MySql体系架构(MySQL深度优化)
这里写目录标题
- MySql体系架构
-
- 1.体系
-
- 1.1. 连接层
- 1.2. SQL 处理层
-
- 1.2.1. 缓存
- 1.2.2. 解析查询
- 1.2.3. 优化
- 2. 逻辑架构
- 3.物理存储结构
-
- 3.1. 数据库的数据库(DataDir)
- 3.2. 数据库
- 3.3. 表文件
- 3.4. mysql utilities 安装
- 4.存储引擎
-
- 4.1.MyISAM
-
- 4.1.1. 表压缩
- 4.1.2. 适用场景:
- 4.2.Innodb
- 4.3.CSV
- 4.4.Archive
- 4.5.Memory
-
- 4.5.1. 特点
- 4.5.2. 与临时表的区别
- 4.5.3. 使用场景
MySql体系架构
1.体系
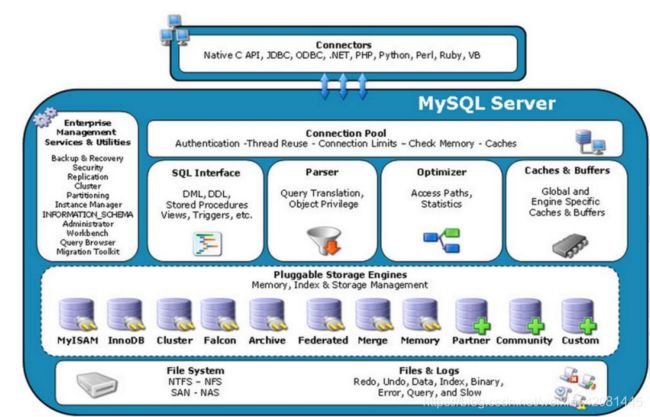
1.1. 连接层
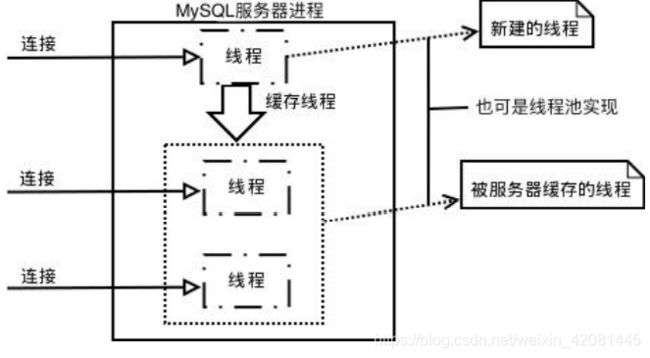
当 MySQL 启动(MySQL 服务器就是一个进程),等待客户端连接,每一个客户端连接请求,
服务器都会新建一个线程处理(如果是线程池的话,则是分配一个空的线程),每个线程独
立,拥有各自的内存处理空间
#查看线程数
show VARIABLES like '%max_connections%'
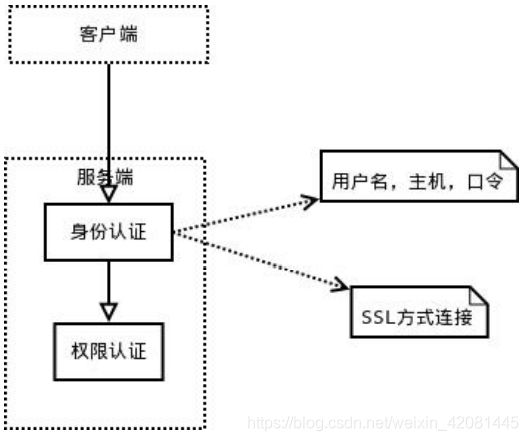
连接到服务器,服务器需要对其进行验证,也就是用户名、IP、密码验证,一旦连接成功,
还要验证是否具有执行某个特定查询的权限(例如,是否允许客户端对某个数据库某个表的
某个操作)
1.2. SQL 处理层
这一层主要功能有:SQL 语句的解析、优化,缓存的查询,MySQL 内置函数的实现,跨存储
引擎功能(所谓跨存储引擎就是说每个引擎都需提供的功能(引擎需对外提供接口)),例如:
存储过程、触发器、视图等。
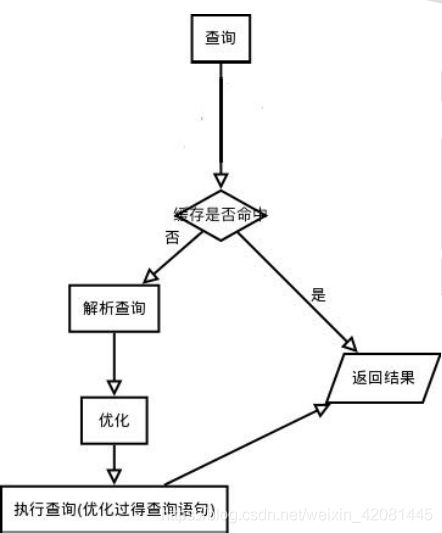
1.如果是查询语句(select 语句),首先会查询缓存是否已有相应结果,有则返回结果,无则
进行下一步(如果不是查询语句,同样调到下一步)
