谷歌、苹果、亚马逊等大厂技术面试真题
技术面试题是许多顶尖科技公司面试的主要内容,其中一些难题会令许多面试者望而却步,但其实这些题是有合理的解决方法的。
7.1 准备事项
多数求职者只是通读一遍问题和解法,囫囵吞枣。这好比试图单凭看问题和解法就想学会微积分。你得动手练习如何解题,单靠死记硬背效果不彰。
就本书的面试题以及你可能遇到的其他题目,请参照以下几个步骤。
(1) 尽量独立解题。本书后面有一些提示可供参考,但请尽量不要依赖提示解决问题。许多题目确实难乎其难,但是没关系,不要怕!此外,解题时还要考虑空间和时间效率。
(2) 在纸上写代码。在电脑上编程可以享受到语法高亮、代码完整、调试快速等种种好处,在纸上写代码则不然。通过在纸上多多实践来适应这种情况,并对在纸上编写、编辑代码之缓慢习以为常。
(3) 在纸上测试代码。就是要在纸上写下一般用例、基本用例和错误用例等。面试中就得这么做,因此最好提前做好准备。
(4) 将代码照原样输入计算机。你也许会犯一大堆错误。请整理一份清单,罗列自己犯过的所有错误,这样在真正面试时才能牢记在心。
此外,尽量多做模拟面试。你和朋友可以轮流给对方做模拟面试。虽然你的朋友不见得受过什么专业训练,但至少能带你过一遍代码或者算法面试题。你也会在当面试官的体验中,受益良多。
7.2 必备的基础知识
许多公司关注数据结构和算法面试题,并不是要测试面试者的基础知识。然而,这些公司却默认面试者已具备相关的基础知识。
7.2.1 核心数据结构、算法及概念
大多数面试官都不会问你二叉树平衡的具体算法或其他复杂算法。老实说,离开学校这么多年,恐怕他们自己也记不清这些算法了。
一般来说,你只要掌握基本知识即可。下面这份清单列出了必须掌握的知识。
数据结构 |
算法 |
概念 |
|---|---|---|
链表 |
广度优先搜索 |
位操作 |
树、单词查找树、图 |
深度优先搜索 |
内存(堆和栈) |
栈和队列 |
二分查找 |
递归 |
堆 |
归并排序 |
动态规划 |
向量/数组列表 |
快排 |
大 |
散列表 |
|
|
对于上述各项题目,务必掌握它们的具体用法、实现方法、应用场景以及空间和时间复杂度。
一种不错的方法就是练习如何实现数据结构和算法(先在纸上,然后在电脑上)。你会在这个过程中学到数据结构内部是如何工作的,这对很多面试而言都是不可或缺的。
你错过上面那段了吗?千万不要错过,这非常重要。如果对上面列出的某个数据结构和算法感觉不能运用自如,就从头开始练习吧。
其中,散列表是必不可少的一个题目。对这个数据结构,务必要胸有成竹。
7.2.2 2的幂表
下面这张表会在很多涉及可扩展性或者内存排序限制等问题上助你一臂之力。尽管不强求你记下来,可是记住总会有用。你至少应该轻车熟路。
2的幂 |
准确值(X) |
近似值 |
X字节转换成MB、GB等 |
|---|---|---|---|
7 |
128 |
|
|
8 |
256 |
|
|
10 |
1024 |
一千 |
1 K |
16 |
65 536 |
|
64 K |
20 |
1 048 576 |
一百万 |
1 MB |
30 |
1 073 741 824 |
十亿 |
1 GB |
32 |
4 294 967 296 |
|
4 GB |
40 |
1 099 511 627 776 |
一万亿 |
1 TB |
这张表可以拿来做速算。例如,一个将每个32位整数映射成布尔值的向量表可以在一台普通计算机内存中放下。那样的整数有![]() 个。因为每个整数只占位向量表中的一位,共需要
个。因为每个整数只占位向量表中的一位,共需要![]() 位(或者
位(或者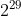 字节)来存储该映射表,大约是千兆字节的一半,普通机器很容易满足。
字节)来存储该映射表,大约是千兆字节的一半,普通机器很容易满足。
在接受互联网公司的电话面试时,不妨把表放在眼前,也许能派上用场。
7.3 解题步骤
下面的流程图将教你如何逐步解决一个问题。要学以致用。你可以从CrackingTheCodingInterview.com下载这个提纲及更多内容。

接下来我会详述该流程图。
面试期待
面试本就困难。如果你无法立刻得出答案,那也没有关系,这很正常,并不代表什么。
注意听面试官的提示。面试官有时热情洋溢,有时却意兴阑珊。面试官参与程度取决于你的表现、问题的难度以及该面试官的期待和个性。
当你被问到一个问题或者当你在练习时,按下面的步骤完成解题。
7.3.1.1 认真听
也许你以前听过这个常规性建议:确保听清楚题。但我给你的建议不止这一点。
当然了,你首先要保证听清题,其次弄清楚模棱两可的地方。
但是我要说的不止如此。
举个例子,假设一个问题以下列其中一个话题作为开头,那么可以合理地认为它给出的所有信息都并非平白无故的。
“有两个排序的数组,找到……”
你很可能需要注意到数据是有序的。数据是否有序会导致最优算法大相径庭。
“设计一个在服务器上经常运行的算法……”
在服务器上/重复运行不同于只运行一次的算法。也许这意味你可以缓存数据,或者意味着你可以顺理成章地对数据集进行预处理。
如果信息对算法没影响,那么面试官不大可能(尽管也不无可能)把它给你。
很多求职者都能准确听清问题。但是开发算法的时间只有短短的十来分钟,以至于解决问题的一些关键细节被忽略了。这样一来无论怎样都无法优化问题了。
你的第一版算法确实不需要这些信息。但是如果你陷入瓶颈或者想寻找更优方案,就回头看看有没有错过什么。
即使把相关信息写在白板上也会对你大有裨益。
7.3.1.2 画个例图
画个例图能显著提高你的解题能力,尽管如此,还有如此多的求职者只是试图在脑海中解决问题。
当你听到一道题时,离开椅子去白板上画个例图。
不过画例图是有技巧的。首先你需要一个好例子。
通常情况下,以一棵二叉搜索树为例,求职者可能会画如下例图。

这是个很糟糕的例子。第一,太小,不容易寻找模式。第二,不够具体,二叉搜索树有值。如果那些数字可以帮助你处理这个问题怎么办?第三,这实际上是个特殊情况。它不仅是个平衡树,也是个漂亮、完美的树,其每个非叶节点都有两个子节点。特殊情况极具欺骗性,对解题无益。
实际上,你需要设计一个这样的例子。
- 具体。应使用真实的数字或字符串(如果适用的话)。
- 足够大。一般的例子都太小了,要加大0.5倍。
- 具有普适性。请务必谨慎,很容易不经意间就画成特殊的情况。如果你的例子有任何特殊情况(尽管你觉得它可能不是什么大事),也应该解决这一问题。
尽力做出最好的例子。如果后面发现你的例子不那么正确,你应该修复它。
7.3.1.3 给出一个蛮力法
一旦完成了例子(其实,你也可以在某些问题中调换7.3.1.2步和7.3.1.3步的顺序),就给出一个蛮力法。你的初始算法不怎么好也没有关系,这很正常。
一些求职者不想给出蛮力法,是因为他们认为此方法不仅显而易见而且糟糕透顶。但是事实是:即使对你来说轻而易举,也未必对所有求职者来说都这样。你不会想让面试官认为,即使解出这一简单算法对你来说也得绞尽脑汁。
初始解法很糟糕,这很正常,不必介怀。先说明该解法的空间和时间复杂度,再开始优化。
7.3.1.4 优化
你一旦有了蛮力法,就应该努力优化该方法。以下技巧就有了用武之地。
(1) 寻找未使用的信息。你的面试官告诉过你数组是有序的吗?你如何利用这些信息?
