【Java EE】-多线程编程(六) 多线程案例之阻塞队列&&生产者消费者模型
作者:学Java的冬瓜
博客主页:☀冬瓜的主页
专栏:【JavaEE】
分享:久闻中原歧王战力无双,今日一见,果非虚言!——《画江湖之不良人》
主要内容:阻塞队列的概念,标准库阻塞队列的使用,使用空一个空间区分队满和队空的方式实现循环队列,用size记录元素个数实现循环队列。把普通的循环队列改造成阻塞队列。生产者消费者模型,优点解耦,削峰填谷。使用自定义阻塞队列实现生产者消费者模型。

文章目录
- 一、阻塞队列
-
- 1、什么是阻塞队列?
-
- 1> 概念
- 2> 使用标准库的阻塞队列
- 2、自定义实现阻塞队列
-
- 1> 普通队列的实现
-
- <1> `空一个空间:`
- <2> `用size记录元素个数`
- 2> 把普通队列改造成阻塞队列
- 二、生产者消费者模型
-
- 1、什么是生产者消费者模型
- 2、为什么要用生产者消费者模型
- 3、利用自定义阻塞队列实现生产者消费者模型
一、阻塞队列
1、什么是阻塞队列?
1> 概念
阻塞队列是一种特殊的队列,是在普通队列的基础上,加上了阻塞的功能。(消息队列,优先级队列都是特殊的队列)
具体的阻塞效果:
队列为空时,尝试出队(take方法),就会阻塞
队列为满时,尝试入队(put方法),就会阻塞
2> 使用标准库的阻塞队列
ArrayBlockingQueue需要传入一个capacity作为数组长度。除此之外它们三个的用法都一样,都有put()入队,take()出队。只是底层实现和相关性质不一样。
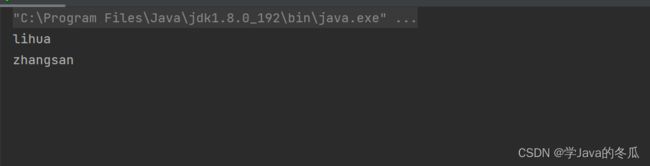
要出队时队空阻塞示例:
public class Main {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> bq = new LinkedBlockingQueue<>();
bq.put("lihua");
bq.put("zhangsan");
System.out.println(bq.take());
System.out.println(bq.take());
System.out.println(bq.take());
}
}
结果:程序一直在进行,并未停止,而是进入阻塞状态了。
2、自定义实现阻塞队列
1> 普通队列的实现
- 阻塞队列是一个特殊的队列,要想实现阻塞队列,那就得先实现普通队列。那么我们先来回忆一下,普通队列可以怎么实现?
队列的性质是:先进先出,队尾入队头出。 - 方法:
法一:使用链表实现:如果使用链表,我们可以选择头删尾插的方式(大家都知道尾删要找前一个节点,相对来说较为麻烦),那么就把链表的头作为队头,链表的尾作为队尾。这样给队尾加上一个引用,那么就可以实现入队和出队都是O(1)的复杂度。队列元素范围:[front,rear) ==> 左开右闭
法二:使用数组实现,又叫做循环队列。那么循环队列怎么实现?又可以有两种办法,第一种:循环队列空一个空间不放元素,用来区分队空和队满的情况。第二种:记录元素的个数,就可以明确的知道队空和队满的情况。下面我们就来看看怎么写基于数组实现的这个循环队列。队列元素范围:[head,tail) ==> 左开右闭(用front和rear或者head和tail都是你自己选择)
<1> 空一个空间:
// 数组实现队列:
// 法一:空出一个空间,用于区分队列空和队列满,使用front表示队首元素,rear表示队尾的下一个下标,即左闭右开[head,tail)
class CircularQueueFunc1 {
private int[] items = new int[100];
private int front = 0;
private int rear = 0;
public CircularQueueFunc1() {}
public void put(int val){
if((rear+1) % items.length == front){
// 队列满,
return;
}
items[rear] = val;
rear++;
rear = rear % items.length;
}
public Integer take(){
if(rear == front){
return null;
}
int result = items[front];
front++;
front = front % items.length; // 出队元素归位
return result;
}
}
我们来分析一下上面的代码,这是数据结构第二版里的经典的循环队列的实现方法。我们把put分析懂了,其实take就懂了。
首先我们抛出第一个问题,队满操作为什么要这样实现?看似不是不用求余就可以完成了吗?
