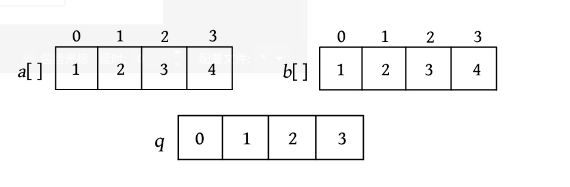
算法训练营学习笔记1
算法训练营学习笔记
贪心算法
心算法总是做出当前最好的选择,期望通过局部最优选择得到全局最优的解决方案。从问题的初始解开始,一步歩地做出当前最好的选择,逐步逼近问题的目标,尽可能得到最优解;
贪心本质
我们在遇到具体问题时,往往分不清对哪些问题可以用贪心算法,对哪些问题不可以用贪心算法。实际上,如果问题具有两个特性:贪心选择性质和最优子结构性质,则可以用贪心算法。
(1)贪心选择性质。贪心选择性质指原问题的整体最优解可以通过一系列局部最优的选择得到。应用同一规则,将原问题变为一个相似的、但规模更小的子问题,而后的每一步都是当前最优的选择。这种选择依赖于已做出的选择,但不依赖于未做出的选择。运用贪心算法解决的问题在程序的运行过程中无回溯过程。关于贪心选择性质,读者可在后面贪心算法图解中得到深刻的体会。
(2)最优子结构性质。当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。问题的最优子结构性质是该问题是否可以用贪心算法求解的关键。例如原问题S= {a 1 ,a 2 ,…,ai ,…,a n },通过贪心选择选出一个当前最优解{a i }之后,转化为求解子问题S -{ai },如果原问题的最优解包含子问题的最优解,则说明该问题满足最优子结构性质。
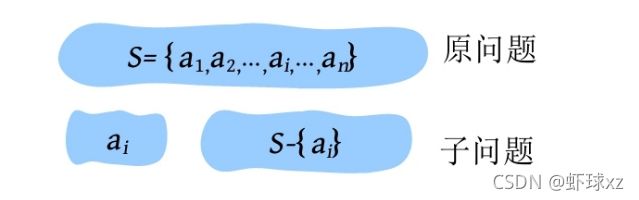
贪心算法的求解步骤如下
(1)贪心策略。指确定贪心策略,选择当前看上去最好的一个。比如挑选苹果,如果你认为个头大的是最好的,那么每次都从苹果堆中拿一个最大的作为局部最优解,贪心策略就是选择当前最大的苹果。如果你认为最红的苹果是最好的,那么每次都从苹果堆中拿一个最红的,贪心策略就是选择当前最红的苹果。因此根据求解目标的不同,贪心策略也会不同。
(2)局部最优解。指根据贪心策略,一步步地得到局部最优解。比如第1次选一个最大的苹果放起来,记为a 1 ;第2次再从剩下的苹果中选择一个最大的苹果放起来,记为a 2 ,以此类推。
(3)全局最优解。指把所有的局部最优解都合成原问题的一个最优解{a 1 ,a 2 ……}。
最优装载问题
有一天,海盗们截获了一艘装满各种各样古董的货船,每件古董都价值连城,一旦打碎就失去了价值。虽然海盗船足够大,但载重为c ,每件古董的重量为wi ,海盗们绞尽脑汁要把尽可能多的宝贝装上海盗船,该怎么办呢?
问题分析
根据问题描述可知,这是一个可以用贪心算法求解的最优装载问题,要求装载的物品尽可能多,而船的容量是固定的,那么优先把重量小的物品放进去,在容量固定的情况下,装的物品最多。可以采用重量最轻者先装的贪心选择策略,从局部最优达到全局最优,从而得到最优装载问题的最优解。
算法设计
(1)当载重为定值c 时,wi 越小,可装载的古董数量n 越大。依次选择最小重量的古董,直到不能装入为止。
(2)把n 个古董的重量从小到大(非递减)排序,然后根据贪心策略尽可能多地选出前i 个古董,直到不能继续装入为止。此时装入的古董数量就达到全局最优解。
- 完美图解
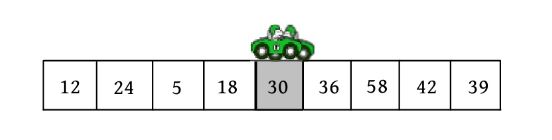
每个古董的重量都如下表所示,海盗船的载重c 为30,那么在不打碎古董又不超过载重的情况下,怎样装入最多的古董?

因为贪心策略是每次都选择重量最小的古董装入海盗船,因此可以按照古董的重量非递减排序,排序后如下表所示。

照贪心策略,每次都选择重量最小的古董装入
i =0:选择排序后的第1个古董装入,装入重量tmp=2,不超过载重30,ans=1。
i =1:选择排序后的第2个古董装入,装入重量tmp=2+3=5,不超过载重30,ans=2。
i =2:选择排序后的第3个古董装入,装入重量tmp=5+4=9,不超过载重30,ans=3。
i =3:选择排序后的第4个古董装入,装入重量tmp=9+5=14,不超过载重30,ans=4。
i =4:选择排序后的第5个古董装入,装入重量tmp=14+7=21,不超过载重30,ans=5。
i =5:选择排序后的第6个古董装入,装入重量tmp=21+10=31,超过载重30,算法结束。
即装入古董的个数为5(ans=5)个。
- 算法实现
根据算法设计描述,可以用一维数组w存储古董的重量
(1)按重量排序。可以利用C++中的排序函数sort,对古董的重量从小到大(非递减)排序。要使用此函数,只需引入头文件:#include 。排序函数如下:
sort(begin,end)
在本例中,只需要调用sort函数对古董的重量从小到大排序即可:sort(w ,w +n )。
(2)按照贪心策略找最优解。首先用变量ans记录已经装载的古董个数,tmp代表装载到船上的古董的重量,将两个变量都初始化为0;然后在按照重量从小到大排序的基础上,依次检查上的古董的重量,将两个变量都初始化为0;然后在按照重量从小到大排序的基础上,依次检查
#include \5. 算法分析
时间复杂度 :按古董重量排序并调用sort函数,其平均时间复杂度为O (n logn ),输入和贪心策略求解的两个for语句的时间复杂度均为O (n ),因此总时间复杂度为O (n logn )。
空间复杂度 :在程序中使用了tmp、ans等辅助变量,空间复杂度为O (1)
分治算法
《孙子兵法》中有句名言“凡治众如治寡,分数是也”,意思是把部队分为各级组织,将帅只需通过管理少数几个人就可以统领全军。管理和指挥人数众多的大军,如同管理和指挥人数少的部队一样容易。在算法设计中,常常引入分而治之的策略,称之为分治算法,其本质就是将一个大规模的问题分解为若干规模较小的相同子问题,分而治之。
分治算法秘籍
在现实生活中,对什么样的问题才能使用分治算法解决呢?想要使用分治算法,需要满足以下三个条件:
(1)原问题可被分解为若干规模较小的相同子问题;
(2)子问题相互独立;
(3)子问题的解可以合并为原问题的解。
分治算法求解秘籍如下。
(1)分解:将原问题分解为若干规模较小、相互独立且与原问题形式相同的子问题。
(2)治理:求解各个子问题。由于各个子问题与原问题形式相同,只是规模较小,所以当子问题划分得足够小时,就可以用较简单的方法解决。
(3)合并:按原问题的要求,将子问题的解逐层合并成原问题的解。
一言以蔽之,分治算法是将一个难以直接解决的大问题分割成一些规模较小的相同问题,以便各个击破、分而治之。在分治算法中,各个子问题形式相同,解决方法也一样,因此可以使用递归算法快速解决。所以,递归是彰显分治算法优势的利器。
合并排序
在数列排序中,如果只有一个数,那么它本身就是有序的;如果只有两个数,那么进行一次比较就可以完成排序。也就是说,数越少,排序越容易。那么,对于一个由大量数据组成的数列,我们很难一次完成排序,这时可将其分解为小的数列,一直分解到只剩一个数时,本身已有序,再把这些有序的数列合并在一起,执行一个和分解相反的过程,从而完成对整个序列的排序。
合并排序就是采用分治策略,将一个大问题分成很多个小问题,先解决小问题,再通过小问题解决大问题。由于排序问题给定的是一个无序序列,所以可以把待排序元素分解成两个规模大致相等的子序列,如果不易解决,则再将得到的子序列继续分解,直到在子序列中包含的元素个数为1。因为单个元素的序列本身是有序的,此时便可以进行合并,从而得到一个完整的有序序列。
- 算法设计
合并排序是采用分治策略进行排序的算法,是分治算法的一个典型应用和完美体现。它是一种平衡、简单的二分分治策略。
算法步骤如下。
(1)分解:将待排序元素分成大小大致相同的两个子序列
(2)治理:对两个子序列进行合并排序。
(3)合并:将排好序的有序子序列进行合并,得到最终的有序序列
完美图解
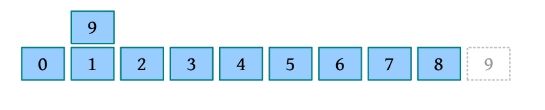
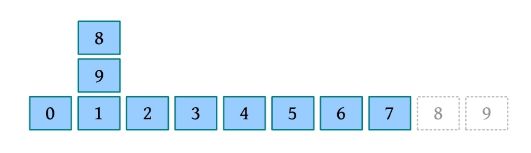
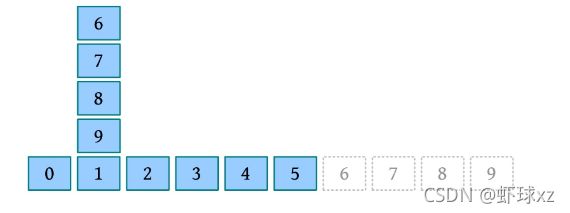
给定一个数列(42,15,20,6,8,38,50,12),执行合并排序的过程如下图所示。
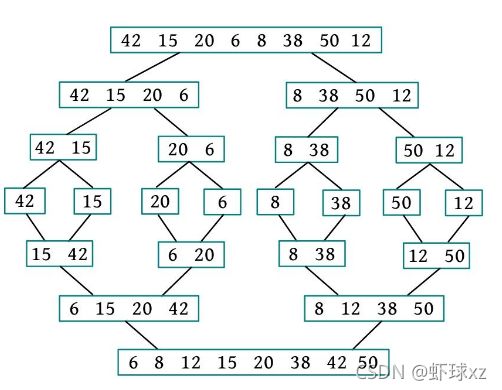
从上图可以看出,首先将待排序元素分成大小大致相同的两个子序列,然后把子序列分成大小大致相同的两个子序列,如此下去,直到分解成一个元素时为止,这时含有一个元素的子序列就是有序的;然后执行合并操作,将两个有序的子序列合并为一个有序序列,如此下去,直到所有的元素都合并为一个有序序列时为止。
3. 算法设计
1)合并操作
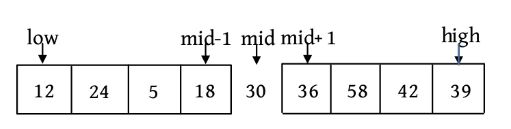
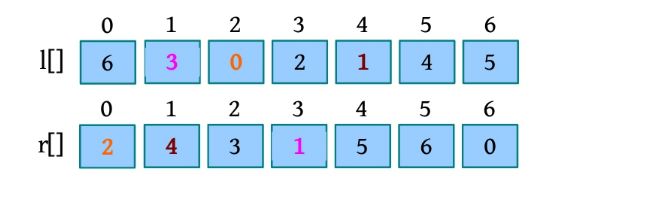
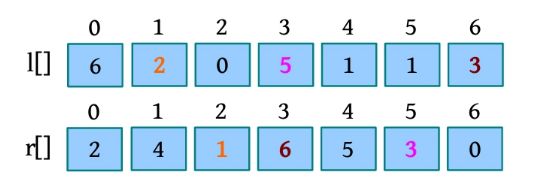
为了进行合并,这里引入一个辅助合并函数Merge(A,low,mid,high),该函数将排好序的两个子序列A[low:mid]和A[mid+1:high]进行合并。其中,low、high代表待合并的两个子序列在数组中的下界和上界,mid代表下界和上界的中间位置,如下图所示
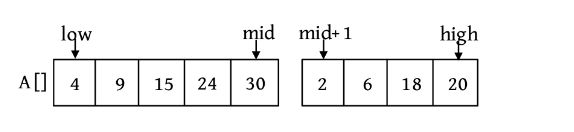
这里还设置3个工作指针i 、j 、k (整型下标)和一个辅助数组B。其中,i 和j 分别指向两个。待排序子序列中当前待比较的元素,k 指向辅助数组B中待放置元素的位置。比较A[i ]和A[j ],将较小的赋值给B[k ],相应的指针同时向后移动。如此反复,直到所有元素都处理完毕。最后把辅助数组B中排好序的元素复制到数组A中,如下图所示。
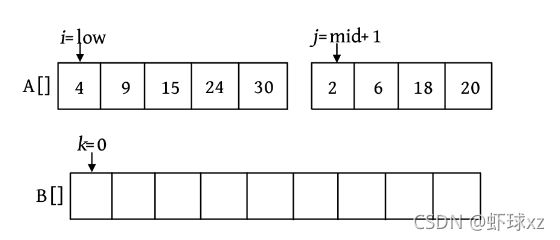
第1次比较时,A[i ]=4,A[j ]=2,将较小的元素2放入数组B中,j ++,k ++
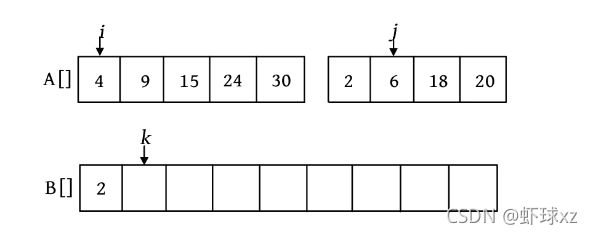
第2次比较时,A[i ]=4,A[j ]=6,将较小的元素4放入数组B中,i ++,k ++。
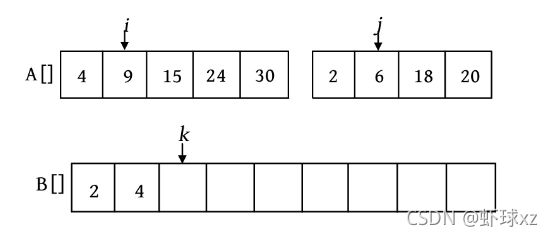
第3次比较时,A[i ]=9,A[j ]=6,将较小的元素6放入数组B中,j ++,k ++
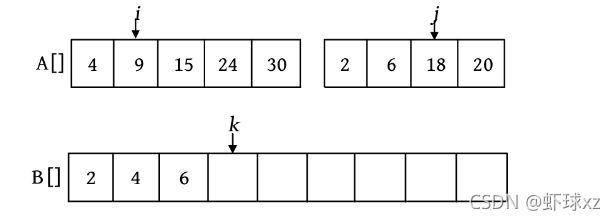
第4次比较时,A[i ]=9,A[j ]=18,将较小的元素9放入数组B中,i ++,k ++。
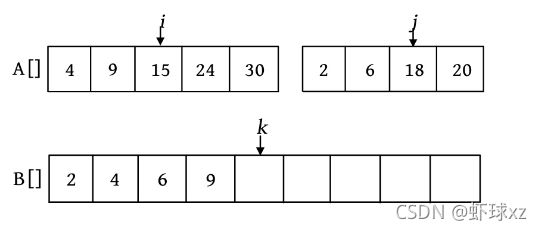
第5次比较时,A[i ]=15,A[j ]=18,将较小的元素15放入数组B中,i ++,k ++。
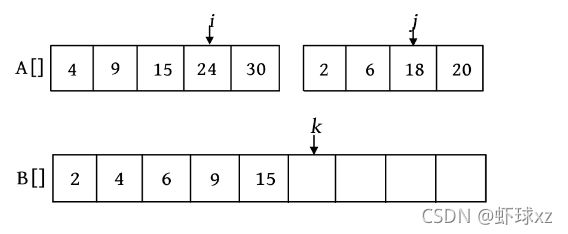
第6次比较时,A[i ]=24,A[j ]=18,将较小的元素18放入数组B中,j ++,k ++。
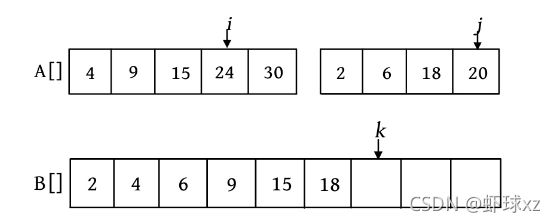
第7次比较时,A[i ]=24,A[j ]=20,将较小的元素20放入数组B中,j ++,k ++。
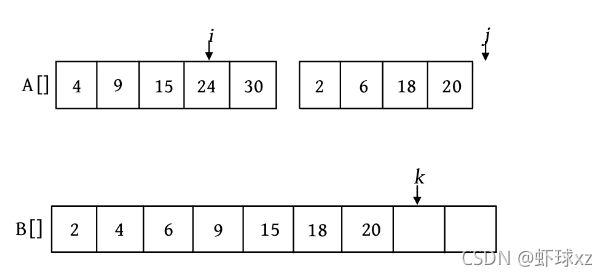
此时,j >high的后半部分已处理完毕,但前半部分还剩余元素,该怎么办?将剩余元素照搬到数组B就可以了。
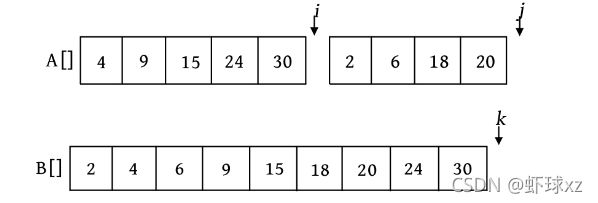
完成合并后,需要把辅助数组B中的元素复制到原来的数组A中。
void Merge(int A[],int low,int mid,int high)
{
int *B = new int[high-low+1];
int i=low,j=mid+1,k=0;
while(i<=mid && j<=high)
{
if(A[i]<=A[j])
B[k++]=A[i++];
else
B[k++]=A[j++];
}
while(i<=mid) B[k++]=A[i++];
while(j<=high) B[k++]=A[j++];
for(i=low,k=0;i<=high;i++)
A[i]=B[k++];
delete[] B;
}
合并排序
将序列分为两个子序列,然后对子序列进行递归排序,再把两个已排好序的子序列合并成一个有序的序列。
void MergeSort(int A[],int low,int high)
{
if(low<high)
{
int mid = (low+high)/2;
MergeSort(A,low,mid);
MergeSort(A,mid+1,high);
Merge(A,low,mid,high);
}
}
算法分析
时间复杂度:分解仅仅是计算出子序列的中间位置,需要常数时间O (1)。递归求解两个规模为n /2的子问题,所需时间为2T (n /2)。合并算法可以在O (n )时间内完成。所以总运行时间如下:
Cannot read property 'type' of undefined
当n >1时,递推求解:
合并排序算法的时间复杂度为O (n logn )
快速排序
我们在生活中到处都会用到排序,例如比赛、奖学金评选、推荐系统等。排序算法有很多种,能不能找到更快速、高效的排序算法呢?
有人曾通过实验,对各种排序算法效率做了对比(单位:毫秒),对比结果如下表所示
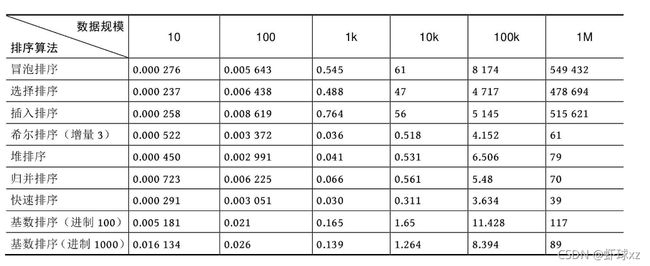
从上表可以看出,如果对10万个数据进行排序,则冒泡排序需要8174毫秒,快速排序只需3.634毫秒!