(2) 换个新例子。很多时候,换个不同的例子会让你思路畅通,看到问题模式所在。
(3) 尝试错误解法。低效的例子能帮你看清优化的方法,一个错误的解法可能会帮助你找到正确的方法。比方说,如果让你从一个所有值可能都相等的集合中生成一个随机值。一个错误的方法可能是直接返回半随机值。可以返回任何值,但是可能某些值概率更大,进而思考为什么解决方案不是完美随机值。你能调整概率吗?
(4) 权衡时间、空间。有时存储额外的问题相关数据可能对优化运行时间有益。
(5) 预处理信息。有办法重新组织数据(排序等)或者预先计算一些有助于节省时间的值吗?
(6) 使用散列表。散列表在面试题中用途广泛,你应该第一个想到它。
(7) 考虑可想象的极限运行时间(详见7.9节)。
在蛮力法基础上试试这些技巧,寻找BUD的优化点。
7.3.1.5 梳理
明确了最佳算法后,不要急于写代码。花点时间巩固对该算法的理解。
白板编程很慢,慢得超乎想象。测试、修复亦如此。因此,要尽可能地在一开始就确保思路近乎完美。
梳理你的算法,以了解它需要什么样的结构,有什么变量,何时发生改变。
伪代码是什么?如果你更愿意写伪代码,没有问题。但是写的时候要当心。基本的步骤((1) 访问数组。(2) 找最大值。(3) 堆插入。)或者简明的逻辑(if
p < q, movep. else moveq.)值得一试。但是如果你用简单的词语代表for循环,基本上这段代码就烂透了,除了代码写得快之外一无是处。
你如果没有彻底理解要写什么,就会在编程时举步维艰,这会导致你用更长的时间才能完成,并且更容易犯大错。
7.3.1.6 实现
这下你已经有了一个最优算法并且对所有细节都了如指掌,接下来就是实现算法了。
写代码时要从白板的左上角(要省着点空间)开始。代码尽量沿水平方向写(不要写成一条斜线),否则会乱作一团,并且像Python那样对空格敏感的语言来说,读起来会云里雾里,令人困惑。
切记:你只能写一小段代码来证明自己是个优秀的开发人员。因此,每行代码都至关重要,一定要写得漂亮。
写出漂亮代码意味着你要做到以下几点。
- 模块化的代码。这展现了良好的代码风格,也会使你解题更为顺畅。如果你的算法需要使用一个初始化的矩阵,例如
{{1, 2, 3}, {4, 5, 6}, ...},不要浪费时间去写初始化的代码。可以假装自己有个函数initIncrementalMatrix(int size),稍后需要时再回头写完它。 - 错误检查。有些面试官很看重这个,但有些对此并不“感冒”。一个好办法是在这里加上
todo,这样只需解释清楚你想测试什么就可以了。 - 使用恰到好处的类、结构体。如果需要在函数中返回一个始末点的列表,可以通过二维数组来实现。当然,更好的办法是把
StartEndPair(或者Range)对象当作list返回。你不需要去把这个类写完,大可假设有这样一个类,后面如果有富裕时间再补充细节即可。 - 好的变量名。到处使用单字母变量的代码不易读取。这并不是说在恰当场合(比如一个遍历数组的普通
for循环)使用i和j就不对。但是,使用i和j时要多加小心。如果写了类似于int i = startOfChild(array)的变量名称,可能还可以使用更好的名称,比如startChild。
然而,长的变量名写起来也会比较慢。你可以除第一次以外都用缩写,多数面试官都能同意。比方说你第一次可以使用startChild,然后告诉面试官后面你会将其缩写为sc。
评价代码好坏的标准因面试官、求职者、题目的不同而有所变化。所以只要专心写出一手漂亮的代码即可,尽人事、知天命。
如果发现某些地方需要稍后重构,就和面试官商量一下,看是否值得花时间重构。通常都会得到肯定答复,偶尔不是。
如果觉得一头雾水(这很常见),就再回头过一遍。
7.3.1.7 测试
在现实中,不经过测试就不会签入代码;在面试中,未经过测试同样不要“提交”。
测试代码有两种办法:一种聪明的,一种不那么聪明的。
许多求职者会用最开始的例子来测试代码。那样做可能会发现一些bug,但同样会花很长时间。手动测试很慢。如果设计算法时真的使用了一个大而好的例子,那么测试时间就会很长,但最后可能只在代码末尾发现一些小问题。
你应该尝试以下方法。
(1) 从概念测试着手。概念测试就是阅读和分析代码的每一行。像代码评审那样思考,在心中解释每一行代码的含义。
(2) 跳着看代码。重点检查类似x = length-2的行。对于for循环,要尤为注意初始化的地方,比如i = 1。当你真的去检查时,就很容易发现小错误。
(3) 热点代码。如果你编程经验足够丰富的话,就会知道哪些地方可能出错。递归中的基线条件、整数除法、二叉树中的空节点、链表迭代中的开始和结束,这些要反复检查才行。
(4) 短小精悍的用例。接下来开始尝试测试代码,使用真实、具体的用例。不要使用大而全的例子,比如前面用来开发算法的8元素数组,只需要使用3到4个元素的数组就够了。这样也可以发现相同的bug,但比大的快多了。
(5) 特殊用例。用空值、单个元素、极端情况和其他特殊情况检测代码。
发现了bug(很可能会)就要修复。但注意不要贸然修改。仔细斟酌,找出问题所在,找到最佳的修改方案,只有这样才能动手。
7.4 优化和解题技巧 1:寻找BUD
这也许是我找到的优化问题最有效的方法了。BUD是以下词语的首字母缩写:
- 瓶颈(bottleneck);
- 无用功 (unnecessary work);
- 重复性工作 (duplicated work)。
以上是最常见的3个问题,而面试者在优化算法时往往会浪费时间于此。你可以在蛮力法中找找它们的影子。发现一个后,就可以集中精力来解决。
如果这样仍没有得到最佳算法,也可以在当前最好的算法中找找这3类优化点。
7.4.1 瓶颈
瓶颈就是算法中拖慢整体运行时间的某部分。通常会以两种方式出现。
一次性的工作会拖累整个算法。例如,假设你的算法分为两步,第一步是排序整个数组,第二步是根据属性找到特定元素。第一步是![]() ,第二步是
,第二步是![]() 。尽管可以把第二步时间优化到
。尽管可以把第二步时间优化到![]() 甚至
甚至![]() ,但那又有什么用呢?聊胜于无而已。它不是当务之急,因为
,但那又有什么用呢?聊胜于无而已。它不是当务之急,因为![]() 才是瓶颈。除非优化第一步,否则你的算法整体上一直是
才是瓶颈。除非优化第一步,否则你的算法整体上一直是![]() 。
。
你有一块工作不断重复,比如搜索。也许你可以把它从![]() 降到
降到![]() 甚至
甚至![]() 。这样就大大加快了整体运行时间。
。这样就大大加快了整体运行时间。
优化瓶颈,对整体运行时间的影响是立竿见影的。
举个例子:有一个值都不相同的整数数组,计算两个数差值为
的对数。例如,数组
{1, 7, 5, 9, 2, 12, 3},差值
用蛮力法就是遍历数组,从第一个元素开始搜索剩下的元素(即一对中的另一个)。对于每一对,计算差值。如果差值等于,计数加一。
该算法的瓶颈在于重复搜索对数中的另一个。因此,这是接下来优化的重点。
怎么才能更快地找到正确的另一个?已知![]() 的另一个,即
的另一个,即 ![]() 或
或![]() 。如果把数组排序,就可以用二分查找来找到另一个,
。如果把数组排序,就可以用二分查找来找到另一个,![]() 个元素的话查找的时间就是
个元素的话查找的时间就是![]() 。
。
现在,将算法分为两步,每一步都用时![]() 。接下来,排序构成新的瓶颈。优化第二步于事无补,因为第一步已经拖慢了整体运行时间。
。接下来,排序构成新的瓶颈。优化第二步于事无补,因为第一步已经拖慢了整体运行时间。
必须完全丢弃第一步排序数组,只使用未排序的数组。那如何在未排序的数组中快速查找呢?借助散列表吧。
把数组中所有元素都放到散列表中。然后判断![]() 或者
或者![]() 是否存在。只是过一遍散列表,用时为
是否存在。只是过一遍散列表,用时为![]() 。
。
7.4.2 无用功
举个例子:打印满足
的所有正整数解,其中
、
、
、
是1至1000间的整数。
用蛮力法来解会有四重for循环,如下:
1. n = 1000 2. for a from 1 to n 3. for b from 1 to n 4. for c from 1 to n 5. for d from 1 to n 6. if a3 + b3 == c3 + d3 7. print a, b, c, d
用上面算法迭代、![]() 、
、![]() 、
、![]() 所有可能,然后检测是否满足上述表达式。
所有可能,然后检测是否满足上述表达式。
在找到一个可行解后,就不用继续检查![]() 的其他值了。因为
的其他值了。因为![]() 的一次循环中只有一个值能满足。所以一旦找到可行解至少应该跳出循环。
的一次循环中只有一个值能满足。所以一旦找到可行解至少应该跳出循环。
1. n = 1000 2. for a from 1 to n 3. for b from 1 to n 4. for c from 1 to n 5. for d from 1 to n 6. if a3 + b3 = c3 + d3 7. print a, b, c, d 8. break // 跳出d循环
虽然该优化对运行时间并无改变,运行时间仍是![]() ,但仍值得一试。
,但仍值得一试。
还有其他无用功吗?答案是肯定的,对于每个 ![]() ,都可以通过
,都可以通过![]() 这个简单公式得到
这个简单公式得到![]() 。
。
1. n = 1000 2. for a from 1 to n 3. for b from 1 to n 4. for c from 1 to n 5. d = pow(a3 + b3 - c3, 1/3) // 取整成int 6. if a3 + b3 == c3 + d3 && 0 <= d && d <= n // 验证结果 7. print a, b, c, d
第6行的if语句至关重要,因为第5行每次都会找到一个![]() 的值,但是需要检查是否是正确的整数值。
的值,但是需要检查是否是正确的整数值。
这样一来,运行时间就从![]() 降到了
降到了![]() 。
。
7.4.3 重复性工作
沿用上述问题及蛮力法,这次来找一找有哪些重复性工作。
这个算法本质上遍历所有![]() 对的可能性,然后寻找所有
对的可能性,然后寻找所有![]() 对的可能性,找到和
对的可能性,找到和![]() 对匹配的对。
对匹配的对。
为什么对于每一对![]() 都要计算所有
都要计算所有![]() 对的可能性?只需一次性创建一个
对的可能性?只需一次性创建一个![]() 对列表,然后对于每个
对列表,然后对于每个![]() 对,都去
对,都去![]() 列表中寻找匹配。想要快速定位
列表中寻找匹配。想要快速定位![]() 对,对
对,对![]() 列表中每个元素,都可以把
列表中每个元素,都可以把![]() 对的和当作键,
对的和当作键,![]() 当作值(或者满足那个和的对列表)插入到散列表。
当作值(或者满足那个和的对列表)插入到散列表。
1. n = 1000 2. for c from 1 to n 3. for d from 1 to n 4. result = c3 + d3 5. append (c, d) to list at value map[result] 6. for a from 1 to n 7. for b from 1 to n 8. result = a3 + b3 9. list = map.get(result) 10. for each pair in list 11. print a, b, pair
实际上,已经有了所有![]() 对的散列表,大可直接使用。不需要再去生成
对的散列表,大可直接使用。不需要再去生成![]() 对。每个
对。每个![]() 都已在散列表中。
都已在散列表中。
1. n = 1000
2. for c from 1 to n
3. for d from 1 to n
4. result = c3 + d3
5. append (c, d) to list at value map[result]
6.
