openCV 自学笔记
opencv官方文件
一:Mac下命令方式搭建opencv开发环境
1.安装homebrew 在终端输入homebrew下的命令
2.根据提示配置环境
3.通过以下两个命令安装配置环境
brew install [email protected]
pip3 install numpy matplotlib opencv_python
配置完成后可顺利导入相应包即可
opencv开发工具:pyсharm vscode
利用开发工具尝试的第一个小例子:通过CV2打开一张图片,现实时长用waitKey
如果小写会出现以下错误提示:AttributeError: module 'cv2' has no attribute 'waitkey'

Mac系统下可以直接 mkdir&&cd&&code.
然后进入代码编写即可
二:车辆检测
1.窗口的展示
1.1:创建和显示窗口
namedWindow()
imshow()
destoryAllWindows()
resizeWindows 具体参数可以下载master opencv 进行查看
import cv2
cv2.namedWindow('new',cv2.WINDOW_NORMAL) #创建窗口
cv2.resizeWindow('new',1920,1080)#resize窗口的大小
cv2.imshow('new',0) #展示窗口
key=cv2.waitKey(0)#设置展示窗口的时长 单位毫秒
if (key == 'q'):#接受键盘信息 如果输入q 结束窗口展示
exit()
cv2.destroyAllWindows() #释放掉所有窗口资源设置鼠标回调函数
setMouseCallback(winname,callback,userdate) 窗口名字 回调函数 参数
callback (event,x, y, flags, userdate) 事件(左键 右键) 坐标位置
opencv控制鼠标:
import cv2
import numpy as np
from cv2 import resizeWindow
#设置函数
def mouse_callback(event,x,y,flags,userdata):
print(event,x,y,flags,userdata)
#mouse_callback(1,100,100,16,"666")
#创建窗口
cv2.namedWindow('mouse',cv2.WINDOW_NORMAL)
cv2,resizeWindow('mouse',640,360)
#设置鼠标回调
cv2.setMouseCallback('mouse',mouse_callback,"123")
#显示窗口和背景
img =np.zeros((360,640,3),np.uint8) #与窗口的长宽比是相反的360 640
while True:
cv2.imshow('mouse',img)
key = cv2.waitKey(1)
if key & 0xFF == ord('q'):
break
cv2.destroyAllWindows()2.图像视频的加载(imread)
2.1:imread
im == image
imread(path,flag)
加入图片可能存在的问题:
import cv2
from cv2 import WINDOW_NORMAL
cv2.namedWindow('img',cv2.WINDOW_NORMAL)
img=cv2.imread('/Users/wangcc/Desktop/截屏2022-07-22 下午2.56.35.png')#读入图片
cv2.imshow('img',img)
key=cv2.waitKey(0)
print(key)
print('q')
print(ord('q'))
if(key & 0xFF ==ord('q')): #最好更改成这样 这样才能真正进入退出的代码段执行
print(1111)
cv2.destroyAllWindows()#直接替换exit()
保存图片:
imwrite(name,img). name:要保存的文件名。img:是mat类型
import cv2
from cv2 import WINDOW_NORMAL
cv2.namedWindow('img',cv2.WINDOW_NORMAL)
img=cv2.imread('/Users/wangcc/Desktop/截屏2022-07-22 下午2.56.35.png')#读入图片
while True:#加了while循环
cv2.imshow('img',img)
key=cv2.waitKey(0)
if(key &0xFF ==ord('q')):
break
elif(key &0xFF ==ord('s')):
cv2.imwrite('/Users/wangcc/Desktop/截屏2022-07-22 下午2.56.35.jpeg',img)
cv2.destroyAllWindows()2.2:视频采集:
VideoCapure()
cap.read() 返回两个值,第一个为状态值,读到帧为true,第二个值为视频帧
cap.release()
import cv2
#创建窗口
cv2.namedWindow('video',cv2.WINDOW_NORMAL)
cv2.resizeWindow('video',640,480)
#获取视频设备
cap = cv2.VideoCapture(0)
while True:
ret,frame=cap.read() #从设备中(摄像头)读取数据 视频帧
#一帧一帧的读 循环所以形成了视频
cv2.imshow('video',frame) #将获得的视频帧在窗口中显示
key = cv2.waitKey(10)#等待键盘事件,如果为q退出
if(key & 0xFF == ord('q')):
break
#释放videoCapture
cap.release()