2.解析查询,创建一个内部数据结构(解析树),这个解析树主要用来 SQL 语句的语义与语
法解析;
3.优化:优化 SQL 语句,例如重写查询,决定表的读取顺序,以及选择需要的索引等。这一
阶段用户是可以查询的,查询服务器优化器是如何进行优化的,便于用户重构查询和修改相
关配置,达到最优化。这一阶段还涉及到存储引擎,优化器会询问存储引擎,比如某个操作
的开销信息、是否对特定索引有查询优化等。
1.2.1. 缓存
show variables like '%query_cache_type%' -- 默认不开启
show variables like '%query_cache_size%' --默认值 1M
SET GLOBAL query_cache_type = 1; --会报错
query_cache_type 只能配置在 my.cnf 文件中,这大大限制了 qc 的作用
在生产环境建议不开启,除非经常有 sql 完全一模一样的查询
QC 严格要求 2 次 SQL 请求要完全一样,包括 SQL 语句,连接的数据库、协议版本、字符
集等因素都会影响
1.2.2. 解析查询
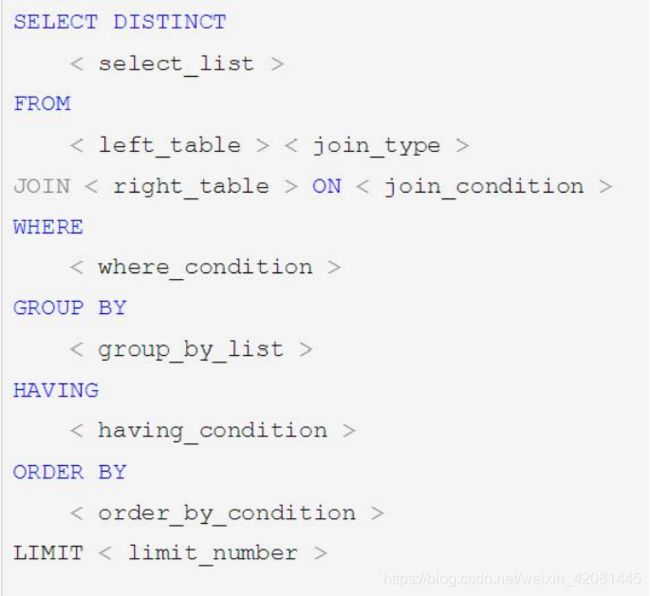
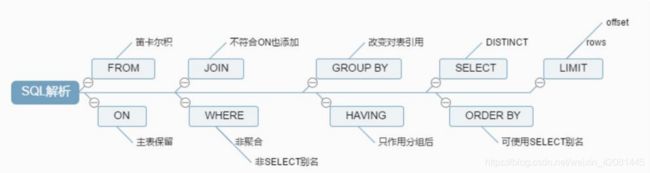
1.2.3. 优化
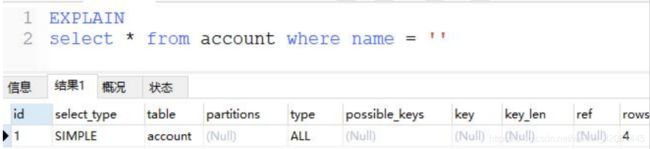
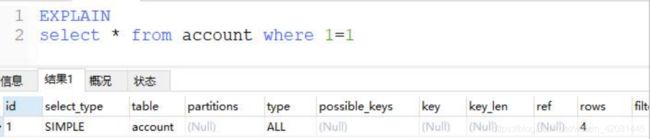
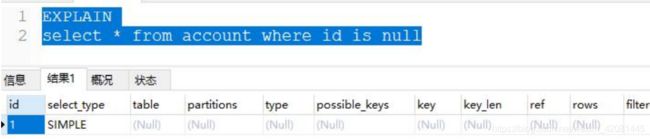
通过上面的 sql 大概就能看出,虽然现在还没学执行计划,但通过这个已经看出一个 sql 并
不一定会去查询物理数据,sql 解析器会通过优化器来优化程序员写的 sql
explain
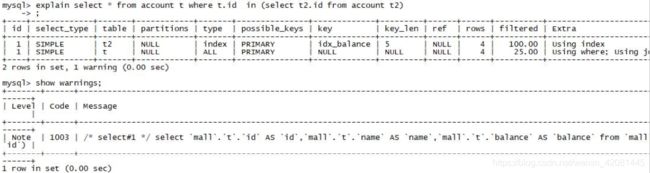
select * from account t where t.id in (select t2.id from account t2)
show warnings;
2. 逻辑架构
mysql逻辑架构
Datebase
Datebase
Schema
Schema
table1
......