7. for each result, list in map
8. for each pair1 in list
9. for each pair2 in list
10. print pair1, pair2它的运行时间是![]() 。
。
7.5 优化和解题技巧 2:亲力亲为
第一次遇到如何在排序的数组中寻找某个元素(习得二分查找之前),你可能不会一下子想到:“啊哈!我们可以比较中间值和目标值,然后在剩下的一半中递归这个过程。”
然而,如果让一些没有计算机科学背景的人在一堆按字母表排序的论文中寻找指定论文,他们可能会用到类似于二分查找的方式。他们估计会说:“天哪,Peter Smith?可能在这堆论文的下面。”然后随机选择一个中间的(例如i,s,h开头的)论文,与Peter Smith做比较,接着在剩余的论文中继续用这个方法查找。尽管他们不知道二分查找,但可以凭直觉“做出来”。
我们的大脑很有趣。干巴巴地抛出像“设计一个算法”这样的题目,人们经常会搞得乱七八糟。但是如果给出一个实例,无论是数据(例如数组)还是现实生活中其他的类似物(例如一堆论文),他们就会凭直觉开发出一个很好的算法。
我已经无数次地看到这样的事发生在求职者身上。他们在计算机上完成的算法奇慢无比,但一旦被要求人工解决同样问题,立马干净利落地完成。
因此,当你遇到一个问题时,一个好办法是尝试在直观的真实例子上凭直觉解决它。通常越大的例子越容易。
举个例子:给定较小字符串
s和较大字符串b,设计一个算法,寻找在较大字符串中较小字符串的所有排列,打印每个排列的位置。
考虑一下你要怎么解决这道题。注意排列是字符串的重组,因此s中的字符能以任何顺序出现在b中,但是它们必须是连续的(不被其他字符隔开)。
像大多数求职者一样,你可能会这么想:先生成s的全排列,然后看它们是否在b中。全排列有![]() 种,因此运行时间是
种,因此运行时间是![]() ,其中
,其中![]() 是
是s的长度,![]() 是
是b的长度。
这样是可行的,但实在慢得太离谱了。实际上该算法比指数级的算法还要糟糕透顶。如果s有14个字符,那么会有超过870亿个全排列。s每增加一个字符,全排列就会增加15倍。天哪!
换种不同的方式,就可以轻而易举地开发出一个还不错的算法。参考如下例子:
s:abbc
b:cbabadcbbabbcbabaabccbabcb中s的全排列在哪儿?不要管如何做,找到它们就行。很简单的,12岁的小孩子都能做到!
(真的,赶紧去找,我等你。)
我已经在每个全排列下面画了线。
s: abbc
b: cbabadcbbabbcbabaabccbabc
———— ———— ————
———— ———— ————
————你找到了吗?怎么做的?
很少有人——即使之前提出![]() 算法的人——真的去生成
算法的人——真的去生成abbc的全排列,再去b中逐个寻找。几乎所有人都采用了如下两种方式(非常相似)之一。
(1) 遍历b,查看4个字符(因为s中只有4个字符)的滑动窗口。逐一检查窗口是否是s的一个全排列。
(2) 遍历b。每次发现一个字符在s中时,就去检查它往后的4个(包括它)字符是否属于s的全排列。
取决于“是否是一个全排列”的具体实现方式,你得到的运行时可能是![]() 、
、![]() 或者
或者![]() 。尽管这些都不是最优算法(包含
。尽管这些都不是最优算法(包含![]() 算法),但已经比我们之前的好太多。
算法),但已经比我们之前的好太多。
解题时,试试这个方法。使用一个大而好的例子,直观地手动解决这个特定例子。然后复盘,思考你是如何解决它的。反向设计算法。
重点留意你凭直觉或不经意间做的任何“优化”。例如,解题时你可能会跳过以d开头的窗口,因为d不在abbc中。这是你靠大脑做出的一个优化,在设计算法时也应该留意到。
7.6 优化和解题技巧 3:化繁为简
我们通过简化来实现一个由多步骤构成的方法。首先,可以简化或者调整约束,比如数据类型。这样一来,就可以解决简化后的问题了。最后,调整这个算法,让它适应更为复杂的情况。
举个例子:可以通过从杂志上剪下词语拼凑成句来完成一封邀请函。如何分辨一封邀请函(以字符串表示)是否可以从给定杂志(字符串)中获取呢?