cv2.destroyAllWindows()如何视频文件中读取视频帧:只需在cv2.VideoCapture中写入视频地址即可
#获取视频设备/从视频文件中读取视频帧
cap = cv2.VideoCapture('/Users/wangcc/Desktop/opencv/IMG_5091.MOV')2.3:如何将视频数据录制成多媒体文件
VideoWriter 参数一位输出文件 参数二为多媒体文件格式(VideoWriter_fourcc)帧率➕分辨率
write
release
#创建VideoWriter为写多媒体文件
fourcc=cv2.VideoWriter_fourcc(*'MJPG')#创建fourcc
vw=cv2.VideoWriter('./out.mp4',fourcc,25,(1280,720))
#某一路径下 fourcc 帧率 分辨率要与自己摄像头的分辨率一样
#写数据到多媒体文件
vw.writer(frame)
#释放VideoWriter资源
vw.release()import cv2
#创建VideoWriter为写多媒体文件
fourcc=cv2.VideoWriter_fourcc('M','J','P','G')#创建fourcc
vw=cv2.VideoWriter('/Users/wangcc/Desktop/opencv',fourcc,25,(1296,694)) #某一路径下 fourcc 帧率 分辨率
#创建窗口
cv2.namedWindow('video',cv2.WINDOW_NORMAL)
cv2.resizeWindow('video',640,360)
#获取视频设备/从视频文件中读取视频帧
#cap = cv2.VideoCapture('/Users/wangcc/Desktop/opencv/IMG_5091.MOV')
cap = cv2.VideoCapture(0)
while cap.isOpened(): #判断摄像头是否为打开状态
ret,frame=cap.read() #从设备中(摄像头)读取数据 视频帧
if ret == True:
cv2.imshow('video',frame) #将获得的视频帧在窗口中显示
cv2.resizeWindow('video',640,360) #重新将窗口设置为指定大小
#写数据到多媒体文件
vw.writer(frame)
key = cv2.waitKey(1)#等待键盘事件,如果为q退出
if(key & 0xFF == ord('q')):
break
else:
break
#释放videoCapture
cap.release()
#释放VideoWriter资源
vw.release()
cv2.destroyAllWindows()TrackBar控件:
createTrackBar 参数trackbarname(控件名), winname(窗口名),value:trackbar当前值
count:最小值为0,最大值为count。callback,userdate
getTrackbarPos 参数:输入值trackbarname,winname. 输出:当前值
import cv2
import numpy as np
def callback():
pass
#创建窗口
cv2.namedWindow('trackbar',cv2.WINDOW_NORMAL)
#创建trackbar
cv2.createTrackbar('R','trackbar',250, 255, callback)
cv2.createTrackbar('G','trackbar',100, 255, callback)
cv2.createTrackbar('B','trackbar',100, 255, callback)
#设置一个纯黑色的背景
img = np.zeros((480,640,3),np.uint8)
while True:
#获取当前trackbar的值
r = cv2.getTrackbarPos('R','trackbar')
g = cv2.getTrackbarPos('G','trackbar')
b = cv2.getTrackbarPos('B','trackbar')
#改变背景图片颜色
img[:] = [b, g, r]
cv2.imshow('trackbar',img)
key = cv2.waitKey(10)
if key & 0xFF == ord('q'):
break
cv2.destroyAllWindows()3.基本图形的绘制
3.1:openCV的色彩空间
openCV默认使用BGR
YUV:用在视频中 4:2:0 4:2:2 4:4:4
HSV 与 HSL:
Hue:色相,即色彩,如红色,蓝色
Saturation:饱和度,颜色的纯度
Value:明度 Lightness:
openCV色彩空间的转换
#颜色空间转换
cvt_img = cv2.cvtColor(img,colorspaces[index])import cv2
def callback():
pass
cv2.namedWindow('color',cv2.WINDOW_NORMAL)
img = cv2.imread('/Users/wangcc/Desktop/截屏2022-07-22 下午2.56.35.png')
colorspaces=[cv2.COLOR_BGR2RGBA,cv2.COLOR_BGR2BGRA,cv2.COLOR_BGR2GRAY,cv2.COLOR_BGR2YUV]
cv2.createTrackbar('curcolor','color',0,len(colorspaces),callback)
while True:
index = cv2.getTrackbarPos('curcolor','color')
#颜色空间转换
cvt_img = cv2.cvtColor(img,colorspaces[index])
cv2.imshow('color',img)
key = cv2.waitKey(10)
if key & 0xFF == ord('q'):
break
cv2.destroyAllWindows()Numpy创建矩阵:
创建数组array()
创建全0数组 zeros()/ones
创建全值数组full()
创建单元数组identity()/eye()
import numpy as np
a = np.array([2,3,4])
b = np.array([[1,2,3],[4,5,6]])
#(480,640,3)(行的个数,列的个数,通道数/ 层数) np.uint8矩阵中的数据类型
c = np.zeros((480,640,3),np.uint8)
#ones矩阵
d = np.ones((8,8,3),np.uint8)
#full矩阵 255 是矩阵中的数值
e = np.full((8,8),255,np.uint8)
#单位矩阵identity
f = np.identity(4)
#eye 矩阵
g = np.eye(3,5,k=1)
print(g)numpy的检索与赋值
import cv2
img = np.zeros((480,640,3),np.uint8)
print(img[100,100])
count =0
while count < 400:
img[count,400,2] = 255
#img[count,400] = [0,0,255] 多通道赋值的两种方法
count = count + 1
cv2.imshow('img',img)
key = cv2.waitKey(0)
if key & 0xFF == ord('q'):
cv2.destroyAllWindows()
Region of image(RIO) 图形的绘制
获取子矩阵
[y1:y2,x1:x2] 取某一部分 [:,:] 全部矩阵
import cv2
img = np.zeros((480,640,3),np.uint8)
# print(img[100,100])
# count =0
# while count < 400:
# img[count,400,2] = 255
# #img[count,400] = [0,0,255]
# count = count + 1
roi = img[200:400,200:400]
roi[:,:]=[0,255,0]
roi[50:100,50:100]=[0,0,255]
cv2.imshow('img',roi)
key = cv2.waitKey(0)
if key & 0xFF == ord('q'):
cv2.destroyAllWindows()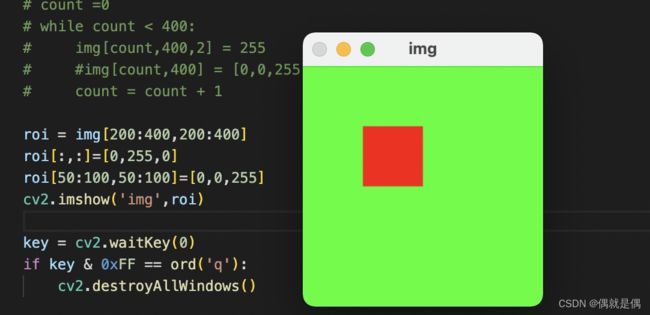
Mat 属性

mat的深浅拷贝
浅拷贝:
Mat A
A = imread(file, IMREAD_COLOR)
Mat B(A); B与A的Header不同,但指向的数据相同
深拷贝:
C++中实现方式有两种
cv ::Mat::clone()
cv::Mat::copyTo()
将DATA也重新赋值一份,A与B完全切断
python中实现:
copy(),使用该方法就是深拷贝
进行深拷贝后,进行图片的处理时不影响原图片,cv2.add也是深拷贝操作
import cv2
from cv2 import resizeWindow
import numpy as np
img = cv2.imread('/Users/wangcc/Desktop/截屏2022-07-22 下午2.56.35.png')
resizeWindow
img1 = img# 浅拷贝
img2 = img.copy() #深拷贝 即使图片做了改变,但拷贝的是原图片
img[100:400,100:400] = [255,0,0]
cv2.imshow('img',img)
cv2.imshow('img1',img1)
cv2.imshow('img2',img2)
cv2.waitKey(0)访问图像的属性:
import cv2
import numpy as np
img = cv2.imread('/Users/wangcc/Desktop/截屏2022-07-22 下午2.56.35.png')
print(img.shape)
print(img.size)
print(img.dtype)通道的分离与合并:
split(mat)
merge((ch1,ch2,...)
import cv2
import numpy as np
img = np.ones((640,480,3),np.uint8)
b,g,r=cv2.split(img)
b[100:400,100:400] = 255
g[100:400,100:400] = 255
img1=cv2.merge((b,g,r))
cv2.imshow('img',img)
cv2.imshow('b',b)
cv2.imshow('g',g)
cv2.imshow('img1',img1)
cv2.waitKey(0)图形的绘制:
画线:
cv2.line(img,(10,20),(300,400),(0,0,255),5,4). 背景,x坐标,y坐标,颜色,线宽,线型。
画圆:
cv2.circle(img,中心点,半径,颜色,线型(-1填充)......)
画椭圆:
cv2.ellipse(img,中心点,长宽的一半,角度,从哪个角度开始(按顺时针),到那个角度结束.....)
画多边形:
pts=np.array([(),(),()],np.int32). 必须是int32 位
cv2.polylines(img,点集[pts],是否闭合(true false),颜色)
填充多边型:cv2.fillpoly(img,[pts],(0,0,255))
画文本:
cv2.putText(img,字符串,起始点,字体(cv2.FONT_HERSHEY_PLAIN),字号,颜色.....)
import cv2
import numpy as np
img = np.zeros((480,640,3),np.uint8)
#画线,画圆,画椭圆
cv2.line(img,(10,10),(400,400),(0,0,255),4,8)
cv2.circle(img,(300,300),100,(255,0,0),-1)
cv2.ellipse(img,(200,200),(150,50),45,0,300,(0,255,0),-1)
#绘制多边形
pots = np.array([(10,10),(10,110),(110,110),(110,10)],np.int32)
cv2.polylines(img,[pots],True,(0,0,255))
#cv2.fillpoly(img,[pots],(255,0,0))
#绘制文本
cv2.putText(img,'openCV',(1,300),cv2.FONT_HERSHEY_SIMPLEX,5,(0,0,255))
cv2.imshow('img',img)
cv2.waitKey(0)鼠标回调函数画图:
import cv2
import numpy as np
curshape = 0
startpos =(0,0)
#鼠标回调函数
def mouse_callback(event,x,y,flags,userdate):
global curshape,startpos
if(event & cv2.EVENT_LBUTTONDOWN == cv2.EVENT_LBUTTONDOWN):
startpos = (x,y)
elif(event & cv2.EVENT_LBUTTONUP == cv2.EVENT_LBUTTONUP):
if curshape == 0:
cv2.line(img,startpos,(x,y),(0,0,255))
elif curshape == 1:
cv2.rectangle(img,startpos,(x,y),(0,0,255))
elif curshape == 2:
a = (x-startpos[0])
b = (y-startpos[1])
r=int((a**2+b**2)**0.5)
cv2.circle(img,startpos,r,(0,0,255))
else:
print('error')
#创建窗口
cv2.namedWindow('drawshape',cv2.WINDOW_NORMAL)
#设置鼠标回调
cv2.setMouseCallback('drawshap',mouse_callback)
#显示窗口和背景
img =np.zeros((480,640,3),np.uint8) #与窗口的长宽比是相反的360 640
while True:
cv2.imshow('drawshap',img)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key == ord('l'): #line
curshape = 0
elif key == ord('r'): #rect
curshape = 1
elif key == ord('c'): #circle
curshape = 2
cv2.destroyAllWindows()4.车辆识别
第一章:基本图像运算与处理
1.图像的加法运算(图更亮)
cv2.add(dog,img). dog+img
2.图像的减法运算(图更暗)
subtract(A,B) A-B
3.图像的乘与除
multiply(A,B)
divide(A,B)
4.图像位运算(与,或,非,异或)
非:bitwise_not(img)
与:bitwise_and(img1,img2). 找出图片的交叉点
或:bitwise_or(img1,img2)
异或:bitwise_xor(img1,img2)
import cv2
from cv2 import waitKey
import numpy as np
img = cv2.imread('/Users/wangcc/Desktop/截屏2022-07-22 下午2.56.35.png')
print(img.shape)
back = np.ones((694,1296,3),np.uint8)*20
add = cv2.add(img,back)
sub = cv2.subtract(img,back)
mul = cv2.multiply(img,back)
div = cv2.divide(img,back)
no = cv2.bitwise_not(img)
cv2.imshow('no',no)
# cv2.imshow('add',add)
# cv2.imshow('sub',sub)
# cv2.imshow('mul',mul)
# cv2.imshow('div',div)
# cv2.imshow('img',img)
# cv2.imshow('back',back)
cv2.waitKey(0)给图片添加水印
import cv2
import numpy as np
img = cv2.imread('/Users/wangcc/Desktop/截屏2022-07-22 下午2.56.35.png')
print(img.shape)
logo = np.zeros((200,200,3),np.uint8)
mask = np.zeros((200,200),np.uint8)
logo[20:100,20:100] = (0,0,255)
logo[80:160,80:160] = (255,0,0)
mask[20:100,20:100] = 255
mask[80:160,80:160] = 255
#对mask按位求反
m = cv2.bitwise_not(mask)
#选择logo粘贴的位置
roi = img[0:200,0:200]
#con = cv2.add(logo,mask)
#对m进行与操作
tmp = cv2.bitwise_and(roi,roi,mask=m)
dst = cv2.add(tmp,logo) #保留不是黑的部分
#将dst赋值给img
img[0:200,0:200] = dst
cv2.imshow('img',img)
cv2.imshow('dst',dst)
cv2.imshow('tmp',tmp)
cv2.imshow('mask',mask)
cv2.imshow('roi',roi)
cv2.imshow('logo',logo)
cv2.waitKey(0)图像的基本变换:
图像的缩放:resize(src,dst,dsize,fx,fy,interpolation)
src:源图片,dst;目的 [dsize:目标的大小 fx:fy: x y 轴的缩放因子],
interpolation:缩放算法
INTER_NEAREST 领近插值, INTER_LINEAR 双线性插值,INTER_CUBIR:三次插值
INTER_AREA:双线性插值,原图中的四个点
INTER_CUBIC:三次插值,原图中的16个点
INTER_AREA:效果最好
import cv2
import numpy as np
img = cv2.imread('/Users/wangcc/Desktop/截屏2022-07-22 下午2.56.35.png')
new = cv2.resize(img,(300,200))
new1 = cv2.resize(img,None,fx=0.3,fy=0.3,interpolation=cv2.INTER_AREA)
cv2.imshow('new',new)
cv2.imshow('new1',new1)
cv2.waitKey(0)图像的翻转:
flip(img,flipcode). flipcode==0,上下翻转,flipcode>0左右 flipcode<0,上下+左右
图像的旋转:
rotate(img,rotateCode)
ROTATE_90_CLOCKWISE ROTATE_180 ROTATE_90_COUNTERCLOCKWISE
顺时针方向90度。 顺时针180度 逆时针90度
图像的仿射变换:(图像旋转 缩放 平移的总称)
warpAffine(src,M,dsize,flags,mode,value)
M:变换矩阵 dsize:输出图片尺寸大小 flags:与resize中的插值算法一样
mode:边界外推法标志 Value:填充边界的值
变换矩阵M:
getRotationMatrix2D(center,angle,scale)
center:旋转的中心点 angle:旋转的角度 scale;放大缩小
M = cv2.getRotationMatrix2D((500,500),90,0.5)如果想改变图片的尺寸,需要改变dsize的数值。
getAffineTransform(src[],dts[])
src[]: 原图片中的三个点 与新图片中的三个点一一对应
h,w,ch =img.shape
#M = cv2.getRotationMatrix2D((w/2,h/2),90,0.5)
#M = np.float32([[1,0,100],[0,1,100]])
src = np.float32([[200,400],[200,800],[400,400]])
dts = np.float32([[100,300],[100,700],[300,200]])
M = cv2.getAffineTransform(src,dts)
new = cv2.warpAffine(img,M,(w,h))
透视变换
warpPerspective(img,M,dsize....)