table2
table1
......
table2
在 mysql 中其实还有个 schema 的概念,这概念没什么太多作用,只是为了兼容其他数据库,
所以也提出了这个。
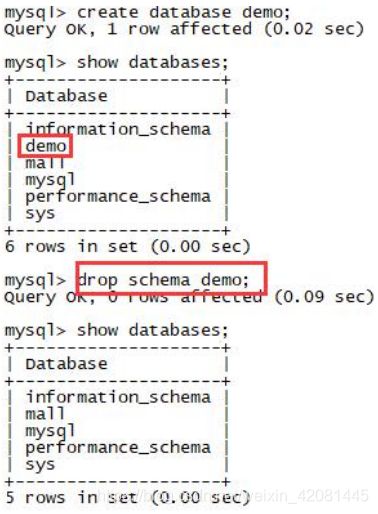
在 mysql 中 database 和 schema 是等价的
create database demo;
show databases;
drop schema demo;
show databases;
3.物理存储结构
3.1. 数据库的数据库(DataDir)
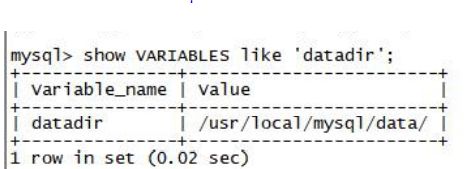
mysql 安装的时候都要指定 datadir,其查看方式为:
show VARIABLES like 'datadir',其规定所有建立的数据库存放位置
3.2. 数据库
创建了一个数据库后,会在上面的 datadir 目录新建一个子文件夹
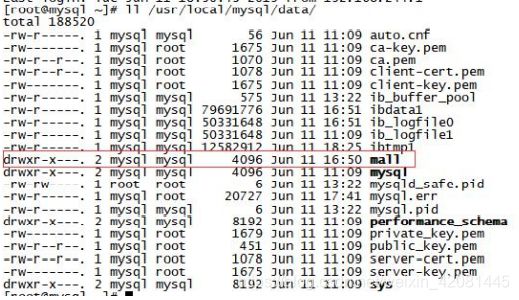
3.3. 表文件
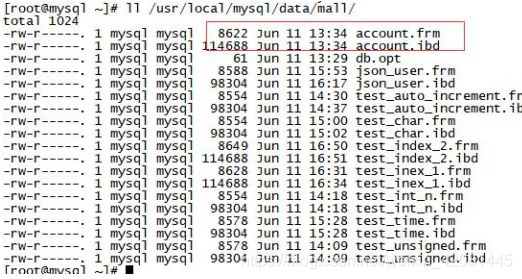
用户建立的表都会在上面的目录中,它和具体的存储引擎相关,但有个共同的就是都有个
frm 文件,它存放的是表的数据格式。
mysqlfrm --diagnostic /usr/local/mysql/data/mall/account.frm
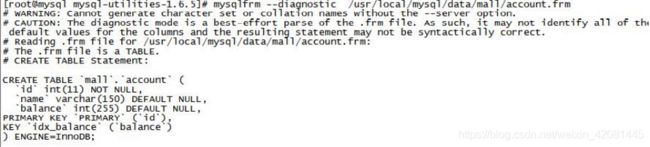
3.4. mysql utilities 安装
管理和维护MySQL数据库有时会复杂化,有时任务需要繁琐甚至重复操作,鉴于这些因素,MySQL Utilities扩展是为了帮助初学者和经验丰富的数据库管理员执行常见任务。
MySQL Utilities内部
MySQL Utilities被设计成易于使用Python脚本,可以组合来提供更强大的功能。在内部,脚本使用mysql.utilities模块库来执行各项任务。由于该库是通用的函数,数据库管理员很容易创建自己的脚本来执行常见任务。这些工具都位于 /scripts文件夹下。
MySQL Utilities剖析
MySQL Utilities使用了三层模块组织。在顶层是命令脚本,位于 /scripts 目录下。脚本中包含的命令模块设计来封装和隔离大部分工具的工作。命令模块位于/mysql/utilities/command目录下。命令模块的名称类似于脚本。一个命令模块包含一个或多个通用模块类和方法。通用模块位于 /mysql/utilities/common目录下。
# 安装方法
tar -zxvf mysql-utilities-1.6.5.tar.gz
cd mysql-utilities-1.6.5
python ./setup.py build
python ./setup.py install
4.存储引擎
# 看你的 mysql 现在已提供什么存储引擎:
mysql> show engines;
# 看你的 mysql 当前默认的存储引擎:
mysql> show variables like '%storage_engine%';
4.1.MyISAM
MySql 5.5 之前默认的存储引擎
MyISAM 存储引擎由 MYD 和 MYI 组成
create table testmysam (
id int PRIMARY key
) ENGINE=myisam
insert into testmysam VALUES(1),(2),(3)
4.1.1. 表压缩
myisampack -b -f /usr/local/mysql/data/mall/testmysam.MYI
# 压缩后再往表里面新增数据就新增不了
insert into testmysam VALUES(1),(2),(3)

# 压缩后,需要
myisamchk -r -f /usr/local/mysql/data/mall/testmysam.MYI
4.1.2. 适用场景:
- 非事务型应用(数据仓库,报表,日志数据)
- 只读类应用
- 空间类应用(空间函数,坐标)
由于现在 innodb 越来越强大,myisam 已经停止维护
