PCIE基本概念
1. PCIe总线基本概念
PCIe采用全双工的传输设计,即允许在同一时刻,同时进行发送和接收数据。如下图所示,设备A和设备B之间通过双向的Link相连接,每个Link支持1到32个通道(Lane)。由于是串行总线,因此所有的数据(包括配置信息等)都是以数据包为单位进行发送的

与绝大部分的高速连接一样,PCIe采用了差分对进行收发,以提高总线的性能。一个PCIe Lane的例子如下图所示:

除了差分总线,PCIe还引入了嵌入式时钟的技术(Embedded Clock),即发送端不再向接收端发送时钟,但是接收端可以通过8b/10b的编码从数据Lane中恢复出时钟。一个简单的时钟恢复电路模型如下图所示:
注:PCie Gen3以及之后的版本采用了128b/130b的编码方式。

PCIe相对于PCI总线的另一个大的优势是其的Scalable Performance,即可以根据应用的需要来调整PCIe设备的带宽。如需要很高的带宽,则采用多个Lane(比如显卡);如果并不需要特别高的带宽,则只需要一个Lane就可以了(比如说网卡等)。PCIe是一种点对点连接的总线,而不像PCI那样的共享总线。但是PCIe总线系统可以通过Switch连接多个PCIe设备,也可以通过PCIe桥连接传统的PCI和PCI-X设备。一个简单的PCIe总线系统的拓扑结构图如下所示:
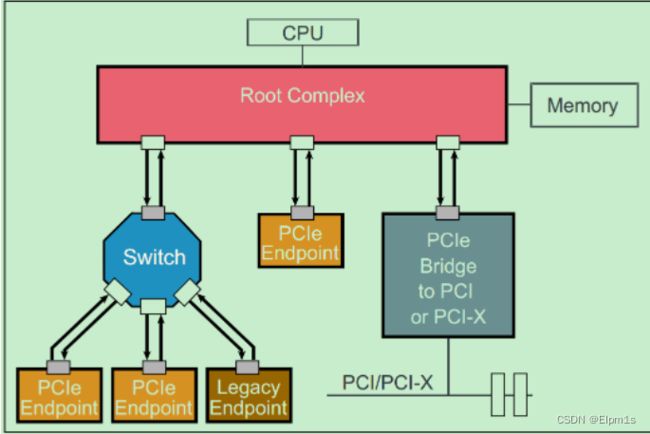
图中的Root Complex经常被称为RC或者Root。在PCIe的Spec中,并没有特别详细的关于Root Complex的定义,从实际的角度来讲,可以把Root Complex理解为CPU与PCIe总线系统通信的媒介。Endpoint处于PCIe总线系统拓扑结构中的最末端,一般作为总线操作的发起者(initiator,类似于PCI总线中的主机)或者终结者(Completers,类似于PCI总线中的从机)。显然,Endpoint只能接受来自上级拓扑的数据包或者向上级拓扑发送数据包。
所谓Lagacy PCIe Endpoint是指那些原本准备设计为PCI-X总线接口的设备,但是却被改为PCIe接口的设备。而Native PCIe Endpoint则是标准的PCIe设备。其中,Lagacy PCIe Endpoint可以使用一些在Native PCIe Endpoint禁止使用的操作,如IO Space和Locked Request等。Native PCIe Endpoint则全部通过Memory Map来进行操作,因此,Native PCIe Endpoint也被称为Memory Mapped Devices(MMIO Devices)。
2. PCIe总线体系结构
一个完整的PCIe体系结构包括应用层、事务层(Transaction Layer)、数据链路层(Data Link Layer)和物理层(Physical Layer)。其中,应用层并不是PCIe Spec所规定的内容,完全由用户根据自己的需求进行设计,另外三层都是PCIe Spec明确规范的,并要求设计者严格遵循的。

一个简化的PCIe总线体系结构如上图所示,其中Device Core and interface to Transaction Layer就是我们常说的应用层或者软件层。这一层决定了PCIe设备的类型和基础功能,可以由硬件(如FPGA)或者软硬件协同实现。如果该设备为Endpoint,则其最多可拥有8项功能(Function),且每项功能都有一个对应的配置空间(Configuration Space)。如果该设备为Switch,则应用层需要实现包路由(Packet Routing)等相关逻辑。如果该设备为Root,则应用层需要实现虚拟的PCIe总线0(Virtual PCIe Bus 0),并代表整个PCIe总线系统与CPU通信。
3. 常用概念
3.1 BDF
每一个PCIe设备可以只有一个功能(Function),即Fun0。也可以拥有最多8个功能,即多功能设备(Multi-Fun)。不管这个PCIe设备拥有多少个功能,其每一个功能都有一个唯一独立的配置空间(Configuration Space)与之对应。
和PCI总线一样,PCIe总线中的每一个功能(Function)都有一个唯一的标识符与之对应。这个标识符就是BDF(Bus,Device,Function),PCIe的配置软件(即Root的应用层,一般是PC)应当有能力识别整个PCIe总线系统的拓扑逻辑,以及其中的每一条总线(Bus),每一个设备(Device)和每一项功能(Function)。
在BDF中,Bus Number占用8位,Device Number占用5位,Function Number占用3位。显然,PCIe总线最多支持256个子总线,每个子总线最多支持32个设备,每个设备最多支持8个功能。
PCIe总线采用的是一种深度优先(Depth First Search)的拓扑算法,且Bus0总是分配给Root Complex。Root中包含有集成的Endpoint和多个端口(Port),每个端口内部都有一个虚拟的PCI-to-PCI桥(P2P),并且这个桥也应有设备号和功能号。
需要注意的是,每个设备必须要有功能0(Fun0),其他的7个功能(Fun1~Fun7)都是可选的。
一个简单的例子如下图所示:

3.2 BAR
基地址寄存器(BAR)在配置空间(Configuration Space)中的位置如下图所示:
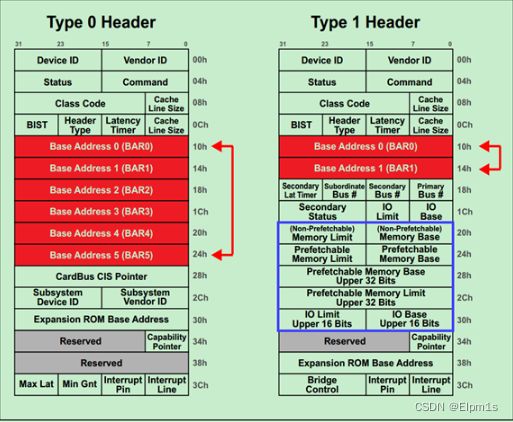
其中Type0 Header最多有6个BAR,而Type1 Header最多有两个BAR。这就意味着,对于Endpoint来说,最多可以拥有6个不同的地址空间。但是实际应用中基本上不会用到6个,通常1~3个BAR比较常见。
主要注意的是,如果某个设备的BAR没有被全部使用,则对应的BAR应被硬件全被设置为0,并且告知软件这些BAR是不可以操作的。对于被使用的BAR来说,其部分低比特位是不可以被软件操作的,只有其高比特位才可以被软件操作。而这些不可操作的低比特决定了当前BAR支持的操作类型和可申请的地址空间的大小。
一旦BAR的值确定了(Have been programmed),其指定范围内的当前设备中的内部寄存器(或内部存储空间)就可以被访问了。当该设备确认某一个请求(Request)中的地址在自己的BAR的范围内,便会接受这请求。
3.3 中断传递方式(INTx、MSI/MSI-X)
PCI总线最早采用的中断机制是INTx,这是基于边带信号的。后续的PCI/PCI-X版本,为了消除边带信号,降低系统的硬件设计复杂度,逐渐采用了MSI/MSI-X(消息信号中断)的中断机制。
INTx一般被称为传统的(Legacy)PCI中断机制,每个PCI设备最多支持四个中断信号(边带信号,INTA#、INTB#、INTC#和INTD#)。一个简单的例子如下图所示:
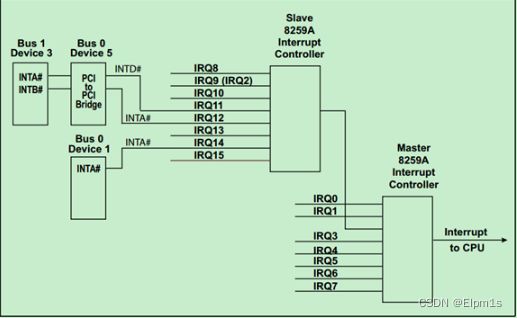
MSI/MSI-X是后续的PCI/PCI-X总线改进后的中断机制,其中MSI-X(MSI-eXtented)是PCI-X中提出的升级版本。需要特别注意的是,MSI/MSI-X与PCIe总线中的消息(Message)的概念完全不同!MSI/MSI-X本质上是一种Posted Memory Write。
一个简单的例子如下图所示:
