c语言学习第三十五课——程序环境与预处理
目录
程序的翻译环境与执行环境
预处理详解
1.预定义符号
#define
定义一个标识符 完成替换.
#define 定义宏 替换参数
预处理的操作符#
预处理的操作符##
带副作用的宏参数
宏和函数对比
命名约定
#undef
条件编译
头文件包含
程序的翻译环境与执行环境
在ANSIC的任何一种实现中,存在不同的两个环境:
第一种环境是翻译环境:在这个环境中源代码被转换为可执行的机器指令。
第二中是执行环境:用于执行实际的代码。

我们用图来认识到一个项目是如何编译运行的:
源文件单独通过编译器生成一个目标文件(.obj文件),在利用链接器将众多的可执行程序链接起来
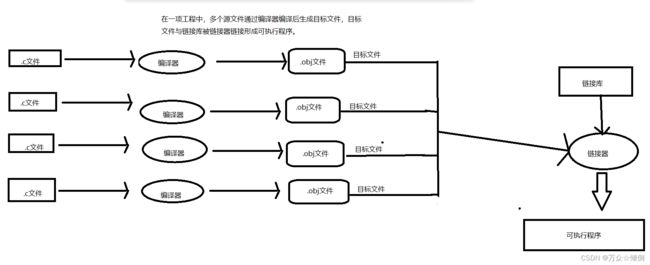
每一个源文件单独经过编译器编译生成对应的目标文件,我们可在源文件下找到这些目标文件。
在vs编译器上:
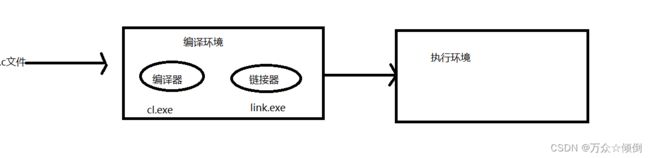
编译器是cl.exe文件,链接器是link.exe文件 。
现在详解一下编译环境下的操作:
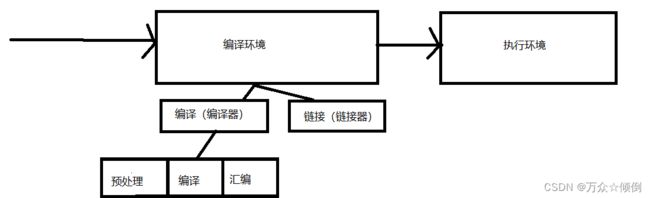
在进入编译时的
编译分三个阶段
预编译 编译 汇编
gcc test.c 预处理中1.头文件的包含 2.注释的删除及define定义的符号的替换/gcc.test.i -S编译过程中会生成一个.s文件,把c语言代码翻译成汇编代码(通过语法分析,词法分析,语义分析,符号汇总等)参考《编译原理》
汇编 gcc.test -C 该过程会生成一个test.o的文件,在gcc中就是目标文件-一个二进制文件,所以会变就是把汇编代码转换为二进制指令,形成符号表。
预处理阶段会做三个事: 编译做的事: 汇编做的事:



这里的编译,感兴趣可以去看《程序员的自我修养》,里面会详细讲到如何翻译成汇编代码。
这里的汇编,会形成符号表。
之后在进行链接: 
链接 链接所有的.o的可执行文件,包括库形成可执行程序 1.合并段表 2.符号表的合并与重定位
符号(一般是全局变量的与函数的名称)。将这些符号汇总到一起,形成符号表。
因为文本文件的格式是elf格式
合并段表,把对应的段的数据合并到一起
在形成符号表时分模块,static修饰外部链接属性为内部连接属性,即他们符号表合并到一起。
与链接库链接生成可执行文件。
整个过程可理解为就是将高级语言转化位低级语言给计算机识别:

在程序执行的过程中:
1.程序必须载入内存,再有操作系统的环境中:一般由这个操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
2.程序的执行便开始调用main函数。
3开始执行程序代码时,这个时候程序将使用一个运行堆栈,存储函数的局部变量和返回值地址,程序同时也可以使用静态内存,存储在静态内存中的变量在整个程序中保存着他们的值。
4.终止程序,正常种植main函数,亦有可能是意外终止。
预处理详解
1.预定义符号
__LINE__ //文件当前行号
__FUNCTION__//
__FILE__ //进行的源文件
__DATA__ //文件被编译的日期
__FUNCDNAME__//
__TIME__ //文件被编译的时间
等都是可以展示该文件的属性的指令
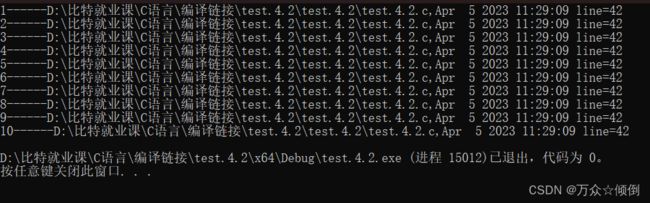
#include
int main()
{
int i;
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (i = 0; i < 10; i++)
{
printf("%d------%s,%s %s line=%d\n", arr[i], __FILE__, __DATE__, __TIME__, __LINE__);
}
return 0;
}
#define
定义一个标识符 完成替换.
这里 \为续行符 在代码后 \之后可以换行,表示还是在一行上。
//在有些计算机语言没有break语句,但在c语言里是必须要有break语句来结束case语句。
//有人就会定义宏来实现不去写break语句
#define CASE break;case
int main()
{
int n=0;
scanf("%d",&n);
switch(n)
{
case 1:
//....
CASE 2:
//.....
CASE 3:
//.....
break;
}
return 0;
}
#define 定义宏 替换参数
实现一个数的平方
#define POW(x) x*x
int main()
{
printf("%d", POW(8));
return 0;
}预处理的操作符#
define print_format(num,format) printf("the value of "#num" is "format,num)
#的作用是不是替换内容,而是变成对应的字符串
int main()
{
int a = 10;
printf("the value of a is %d", a);
int b = 20;
printf("the value of b is %d", b);
//我们可以这样写
print_format(a, "%d\n");
}预处理的操作符##
可以把位于它两边的符号合成一个符号
int Class110 = 2023;
#define CAT(x,y) x##y
int main()
{
printf("%d\n", CAT(Class, 110));//2023 前提是合成的符号具有意义
return 0;
}带副作用的宏参数
#define MAX(x,y) ((x)>(y)?(x):(y))
int main()
{
//这里想求最大值
int a = 3;
int b = 5;
int c = MAX(3, 5);
//int c=((3++)>(5++)?(3++):(5++))
//这里反而不能实现最大值的求解
printf("%d\n", c);//6
printf("%d\n", a);//4
printf("%d\n", b);//7
return 0;
}我们从中可以发现。在定义宏参与运算时,我们最好加上括号,防止因为运算优先级而出现问题,因为宏的作用仅仅是替换。
宏和函数对比
1.调用函数的从函数返回的代码比实际执行这个计算需要的时间多。考虑函数栈帧,调用前到运行结束都是需要花费时间的而宏只有主要运算,时间更短,效率更高。
2.宏无类型,函数传参还需定义类型宏的替换可以是类型
如 #define MALLOC(num,type) (type*)malloc(num,sizoef(type))
3.但是宏只能实现简单的效果,若一个程序实现复杂,宏需多次定义
4.宏无法调试,与类型无关,当然也不够严谨
5.宏会带来运算符优先级的问题
命名约定
宏名都是大写
函数一般部分字母大写
#undef
取消符号的宏定义
#define MAX 100
#undef MAX;
int main()
{
int a = 0;
int b = a + MAX;
printf("%d", b);
return 0;
}
这里的MAX未被定义
条件编译
#if #endif #if define #if !define
满足条件可以进入编译 不满足不进入编译
#if (条件)//条件一般为常量表达式
.....
#endif
//多分支
#if (条件)
....
#elif(条件)
.........
#endif
//判断是否被定义
#if defined (定义的变量)
......
#endif
//如果定义了MAX,语句参与编译
//如果没定义,语句参与编译
#if !defined(定义的变量)
...
#endif
#ifndef MAX
....
#endif
头文件包含
头文件分两种:
库文件#include
当前文件#include"file name"
对于两者的区别:
" "先在文件路径查找之后才在库文件查找。
<>包含的头文件会直接去库文件里调用。
我们一般不去将库函数的头文件用“”来调用,这样反而效率会变低。
若头文件被重复包含,里面的内容也被重复的调用进来
可以定义#pragma once #define __TEST.H__,(头文件)这样重复包含也只调用一次
其他还有许多预处理指令,详见高质量c++/c编程