变换矩阵:getPerspectiveTransform(src,dst) 四个点:图形的四个点
src = np.float32([[100,400],[100,800],[400,400],[400,800]])
dst = np.float32([[100,300],[100,700],[300,200],[300,300]])
M = cv2.getPerspectiveTransform(src,dst)
new1 = cv2.warpPerspective(img,M,(200,200))
图像卷积
fliter2D(src, ddepth, kernel, anchor, delta, borderType)
src:源图像, ddepth:位深多少位(-1 与源图像一致)kernel:卷积核
anchor:锚点 图中心点(可以不设)delta:默认0 borderType:默认 不设
import cv2
import numpy as np
img = cv2.imread('/Users/wangcc/Desktop/截屏2022-07-22 下午2.56.35.png')
kernel = np.ones((5,5),np.float32)/25
dst = cv2.filter2D(img,-1,kernel) #效果让图像更平滑了
cv2.imshow('dst',dst)
cv2.imshow('img',img)
cv2.waitKey(0)低通滤波:作用降噪
方盒滤波与均值滤波
normalize = true, a=1/W*H [方盒滤波等于均值滤波】
noramlize = false, a = 1,
boxFliter(src,ddepth,ksize,anchor,normalize,boderType) 方盒滤波
src, 源图
ddepth, 位深
ksize, 卷积核大小
anchor,锚点:默认-1
normalize, :True. Flase
boderType:
blur(src,ksize,anchor,boderType) 均值滤波 大多数情况下直接使用均值滤波代替方盒滤波
dst = cv2.blur(img,(5,5)) #均值滤波卷积核为:a=1/W*H。 a*[5乘5的矩阵]
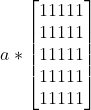
高斯滤波:
作用:解决高斯噪音
GaussianBlur(img,kernel,sigmaX,sigmaY,.....)
源图,卷积核,到中心点的误差,
代码:
中值滤波:
可以很好的处理图片中的胡椒噪点
API: medianBlur(img,ksize) ksize:卷积核的大小 单值
代码:
双边滤波:
作用:美颜
API:bilateralFilter(img,d,sigmaColor,sigmaSpace,....)
img:图像, d:直径,sigmaColor:颜色的sigma,空域核 sigmaSpace:空间核sigma
代码:
高通滤波:作用:检测边缘
Sobel(索贝尔)高斯:可改变卷积核大小,3*3的卷积核无沙尔效果好,只能求一个方向的边缘。
1: 先向X方向求导,然后在Y方向求导,最终结果:|G| = |Gx|+|Gy| CV2.add(d1,d2)
2:API:Sobel(src,ddepth,dx,dy,ksize=3,scale=1,delta=0,borderType =BORDER_DEFAULT)
当scale=-1,则为Scharr, 对X求导检测出Y方向边缘, 对Y求导显示X边缘
代码:
Scharr(沙尔):不可改变卷积核大小,与Sobel类似,只不过是Kernel值不同
1:API:Scharr(src,ddepth,dx,dy,scale=1,delta=0,borderType =Border_DEFAULT)
2: 可识别很细的边界
代码:
Laplacian(拉普拉斯),可同时求X,Y方向的边缘,但自身没有降噪功能,在使用之前需要先手工降噪
1:API:Laplacian(img,ddepth,kszie = 1, scale = 1,borderType = BORDER_DEFAULT)
代码:
边缘检测Canny:终极边缘检测大法
1:使用5*5高斯滤波消除噪声
2:计算图像梯度的方向(0°/45°/90°/135°)
3:取局部最大值
4:canny阈值计算 轮廓
API:Canny(img, minVal.maxVal,....)最小阈值,最大阈值
第二章:形态学
知乎关于形态学的介绍 包含代码
什么是形态学处理:
1:基于图像形态进行处理的一些基本方法;比如识别杯子的位置
2:这些处理方法基本是对二进制图像进行处理:也就是黑白图片
二值化:将图像的每个像素变成两种值,如0,255
全局二值化:API:threshold(img,thresh,maxVal,type)
img:图像,最好是灰度图,thresh:阈值 ,maxVal:超过阈值,替换成maxVal
type:THRESH_BINARY和THRESH_BINAPY_INV
二进制 低于阈值变最小值,反之最大值
THRESH_TRUNC THRESH_TOZERO 和 THRESH_TOZERO_INV

代码:
自适应阈值:
API:adaptiveThreshold(img,maxVal,adaptiveMethod,type,blockSize,C) adaptiveMethod:计算阈值的方法。
ADAPTIVE_THRESH_MEAN_C:计算邻近区域的平均值作为阈值
ADAPTIVE_THREAH_GASSIAN_C:高斯窗口加权平均值