为了简化问题,可以把从杂志上剪下词语改为剪下字符。
通过创建一个数组并计数字符串,可以解决邀请函的字符串简化版问题,其中数组中的每一位对应一个字母。首先计算每个字符在邀请函中出现的次数,然后遍历杂志查看是否能满足。
推导出这个算法,意味着我们做了类似的工作。不同的是,这次不是创建一个字符数组来计数,而是创建一个单词映射频率的散列表。
7.7 优化和解题技巧 4:由浅入深
我们可以由浅入深,首先解决一个基本情况(例如,![]() ),然后尝试从这里开始构建。遇到更复杂或者有趣的情况(通常是
),然后尝试从这里开始构建。遇到更复杂或者有趣的情况(通常是![]() 或者
或者![]() )时,尝试使用之前的方法解决。
)时,尝试使用之前的方法解决。
举个例子:设计一个算法打印出字符串的所有排列组合。简单起见,假设所有字符均不相同。
思考一个测试字符串abcdefg。
用例 "a" --> {"a"}
用例 "ab" --> {"ab", "ba"}
用例 "abc" --> ?这是第一个“有趣”的情况。如果已经有了P("ab")的答案,如何得到P("abc")的答案呢?已知可选的字母是c,因此可以在每种可能中插入c,即如下模式。
P("abc") = 把"c"插入到 P("ab")中的所有字符串的所有位置
P("abc") = 把"c"插入到{"ab","ba"}中的所有字符串的所有位置
P("abc") = 合并({"cab", "acb", "abc"}, {"cba", "bca", bac"})
P("abc") = {"cab", "acb", "abc", "cba", "bca", bac"}理解了这个模式后,就可以写个差不多的递归算法了。通过“截断末尾字符”的方式,可以生成s1...sn字符串的所有组合。做法很简单,首先生成字符串s1...sn-1的所有组合,然后遍历所有组合,每个字符串的每个位置都插入sn得到新的字符串。
这种由基础例子逐渐推导的方法通常会得到一个递归算法。
7.8 优化和解题技巧 5:数据结构头脑风暴法
这种方法很取巧但奏效。我们可以简单过一遍所有的数据结构,一个个地试。这种方法之所以有效在于,一旦数据结构(比方说树)选对了,解题可能就简单了,手到擒来。
举个例子:随机产生数字并放入(动态)数组。你怎么记录它每一步的中间值?
应用数据结构头脑风暴法的过程可能如下所示。
- 链表?可能不行。链表一般不擅长随机访问和排序数字。
- 数组?也许可以,但已经有一个数组了。你能设法保持元素的有序吗?这样可能代价巨大。可以先放一放,如果后面需要了再考虑一试。
- 二叉树?貌似可以,因为二叉树的看家本领就是排序。实际上,如果这棵二叉搜索树是完全平衡二叉搜索树的话,顶节点可能就是中间值。但要注意的是,如果数字个数是偶数,中值实际上是中间两个数的平均值,毕竟这两个数不能都在顶节点上。该算法可行,但可稍后再考虑。
- 堆?堆对于基本排序和保存最大值、最小值手到擒来。如果你有两个堆,事情就有意思了。你可以分别保存元素中大的一半和小的一半。更大的一半数据保存在最小堆,因此这较大的一半中最小的元素在根节点。而更小的一半数据保存在最大堆,所以这较小的一半中最大的元素也在根节点。有了这些数据结构,就得到了所有可能的中值元素。如果两个堆的大小不一致,则可以通过从一个堆弹出元素插入到另一个堆实现快速“平衡”。
总的来说,你解决过的问题越多,就越擅于选择出合适的数据结构。不仅如此,你的直觉还会变得更加敏锐,能判断出哪种方法最为行之有效。
7.9 可想象的极限运行时间
考虑到可想象的极限运行时间(BCR),可能对解决某些问题大有裨益。
可想象的极限运行时间,按字面意思理解就是,关于某个问题的解决,你可以想象出的运行时间的极限。你可以轻而易举地证明,BCR是无法超越的。
比方说,假设你想计算两个数组(长度分别为![]() 、
、![]() )共有元素的个数,会立马想到用时不可能超过
)共有元素的个数,会立马想到用时不可能超过![]() ,因为必须要访问每个数组中的所有元素,所以
,因为必须要访问每个数组中的所有元素,所以![]() 就是可想象的极限运行时间。
就是可想象的极限运行时间。
或者,假设你想打印数组中所有成对值。你当然明白用时不可能超过![]() ,因为有
,因为有![]() 对需要打印。
对需要打印。
不过还要注意。假设面试官要求你在一个数组中(假定所有元素均不同)找到所有和为的对。一些对可想象的极限运行时间概念一知半解的求职者可能会说BCR是![]() ,理由是不得不访问
,理由是不得不访问![]() 对。
对。
这种说法大错特错。仅仅因为你想要所有和为特定值的对,并不意味着必须访问所有对。事实上根本不需要。
可想象的极限运行时间与最佳运行时间(best case runtime)有什么关系呢?毫不相干!可想象的极限运行时间是针对一个问题而言,在很大程度上是一个输入输出的函数,和特定的算法并无关系。事实上,如果计算可想象的极限运行时间时还要考虑具体用到哪个算法,那就很可能做错了。最佳运行时间是针对具体算法(通常是一个毫无意义的值)的。
注意,可想象的极限运行时间不一定可以实现。它的意义在于告诉你用时不会超过该时间。
举例说明BCR的用法
问题:找到两个排序数组中相同元素的个数,这两个数组长度相同,且每个数组中元素都不同。
从如下这个经典例子着手,在共同元素下标注下划线。
A: 13 27 35 40 49 55 59 B: 17 35 39 40 55 58 60
解出这道题使用的是蛮力法,即对于A中的每个元素都去B中搜索。这需要花费![]() 的时间,因为对于
的时间,因为对于A中的每个元素(共![]() 个)都需要在
个)都需要在B中做![]() 的搜索。
的搜索。
BCR为![]() ,因为我们知道每个元素至少访问一次,一共
,因为我们知道每个元素至少访问一次,一共![]() 个元素。如果跳过一个元素,那么这个元素是否有相同的值会影响最后的结果。例如,如果从没有访问过
个元素。如果跳过一个元素,那么这个元素是否有相同的值会影响最后的结果。例如,如果从没有访问过B中的最后一个元素,那么把60改成59,结果就不对了。
回到正题。现在有一个![]() 的算法,我们想要更好地优化该算法,但不一定要像
的算法,我们想要更好地优化该算法,但不一定要像![]() 那样快。
那样快。
Brute Force: O(N2) Optimal Algorithm: ? BCR: O(N)
![]() 与
与![]() 之间的最优算法是什么?有许多,准确地讲,有无穷无尽。理论上可以有个算法是
之间的最优算法是什么?有许多,准确地讲,有无穷无尽。理论上可以有个算法是![]() 。然而,无论是在面试还是现实中,运行时间都不太可能是这样。
。然而,无论是在面试还是现实中,运行时间都不太可能是这样。
请记住这个问题,因为它在面试中淘汰了很多人。运行时间不是一个多选题。虽然常见的运行时间有
、
、
、
或者
,但你不该直接假设某个问题的运行时间是多少而不考虑推导的过程。事实上,当你对运行时间是多少百思不解时,不妨猜一猜。这时你最有可能遇到一个不太明显、不太常见的运行时间。也许是
,
是数组的大小,
最有可能的是,我们正努力推导出![]() 或者
或者![]() 算法。这说明什么呢?