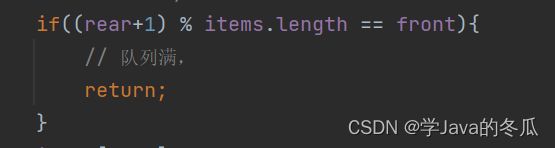
这个问题,要想清楚需要举例子,我们看到上面的数组我们自定义是长度位100,我们假设一个可能存在的场景:此时已经连续插入98(下标0-97)个数,要插入第99(下标98)个数时,rear=98,还不满足队列满的条件。继续往下,第99个元素插入,rear+1之后,rear变成了99,rear = rear % items.length;取余数后还是99。当我们要准备插入第100个元素时,此时rear=99,我们知道一直都在入队,而没有出队,所以front此时还等于最开始的0,那就情况来了,if((rear+1) % items.length == front)就是if((99+1)%100==0),很明显满足了条件,所以队满。因此这个取余数操作其实就是为了这一步。
当然,如果也已经出队了一些元素,比如此时front=5,那要插入第100个这时依旧不满足队满的条件,那就继续放元素,然后下面rear+1就变成100,然后rear就取模归位到0,达到循环的目的。(take中的front循环归位到0也是一样的)
<2> 用size记录元素个数
// 法二:使用size记录队列元素个数,此时数组全部空间都可放元素。使用head表示队首元素,tail表示队尾的下一个下标,依然是[head,tail)
class CircularQueueFunc2 {
private int[] items = new int[100];
private int head = 0;
private int tail = 0;
private int size = 0;
public void put(int val){
if(size == items.length){
return;
}
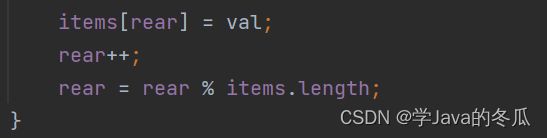
items[tail] = val;
tail++;
size++;
// tail = tail % items.length;
if(tail == items.length){ // 上面的取模操作和这一步操作功能一样,但是这里的比较比取模效率高,且代码可读性更高。
tail = 0;
}
}
public Integer take(){
if(size == 0){
return null;
}
int result = items[head];
head++;
size--;
if (head == items.length){
head = 0;
}
return result;
}
}
相比于第一个代码对于队空和队满的判断,那这个记录元素个数的方法简单很多。size == items.length即表示队满,size == 0即表示队空。然后对取模归位为0的代码也稍作了修改,把取模归位0变成了tail(最后一个元素的下一个空间的下标)等于数组长度,就归位0。修改过后,代码更易理解,且效率会更高。因为比较运算会比取模运算(相当于做除法)快很多。

2> 把普通队列改造成阻塞队列
- 那我们就把用size记录元素个数实现循环队列的这个普通队列,实现成一个阻塞队列。我们想想,阻塞队列,那肯定是需要阻塞的,那么怎么阻塞呢?这就回到我们最开始的阻塞队列的概念理解的部分了,阻塞队列,队满时,想要入队会阻塞;队空时,想要出队会阻塞。
但是我们的普通队列的代码中,队满或者队空都直接返回了,所以需要修改的地方在这里,那么怎么让它实现阻塞,然后由我们人为去控制呢?sleep无法确定具体时间,而wait和notify可以很好的控制。代码如下:
// 阻塞队列:在普通循环队列的基础上,增加阻塞的功能,让它变成阻塞队列。
class MyBlockingQueue {
private int[] items = new int[1];
private int head = 0;
private int tail = 0;
private int size = 0;
public void put(int val) throws InterruptedException {
synchronized (this){
while (size == items.length){
// 队列满时wait,等待先take()元素出队后才能继续执行入队元素
this.wait();
