爬虫日常练习-协程方式爬取图片
文章目录
- 前言
- 代码设计
前言
hello朋友们,欢迎回来。这里是无聊的网友。今天给大家分享另一种处理多任务的方法–协程

那么在开始之前我们首先要了解什么是协程。协程是在一个线程内:多个任务出现阻塞时,由envet_loop轮转查看阻塞状态,收到回复的任务优先执行
简单来说,他会自动检测程序的运行状态。想必看到这的同学一阵头大。

机智的程序猿决定给小伙子们解释一二。假设线程内有四个不同的请求任务,分别为A,B,C,D。内部会有一个管理员帮我们查看他们的运行状态
普通的程序一般都是运行完A后才接着运行B,而协程则可以帮助我们在宏观上实现多任务同时处理。

比方说 A首先发送了请求,但是还没有得到回应,envet_loop(我们称他为管理员)发现服务器还没有返回对A的回应,这个时候它就会把A先放在一边。将B放上,B此时开始发送请求,若是还没有回应,则接着发送C的请求。中间还会不断地检测前面的任务有没有得到回应,检测到回应后就会将对应的任务重新启动。
这大大提升了运行端与服务端之间因为请求与回应的延迟带来的效率浪费,当然也并不是说协程一定快于多线程多进程。具体写法还是要根据实际的爬取任务来编写。
代码设计
接下来我们就可以接着对前面的程序做一些改动,首先我们增加一个main函数用来存放运行的任务主体。
一开始的设计思路是首先设计一个循环将所有页面的url获取并存放到列表中。再对列表循环发送请求。
如下列代码:
def main():
url_list = []
for i in range(1, 25):
url = f"https://www.iituku.com/lvyou/index_{i}.html?sort=0"
url_list.append(url)
for url in url_list:
pic_url_list = get_pic_url(url)
asyncio.run(download(pic_url_list))
但经过测试发现这一步不如直接在第一个循环时就对url发送请求,这样节约了二次循环带来的效率浪费
于是我们重新改写:
def main():
for i in range(1, 25):
url = f"https://www.iituku.com/lvyou/index_{i}.html?sort=0"
pic_url_list = get_pic_url(url)
asyncio.run(download(pic_url_list))
将页面链接循环放在此处后,我们先对get_pic_url()函数改写定义:
首先删除了原先放在该函数里的页面循环,通过url参数传递每个页面的url到函数中,并对页面进行请求,获取图片下载链接。由于这一步并不需要异步操作,所以只定义为普通函数。该函数返回存储图片下载链接的列表
def get_pic_url(url):
resp = requests.get(url)
resp.encoding = 'utf-8'
tree = etree.HTML(resp.text)
pic_url_string = tree.xpath('//html/body/script[2]/text()')[0]
obj = re.compile(r'var imagesarr=\"(.*?)\";')
data = obj.findall(pic_url_string)[0]
data = str(data).replace('"', '')
data_list = data.split('}')
pic_url_list = []
for li in data_list:
http = re.findall(r'picture:(.*?)/nu', li)
if not http:
continue
else:
http_str = http[0]
http = http_str.replace('\\', '')
pic_url_list.append(http)
return pic_url_list
接着对download函数定义。在这步就可以用上我们之前所说的协程概念,在向服务器请求下载数据的过程中,可以接着对下一图片链接发送请求,因此在此处采用协程模块。
创建特殊函数,在普通函数前添加一个async关键字。特殊函数的特点在于被调用后,函数内部的程序语句(函数体)没有被立即执行,且会返回一个协程对象
async def download(src_list):
tasks = []
for src in src_list:
task = asyncio.create_task(download_pic(src))
tasks.append(task)
await asyncio.wait(tasks)
接着在函数内部创建一个tasks列表存储任务对象列表。如上述代码中的task就是一个任务对象,里面指向要运行的函数download_pic()以及需要的参数src,所有任务对象添加到任务列表后,利用await关键字挂起发生阻塞操作的任务对象。然后在对download_pic()函数定义。
async def download_pic(src):
pic_name = src.split('/')[-1]
async with aiohttp.ClientSession() as session:
async with session.get(src) as resp:
cont = await resp.content.read()
async with aiofiles.open('./aitu_pic/' + pic_name, mode='wb') as f:
await f.write(cont)
print(f'{pic_name}下载完成')
需要注意的就是这里对文件的操作不同于普通函数的文件操作,需要使用aiofiles库对文件进行输入输出。并且对链接的请求也需要使用aiohttp库中的ClientSession()方法。在对二进制文件的读取也要加上.read()方法。
老规矩,编写完后看看运行效果。
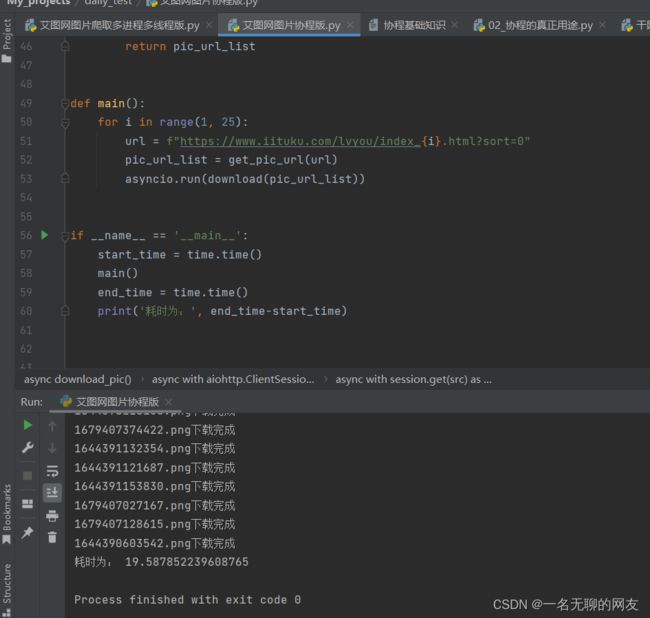
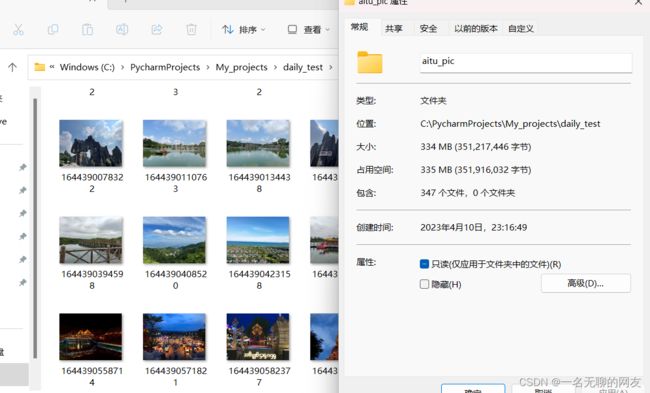 可以看到时间其实是差不多的,因为今天下载了347个文件,相较于前文的要多100多个文件。由此可见二者其实并没有太大的效率区别。所以具体的方法选择还是要看爬取的网站到底适合哪一种方式。
可以看到时间其实是差不多的,因为今天下载了347个文件,相较于前文的要多100多个文件。由此可见二者其实并没有太大的效率区别。所以具体的方法选择还是要看爬取的网站到底适合哪一种方式。
末尾附上源码
import asyncio
import time
import aiofiles
import aiohttp
import requests
from lxml import etree
import re
async def download(src_list):
tasks = []
for src in src_list:
task = asyncio.create_task(download_pic(src))
tasks.append(task)
await asyncio.wait(tasks)
async def download_pic(src):
pic_name = src.split('/')[-1]
async with aiohttp.ClientSession() as session:
async with session.get(src) as resp:
cont = await resp.content.read()
async with aiofiles.open('./aitu_pic/' + pic_name, mode='wb') as f:
await f.write(cont)
print(f'{pic_name}下载完成')
def get_pic_url(url):
resp = requests.get(url)
resp.encoding = 'utf-8'
tree = etree.HTML(resp.text)
pic_url_string = tree.xpath('//html/body/script[2]/text()')[0]
obj = re.compile(r'var imagesarr=\"(.*?)\";')
data = obj.findall(pic_url_string)[0]
data = str(data).replace('"', '')
data_list = data.split('}')
pic_url_list = []
for li in data_list:
http = re.findall(r'picture:(.*?)/nu', li)
if not http:
continue
else:
http_str = http[0]
http = http_str.replace('\\', '')
pic_url_list.append(http)
return pic_url_list
def main():
for i in range(1, 25):
url = f"https://www.iituku.com/lvyou/index_{i}.html?sort=0"
pic_url_list = get_pic_url(url)
asyncio.run(download(pic_url_list))
if __name__ == '__main__':
start_time = time.time()
main()
end_time = time.time()
print('耗时为:', end_time-start_time)
今天内容就说这么多,下期再见。另外跪求各位好汉不要吝啬你们的赞赞,动动手指帮忙赞赞,感激!!
