knn的python实现(numpy矩阵运算)
knn的内容很简单,假设给定m个点和一个中心点,找到所给的点中距离中心点最近的k个点。
因此代码思路是先计算所有点与中心点的距离,进行升序排序,取前k个点。
在机器学习中,数据量较大的情况下,使用循环会使得代码运行效率非常低,因此用矩阵运算的方式完成代码。
欧式距离的矩阵运算

代码如下
def euclidean_dist(x, y):
"""
矩阵计算欧式距离
:param x: Ndarray Variable, with shape [m, d]
:param y: Ndarray Variable, with shape [n, d]
:return: dist: Ndarray Variable, with shape [n, m]
"""
m, n = x.shape[0], y.shape[0]
# x先对每个数据取平方,后按行求和,再将得到的重复扩展n个,得到m*n的数据
xx = np.expand_dims(np.sum((x**2), axis=1), axis=1).repeat(n, axis=1)
# x先对每个数据取平方,后按行求和,再将得到的重复扩展m个,转置后得到m*n的数据
yy = np.expand_dims(np.sum((y**2), axis=1), axis=1).repeat(m, axis=1).T
dist = xx + yy - 2 * x @ y.T
# np.clip()函数可以限定dist内元素的最大最小范围,然后用np.sqrt()开方,得到样本之间的距离矩阵
dist = np.sqrt(np.clip(dist, a_min=1e-12, a_max=None))
return dist.TKnn
def knn(data_support, center_data, k):
"""
根据给定的center_data, 在data_support中找到最近的k个数据的idx
:param data_support:[M, D], M个D维的数据
:param center_data:[N, D], N个D维的数据
:param k:
:return:res:[N, k, D]
res[0]为[k, D],即第一个center_data的k个最近数据
"""
# 计算距离矩阵,(i, j)处的数据表示center_data[j]与data_support[i]的距离
dist = euclidean_dist(data_support, center_data)
# 对每一列进行排序,找到center_data[]最近的k个data_support
sorted_idxs = dist.argsort(axis=1)
res = []
for idxs in sorted_idxs:
res.append([data_support[idx] for idx in idxs[:k]])
return np.array(res)完整代码
# -*- coding: utf-8 -*-
"""
Time: 2023/3/13 13:56
Author: cjn
Version: 1.0.0
File: knn.py
Describe:
"""
import numpy as np
def euclidean_dist(x, y):
"""
矩阵计算欧式距离
:param x: Ndarray Variable, with shape [m, d]
:param y: Ndarray Variable, with shape [n, d]
:return: dist: Ndarray Variable, with shape [n, m]
"""
m, n = x.shape[0], y.shape[0]
# x先对每个数据取平方,后按行求和,再将得到的重复扩展n个,得到m*n的数据
xx = np.expand_dims(np.sum((x**2), axis=1), axis=1).repeat(n, axis=1)
# x先对每个数据取平方,后按行求和,再将得到的重复扩展m个,转置后得到m*n的数据
yy = np.expand_dims(np.sum((y**2), axis=1), axis=1).repeat(m, axis=1).T
dist = xx + yy - 2 * x @ y.T
# np.clip()函数可以限定dist内元素的最大最小范围,然后用np.sqrt()开方,得到样本之间的距离矩阵
dist = np.sqrt(np.clip(dist, a_min=1e-12, a_max=None))
return dist.T
def knn(data_support, center_data, k):
"""
根据给定的center_data, 在data_support中找到最近的k个数据的idx
:param data_support:[M, D], M个D维的数据
:param center_data:[N, D], N个D维的数据
:param k:
:return:res:[N, k, D]
res[0]为[k, D],即第一个center_data的k个最近数据
"""
# 计算距离矩阵,(i, j)处的数据表示center_data[j]与data_support[i]的距离
dist = euclidean_dist(data_support, center_data)
# 对每一列进行排序,找到center_data[]最近的k个data_support
sorted_idxs = dist.argsort(axis=1)
res = []
for idxs in sorted_idxs:
res.append([data_support[idx] for idx in idxs[:k]])
return np.array(res)
if __name__ == "__main__":
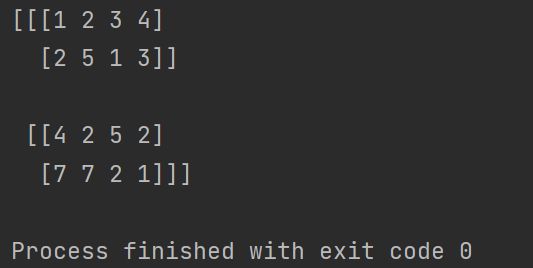
dataset = np.array([[1, 2, 3, 4], [2, 5, 1, 3], [7, 7, 2, 1], [4, 2, 5, 2]])
center = np.array([[2, 2, 1, 4], [7, 3, 2, 4]])
k = 2
res = knn(dataset, center, k)
print(res)运行结果: