HTTP相关知识点整理
HTTP

一次完整的http请求服务过程
输入url后,首先需要找到这个url域名的服务器ip,为了寻找这个ip,浏览器首先会寻找缓存,查看缓存中是否有记录,缓存的查找记录为:浏览器缓存-》系统缓存-》路由器缓存,缓存中没有则查找系统的hosts文件中是否有记录,如果没有则查询DNS服务器,得到服务器的ip地址后,浏览器根据这个ip以及相应的端口号,构造一个http请求,这个请求报文会包括这次请求的信息,主要是请求方法,请求说明和请求附带的数据,并将这个http请求封装在一个tcp包中,这个tcp包会依次经过传输层,网络层,数据链路层,物理层到达服务器,服务器解析这个请求来作出响应,返回相应的html给浏览器,因为html是一个树形结构,浏览器根据这个html来构建DOM树,在dom树的构建过程中如果遇到JS脚本和外部JS连接,则会停止构建DOM树来执行和下载相应的代码,这会造成阻塞,这就是为什么推荐JS代码应该放在html代码的后面,之后根据外部央视,内部央视,内联样式构建一个CSS对象模型树CSSOM树,构建完成后和DOM树合并为渲染树,这里主要做的是排除非视觉节点,比如script,meta标签和排除display为none的节点,之后进行布局,布局主要是确定各个元素的位置和尺寸,之后是渲染页面,因为html文件中会含有图片,视频,音频等资源,在解析DOM的过程中,遇到这些都会进行并行下载,浏览器对每个域的并行下载数量有一定的限制,一般是4-6个,当然在这些所有的请求中我们还需要关注的就是缓存,缓存一般通过Cache-Control、Last-Modify、Expires等首部字段控制。 Cache-Control和Expires的区别在于Cache-Control使用相对时间,Expires使用的是基于服务器 端的绝对时间,因为存在时差问题,一般采用Cache-Control,在请求这些有设置了缓存的数据时,会先 查看是否过期,如果没有过期则直接使用本地缓存,过期则请求并在服务器校验文件是否修改,如果上一次 响应设置了ETag值会在这次请求的时候作为If-None-Match的值交给服务器校验,如果一致,继续校验 Last-Modified,没有设置ETag则直接验证Last-Modified,再决定是否返回304
输入完网址按下回车,到看到网页这个过程中发生了什么
1.浏览器向DNS服务器请求解析该 URL 中的域名所对应的 IP 地址;
2.跟服务器建立TCP连接(三次握手);
3.建立TCP连接后浏览器发出HTTP 请求
4.服务器对浏览器请求作出响应,并把对应的 html 代码发送给浏览器;
5.浏览器解析HTML代码,并请求HTML代码中资源(如js,css,图片)
6.浏览器对页面进行渲染并呈现给用户;
7.服务器关闭TCP连接(四次挥手)
a.域名解析
DNS域名系统,是应用层协议,运行UDP协议之上,使用端口43。
浏览器先查看浏览器缓存-系统缓存-路由器缓存,如果缓存中有该请求资源,会直接在屏幕中显示页面内容,没有再使用DNS服务器解析,本地查询是递归查询,依次通过浏览器缓存 —>> 本地hosts文件 —>> 本地DNS解析器 —>>本地DNS服务器 —>> 其他域名服务器请求。接下来的过程就是迭代过程。
递归查询一般而言,发送一次请求就够,迭代过程需要用户发送多次请求。
DNS 使用 UDP 协议作为传输层协议的主要原因是为了避免使用 TCP 协议时造成的连接时延。
为了得到一个域名的 IP 地址,往往会向多个域名服务器查询,如果使用 TCP 协议,那么每次请求都会存在连接时延,这样使 DNS 服务变得很慢。
