【目标检测】目标检测遇上知识图谱:Object detection meets knowledge graphs论文解读与复现
前言
常规的目标检测往往是根据图像的特征来捕捉出目标信息,那么是否有办法加入一些先验信息来提升目标检测的精准度?
一种可行的思路是在目标检测的输出加入目标之间的关联信息,从而对目标进行干涉。
2017年8月,新加波管理大学的Yuan Fang等人发表了一篇文章《Object Detection Meets Knowledge Graphs》,就按照这个思路做了一些工作。
论文地址:https://www.ijcai.org/proceedings/2017/0230.pdf
文章写得非常通俗易懂,因此本文进行思路解读和代码复现。
工作架构
这篇文章作者提出的是一个通用的知识引入架构,因此对于任何目标检测模型都可以适用。
知识引入的流程图如下图所示:

原论文作者采用的是Faster R-CNN算法进行检测,正常检测输出结果会是一个P矩阵(即图中的Existing model output),这里的列表示总共的目标数,行表示类别。
图中的这个矩阵意义是:第一个检测目标属于类别1的置信度为0.6,属于类别2的置信度为0.4;第二个检测目标属于类别1的置信度为0.2,属于类别2的置信度为0.8;
在这个输出结果基础上,从先验知识(Knowledge)中提取出类别之间的语义一致性(semantic consistency),从而对输出结果进行干涉,得到最终的输出结果(Knowledge-aware output)。
语义一致性提取
那么这套架构的关键就是如何提取语义一致性,这一点作者给出了两种思路。
思路一:基于频率的知识(Frequency-based knowledge)
基于频率应该是最容易想到的知识关联方式,比如两个目标同时出现的频率高(比如键盘和鼠标经常一起出现),那么检测出其中一个目标时,自然可以考虑增加另一个目标的置信度。
因此,作者提出了一个对阵矩阵S,作为目标类别之间的语义一致性矩阵,计算公式如下:

- n(l,l’):类别l和类别l‘一起出现的次数
- n(l):类别l出现的次数
- n(l’):类别l’出现的次数
- N:所有类别出现的总次数
思路二:基于知识图谱的知识(Graph-based knowledge)
思路一的方式比较直观,不过存在的缺陷是无法表征两个没有同时出现过的类别之间的关系。比如,车和游艇没有在一个场景中同时出现,但不能“粗暴”的认为这两者毫无关联吧,肯定需要一个微弱的权值来表示两者之间的关系。
因此,作者想到了用知识图谱的方式来提取语义一致性。
首先,通过对一些公开的大型知识图谱进行过滤,提取出需要检测的类别信息和关系。
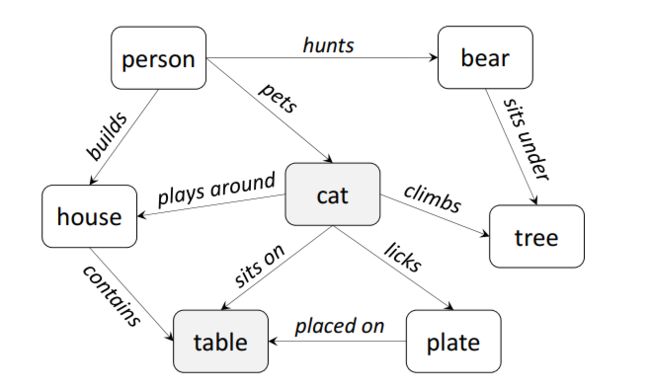
之后,通过重启随机游走算法(random walk with restart)来得到该关系图的收敛状态。重启随机游走算法是经典的随机游走算法的一个变种,相当于在随机游走算法的基础上,添加了一个重启概率,触发重启后会回到原点。

收敛之后,会得到一个R矩阵,这个矩阵表征了当算子处于某个状态类别时,向另一状态类别转移的概率。由于语义一致性矩阵是对称矩阵,因此作者采用了一个状态相乘再开方的操作。