快速排序是比较快速的排序方法,由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据小,然后按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
合并排序每次都从中间位置把问题一分为二,一直分解到不能再分时再执行合并操作。合并排序的划分很简单,但合并操作需要在辅助数组中完成,是一种异地排序的方法。合并排序分解容易、合并难,属于“先易后难”。而快速排序是原地排序,不需要辅助数组,但分解困难、合并容易,属于“先苦后甜”。
- 算法设计
快速排序是基于分治策略的,其算法思想如下
(1)分解:先从数列中取出一个元素作为基准元素。以基准元素为标准,将问题分解为两个子序列,使小于或等于基准元素的子序列在左侧,使大于基准元素的子序列在右侧。
(2)治理:对两个子序列进行快速排序。
(3)合并:将排好序的两个子序列合并在一起,得到原问题的解。
如何分解是一个难题,因为如果基准元素选取不当,就有可能分解成规模为0和n -1的两个子序列,这样快速排序就退化为冒泡排序了
例如对于序列(30,24,5,58,18,36,12,42,39),第1次选取5作为基准元素,分解后如下图所示。
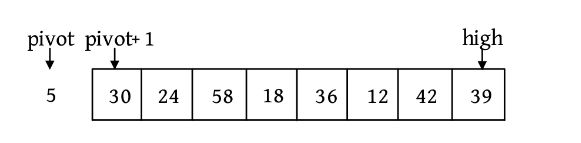
第2次选取12作为基准元素,分解后如下图所示。
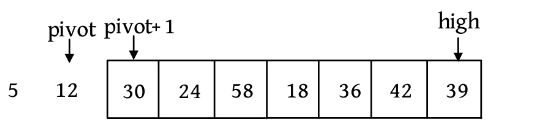
这样做的效率是最低的,最理想的状态是把序列分解为两个规模相当的子序列,那么怎样选取基准元素呢?一般来说,对基准元素的选取有以下几种方法:
取第一个元素;
取最后一个元素;
取中间位置的元素;
取第一个元素、最后一个元素、中间位置的元素三者的中位数;
取第一个元素和最后一个元素之间位置的随机数k (low≤k ≤high),选R[k ]作为基准元素。
完美图解
因为并没有明确说明哪一种基准元素选取方案最好,所以在此选取第一个元素作为基准,以说明快速排序的执行过程。
假设当前待排序的序列为r[low: high],其中low≤high。
(1)取数组的第一个元素作为基准元素pivot=r[low],i =low,j =high。
(2)从右向左扫描,找小于或等于pivot的数,如果找到,则r[i ]和r[j ]交换,i ++。
(3)从左向右扫描,找大于pivot的数,如果找到,则r[i ]和r[j ]交换,j --。
(4)重复第2~3步,直到i 和j 重合,返回mid=i ,该位置的数正好是pivot元素。
至此完成一趟排序。此时以mid为界,将原数据分为两个子序列,左侧子序列都比pivot小,右侧子序列都比pivot大。然后分别对这两个子序列进行快速排序。
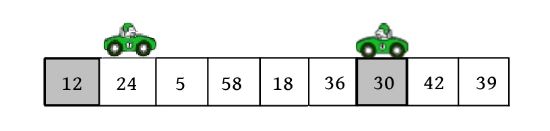
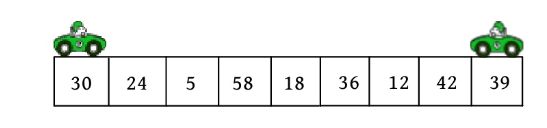
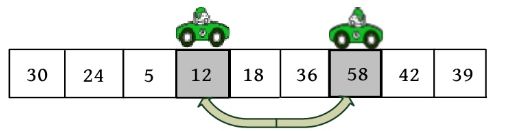
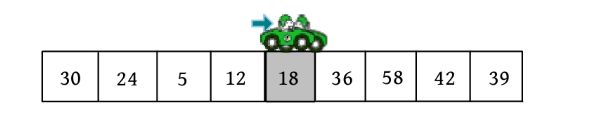
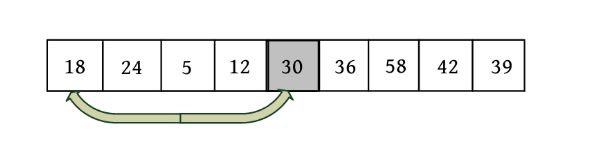
这里以序列(30,24,5,58,18,36,12,42,39)为例,演示快速排序过程
(1)初始化。i =low,j =high,pivot=r[low]=30。
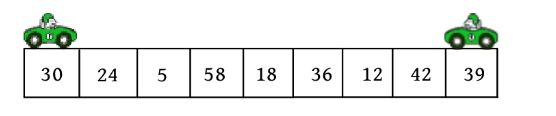
(2)向左走。从数组的右边位置向左找,一直找小于或等于pivot的数,找到r[j ]=12。
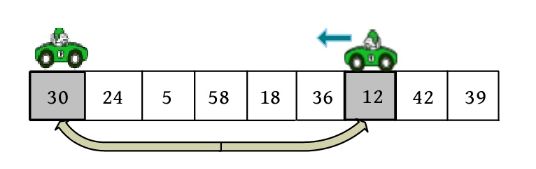
r[i ]和r[j ]交换,i ++,如下图所示。
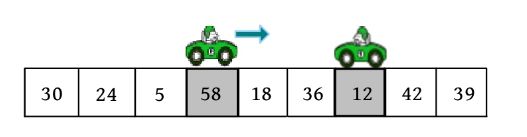
3)向右走。从数组的左边位置向右找,一直找比pivot大的数,找到r[i ]=58。
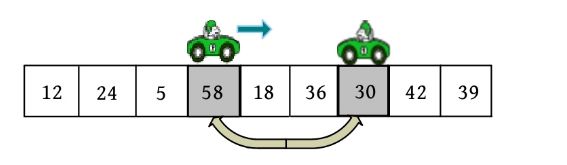
r[i ]和r[j ]交换,j --,如下图所示。
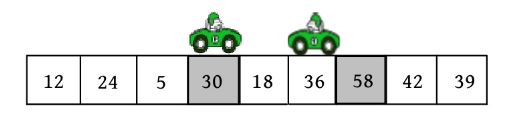
4)向左走。从数组的右边位置向左找,一直找小于或等于pivot的数,找到r[j ]=18。
r[i ]和r[j ]交换,i ++,如下图所示。
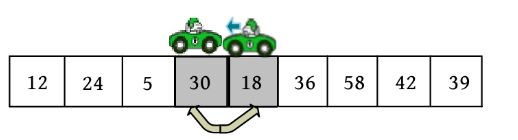
(5)向右走。从数组的左边位置向右找,一直找比pivot大的数,此时i =j ,第一趟排序结束,返回i 的位置,mid=i ,如下图所示。
此时以mid为界,将原序列分为两个子序列,左侧子序列都比pivot小,右侧子序列都比pivot大。然后分别对两个子序列(12,24,5,18)、(36,58,42,39)进行快速排序。
\3. 算法实现
1)划分函数。划分函数对原序列进行分解,将其分解为两个子序列,以基准元素pivot为界,左侧子序列都比pivot小,右侧子序列都比pivot大。先从右向左扫描,找小于或等于pivot的数,找到后两者交换(在r[i ]和r[j ]交换后,i ++);再从左向右扫描,找比基准元素大的数,找到后两者交换(在r[i ]和r[j ]交换后,j --)。扫描交替进行,直到i =j 时停止,返回划分的中间位置i 。
int Partition(int r[], int low, int high) //划分函数
{
int i = low, j = high, pivot = r[low]; //基准元素
while (i < j)
{
while (i < j && r[j] > pivot) j--; //向左扫描
if (i < j)
swap(r[i++], r[j]); //r[i]和r[j]交换后i+1,右移1位
while (i < j && r[i] <= pivot) i++; //向右扫描
if (i < j)
swap(r[i], r[j--]); //r[i]和r[j]交换 后j-1,左移1位
}
return i;//返回基准元素位置
}
(2)快速排序。首先对原序列划分,得到划分的中间位置mid;然后以中间位置为界,分别对左半部分(low,mid-1)执行快速排序,对右半部分(mid+1,high)执行快速排序。递归结束的条件是low≥high。