算法。这说明什么呢?
如果当前算法的运行时间是![]() ,那么想得到
,那么想得到![]() 或者
或者![]() 可能意味着要把第二个
可能意味着要把第二个![]() 优化成
优化成![]() 或者
或者![]() 。
。
这是BCR的一大益处,我们可以通过运行时间得到关于优化方向的启示。
第二个![]() 来自于搜索。已知数组是排序的,可以用快于
来自于搜索。已知数组是排序的,可以用快于![]() 的时间在排序的数组中搜索吗?
的时间在排序的数组中搜索吗?
当然可以了,用二分查找在一个排序的数组中寻找一个元素的运行时间是![]() 。
。
现在我们把算法优化为![]() 。
。
Brute Force: O(N2) Improved Algorithm: O(N log N) Optimal Algorithm: ? BCR: O(N)
还能继续优化吗?继续优化意味着把 ![]() 缩短为
缩短为![]() 。
。
通常情况下,二分查找在排序数组中的最快运行时间是![]() 。但这次不是正常情况,我们一直在重复搜索。
。但这次不是正常情况,我们一直在重复搜索。
BCR告诉我们,解出这个算法的最快运行时间为![]() 。因此,我们所做的任何
。因此,我们所做的任何![]() 的工作都是“免费的”,不会影响到运行时间。
的工作都是“免费的”,不会影响到运行时间。
重读7.3.1节关于优化的技巧,是否有一些可以派上用场呢?
一个技巧是预计算或者预处理。任何![]() 时间内的预处理都是“免费的”。这不会影响运行时间。
时间内的预处理都是“免费的”。这不会影响运行时间。
这又是BCR的一大益处。任何你所做的不超过或者等于BCR的工作都是“免费的”,从这个意义上来说,对运行时间并无影响。你可能最终会将此剔除,但是目前不是当务之急。
重中之重仍在于将搜索由![]() 减少为
减少为![]() 。任何
。任何![]() 或者不超过
或者不超过![]() 时间内的预计算都是“免费的”。
时间内的预计算都是“免费的”。
因此,可以把B中所有数据都放入散列表,它的运行时间是![]() ,然后只需要遍历
,然后只需要遍历A,查看每个元素是否在散列表中。查找(搜索)时间是![]() ,所以总的运行时间是
,所以总的运行时间是![]() 。
。
假设面试官问了一个让我们坐立不安的问题:还能继续优化吗?
答案是不可以,这里指运行时间。我们已经实现了最快的运行时间,因此没办法继续优化大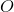 时间,倒可以尝试优化空间复杂度。
时间,倒可以尝试优化空间复杂度。
这是BCR的另一大益处。它告诉我们运行时间优化的极限,我们到这儿就该调转枪头,开始优化空间复杂度了。
事实上,就算面试官不主动要求,我们也应该对算法抱有疑问。就算不存储数据,也可以精确地获得相同的运行时间。那么为什么面试官给出了排序的数组?并非不寻常,只是有些奇怪罢了。
回到我们的例子:
A: 13 27 35 40 49 55 59 B: 17 35 39 40 55 58 60
要找有如下特征的算法。
- 占用空间为
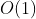 (或许是)。现在已经有了空间为、时间最优的算法。如果想使用更少的其他空间,这可能意味着没有其他空间。因此,得丢弃散列表。
(或许是)。现在已经有了空间为、时间最优的算法。如果想使用更少的其他空间,这可能意味着没有其他空间。因此,得丢弃散列表。 - 占用时间为(或许是)。我们期望最少也要和当前的一样,该时间是最优时间,不可超越。
- 使用给定的条件,数组有序。
不使用其他空间的最佳算法是二分查找。想一想怎么优化它。试着过一遍整个算法。
(1) 用二分查找在B中找 A[0] = 13。没找到。
(2) 用二分查找在B中找 A[1] = 27。没找到。
(3) 用二分查找在B中找 A[2] = 35。在B[1]中找到。
(4) 用二分查找在B中找 A[3] = 40。在B[5]中找到。
(5) 用二分查找在B中找 A[4] = 49。没找到。
(6) ……
想想BUD。搜索是瓶颈。整个过程有多余或者重复性工作吗?
搜索A[3] = 40不需要搜索整个B。在B[1]中已找到35,所以40不可能在35前面。
每次二分查找都应该从上次终止点的左边开始。
实际上,根本不需要二分查找,大可直接借助线性搜索。只要在B中的线性搜索每次都从上次终止的左边出发,就知道将要用线性时间进行搜索。
(1) 在B中线性搜索 A[0] = 13,开始于 B[0] = 17,结束于 B[0] = 17。未找到。
(2) 在B中线性搜索 A[1] = 27,开始于 B[0] = 17,结束于 B[1] = 35。未找到。
(3) 在B中线性搜索 A[2] = 35,开始于 B[1] = 35,结束于 B[1] = 35。找到。
(4) 在B中线性搜索 A[3] = 40,开始于 B[2] = 39,结束于 B[3] = 40。找到。
(5) 在B中线性搜索 A[4] = 49,开始于 B[3] = 40,结束于 B[4] = 55。找到。
(6) ……
以上算法与合并排序数组如出一辙。该算法的运行时间为![]() ,空间为
,空间为![]() 。
。
现在同时达到了BCR和最小的空间占用,这已经是极限了。
这是另一个使用BCR的方式。如果达到了BCR并且其他空间为
BCR不是一个真正的算法概念,也无法在算法教材中找到其身影。但我个人觉得其大有用处,不管是在我自己解题时,还是在指导别人解题时。
如果很难掌握它,先确保你已经理解了大时间的概念。你要做到运用自如。一旦你掌握了,弄懂BCR不过是小菜一碟。
7.10 处理错误答案
流传最广、危害最大的谣言就是,求职者必须答对每个问题。这种说法并不全对。
首先,面试的回答不应该简单分为“对”或“不对”。当我评价一个人在面试中的表现时,从不会想:“他答对了多少题?”评价不是非黑即白。相反地,评价应该基于最终解法有多理想,解题花了多长时间,需要多少提示,代码有多干净。这些才是关键。
其次,评价面试表现时,要和其他的候选人做对比。例如,如果你优化一个问题需要15分钟,别人解决一个更容易的问题只需要5分钟,那么他就比你表现好吗?也许是,也许不是。如果给你一个显而易见的问题,面试官可能会希望你干净利落地给出最优解法。但是如果是难题,那么犯些错也是在意料之中的。
最后,许多或者绝大多数的问题都不简单,就算一个出类拔萃的求职者也很难立刻给出最优算法。通常来说,对于我提出的一些问题,厉害的求职者也要20到30分钟才能解出。
我在谷歌评估过成千上万份求职者的信息,也只看到过一个求职者完美无缺地通过了面试。其他人,包括收到录用通知的人,都或多或少犯过错。
7.11 做过的面试题
如果你曾见过某个面试题,要提前说明。面试官问你这些问题是为了评估你解决问题的能力。如果你已经知道某个题的答案了,他们就无法准确无误地评估你的水平了。
此外,如果你对自己见过这道题讳莫如深,面试官还可能会发现你为人不诚实。反过来说,如果你坦白了这一点,就会给面试官留下诚实的好印象。
7.12 面试的“完美”语言
在很多顶级公司,面试官并不在乎你用什么语言。相比之下,他们更在乎你解决问题的能力。
不过,也有些公司比较关注某种语言,乐于看到你是如何得心应手地使用该语言编写代码的。
如果你可以任意选择语言的话,就选最为得心应手的。
话虽如此,如果你擅长几种语言,就将以下几点牢记于心。
7.12.1 流行度
这一点不强求。但是若面试官知道你所使用的语言,可能是最为理想的。从这点上讲,更流行的语言可能更为合适。
7.12.2 语言可读性
即使面试官不知道你所用的语言,他们也希望能对该语言有个大致了解。一些语言的可读性天生就优于其他语言,因为它们与其他语言有相似之处。
举个例子,Java很容易理解,即使没有用过它的人也能看懂。绝大多数人都用过与Java语法类似的语言,比如C和C++。
然而,像Scala和Objective C这样的语言,其语法就大不相同了。
7.12.3 潜在问题
使用某些语言会带来潜在的问题。例如,使用C++就意味着除了代码中常见的bug,还存在内存管理和指针的问题。
7.12.4 冗长
有些语言更为冗长烦琐。Java就是一个例子,与Python相比,该语言极为烦琐。通过比较以下代码就一目了然了。
Python:
1. dict = {"left": 1, "right": 2, "top": 3, "bottom": 4};Java:
1. HashMap dict = new HashMap().
2. dict.put("left", 1);
3. dict.put("right", 2);
4. dict.put("top", 3);
5. dict.put("bottom", 4); 可以通过缩写使Java更为简洁。比如一个求职者可以在白板上这样写:
1. HM dict = new HM().
2. dict.put("left", 1);
3. ... "right", 2
4. ... "top", 3
5. ... "bottom", 4 你需要解释这些缩写,但绝大多数面试官并不在意。
7.12.5 易用性
有些语言使用起来更为容易。例如,使用Python可以轻而易举地让一个函数返回多个值。但是如果使用Java,就还需要一个新的类。语言的易用性可能对解决某些问题大有裨益。
与上述类似,可以通过缩写或者实际上不存在的假设方法让语言更易使用。例如,如果一种语言提供了矩阵转置的方法而另一种语言未提供,也并不一定要选第一种语言(如果面试题需要那个函数的话),可以假设另一种语言也有类似的方法。
7.13 好代码的标准
到目前为止,你可能知道雇主想看到你写出一手“漂亮的、干净的”代码。但具体的标准是什么呢?在面试中又如何体现呢?
一般来讲,好代码应符合以下标准。
- 正确:对于预期输入和非预期输入都能正确运行。
- 高效:代码在时间与空间上应尽可能高效,“高效”不单单指渐近线(大)的高效,还指实际、现实生活中的高效,也就是说,计算大时会放弃的常量,在现实生活中可能至关重要。
- 简洁:能用10行代码解决的问题就不要用100行,开发者应竭尽全力干净利落地编写代码。
- 可读性:其他开发者要能看懂你的代码,能理解代码的功能以及实现方法。易读的代码在必要时有注释,但其实现方法一目了然。这意味着,你写出的花哨代码,比如包含一组复杂的比特位移动,不一定就是好代码。
- 可维护性:代码应能合理适应产品在生命周期中的变化,对初始和后来开发者而言,都应易于维护。
追求这些需要掌握好平衡。比如,有时牺牲一定的效率来提高可维护性就是明智之举,反之亦然。
在面试中写代码时应该考虑到这些。以下内容更为具体地阐述了好代码的标准。
7.13.1 多多使用数据结构
假设让你写一个函数,把两个单独的数学表达式相加,形如![]() (其中系数和指数可以为任意正实数或负实数),即该表达式是由一系列项组成,每个项都是一个常数乘以一个指数。面试官还补充说,不希望你解析字符串,但你可以使用任何数据结构。
(其中系数和指数可以为任意正实数或负实数),即该表达式是由一系列项组成,每个项都是一个常数乘以一个指数。面试官还补充说,不希望你解析字符串,但你可以使用任何数据结构。
这有几种不同的实现方式。
7.13.1.1 糟糕透顶的实现方式
一个糟糕透顶的实现方式是把表达式放在一个double的数组中,第个元素对应表达式中![]() 项的系数。这个数据结构的问题在于,不支持指数为负数或非整数的表达式,还要求1000个元素大小的数组来存储表达式
项的系数。这个数据结构的问题在于,不支持指数为负数或非整数的表达式,还要求1000个元素大小的数组来存储表达式![]() 。
。
1. int[] sum(double[] expr1, double[] expr2) {
2. ...
3. }7.13.1.2 勉强凑合的实现方式
稍差的方案是用两个数组分别保存系数和指数。用这种方法,表达式的每一项都有序保存,但能“匹配”。第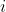 项就表示为
项就表示为oefficients[i]*xexponents[i]。
对于这种实现方式,如果coefficients[p] = k并且exponents[p] = m,那么第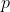 项就是
项就是![]() 。虽然这样没有了上一种方式的限制,但仍然显得杂乱无章。一个表达式却需要使用两个数组。如果两个数组长度不同,表达式可能有“未定义”的值。不仅如此,返回也让人不胜其烦,因为要返回两个数组。
。虽然这样没有了上一种方式的限制,但仍然显得杂乱无章。一个表达式却需要使用两个数组。如果两个数组长度不同,表达式可能有“未定义”的值。不仅如此,返回也让人不胜其烦,因为要返回两个数组。
1. ??? sum(double[] coeffs1, double[] expon1, double[] coeffs2, double[] expon2) {
2. ...
3. }7.13.1.3 优美的实现方式
一个好的实现方式就是为这个问题中的表达式设计数据结构。
1. class ExprTerm {
2. double coefficient;
3. double exponent;
4. }
5.
6. ExprTerm[] sum(ExprTerm[] expr1, ExprTerm[] expr2) {
7. ...
8. }有些人可能认为甚至声称,这是“过度优化”。不管是不是,也不管你有没有觉得这是过度优化,关键在于上面的代码体现了你在思考如何设计代码,而不是以最快速度将一些数据东拼西凑。
7.13.2 适当代码复用
假设让你写一个函数来检查是否一个二进制的值(以字符串表示)等于用字符串表示的一个十六进制数。
解决该问题的一种简单方法就是复用代码。
1. boolean compareBinToHex(String binary, String hex) {
2. int n1 = convertFromBase(binary, 2);
3. int n2 = convertFromBase(hex, 16);
4. if (n1 < 0 || n2 < 0) {
5. return false;
6. }
7. return n1 == n2;
8. }
9.
10. int convertFromBase(String number, int base) {
11. if (base < 2 || (base > 10 && base != 16)) return -1;
12. int value = 0;
13. for (int i = number.length() - 1; i >= 0; i--) {
14. int digit = digitToValue(number.charAt(i));
15. if (digit < 0 || digit >= base) {
16. return -1;
17. }
18. int exp = number.length() - 1 - i;
19. value += digit * Math.pow(base, exp);
20. }
21. return value;
22. }
23.
24. int digitToValue(char c) { ... }可以单独实现二进制转换和十六进制转换的代码,但这只会让代码难写且难以维护。不如写一个convertFromBase方法和 digitToValue方法,然后复用代码。
7.13.3 模块化
编写模块化的代码时要把独立代码块放到各自的方法中。这有助于提高代码的可维护性、可读性和可测试性。
想象你正在写一个交换数组中最小数和最大数的代码,可以用如下方法完成。
1. void swapMinMax(int[] array) {
2. int minIndex = 0;
3. for (int i = 1; i < array.length; i++) {
4. if (array[i] < array[minIndex]) {
5. minIndex = i;
6. }
7. }
8.
9. int maxIndex = 0;
10. for (int i = 1; i < array.length; i++) {
11. if (array[i] > array[maxIndex]) {
12. maxIndex = i;
13. }
14. }
15.
16. int temp = array[minIndex];
17. array[minIndex] = array[maxIndex];
18. array[maxIndex] = temp;
19. }或者你也可以把相对独立的代码块封装成方法,这样写出的代码更为模块化。
1. void swapMinMaxBetter(int[] array) {
2. int minIndex = getMinIndex(array);
3. int maxIndex = getMaxIndex(array);
4. swap(array, minIndex, maxIndex);
5. }
6.
7. int getMinIndex(int[] array) { ... }
8. int getMaxIndex(int[] array) { ... }
9. void swap(int[] array, int m, int n) { ... }虽然非模块化的代码也不算糟糕透顶,但是模块化的好处是易于测试,因为每个组件都可以单独测试。随着代码越来越复杂,代码的模块化也愈加重要,这将使代码更易维护和阅读。面试官想在面试中看到你能展示这些技能。
7.13.4 灵活性和通用性
你的面试官要求你写代码来检查一个典型的井字棋是否有个赢家,并不意味着你必须要假定是一个3×3的棋盘。为什么不把代码写得更为通用一些,实现成![]() 的棋盘呢?
的棋盘呢?
把代码写得灵活、通用,也许意味着可以通过用变量替换硬编码值或者使用模板、泛型来解决问题。如果可以的话,应该把代码写得更为通用。
当然,凡事无绝对。如果一个解决方案对于一般情况而言显得太过复杂,并且不合时宜,那么实现简单预期的情况可能更好。
7.13.5 错误检查
一个谨慎的程序员是不会对输入做任何假设的,而是会通过ASSERT和if语句验证输入。
一个例子就是之前把数字从进制(比如二进制或十六进制)表示转换成一个整数。
1. int convertFromBase(String number, int base) {
2. if (base < 2 || (base > 10 && base != 16)) return -1;
3. int value = 0;
4. for (int i = number.length() - 1; i >= 0; i--) {
5. int digit = digitToValue(number.charAt(i));
6. if (digit < 0 || digit >= base) {
7. return -1;
8. }
9. int exp = number.length() - 1 - i;
10. value += digit * Math.pow(base, exp);
11. }
12. return value;
13. }在第2行,检查进制数是否有效(假设进制大于10时,除了16以外,没有标准的字符串表示)。在第6行,又做了另一个错误检查以确保每个数字都在允许范围内。
像这样的检查在生产代码中至关重要,也就是说,面试中同样重要。
不过,写这样的错误检查会很枯燥无味,还会浪费宝贵的面试时间。关键是,要向面试官指出你会写错误检查。如果错误检查不是一个简单的if语句能解决的,最好给错误检查留有空间,告诉面试官等完成其余代码后还会返回来写错误检查。
7.14 不要轻言放弃
面试题有时会让人不得要领,但这只是面试官的测试手段。直面挑战还是知难而退?不畏艰险,奋勇向前,这一点至关重要。总而言之,切记面试不是一蹴而就的。遇到拦路虎本就在意料之中。
还有一个加分项:表现出解决难题的满腔热情。
本文摘自《程序员面试金典(第6版)》