Type: THRESH_BINARY THRESH_BINARY_INV
blockSize:邻近区域的大小
C:常量,应从计算出的平均值和加权平均值中减去
代码:
3:卷积核决定这图像处理后的效果
处理方法:
1:腐蚀(缩小)与膨胀(变大)
腐蚀:只有在卷积核所覆盖区域全大于1时,卷积核中心位置覆盖的点保留原色
API:erode(img,kernel,iterations=1) 原图像 卷积核 腐蚀次数
获得卷积核:getStructuringElemrnt(type,size)
type:MORPH_RECT(矩形 MORPH_ELLIPSE(椭圆形) MORPH_CROSS(交叉 矩形kernel腐蚀最严重
膨胀:只要卷积核中心覆盖的值不为0,其周边值都改变成非0,卷积核越大,膨胀越快
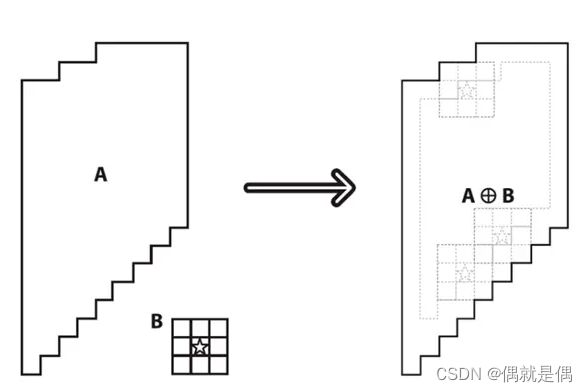
API:dilate(img,kernel,iterations=1)
2:开运算:先腐蚀再膨胀
效果:去除噪点 API:(img,MORPH_OPEN,kernel) 噪点越大 核设置越大
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel, 1)3:闭运算:先膨胀在腐蚀
分析: 字体不改变的前提下,我们把字体缺陷信息补全。
4:形态学梯度:
梯度计算主要显示的是边缘信息。计算的方法:
膨胀的图像 - 腐蚀的图像
我们明显的看出,用大一圈的图像减去小一圈的图像正好就是边缘的信息。
gradient = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel)
cv_show(gradient)5:顶帽:TOPHAT
高帽计算:原始图像 - 开运算结果
我们知道开运算的结果就是去除毛刺,
我们原始图像减去开运算结果就是我们要消除的毛刺信息。
top_hat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
ss = np.hstack((img, top_hat))
cv_show(ss)结果:得到噪点
6:黑帽: MORPH_BLACKHAT
黑帽计算:闭运算结果 - 原始图像
显示缺陷
black_hat = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)
ss = np.hstack((img, black_hat))
cv_show(ss)import cv2
from cv2 import ADAPTIVE_THRESH_GAUSSIAN_C
from cv2 import getStructuringElement
from cv2 import MORPH_CROSS
from cv2 import MORPH_OPEN
import numpy as np
img = cv2.imread('/Users/wangcc/Desktop/opencv/bc036515-ed41-dd06-dd78-203de60d2a22.jpeg')
img1 = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #二值化处理
dst=cv2.adaptiveThreshold(img1,255,ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,7,0)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3))#获得卷积核
dst1 = cv2.erode(dst,kernel,iterations=1) #腐蚀操作
dst2 = cv2.dilate(dst1,kernel,iterations=1) #膨胀操作
kernel1 = cv2.getStructuringElement(cv2.MORPH_RECT,(2,2))#得卷积核
opening = cv2.morphologyEx(dst2,cv2.MORPH_OPEN,kernel1,2)#开运算
close = cv2.morphologyEx(opening,cv2.MORPH_CLOSE,kernel1,1)#闭运算
cv2.imshow('dst1',dst1)
cv2.imshow('dst2',dst2)
cv2.imshow('opening',opening)
cv2.imshow('close',close)
new=cv2.morphologyEx(dst,cv2.MORPH_OPEN,(7,7),1)
# cv2.imshow('gray',img1) #二值化
# cv2.imshow('img',img)
# cv2.imshow('bin',dst) #显示处理后的二值图
# cv2.imshow('new',new)
cv2.waitKey(0)第三章:轮廓查找
轮廓查找的API:
contours,hierarchy=findContours(img,mode,ApproximationMode) 两个返回值
轮廓 层级
mode:RETR_EXTERNAL=0 表示只检测外轮廓
RETR_LIST=1 检测的轮廓都表示出来 没有等级关系
RETR_CCOMP=2,每层最多两级
RETR_TREE=3 按树形存储轮廓
ApproximationMode
CHAIN_APPROX_NONE 保存所有轮廓上的点
CHIAN_APPROX_SIMPLE 只保存角点
绘制轮廓的API:
drawContours(img,contours,contourIdx,color,thickness....)