大多数的地址查询请求,都是浏览器请求页面时发出的,这样会造成网页的等待时间过长。
浏览器会判断所请求的资源是否在缓存里,如果请求的资源在缓存里并且没有失效,那么就直接使用,否则向服务器发起新的请求。
b. 发起TCP的3次握手
TCP协议采用了三次握手策略。发送端首先发送一个带SYN(synchronize)标志的数据包给接收方,接收方收到后,回传一个带有SYN/ACK(acknowledegment)标志的数据包以示传达确认信息。最后发送方再回传一个带ACK标志的数据包,代表握手结束。
为什么要第三次挥手?避免服务器等待造成资源浪费
c. 建立TCP连接后发起http请求
HTTP请求
HTTP1.0定义了三种请求方法,GET,POST和HEAD方法 HTTP1.1新增六种请求方法:OPTIONS,PUT,PATCH,DELETE,TRACH和CONNECT
请求方法:
GET:获取资源
POST:传输资源
PUT:更新资源
DELETE:删除资源
HEAD:获得报文首部
OPTIONS:返回支持的请求方法
TRACE:追踪路径
HTTP报文的组成部分
http报文包括:请求报文和响应报文。
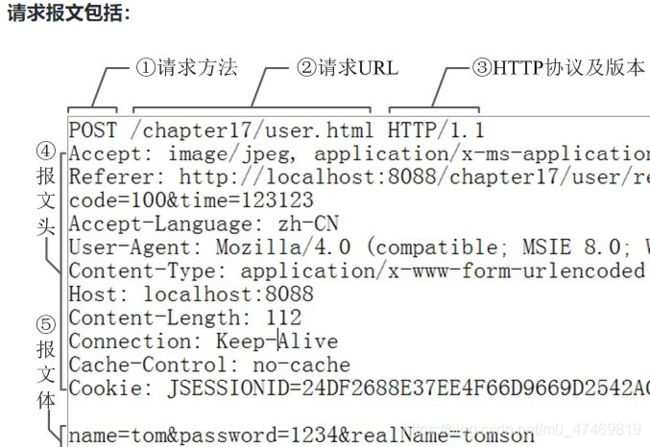
请求报文= 请求行+请求头+空行+请求体
(1)请求行:包含http方法,页面地址,http协议,版本。
(2)请求头:key,value值,告诉服务端我要哪些内容。
(3)空行:分隔请求头、请求体。
(4)请求体:数据部分。
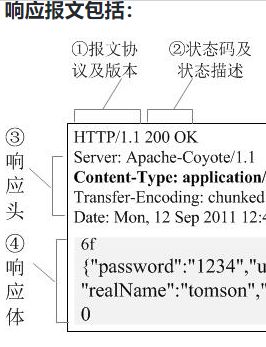
响应报文=状态行+响应头+空行+响应体
状态行:http协议及版本、状态码及状态描述。
get post
GET 用于获取资源,POST 用于提交资源。
- 浏览器在回退时,get不会重新请求,但是post会重新请求
- get请求会被浏览器主动缓存,而post不会
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求大小一般是(1024字节),POST理论上来说没有大小限制。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,请求的 url 会被保留在历史记录中,所以不能用来传递敏感信息。
- get把参数包含在URL上,post的参数在http报文体内

d. 服务器端响应http请求,浏览器得到html代码
服务器在收到浏览器发送的HTTP请求之后,会将收到的HTTP报文封装成HTTP的Request对象,并通过不同的Web服务器进行处理,处理完的结果以HTTP的Response对象返回,主要包括状态码,响应头,响应报文三个部分。
状态码

1xx 信息类
接受的请求正在处理,信息类状态码。
2xx 成功
200 OK 表示从客户端发来的请求在服务器端被正确请求。
204 No content,表示请求成功,但没有资源可返回。
206 Partial Content,该状态码表示客户端进行了范围请求,而服务器成功执行了这部分的 GET 请求响应报文中包含由 Content-Range 指定范围的实体内容。
3xx 重定向
301 moved permanently,永久性重定向,表示资源已被分配了新的 URL,这时应该按 Location 首部字段提示的 URI 重新保存。
302 found,临时性重定向,表示资源临时被分配了新的 URL。
303 see other,表示资源存在着另一个 URL,应使用 GET 方法获取资源。
304 not modified,当协商缓存命中时会返回这个状态码。
307 temporary redirect,临时重定向,和302含义相同,不会改变method