}
items[tail] = val;
tail++;
size++;
// tail = tail % items.length;
if(tail == items.length){ // 上面的取模操作和这一步操作功能一样,但是这里的比较比取模效率高,且代码可读性更高。
tail = 0;
}
// 唤醒take中队空时的wait操作
this.notify();
}
}
public Integer take() throws InterruptedException {
int result = 0;
synchronized (this) {
while (size == 0) {
// 队列空时wait,等待先put()入队元素后才能继续执行出队元素
this.wait();
}
result = items[head];
head++;
size--;
if (head == items.length) {
head = 0;
}
// 唤醒put中队满时的wait操作
this.notify();
}
return result;
}
}
修改的内容1就是下图所展示的:在put方法中,我们把满队时return修改成了wait,然后用take操作出队完一个元素后notify唤醒,继续入队操作。在take方法中,队空时return改成了wait,用put操作入队完一个元素后notify唤醒,继续出队操作。
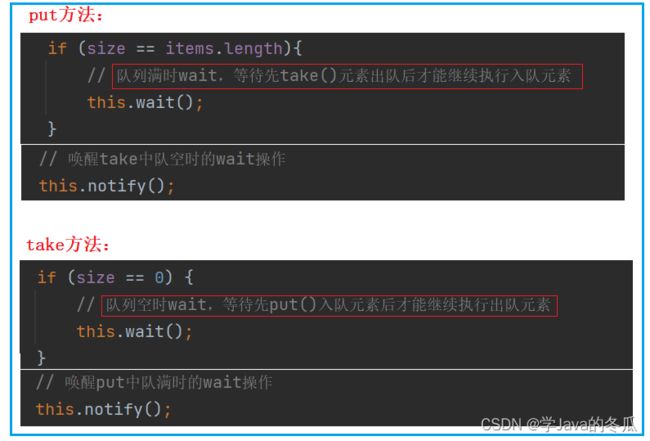
修改的内容2:synchronized加锁到哪个位置?在put方法中,因为多个地方涉及到++和修改操作,还有可能设计if判断读取时的内存可见性问题,所以直接包括方法中的全部内容。take方法中的result是一个局部变量,并不会有线程安全问题,所以放在锁外面。其次还有一点就是要记住:wait和notify的前提是有锁。所以在这里synchronized相当于有两个功能,第一个是保护线程安全,第二个是获取到锁,以便进行后续的put和take操作。
修改内容3:我们想想,wait那里的if操作合理吗?比如,在put中,有没有可能我们wait完后,if (size == items.length)这个判断队满的判断还是成立的?在我们的这个代码里是没有问题的,因为你的put里面的wait被唤醒,肯定是take里的notify操作了,说明有元素出队,那就必定可以唤醒put,然后再插入元素了。
但是呢,其它代码有些情况下可能会出现我们上述所说的问题。所以呢,我们最好的操作是:把if改成while,确保wait被唤醒后继续去判断。

二、生产者消费者模型
1、什么是生产者消费者模型
在开发中:代码的某个模块负责生产数据(供货商),而生产出来的数据却不得不交给另一模块(消费者)来对其进行处理,在这之间我们必须要有一个类似上述超市的东西来存储数据(超市),这就抽象除了我们的生产者/消费者模型。
其中:
生产者:产生数据的模块,就形象地称为生产者;
消费者:而处理数据的模块,就称为消费者;
缓冲区 (阻塞队列):生产者和消费者之间的中介就叫做缓冲区。
2、为什么要用生产者消费者模型
利用阻塞队列可以实现一个生产者消费者模型。
生产者消费者模型的优点:
1>
解耦
2>削峰填谷
第一个优点解耦,通俗来讲,就是降低生产者和消费者之间的联系。如果不使用生产者消费者模型,我们来看看下面这个图:
当用户发送一个请求时,A作为中间处理,然后把请求发给B再让B去处理结果,然后如果有个日志需要记录,那也从A中发送过去,再传回A,最后由A响应给用户。那么问题来了,如果B出错了,那整个项目都崩了,因为要从A传过去的数据B不能即使把结果返回给A,就会导致各自数据丢失等待问题;如果A出错了,更严重,相当于用户发送的请求直接消失不见了,B无法收到A发过来的要处理的信息,日志也无法记录当前信息。

那么怎么解决?生产者消费者模型就可以解决这样的问题:
在下图中,阻塞队列1存放请求,阻塞队列2存放响应。阻塞队列1队满时,A就先阻塞,等B先出队;当阻塞队列1队空时,B先阻塞,等A先入队。阻塞队列2也是一样的分析。而日志可以直接从阻塞队列1中取出消息进行记录。这样A的操作不直接依赖于B,B的操作也不直接依赖于A,即此时A不知道B的存在,B也不知道A的存在。日志也是一样的道理。所以二者之间的联系就降低了,所以达到解耦的效果。

