类ChatGPT代码级解读:如何从零起步实现transformer、llama/ChatGLM
第一部分 如何从零实现transformer
transformer强大到什么程度呢,基本是17年之后绝大部分有影响力模型的基础架构都基于的transformer(比如,这里有200来个,包括且不限于基于decode的GPT、基于encode的BERT、基于encode-decode的T5等等)
通过博客内的这篇文章《Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT》,我们已经详细了解了transformer的原理(如果忘了,建议先务必复习下再看本文)
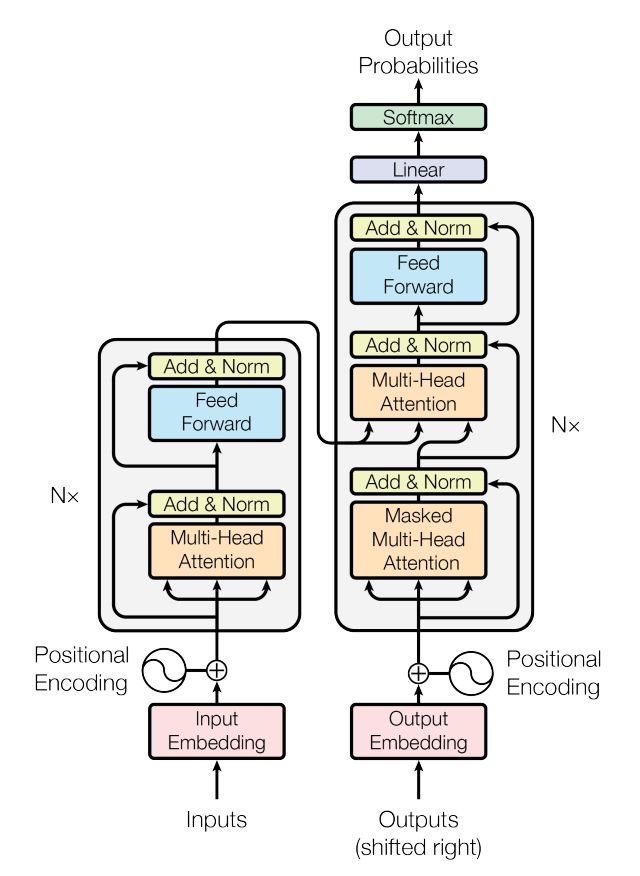
当然,如果你实在忘了,又不想再回过头去看上面那篇transformer笔记,你就只想呆在本文不跳转了(我曾经跨过山和大海,也曾..),也行,咱们一步步结合对应的原理来一步步编码实现
1.1 关于输入的处理:针对输入做embedding,然后加上位置编码
1.1.1 数据处理:向量化表示、分词
首先,先看上图左边的transformer block里,input先embedding,然后加上一个位置编码
这里值得注意的是,对于模型来说,每一句话比如“七月的服务真好,答疑的速度很快”,在模型中都是一个词向量,但如果每句话都临时抱佛脚去生成对应的词向量,则处理起来无疑会费时费力,所以在实际应用中,我们会实现预训练好各种embedding矩阵,这些embedding矩阵包含常用领域常用单词的向量化表示,且提前做好分词
| 教育 | 维度1 | 维度2 | 维度3 | 维度4 | ... | 维度512 |
| 机构 | ||||||
| 在线 | ||||||
| 课程 | ||||||
| .. | ||||||
| 服务 | ||||||
| 答疑 | ||||||
| 老师 | ||||||
| .. |
从而当模型接收到“七月的服务真好,答疑的速度很快”这句输入时,便可以从对应的embedding矩阵里查找对应的词向量,最终把整句输入转换成对应的向量表示
1.1.2 位置编码positional encoding
1.2 encode里的transformer block:
我们聚焦下transformer论文中原图的这部分,可知,输入通过embedding+位置编码后,先做以下两个步骤

- 针对输入query做multi-head attention,得到的结果与原输入query,做相加并归一化
attention = self.attention(query, key, value, mask) output = self.dropout(self.norm1(attention + query)) - 上面步骤得到的输出结果output做feed forward之后,再与上面步骤的原输出结果output也做相加并归一化
forward = self.feed_forward(output) block_output = self.dropout(self.norm2(forward + output))
代码可以如下编写
class TransformerBlock(nn.Module):
def __init__(
self,
hidden_size,
dropout,
forward_expansion
):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(hidden_size)
self.norm1 = nn.LayerNorm(hidden_size)
self.norm2 = nn.LayerNorm(hidden_size)
self.feed_forward = nn.Sequential(
nn.Linear(
hidden_size,
forward_expansion * hidden_size
),
nn.ReLU(),
nn.Linear(
forward_expansion * hidden_size, hidden_size
)
)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask = None):
attention = self.attention(query, key, value, mask)
output = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(output)
block_output = self.dropout(self.norm2(forward + output))
return block_output1.2.2 关键的多头注意力机制multi-head attention
从下图可知,经过embedding + 位置编码的输入进来后,会先分别映射三个矩阵:Q K V
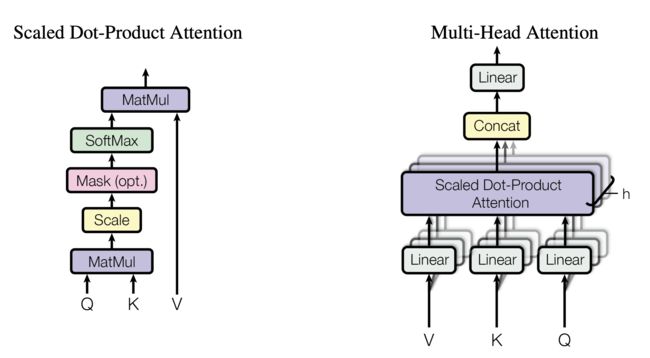
且定义为batch_size,序列的长度分别为q_seq_length,且对应的维度均为hidden_size,比如512维
# query [batch_size, q_seq_length, hidden_size]
query = self.QM(query)
# key [batch_size, k_seq_length, hidden_size]
key = self.KM(key)
# value [batch_size, v_seq_length, hidden_size]
value = self.VM(value)且要注意的是(下图来源)

- Q和K会先做内积 计算相似度,是每个token的q与包括自身在内所有token的k一一做点积
换句话说,矩阵Q(参数为b q h)与K矩阵的转置(参数为b k h)做相乘(得到的结果的参数为b q k)
举个例子,假设一个句子中的单词是:1 2 3 4,则Q乘以K的转置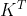 如下图所示
如下图所示
代码则如下编写
# Keep track of the size. QK_prod = torch.einsum('bqh,bkh->bqk', query, key) - 对点积的结果做下缩放,具体是除以
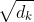

- 接着使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1.
代码则可以如下编写
# word similarities if mask is not None: QK_prod = QK_prod.masked_fill(mask == 0, float('-1e20')) attention = torch.softmax(QK_prod / (self.hidden_size ** 0.5), dim = 2) - 最后再乘以V,下图Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数
对应的示例代码为
# attention,[batch_size, query_length, key_length] output = torch.einsum('bqk,bkh->bqh', attention, value) return output - 最终单词 1 的输出等于所有单词 i 的值 根据 attention 系数的比例加在一起得到,如下图所示:

这部分的完整代码如下所示
class SelfAttention(nn.Module):
def __init__(self, hidden_size):
super(SelfAttention, self).__init__()
self.hidden_size = hidden_size
self.QM = nn.Linear(hidden_size, hidden_size, bias = False)
self.KM = nn.Linear(hidden_size, hidden_size, bias = False)
self.VM = nn.Linear(hidden_size, hidden_size, bias = False)
def forward(
self,
query,
key,
value,
mask = None
):
# It is very true that query, key, value are duplicates of the input, however, this is True only in encoder. In decoder, the attetnion class could also be used, but the difference is that the query is different from key, value.
# query [batch_size, q_seq_length, hidden_size]
query = self.QM(query)
# key [batch_size, k_seq_length, hidden_size]
key = self.KM(key)
# value [batch_size, v_seq_length, hidden_size]
value = self.VM(value)
# Keep track of the size.
QK_prod = torch.einsum('bqh,bkh->bqk', query, key)
# word similarities
if mask is not None:
QK_prod = QK_prod.masked_fill(mask == 0, float('-1e20'))
attention = torch.softmax(QK_prod / (self.hidden_size ** 0.5), dim = 2)
# attention,[batch_size, query_length, key_length]
output = torch.einsum('bqk,bkh->bqh', attention, value)
return output至于多头,则如下图所示

第二部分 如何通过transformer库微调各类LLM
更具体的,Trainer类包括如下关键方法:
__init__:初始化方法,用于创建训练器对象。它接收模型、训练参数、数据集等作为输入,并设置相关属性def __init__( self, model: PreTrainedModel, args: TrainingArguments, train_dataset: Optional[Dataset] = None, eval_dataset: Optional[Dataset] = None, tokenizer: Optional[PreTrainedTokenizerBase] = None, data_collator: Optional[DataCollator] = None, train_iterator: Optional[DataLoader] = None, eval_iterator: Optional[DataLoader] = None, ... ):
train:这个方法负责整个训练过程,它包括遍历数据集、计算损失、计算梯度、更新模型参数以及日志记录等
遍历数据集:train方法通过使用dataloader来遍历训练数据集for step, inputs in enumerate(epoch_iterator):计算损失:损失计算在training_step方法中,接收输入数据并产生预测输出,然后,这个预测输出会与真实输出(标签)进行比较,以计算损失outputs = model(**inputs)上述代码行使用model(已经加载了预训练模型)和inputs(包含输入数据的字典)计算模型的预测输出。这个outputs变量包含模型预测的结果接下来,我们从outputs中获取预测结果,并与真实标签(即labels)进行比较,以计算损失loss = outputs.lossoutputs.loss是模型预测输出和真实输出(标签)之间的损失。这个损失值将用于计算梯度并更新模型参数计算梯度:loss.backward()这行代码计算模型参数关于损失的梯度loss.backward()梯度累积:当gradient_accumulation_steps大于1时,梯度会被累积,而不是立即更新模型参数if (step + 1) % self.args.gradient_accumulation_steps == 0:更新模型参数:optimizer.step()这行代码根据计算出的梯度来更新模型参数self.optimizer.step()学习率调整:lr_scheduler.step()根据预定义的学习率调度策略更新学习率self.lr_scheduler.step()日志记录:log方法用于记录训练过程中的一些关键指标,例如损失、学习率等
evaluate:这个方法用于评估模型在验证数据集上的性能,返回评估结果def evaluate( self, eval_dataset: Optional[Dataset] = None, ignore_keys: Optional[List[str]] = None ) -> Dict[str, float]:
predict:这个方法用于在给定的数据集上进行预测,返回预测结果def predict( self, test_dataset: Dataset, ignore_keys: Optional[List[str]] = None ) -> PredictionOutput:
save_model:这个方法用于将训练好的模型保存到指定的目录def save_model(self, output_dir: Optional[str] = None):
第三部分 如何加速模型的训练以及调优
// 本文正在每天更新中,预计4.16写好初稿..