云曦-大作业-爬虫
爬虫是一个自动化代码 运用python语言实现
前期准备
工具 :pycharm
语言:python
库: re(正则) urllib(爬虫库) requests(爬虫库)
浏览器:Chrome
运用实战来学习爬虫
实战1
爬取网易云音乐
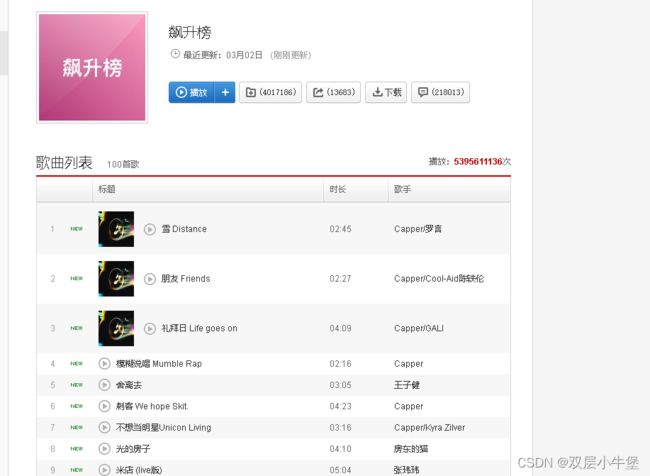
我选择爬取排行榜音乐
我们用Chrome访问这个网站 然后按F12 打开网络
选择Network
然后我们刷新页面
![]()
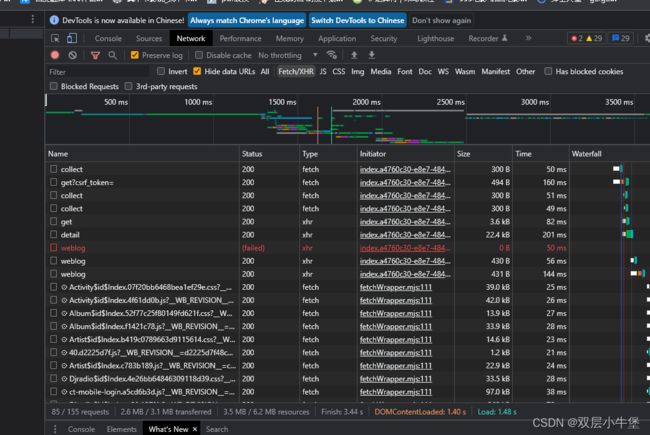
Network出现了一大堆文件 我们应该找哪一个呢 我们就进行查看
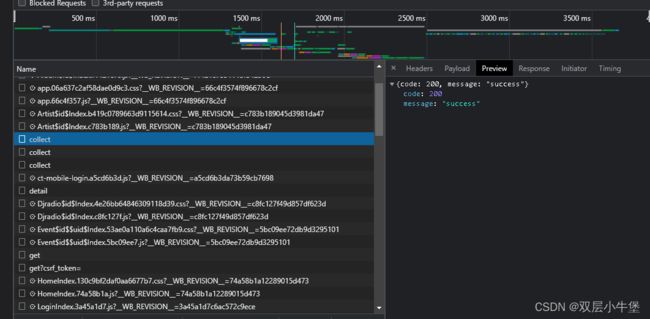
点击其中一个 然后选择Preview进行查看 看看有没有数据是关于音乐的
发现没有 然后我们就思考 我们要的播放界面需要的参数是什么
不然就是瞎找了
找播放接口/下载接口
所以我们随便点开一个歌
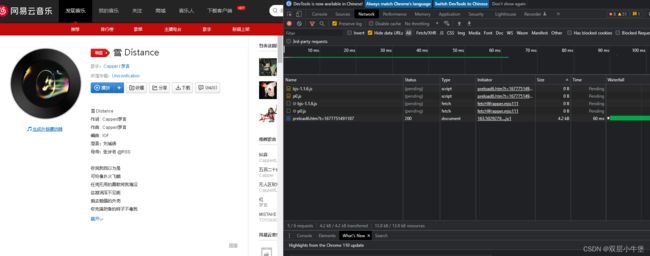
我们先把旁边的得到的数据清空
![]()
在左边第二个我们就可以清空我们现在得到的东西
然后我们点击播放

