一、flink下载安装
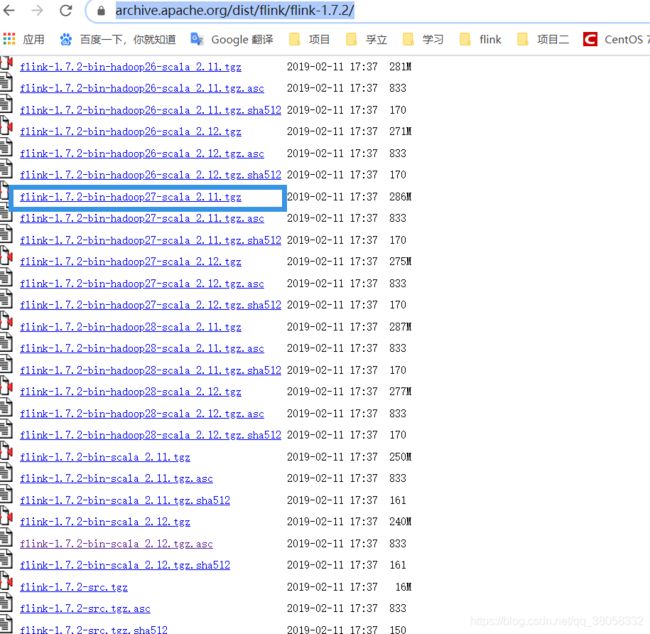
官网下载地址:https://archive.apache.org/dist/flink/flink-1.7.2/
我这里下载的是1.7.2,对应hadoop版本是27,Scala是2.11,另外两种包是添加加密算法的包,你可以选择你需要的版本包
flink的需要运行在Java环境或Scala环境的
所以安装前确保你的服务器安装有Java不低于8的版本
1、Windows版本
将安装包解压,找到bin目录的start-cluster.bat,执行,弹出两个命令窗即为启动成功


地址栏输入:http://localhost:8081/#/overview 即可得到客户端页面
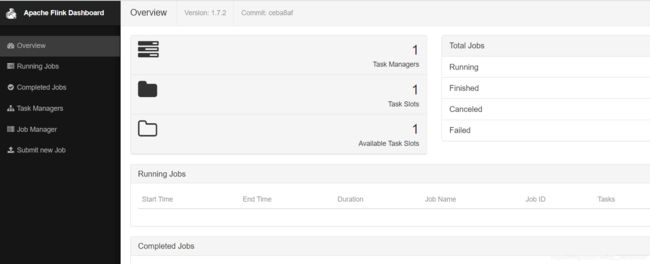
从上到下顺序菜单栏依次:概览、运行中的任务、已完成的任务、任务管理器、工作管理器、上传新的任务
2、Linux版本
跟Windows环境一样,注意检查Java环境和Scala环境
输入:
java -version检查Java环境
在/usr/local中新增文件夹flink
cd /usr/local
mkdir flink然后将下载的安装包放到该目录下,目录可以自己随意定,只要能找到即可,我习惯放在这里
然后解压
tar -zxvf flink-1.7.2-bin-hadoop27-scala_2.11.tgz解压后查看目录结构

bin目录是命令目录
conf配置文件目录
examples是官网提供的demo
lib是依赖jar
log是日志
首先bin目录

集群启动命令是:在bin目录下执行 ./start-cluster.sh
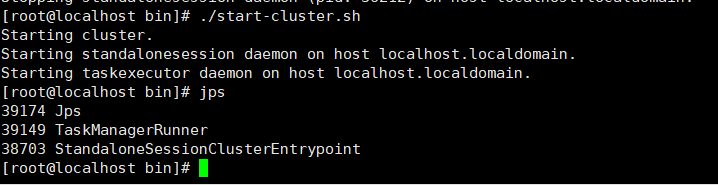
jps是查看flink是否启动成功,也有部分人说是flink启动进程
ps -ef|grep flink也可以查看flink是否启动成功
集群停止的命令:在bin目录下执行 ./stop-cluster.sh
其次我们再看一下conf目录
![]()
这里主要是flink和日志以及集群配置
常用的是flink-conf.yaml 、masters slaves
flink集群默认端口是8081
这里要把8081端口放开
firewall-cmd --zone=public --add-port=8081/tcp --permanent
重启防火墙
service firewalld restart
然后启动flink访问 IP:8081即可,ip是你自己虚拟机或者服务器的ip或者域名,配置集群有时间再更新上来。
注意:java环境的配置,Scala环境、防火墙配置
附:下载地址:链接:https://pan.baidu.com/s/1RZCDU50P_6WLgM66Cs6tNw
提取码:rxe1
官网下载难以想象的慢。