(绝大多数场景都不适合)
4.2.Innodb
- Innodb 是一种事务性存储引擎
- 完全支持事务得 ACID 特性
- Redo Log 和 Undo Log
- Innodb 支持行级锁(并发程度更高)
| 对比项 | MyISAM | Innodb |
|---|---|---|
| 主外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条记录,也会锁住整个表,不适合高并发的操作 | 行锁,操作时只锁某一行,不对其他行有影响,适合高并发的操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引,还会缓存真实数据,对内存要求较高,而且内存大小决定其性能 |
# 查询执行事务分配的缓存
show VARIABLES like 'innodb_log_buffer_size'
4.3.CSV
- 以 csv 格式进行数据存储
- 所有列都不能为 null 的
- 不支持索引(不适合大表,不适合在线处理)
- 可以对数据文件直接编辑(保存文本文件内容)
create table mycsv(id int not null,c1 VARCHAR(10) not null,c2 char(10) not null) engine=csv;
insert into mycsv values(1,'aaa','bbb'),(2,'cccc','dddd');
vi /usr/local/mysql/data/mall/mycsv.CSV 修改文本数据
flush TABLES;
select * from mycsv
create index idx_id on mycsv(id)
4.4.Archive
- 组成
以 zlib 对表数据进行压缩,磁盘 I/O 更少
数据存储在 ARZ 为后缀的文件中 - 特点
只支持 insert 和 select 操作
只允许在自增 ID 列上加索引
create table myarchive(id int auto_increment not null,c1 VARCHAR(10),c2 char(10), key(id))
engine = archive;
create index idx_c1 on myarchive(c1)
INSERT into myarchive(c1,c2) value('aa','bb'),('cc','dd');
delete from myarchive where id = 1
update myarchive set c1='aaa' where id = 1
4.5.Memory
4.5.1. 特点
- 文件系统存储特点,也称 HEAP 存储引擎,所以数据保存在内存中
- 支持 HASH 索引和 BTree 索引
- 所有字段都是固定长度 varchar(10) = char(10)
- 不支持 Blog 和 Text 等大字段
- Memory 存储引擎使用表级锁
- 最大大小由 max_heap_table_size 参数决定
show VARIABLES like 'max_heap_table_size' create table mymemory(id int,c1 varchar(10),c2 char(10),c3 text) engine = memory;
create table mymemory(id int,c1 varchar(10),c2 char(10)) engine = memory;
create index idx_c1 on mymemory(c1);
create index idx_c2 using btree on mymemory(c2);
show index from mymemory
show TABLE status LIKE ‘mymemory’
4.5.2. 与临时表的区别
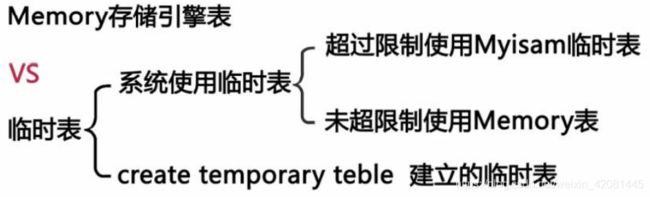
4.5.3. 使用场景
- hash 索引用于查找或者是映射表(邮编和地区的对应表)
- 用于保存数据分析中产生的中间表
- 用于缓存周期性聚合数据的结果表