出现了一大堆东西

第一眼就发现了m4a的文件 我们双击这个文件
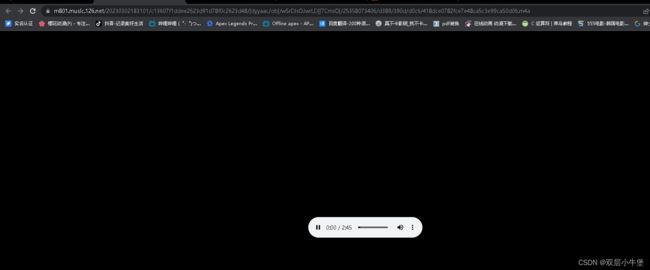
非常完美 我们得到了下载接口
如果我们下载一首歌 我们就可以使用这个接口 但是我们要爬很多歌 我们就要看看这个接口和没每首歌 有什么联系
查看联系
所以我重新找了一首歌
把他的信息记下来
我们在url发现每首歌的url都不一样
并且为get 方式 ?id= 。。。 所以我们记下这个
这一首‘雪’的歌的信息是
https://music.163.com/#/song?id=2026224214
所以我们发现后面的id 2026224214
然后我也卡住了 因为找不到他们之间的关系
我查了一下 有一个固定不变的外链链接 但是我也找不到是怎么发现的
http://music.163.com/song/media/outer/url?id= + 歌曲的id值 + .mp3只要知道id 就可以实现跳转到下载播放接口 所以现在的目标就是把我们要爬取的歌曲
id记下来
爬取歌曲信息

我们使用左上角第一个点击一下我们要的信息

他就会自动在源代码里面给我们找到 所以我们现在就是要爬这个页面的源代码就可以了
所以我们开始写代码
import requests //导入request库
url = 'https://music.163.com/#/discover/toplist' //url
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/109.0'
} //伪造ua
response = requests.get(url=url,headers=headers) // get方式访问url
response.encoding='utf-8' //设置编码方式
content = response.text //以文本显示赋值
print(content) //打印
但是我们在里面搜索发现没有我们要的歌曲信息
所以说明不是这个url
我们再回去查看
对页面右键 发现有一个框架源代码
然后我们在里面搜索歌曲名字 找到了 说明url写错了 我们看上面的url

发现框架源代码 就是少了一个 #
所以把url更改
原本url = 'https://music.163.com/#/discover/toplist'
全新url = 'https://music.163.com/discover/toplist'
我们更改代码尝试
import requests
url = 'https://music.163.com/discover/toplist'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/109.0'
}
response = requests.get(url=url,headers=headers)
response.encoding='utf-8'
content = response.text
print(content)
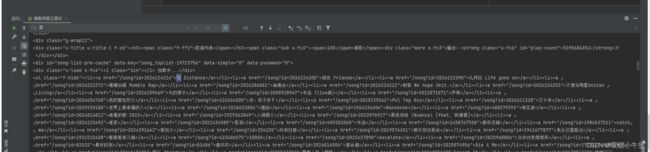
发现了歌曲信息 我们现在对信息执行正则处理
在print 的文本框 点击 然后 CTAL+A全选 复制
然后打开一个正则辅助网站
regex101: build, test, and debug regex
运用网站 我们可以来更便捷的看我们应该如何处理数据
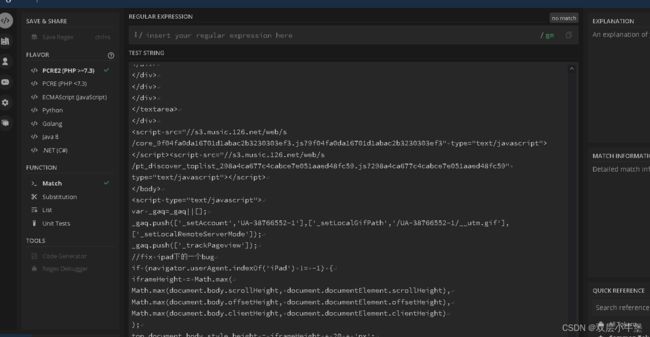
将复制的东西放到下面文件框
然后在上面搜索'雪
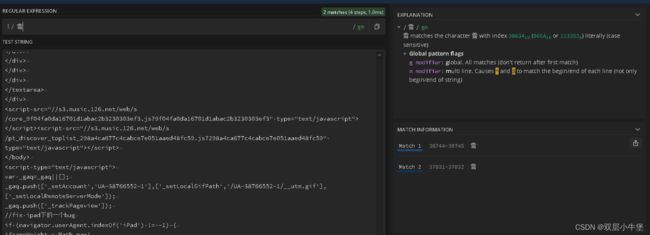 '
'
会发现右边出现了两个 我们点击