void QuickSort(int r[], int low, int high) //快速排序
{
if (low < high)
{
int mid = Partition(r, low, high); //划分
QuickSort(r, low, mid - 1); //左区间递归快排
QuickSort(r, mid + 1, high); //右区间递归快排
}
}
算法分析
快速排序算法在最好情况下的时间复杂度为O (n logn )。
空间复杂度:程序中的变量的辅助空间是常数阶的,递归调用所使用的栈空间为递归树的高度O (logn ),快速排序算法在最好情况下的空间复杂度为O (logn )。
2)最坏情况
快速排序算法在最坏情况下的时间复杂度为O (n 2 )。
空间复杂度:程序中的变量的辅助空间是常数阶的,递归调用所使用的栈空间为递归树的高度O (n ),快速排序算法在最坏情况下的空间复杂度为O (n )。
3)平均情况
由归纳法可以得出,T (n )的数量级也为O (n logn )。快速排序算法在平均情况下的时间复杂度为O (n logn )。递归调用所使用的栈空间为O (logn ),快速排序算法在平均情况下的空间复杂度为O (logn )。
\5. 优化拓展
从上述算法可以看出,每次交换都是和基准元素进行交换,实际上没必要这样做。我们的目的是把原序列分成以基准元素为界的两个子序列,左侧子序列小于或等于基准元素,右侧子序列大于基准元素。那么有很多方法可以实现:可以从右向左扫描,找小于或等于pivot的数r[j ],然后从左向右扫描,找大于pivot的数r[i ],将r[i ]和r[j ]交换,一直交替进行,直到i 和j 相遇为止,这时将基准元素与r[i ]交换即可。这样就完成了一次划分过程,但交换元素的次数少了很多。
假设当前待排序的序列为r[low: high],其中low≤high。
(1)首先取数组的第一个元素作为基准元素,pivot=r[low],i =low,j =high。
(2)从右向左扫描,找小于或等于pivot的数r[i ]。
(3)从左向右扫描,找大于pivot的数r[j ]。
(4)r[i ]和r[j ]交换,i ++,j --。
(5)重复第2~4步,直到i 和j 相等。此时如果r[i ]大于pivot,则r[i -1]和基准元素r[low]交换,返回该位置,mid=i -1;否则r[i ]和r[low]交换,返回该位置,mid=i 。该位置的数正好是基准元素。
至此完成一趟排序。此时以mid为界,将原数据分为两个子序列,左侧子序列都比pivot小,右侧子序列都比pivot大。然后分别对这两个子序列进行快速排序。
这里以序列(30,24,5,58,18,36,12,42,39)为例,演示快速排序的优化过程。
(1)初始化。i =low,j =high,pivot=r[low]=30。
(2)向左走。从数组的右边位置向左找,一直找小于或等于pivot的数,找到r[j ]=12。

(3)向右走。从数组的左边位置向右找,一直找比pivot大的数,找到R[i ]=58。
r[i ]和r[j ]交换,i ++,j --。
4)向左走。从数组的右边位置向左找,一直找小于或等于pivot的数,找到r[j ]=18

(5)向右走。从数组的左边位置向右找,一直找比pivot大的数,这时i =j ,停止。
(6)r[i ]小于pivot,r[i ]和r[low]交换,返回i 的位置,mid=i ,第一趟排序结束。
此时以mid为界,将原数据分为两个子序列,左侧子序列都比pivot小,右侧子序列都比pivot大,如下图所示。然后分别对两个子序列(18,24,5,12)、(36,58,42,39)进行快速排序。

算法代码:
int Partition2(int r[], int low, int high) //划分函数优化
{
int i = low, j = high, pivot = r[low]; //基准元素
while (i < j)
{
while (i < j && r[j] > pivot) j--; //向左扫描
while (i < j && r[i] <= pivot) i++; //向右扫描
if (i < j)
swap(r[i++], r[j--]); //r[i]和r[j]交换
}
if (r[i] > pivot)
{
swap(r[i - 1], r[low]); //r[i-1]和r[low]交换
return i - 1; //返回基准元素位置
}
swap(r[i], r[low]); //r[i]和r[low]交换
return i;//返回基准元素位置
}
训练 间谍
题目描述(HDU3527): X国的情报委员收到一份可靠的信息,信息表明Y国将派间谍去窃取X国的机密文件。X国指挥官手中有两份名单列表,一份是Y国派往X国的间谍名单列表,另一份是X国以前派往Y国的间谍名单列表。这两份名单列表可能有些重叠。因为间谍可能同时扮演两个角色,称之为“双重间谍”。因此,Y国可以把双重间谍送回X国。很明显,这对X国是有利的,因为双重间谍可以把Y国的机密文件带回,而不必担心被Y国边境拘留。所以指挥官决定抓住由Y国派出的间谍,让普通人和双重间谍进入。那么你能确定指挥官需要抓捕的间谍名单吗?
输入: 有几个测试用例。每个测试用例都包含4部分。第1部分包含3个正整数A 、B 、C,A 是进入边境的人数,B 是Y国将派出的间谍人数,C 是X国以前派到Y国的间谍人数。第2部分包含A 个字符串,为进入边境的人员名单。第3部分包含B 个字符串,为由Y国派出的间谍名单。第4部分包含C 个字符串,即双重间谍的名单。每个测试用例后都有一个空白行。在一份名单列表中不会有任何名字重复,如果有重复的名字出现在两份名单列表中,则表示同一个人。
8 4 3
Zhao Qian Sun Li Zhou Wu Zheng Wang
Zhao Qian Sun Li
Zhao Zhou Zheng
2 2 2
Zhao Qian
Zhao Qian
Zhao Qian
输出: 输出指挥官抓捕的间谍名单(按列表B 的出现顺序)。如果不应捕获任何人,则输出“No enemy spy”。
\1. 算法设计
本题有3个名单,可以使用数组vector解决。
(1)定义4个vector,分别记录3行字符串和答案。
(2)判断第2行在第1行中出现但没在第3行中出现的字符串,将其添加到答案中。
(3)如果答案数组不空,则按顺序输出。