当 301、302、303 响应状态码返回时,几乎所有的浏览器都会把 POST 改成 GET,并删除请求报文内的主体,之后请求会自动再次发送301、302 标准是禁止将 POST 方法改变成 GET 方法的,但实际使用时大家都会这么做
4XX 客户端错误
400 bad request,请求报文存在语法错误。
401 unauthorized,表示发送的请求需要有通过 HTTP 认证的认证信息。
403 forbidden,表示对请求资源的访问被服务器拒绝。
404 not found,表示在服务器上没有找到请求的资源。
405 Method Not Allowed,服务器禁止使用该方法,客户端可以通过options方法来查看服务器允许的访问方法,如下
Access-Control-Allow-Methods →GET,HEAD,PUT,PATCH,POST,DELETE
5XX 服务器错误
500 internal sever error,表示服务器端在执行请求时发生了错误。
502 Bad Gateway,服务器自身是正常的,访问的时候出了问题,具体啥错误我们不知道。
503 service unavailable,表明服务器暂时处于超负载或正在停机维护,无法处理请求。
接下来,我们数据拿到了,你认为就会断开TCP连接吗?
这个的看响应头中的Connection字段。上面的字段值为close,那么就会断开,一般情况下,HTTP1.1版本的话,通常请求头会包含「Connection: Keep-Alive」表示建立了持久连接,这样TCP连接会一直保持,之后请求统一站点的资源会复用这个连接。
上面的情况就会断开TCP连接,请求-响应流程结束。
到这里的话,网络请求就告一段落了,接下来的内容就是渲染流程了
浏览器解析渲染页面
浏览器渲染原理:
当我们在浏览器地址输入URL时,浏览器会发送请求到服务器,服务器将请求的HTML文档发送回浏览器,浏览器将文档下载下来后,便开始从上到下解析,解析完成之后,会生成DOM。如果页面中有css,会根据css的内容形成CSSOM,然后DOM和CSSOM会生成一个渲染树,最后浏览器会根据渲染树的内容计算出各个节点在页面中的确切大小和位置,并将其绘制在浏览器上。
css文件的加载是与DOM的加载并行的,也就是说,css在加载时Dom还在继续加载构建,而过程中遇到的css样式或者img,则会向服务器发送一个请求,待资源返回后,将其添加到dom中的相对应位置中;
由于js文件不会与DOM并行加载,因此需要等待js整个文件加载完之后才能继续DOM的加载
解决方法:
前提,js是外部脚本;
- 在scirpt标签中添加 async=“ture”,这个属性告诉浏览器该js文件是异步加载执行的,也就是不依赖于其他js和css,也就是说无法保证js文件的加载顺序,但是同样有与DOM并行加载的效果;
- 在script标签中添加 defer=“ture”,则会让js与DOM并行加载,待页面加载完成后再执行js文件,这样则不存在阻塞;

- 构建 DOM树 解析HTML文档并将HTML标签解析为DOM节点生成内容树。DOM 树与 HTML 标签一一对应,包括 head 和隐藏元素
渲染树不包括 head 和隐藏元素,大段文本的每一个行都是独立节点,每一个节点都有对应的 css 属性 - 加载css,js等资源 诸如图片,CSS,JS 等额外的资源,这些资源需要从网络上或者 cache 中获取。主进程可以在构建 DOM 的过程中会逐一请求它们
- JS 的下载与执行
JavaScript的加载、解析与执行会阻塞DOM的构建,也就是说,在构建DOM时,遇到