他自动会找到这个词
这些是html代码 我们能发现前面有id
html代码都有开始和结尾 我们发现
雪 Distance 以a标签为开头结尾所以我们复制这个
到第一个文本框 这个时候我们要运用万能的(.*?) 通过(.*?) 我们一般都能找到数据

(.*?)<\/a>
//在/song ? /a 前面要加上\
然后我们就可以处理数据了
import re //导入正则
import requests
url = 'https://music.163.com/discover/toplist'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/109.0'
}
response = requests.get(url=url,headers=headers)
response.encoding='utf-8'
content = response.text
new_content = re.findall('(.*?)<\/a>',content)
//re.findall函数处理 re.findall('正则表达式',要处理的数据)
print(new_content)
处理成功

但是我们发现后面有一些我们不想要的东西 怎么去掉呢 正则[:x] 就是只取x和前面的值
我们要看什么时候开始出现我们不要的东西
我们返回之前那个帮助我们处理正则的页面
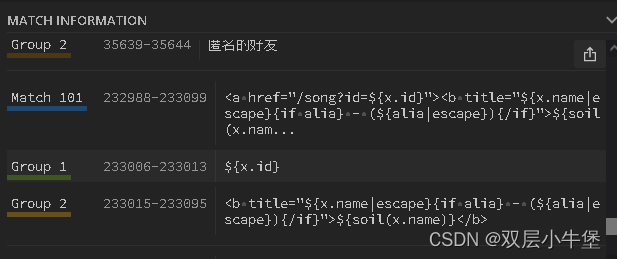
在右边发现我们不要的数据是在101出现的 所以我们[:100]
new_content = re.findall('(.*?)<\/a>',content)[:100]
我们就爬取成功
id 和歌曲名字了
将url自动和id对应上
我们接下来知道啦id 就要运用外链来访问我们下载的网站
import re
import requests
url = 'https://music.163.com/discover/toplist'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/109.0'
}
response = requests.get(url=url,headers=headers)
response.encoding='utf-8'
content = response.text
new_content = re.findall('(.*?)<\/a>',content)[:100]
for info in new_content: //取一个数组 在new_content中循环
really_content = 'http://music.163.com/song/media/outer/url?id='+info[0]
//拼接 将数组info的首项提取出来 就是info[0]
print(really_content)
这样我们就得到了拼接的代码
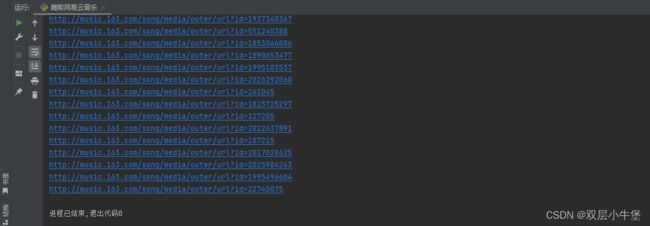
随便点一个都可以访问 证明成功了 接下来 我们就只需要把他们下下来就行了
下载到本地
import re
import requests
url = 'https://music.163.com/discover/toplist'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/109.0'
}
response = requests.get(url=url,headers=headers)
response.encoding='utf-8'
content = response.text
new_content = re.findall('(.*?)<\/a>',content)[:100]
for info in new_content:
really_content = 'http://music.163.com/song/media/outer/url?id='+info[0]
name = info[1]
# print(really_content)
# print(name)
really_content=requests.get(really_content).content //将文件改为二进制代码
# print(really_content) //print 用于测试
with open(f'music/{info[1]}.mp3','wb')as fp:
//保存格式 f'music/{info[1].mp3}' 的意思是保存在music这个文件夹下面
//然后用数组info[1]为名字 wb是用于字节的保存
fp.write(really_content)
这样我们就得到了 mp3文件
结束