\2. 算法实现
#include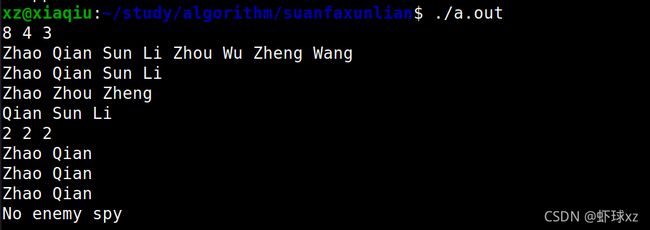
栈
栈(stack)只允许在栈顶操作,不允许在中间位置进行插入和删除操作,不支持数组表示法和随机访问。使用stack时需要引入头文件#include。栈的基本操作很简单,包括入栈、出栈、取栈顶、判断栈空、求栈大小。
stacks :创建一个空栈s ,数据类型为int。
push(x ):x 入栈。
pop():出栈。
top():取栈顶(未出栈)。
empty():判断栈是否为空,若为空则返回true。
size():求栈大小,返回栈中的元素个数。
训练 Web导航
题目描述(POJ1028): 标准的Web浏览器包含在最近访问过的页面中向后和向前移动的功能。实现这些特性的一种方法是使用两个栈来跟踪前后移动可以到达的页面。支持以下命令。
BACK:将当前页面推到前向栈的顶部。从后向栈的顶部弹出页面,使其成为新的当前页面。如果后向栈为空,则忽略该命令。
FORWARD:将当前页面推到后向栈的顶部。从前向栈顶部弹出页面,使其成为新的当前页面。如果前向栈为空,则忽略该命令。
VISIT:将当前页面推到后向栈的顶部,使URL成为新的当前页面。前向栈清空。
QUIT:退出浏览器。
假设浏览器的最初页面为URL ***###.acm.org/(对“http://”用“***”代替,对“www”用“###”代替)。
输入: 输入是一系列BACK、FORWARD、VISIT、QUIT命令。URL没有空白,最多有70个字符。任何时候,在每个栈中都不会超过100个元素。QUIT命令表示输入结束。
输出: 对于除QUIT外的每个命令,如果不忽略该命令,则在执行该命令后单行输出当前页的URL,否则输出“Ignored”。QUIT命令没有输出。
\1. 算法设计
本题模拟Web浏览器中的前进和后退两个操作,可以使用两个stack解决。backward表示后向栈;forward表示前向栈。
(1)初始时,当前页面cur为“***###.acm.org/”。
(2)BACK:如果后向栈为空,则忽略该命令;否则将当前页面放入前向栈,从后向栈的顶部弹出页面,使其成为新的当前页面。输出当前页面。
(3)FORWARD:如果前向栈为空,则忽略该命令;否则将当前页面放入后向栈,从前向栈的顶部弹出页面,使其成为新的当前页面。输出当前页面。
(4)VISIT:将当前页面放入后向栈的顶部,并使URL成为新的当前页面。前向栈清空。输出当前页面。
(5)QUIT:退出浏览器。
\2. 完美图解:
(1)初始时,cur为“***###.acm.org/”。
(2)VISIT ***acm.ashland.edu/,将当前页面放入后向栈的顶部,并使URL成为新的当前页面。前向栈清空。
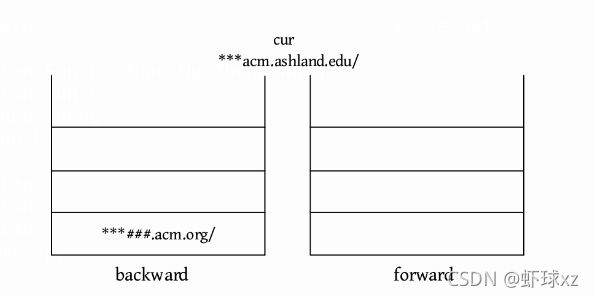
输出cur:***acm.ashland.edu/。
(3)VISIT ***acm.baylor.edu/acmicpc/,将当前页面放入后向栈的顶部,并使URL成为新的当前页面。前向栈清空。
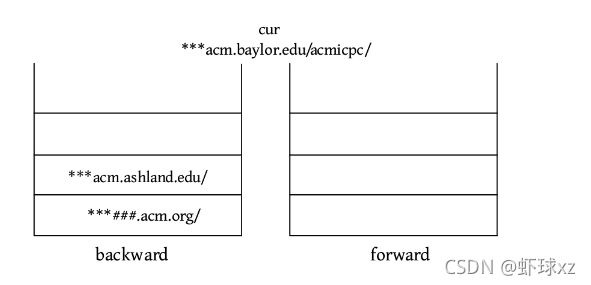
输出cur:***acm.baylor.edu/acmicpc/。
4)BACK:如果后向栈为空,则忽略该命令;否则将当前页面放入前向栈,从后向栈的顶部弹出页面,使其成为新的当前页面。输出当前页面。
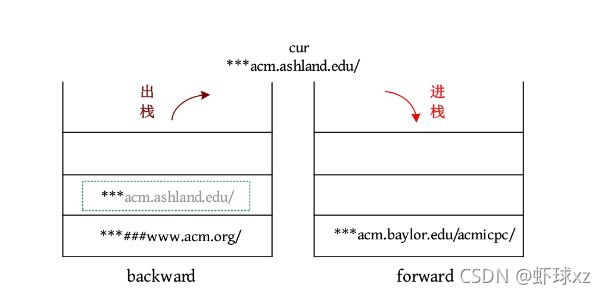
输出cur:***acm.ashland.edu/。
(5)BACK:如果后向栈为空,则忽略该命令;否则将当前页面放入前向栈,从后向栈的顶部弹出页面,使其成为新的当前页面。输出当前页面。
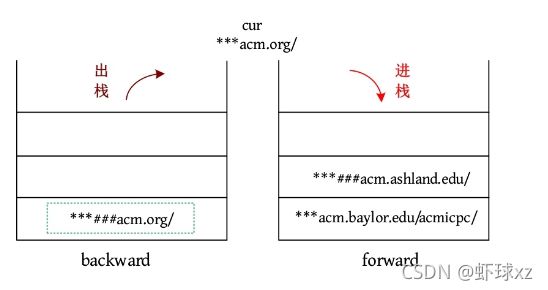
输出cur:***###.acm.org/。
(6)BACK:后向栈为空,输出忽略命令
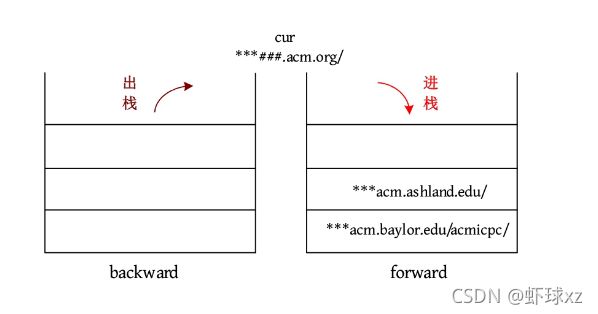
输出:Ignored。
(7)FORWARD:如果前向栈为空,则忽略该命令;否则将当前页面放入后向栈,从前向栈的顶部弹出页面,使其成为新的当前页面。输出当前页面。
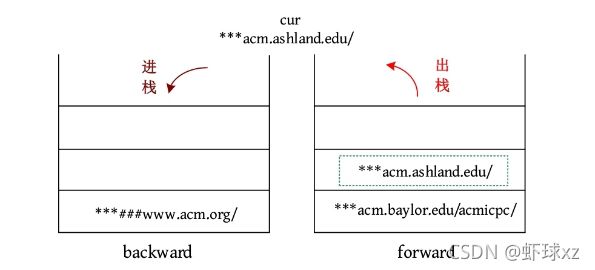
输出cur:***acm.ashland.edu/。
(8)VISIT ***###.ibm.com/,将当前页面放入后向栈的顶部,并使URL成为新的当前页面。前向栈清空。
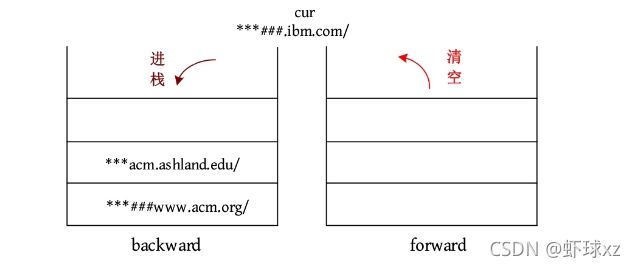
输出cur:***###.ibm.com/
(9)BACK:如果后向栈为空,则忽略该命令;否则将当前页面放入前向栈,从后向栈的顶部弹出页面,使其成为新的当前页面。输出当前页面。
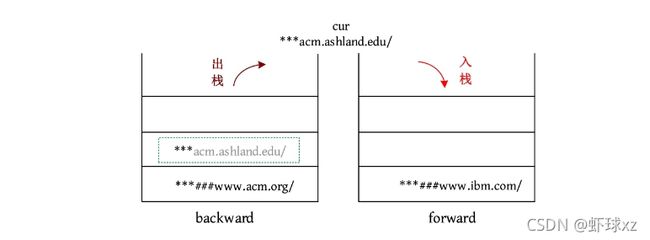
输出cur:***acm.ashland.edu/。
(10)BACK:如果后向栈为空,则忽略该命令;否则将当前页面放入前向栈,从后向栈的顶部弹出页面,使其成为新的当前页面。输出当前页面。
QUIT:结束。
算法实现
#include xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
VISIT ###acm,ashtand.edu/
VISIT *###acm.bayLor.edu/acmicpc/
BACK
BACK
BACK
FORWARD
VISIT ### bm .COmV
BACK
BACK
FORWARD
FORWARD
FORWARD
QUIT
###acm,ashtand.edu/
*###acm.bayLor.edu/acmicpc/
###acm,ashtand.edu/
http://www.acm.org/
Ignored
###acm,ashtand.edu/
###
Ignored
Ignored
###acm,ashtand.edu/
http://www.acm.org/
###acm,ashtand.edu/
###
Ignored
queue
队列(queue)只允许从队尾入队、从队头出队,不允许在中间位置插入和删除,不支持数组表示法和随机访问。使用queue时需要引入头文件#include。队列的基本操作很简单,包括入队、出队、取队头、判断队空、求队列大小。