contourIdx:-1表示绘制所有轮廓 轮廓的顺序号具体展示轮廓 第一个0 第二个1
color:轮廓的颜色(0,0,255)
thickness:线宽,1比较细 -1全部填充
轮廓的面积和周长:
应用:通过面积小于多少,过滤出查找的轮廓
已知其中一个面积的真实值,通过比列计算出其他未知的轮廓面积周长
,面积API:contourArea(contour)
周长API: arcLength(curve,closed) curve:轮廓 closed:是否闭合 true闭合
代码:
import cv2
from cv2 import waitKey
from cv2 import RETR_LIST
from cv2 import CHAIN_APPROX_NONE
from cv2 import ADAPTIVE_THRESH_GAUSSIAN_C
from cv2 import ADAPTIVE_THRESH_MEAN_C
import numpy as np
src = cv2.imread('/Users/wangcc/Desktop/opencv/contours.png')
gray=cv2.cvtColor(src,cv2.COLOR_BGR2GRAY) #转变成单通道
binary = cv2.adaptiveThreshold(gray,255,ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,7,0) #自适应阀值
contours,hierarchy = cv2.findContours(binary,cv2.RETR_LIST,cv2.CHAIN_APPROX_SIMPLE) #查找轮廓 获得轮廓点
cv2.drawContours(src,contours,-1,(0,0,255),-1) #绘制轮廓 src在三通道中才能显示彩色
#轮廓的周长和面积
area0 = cv2.contourArea(contours[0])
area1 = cv2.contourArea(contours[1])
length0 = cv2.arcLength(contours[0],True)
length1 = cv2.arcLength(contours[1],True)
print("area0=%d,area1=%d"%(area0,area1)) #输出面积
print("length0=%d,length1 = %d"%(length0,length1))#输出周长
cv2.imshow('binary',binary)
cv2.imshow('src',src)
cv2.imshow('gray',gray)
waitKey(0)多边形逼近与凸包:
多边形逼近可减少存储的数据量。凸包只描述轮廓
多边形API:approxPolyDP(curve,epsilon,clsed)
曲线轮廓,精度,是否闭合
凸包: API:convexHull(points,clockwise)
轮廓,顺时针true,逆时针false
代码:
import cv2
from cv2 import THRESH_BINARY
from cv2 import RETR_EXTERNAL
from cv2 import CHAIN_APPROX_SIMPLE
from cv2 import approxPolyDP
from cv2 import ADAPTIVE_THRESH_GAUSSIAN_C
import numpy as np
def drawShape(src,points):
i = 0
while i < len(points):
if (i==len(points)-1):
x,y = points[i][0]
x1,y1 = points[0][0]
cv2.line(src,(x,y),(x1,y1),(0,0,255),1)
else:
x,y = points[i][0]
x1,y1 = points[i+1][0]
cv2.line(src,(x,y),(x1,y1),(0,0,255),1)
i = i+1
#灰度化 二值化
img = cv2.imread('/Users/wangcc/Desktop/opencv/contours.png')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret,binary = cv2.threshold(gray,150,255,cv2.THRESH_BINARY)
#查找轮廓
contours,hierarchy = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
#绘制轮廓
# cv2.drawContours(img,contours,-1,(0,0,255),1)
#查找图形轮廓上的点
e = 1 #值越小精度越好
approx = cv2.approxPolyDP(contours[0],e,True)
#画图函数
drawShape(img,approx)
#凸包
hull = cv2.convexHull(contours[1])
drawShape(img,hull)
cv2.imshow('gray',gray)
cv2.imshow('img',img)
cv2.waitKey(0)
外接矩形:
最小外接矩形:API:minAreaRect(points) pomints轮廓
返回值:RotatedRect 包含x,y 起始点,width,height 宽和高 angle 角度
最大外接矩形:API:boundingRect(array) array:轮廓
返回值Rect 包含x,y 起始点,width,height 宽和高
代码:
#最小外接矩形
r = minAreaRect(contours[1])
box = cv2.boxPoints(r) #拿到数据的起始点和宽高
box = np.int0(box) #强制转换整数型
cv2.drawContours(img,[box],0,(0,255,0),2)
#最大外接矩形
x,y,w,h = cv2.boundingRect(contours[1])
cv2.rectangle (img,(x,y),(x+w,y+h),(255,0,0),1)车辆统计项目
窗口的展示
图像/视频的加载
基本图形的绘制
车辆识别:(基本图像运算与处理,形态学,轮廓查找)
1:加载视频 2:通过形态学识别车辆 3:对车辆进行统计 4:显示车辆统计信息
import cv2
from cv2 import ADAPTIVE_THRESH_GAUSSIAN_C
from cv2 import ADAPTIVE_THRESH_MEAN_C
from cv2 import BackgroundSubtractor
from cv2 import dilate
import numpy as np
#创建显示窗口
cv2.namedWindow('video',cv2.WINDOW_NORMAL)
