项的定义。总而言之,通过这些配置,它完整描述了应用程序的期望状态。这些所有的配置文件,都将独立于源代码,存放在一个单独的Git仓库中。
3. GitOps监测配置仓库变更
GitOps agent会实时的监测配置仓库的一切变更,只要监测到有变更发生,便会触发一次部署。配置的变更意味着期望状态的变更,GitOps agent(如ArgoCD或其他类似工具)会对比Git仓库中配置的期望状态与系统的实际状态,这种对比是双向的,如果发现系统中发生了一些Git仓库中没有声明的变更,那么在本次部署中,会丢弃这些变更,回滚到Git仓库中声明的状态。
4. 部署到预发布或生产环境
GitOps 可以处理多个环境或集群。一个常见的模式是首先部署到预发布环境,进行负载测试或集成测试。这是一个额外的可靠性层,确保在生产之前没有部署问题。
5. 测试功能并确认系统状态符合期望
当部署完成后,开发团队可以测试应用程序功能以确保部署成功,并查看集群状态是否与 Git 声明的期望状态相同。
上面描述的工作流程是 GitOps 工作的一个范例,可应用于任何云原生环境,以管理基础架构的配置以及软件的部署。
GitOps 初识(上) - 让DevOps变得更好