queueq :创建一个空队q ,数据类型为int。
push(x ):x 入队。
pop():出队。
front():取队头(未出队)。
empty():判断队列是否为空,若为空,则返回true。
size():求队列大小,返回队列中的元素个数。
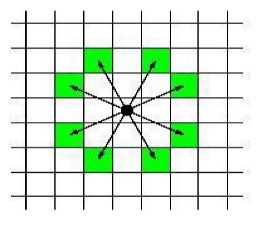
训练 骑士移动
题目描述(POJ1915): 写程序,计算骑士从一个位置移动到另一个位置所需的最少移动次数。骑士移动的规则如下图所示。
输入: 输入的第1行为测试用例的个数N 。每个测试用例都包含3行。第1行表示棋盘的长度L (4≤L ≤300),棋盘的大小为L ×L ;第2行和第3行包含一对{0,…,L -1}×{0,…,L -1}的整数,表示骑士在棋盘上的起始位置和结束位置。假设这些位置是该棋盘上的有效位置。
输出: 对于每个测试用例,都单行输出骑士从起点移动到终点所需的最少移动次数。如果起点和终点相等,则移动次数为零。
\1. 算法设计
本题是求解棋盘上从起点到终点最短距离的问题,可以使用queue进行广度优先搜索,步骤如下:
(1)如果起点正好等于终点,则返回0;
(2)将起点放入队列;
(3)如果队列不空,则队头出队,否则扩展8个方向,如果找到目标,则立即返回步长+1否则判断是否越界;如果没有越界,则将步长+1并放入队列,标记其已访问。如果骑士的当前位置为(x , y ),则移动时当前位置坐标加上偏移量即可。例如骑士从当前位置移动到右上角的位置(x -2, y +1),如下图所示。
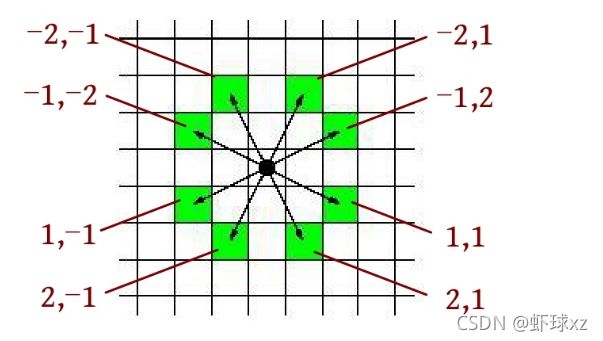
8个方向的位置偏移如下。
int dx[8]={-2,-2,-1,-1,1,1,2,2};
int dy[8]={1,-1,2,-2,2,-2,1,-1};
也可以用一个二维数组int dir [ 8 ] [ 2 ] [8][2] [8][2]={-2,-1,-2,1,-1,-2,-1,2,1,-2,1,2,2,-1,2,1}表示位置偏移。
\2. 算法实现
#include xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
3
8
0 0
7 0
5
100
0 0
30 50
28
10
1 1
1 1
0
list
list是一个双向链表,可以在常数时间内插入和删除,不支持数组表示法和随机访问。使用list时,需要引入头文件#include。
list的专用成员函数如下
merge(b ):将链表b 与调用链表合并,在合并之前,两个链表必须已经排序,合并后经过排序的链表被保存在调用链表中,b 为空。
remove(val):从链表中删除val的所有节点
splice(pos,b ):将链表b 的内容插入pos的前面,b 为空。
reverse():将链表翻转。
sort():将链表排序。
unique():将连续的相同元素压缩为单个元素。不连续的相同元素无法压缩,因此一般先排序后去重。
其他成员函数如下。
push_front(x )/push_back(x ):x 从链表头或尾入。
pop_front()/pop_back():从链表头或尾出
front()/back():返回链表头或尾元素。
insert(p ,t ):在p 之前插入t 。
erase(p ):删除p 。
clear():清空链表。
训练 士兵队列训练
题目描述(HDU1276): 某部队进行新兵队列训练,将新兵从一开始按顺序依次编号,并排成一行横队。训练的规则为从头开始进行1至2报数,凡报2的出列,剩下的向小序号方向靠拢,再从头开始进行1至3报数,凡报到3的出列,剩下的向小序号方向靠拢,继续从头开始进行1至2报数……以后从头开始轮流进行1至2报数、1至3报数,直到剩下的人数不超过3人时为止。
输入: 包含多个测试用例,第1行为测试用例数N ,接着为N 行新兵人数(不超过5 000)
输出: 单行输出剩下的新兵的最初编号,编号之间有一个空格。
\1. 算法设计
本题为报数问题,可以使用list解决
(1)定义一个list,将1~n 依次放入链表尾部。
(2)如果链表中元素大于3,则计数器cnt=1;遍历链表,如果cnt++%k ==0,则删除当前元素,否则指向下一个继续计数;首先k =2报数,报数结束后,再k =3报数,交替进行。
(3)按顺序输出链表中的元素,以空格隔开,最后换行
注意 :慎用STL的list,空间复杂度和时间复杂度都容易超出限制。
\2. 算法实现
#include
#include xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
2
45
1 19 37
12
1 7
deque
deque是一个双端队列,可以在两端进出队,支持数组表示法和随机访问,经常在序列两端操作时应用。使用deque时,需要引入头文件#include。
双端队列的成员函数如下。
push_front(x )/push_back(x ):x 从队头或队尾入队。
pop_front()/pop_back():从队头或队尾出队。
front()/back():返回队头或队尾元素。
size():返回队中的元素个数。
empty():判断队空,若为空,则返回true。
clear():清空双端队列。
训练 度度熊学队列
题目描述(HDU6375): 度度熊正在学习双端队列,它对翻转和合并产生了很大的兴趣。初始时有N 个空的双端队列(编号为1~N) ,度度熊的Q 次操作如下。
①1 u w val:在编号为u 的队列中加入一个权值为val的元素(w =0表示加在最前面,w =1表示加在最后面)。
②2 u w :询问编号为u 的队列中的某个元素并删除它(w =0表示询问并操作最前面的元素,w =1表示询问并操作最后面的元素)
③3 u v w :把编号为v 的队列“接在”编号为u 的队列的最后面。w =0表示顺序接(将队列v 的开头和队列u 的结尾连在一起,将队列v 的结尾作为新队列的结尾),w =1表示逆序接(先将队列v 翻转,再按顺序接在队列u 的后面)。而且在该操作完成后,队列v 被清空。
输入: 有多组数据。对于每一组数据,第1行都包含两个整数N 和Q 。接下来有Q 行,每行3~4个数,意义如上。N ≤1.5× 1 0 5 10^5 105 ;Q ≤4× 1 0 5 10^5 105 ;1≤u ,v ≤N ;0≤w ≤1;1≤val≤ 1 0 5 10^5 105;所有数据里Q 的和都不超过5×105 。