生产者消费者模型第二个优点是削峰填谷,这样可以使系统更加稳定。因为你想,阻塞队列有阻塞效果,如果put过多,就先阻塞一下,让take取走元素后,再进行继续put就达到了削峰的作用;而填谷就是队空时,你想take出队得先等,put后才能继续出队,达到填谷的效果。
3、利用自定义阻塞队列实现生产者消费者模型
// 阻塞队列
class MyBlockingQueue {
private int[] items = new int[100];
private int head = 0;
private int tail = 0;
private int size = 0;
public void put(int val) throws InterruptedException {
synchronized (this){
while (size == items.length){
// 队列满时wait,等待先take()元素出队后才能继续执行入队元素
this.wait();
}
items[tail] = val;
tail++;
size++;
// tail = tail % items.length;
if(tail == items.length){ // 上面的取模操作和这一步操作功能一样,但是这里的比较比取模效率高,且代码可读性更高。
tail = 0;
}
// 唤醒take中队空时的wait操作
this.notify();
}
}
public Integer take() throws InterruptedException {
int result = 0;
synchronized (this) {
while (size == 0) {
// 队列空时wait,等待先put()入队元素后才能继续执行出队元素
this.wait();
}
result = items[head];
head++;
size--;
if (head == items.length) {
head = 0;
}
// 唤醒put中队满时的wait操作
this.notify();
}
return result;
}
}
// 生产者消费者模型代码
public class Main {
public static void main(String[] args){
MyBlockingQueue queue = new MyBlockingQueue();
// 消费者
Thread costumer = new Thread(()->{
while (true){
try {
int result = queue.take();
System.out.println("消费元素:" + result);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 加sleep便于观察运行时具体情况
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// 生产者
Thread producer = new Thread(()->{
int count = 0;
while (true) {
try {
count++;
queue.put(count);
System.out.println("生产元素:" + count);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
costumer.start();
System.out.println("Ok");
}
}
我们来分析这个生产者消费者模型的代码。在最开始我们new了一个我们自定义实现的阻塞队列的对象。然后定义两个线程,一个是生产者一个是消费者。
在生产者中,我们定义了一个局部变量count作为生产的元素,要放在循环外面,然后使用阻塞队列的put方法入队元素,当元素放满时阻塞。
在消费者中,使用阻塞队列的take方法出队元素,进行元素消费。当元素空时阻塞。

在上面的代码中,程序执行速度是极快的,我们的阻塞队列数组象征性的只给了100个空间,那么由于我们在消费者这里加上了Thread.sleep(1000),在这个例子中,生产者会先生产,生产完100个,就阻塞wait等待消费元素后把生产者唤醒。然后就是生产一个,消费一个的情况,你可以把代码拿去复制粘贴试试。