干涉检测输出
有了语义一致性矩阵S之后,就可以对输出结果进行干涉。论文中,对于如何进行干涉并没有说明。
通过后面阅读源码可知,干涉的思路主要是选取某目标类别最邻近的5个类别,然后对其一致性矩阵数值求和得到关联性特征向量。再将该向量和原始检测结果进行加权相加。
核心代码:
num = torch.sum(torch.mm(S_highest, torch.transpose(p_hat_temp[box_nearest[b]], 0, 1)), 1)
denom = torch.sum(S_highest, dim=1) * bk
p_hat[b] = (1 - epsilon) * torch.squeeze(torch.div(num, denom)) + epsilon * p
这里的epsilon代表权重,复现时取0.75,表示75%保留原始结果,25%进行知识干涉。
后面一部分就是损失函数以及网络更新部分了。
下面是损失函数的计算公式,相当于将知识嵌入的结果纳入到网络的更新之中。

实验结果
作者在Coco和VOC数据集上进行了实验,下表是coco的实验结果:

- FRCNN:原始检测网络输出结果
- KF-500:通过思路一来获得一致性矩阵,选择500张训练集图片
- KF-All:通过思路一来获得一致性矩阵,选择所有训练集图片
- KG-CNet:通过思路二来获得一致性矩阵
从表中数据可知,该思路的改进对检测输出的mAP并没有起到提升作用,不过有效提升了召回率。相当于降低了网络的误检率。
结果可视化
最后是结果的可视化,作者选取了一幅图来演示:左图是直接检测结果,右图是添加知识图谱之后的检测结果。
紫框表示模型的检测输出,红框表示实际的标签。

由图可知,原始的FRCNN没有检测出键盘(keyboard),添加知识图谱后,通过鼠标、笔记本等目标的关联信息,成功将键盘检测出来。
实验复现
原论文发布时间较早,使用Caffe框架进行实验,目前已无法找到。
后面有人使用Pytorch对其进行复现。
代码地址:https://github.com/tue-mps/rescience-ijcai2017-230
复现结论
复现作者提到:
对于所描述的任何一种方法,作者的主张都无法得到证实。结果要么显示以 mAP 降低为代价的召回率增加,要么显示 mAP 保持不变,召回率没有改善。三种不同的骨干模型在重新优化后表现出相似的行为,结论是知识感知的重新优化对目标检测算法没有好处。
不清楚是否是超参数的影响,总之论文的效果无法实现。
代码运行
该代码写得比较清晰,并且作者提供了处理好的数据集和语义一致性矩阵。
下载好之后,放置路径如下即可:
之后修改Utils/testing.py里面这三行内容,我测试的时候遇到的小bug:
# 原始
# boxes_temp = prediction[1][0]['boxes']
# labels_temp = prediction[1][0]['labels']
# scores_temp = prediction[1][0]['scores']
# 修改为
boxes_temp = prediction[0]['boxes']
labels_temp = prediction[0]['labels']
scores_temp = prediction[0]['scores']
最后运行Results/results_coco.py即可进行单轮测试。
实验结果
由于原论文作者使用的是VGG16作为backbone,因此这里model_type我设置为coco-FRCNN-vgg16,下面是在我RTX2060下用Coco数据集的实验结果:
| 模型 | mAP @ 100 | Recall @ 100 all classes |
|---|---|---|
| FRCNN | 0.247 | 0.477 |
| KF-All-COCO | 0.245 | 0.432 |
| KG-CNet-55-COCO | 0.243 | 0.436 |
| KG-CNet-57-COCO | 0.243 | 0.437 |
- FRCNN:Fast-RCNN直接检测
- KF-ALL-COCO:思路一获取语义一致性矩阵
- KG-CNet-55-COCO:思路二通过大型常识知识库
ConceptNet-assertions55提取一致性矩阵 - KG-CNet-57-COCO:思路二通过大型常识知识库
ConceptNet-assertions57提取一致性矩阵
从结果来看,的确没什么卵用,mAP和Recall均下降了。。