cv2.resizeWindow('video',640,480)
#导入视频文件/获取摄像头视频帧
cap = cv2.VideoCapture('/Users/wangcc/Desktop/opencv/IMG_6577.MOV')
min_w = 100
min_h = 100
#检测线的高度
line_high = 900
#存放车辆的数组
cars = []
#线的偏移量
offset = 6
carno = 0
def center(x,y,w,h):
x1 = int(w/2)
y1 = int(h/2)
cx = x + x1
cy = y + y1
return cx, cy
bgsubmog = cv2.createBackgroundSubtractorMOG2()
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3)) #获得卷积核
while True:
ret, frame = cap.read()
if (ret == True):
# 灰度化
cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
# #二值化
# blur = cv2.adaptiveThreshold(gray,255,ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,7,0)
#去噪(高斯) 去噪以后比二值化更清楚了
blur = cv2.GaussianBlur(frame,(3,3),5)
#去背影
mask = bgsubmog.apply(blur)
#腐蚀
erode = cv2.erode(mask,kernel)
#膨胀
dilate = cv2.dilate(erode,kernel,iterations=3)
#闭操作
# opening= cv2.morphologyEx(dilate,cv2.MORPH_OPEN,kernel,1)
close = cv2.morphologyEx(dilate, cv2.MORPH_CLOSE,kernel)
close = cv2.morphologyEx(close, cv2.MORPH_CLOSE,kernel)
cnts, h = cv2.findContours(close,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
#检测线
cv2.line(frame,(750,line_high),(1600,line_high),(0,255,0),6)
for(i,c) in enumerate(cnts):
(x,y,w,h)= cv2.boundingRect(c)
#限制宽高 过滤掉干扰框
isValid = (w >= min_w)and (h >= min_h)
if(not isValid):
continue
#统计有效的车辆
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,0,255),6)
cpoint = center(x,y,w,h)
cars.append(cpoint)
for (x,y) in cars:
#画一条线 有范围 从数组中减去
if ((y > line_high - offset) and (y < line_high + offset)):
carno +=1
cars.remove((x,y))
print(carno)
cv2.putText(frame,"cars count:"+str(carno),(700,60),cv2.FONT_HERSHEY_COMPLEX,2,(0,255,0),2)
# cv2.imshow('video',blur)
cv2.imshow('video1',frame)
cv2.imshow('video2',close)
cv2.imshow('video3',mask)
# cv2.imshow('video2',opening)
key = cv2.waitKey(1)
if(key == 27): #27是esc退出键
break
cap.release()
cv2.destoryAllWindows()

Harris角点检测API:
cornerHarris(img,dst,blovkSize,ksize,k)
dst,输出结果
blockSize:检测窗口大小 ksize:Sobel卷积核 k:权重系数,经验值 一般0.02-0.04之间
Shi-Tomasi角点检测:
对Harris角点检测的改进
API:goodFraturesToTrack(img,maxCorners,...)
maxCorners:角点的最大数,值为0表示无限制
qualityLevel:小于1的正数,一般在0.01-0.1之间
minDistance:角之间最小欧式距离,忽略小于此距离的点
mask:感兴趣的区域
blockSize:检测窗口
useHarrisDetector:是否使用Harris算法
k:默认是0.04
SIFT(Scale-Invariant Feature Transform)
Harris 角点具有旋转不变的特性 经过缩放后,原来的角点有可能就不是角点了
使用步骤:
1:创建SIFT对象
2:进行检测,kp=sift.detect(img,...)获得关键点
3:绘制关键点,drawKeypoints(gray,kp, img)
SIFT计算描述子:
关键点:位置,大小和方向
关键点描述子:记录了关键点周围对其有贡献的像素点的一组向量值,其不受仿射变换,光照变换的影响。
kp,des = sift.compute(img,kp) 其作用是进行特征匹配
kp,des = sift.detectAndCompute(img,....) mask:指明对img中哪个区域进行计算
SURF(Speeded-Up Robust Feature)特征检测
SIFT的缺点:速度慢,因此使用SURF速度加快
1:创建对象surf = cv2.xfeatures2d.SURF_creature()
2:kp,des = surf.detectAndCompute(img,mask)
ORB(oriented FAST and Rotated BRIEF):
ORB的优势可以做到实时检测 但准确率不如前者 适用于大批量图片检测
ORB= oriented FAST (可以做特征点的实时检测)+ Rotated BRIEF(是对已检测到的特征点进行描述,加快了特征描述建立的速度 极大降低了匹配的时间)
使用步骤:
1:创建对象:orb = cv2.ORB_create()
2: kp,des= orb.detectAndCompute(img,mask)
暴力特征匹配:BF(Brute-Force)
原理:使用第一组中的每个特征的描述子 与第二组中的所有特征描述子进行匹配
计算他们之间的差距,然后将最接近一个匹配返回