输出: 对于每组数据的每一个操作②,都输出一行表示答案。如果操作②的队列是空的,则输出−1且不执行删除操作。
提示: 由于读入过大,建议使用读入优化。一个简单的例子如下。
void read(int &x)
{
char ch = getchar();x = 0;
for(;ch<'0' || ch > '9';ch = getchar());
for(;ch>='0' && ch<='9';ch = getchar()) x=x*10+ch-'0';
}
\1. 算法设计
本题描述的就是双端队列,可以使用deque解决。
(1)定义一个deque数组d[]。
(2)判断分别执行3种操作,第2种操作需要输出。
(3)第3种情况,由于deque不支持翻转,因此可以使用反向迭代器控制。
if(w)
d[u].insert(d[u].end(),d[v].rbegin(),d[v].rend());
else
d[u].insert(d[u].end(),d[v].begin(),d[v].end());
d[v].clear();
链表支持翻转和拼接,因此也可以采用链表解决,时间复杂度和空间复杂度更小。
(1)定义一个list []。
(2)判断分别执行3种操作,第2种操作需要输出。
(3)第3种情况,list支持翻转,拼接函数splice可以将另一个链表v 拼接到当前链表的pos位置之前,并自动清空v ,且时间复杂度为常数。
if(w)
d[v].reverse();
d[u].splice(d[u].end(),d[v]);
\2. 算法实现
#includepriority_queue
priority_queue是一个优先队列,优先级高的最先出队,默认最大值优先。内部实现为堆因此出队和入队的时间复杂度均为O (logn )。可以自定义优先级控制出队顺序,如果是数值,则也可以采用加负号的方式实现最小值优先,优先队列不支持删除堆中的指定元素,只可以删除堆顶元素,如果需要删除指定元素,则可以采用懒操作。使用priority_queue时,需要引入头文件#include 。
优先队列的成员函数如下。
push(x ):x 入队。
pop():出队
top():取队头。
size():返回队中的元素个数
empty():判断队空,若为空则返回true
训练 黑盒子
题目描述(POJ1442): 黑盒子代表一个原始数据库,保存一个整数数组和一个特殊的i 变量。在最初的时刻,黑盒子是空的,i =0。黑盒子处理一系列命令(事务),有以下两种类型的事务。
ADD(x ):将元素x 放入黑盒子。
GET:将i 增加1,并给出包含在黑盒子中的所有整数中第i 小的值。第i 小的值是黑盒子中按非降序排序后的第i 个位置的数字。
示例如下。
写一个有效的算法来处理给定的事务序列。ADD和GET事务的最大数量均为30 000。用两个整数数组来描述事务的顺序。
(1)A(1),A(2),…,A(M ):包含在黑盒子中的一系列元素。A值是绝对值不超过2 000 000 000的整数,M ≤30 000。对于示例,序列A =(3, 1, -4, 2, 8, -1000, 2)。
(2)u (1),u (2),…,u (N ):表示在第1个,第2个,…,第N 个GET事务时包含在黑盒子中的元素个数。对于示例,u =(1, 2, 6, 6)。
假设自然数序列u (1),u (2),…,u (N )按非降序排序,N ≤M 且每个p (1≤p ≤N )对不等式p ≤u (p )≤M 都有效。由此得出这样的事实:对于u 序列的第p 个元素,执行GET事务,给出A(1),A(2),…,A(u (p ))序列第p 小的数。
输入: 输入包含M ,N ,A(1) ,A(2) ,…,A(M ) ,u (1) ,u (2) ,…,u (N )。
输出: 根据给定的事务顺序输出答案序列,每行一个数字。
\1. 算法设计
可以采用两个优先队列:一个是最大值优先队列q1 ,保存前i -1大的数;另一个是最小值优先队列q2 ,保存从i 到序列末尾的数。q 2 的堆顶就是要查询的第i 小的数。
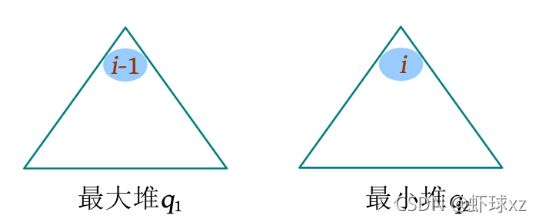
(1)用cnt计数,控制放入黑盒子的元素个数。
(2)读入u (i ),如果cnt≤u (i ),则重复以下操作:如果q 1 不空且a [cnt]<q 1 .top(),则说明a [cnt]属于前i -1大的数,因此将q 1 堆顶放入q 2 ,q 1 堆顶出队,将a [cnt]放入q 1 ;否则,直接将a [cnt]放入q 2 。cnt++。
(3)输出q 2 的堆顶(第i 小的数)。
(4)因为查询第i 小时,i 每次都增1,因此每次处理完毕后,都需要将q 2 中的堆顶放入q 1,q 2 堆顶出队。
\2. 算法实现
#include bitset
bitset是一个多位二进制数,如同状态压缩的二进制数。使用bitset时,需要引入头文件#include。“bitset<1000>s;”表示定义一个1000位的二进制数s 。
基本的位运算有 ~(取反)、&(与)、|(或)、^(异或)、>>(右移)、<<(左移)、==(相等比较)、!=(不相等比较)。
我们可以通过“[ ]”操作符直接得到第k 位的值,也可以通过赋值操作改变该位的值。例如s[k ]=1,表示将二进制数s 的第k 位置1。需要注意的是,最右侧为低位第0位,左侧为高位。1000位的二进制数,位序自右向左是0~999。
成员函数如下
count():统计有多少位是1
any():若至少有一位是1,则返回true
none():若没有位是1,全为0,则返回true
set():将所有位置1。
set(k ):将第k 位置1
set(k ,val):将第k 位的值改为val,即s [k ]=val
reset():将所有位置0
reset(k ):将第k 位置0,即s [k ]=0
flip():将所有位取反
flip(k ):将第k 位取反
size():返回大小(位数)
to_ulong():返回它转换为unsigned long的结果,如果超出范围,则报错
to_string():返回它转换为string的结果
1)bitset定义和初始化
下面列出了bitset的构造函数
bitset<n> b;
bitset<n> b(u);
bitset<n> b(s);
bitset<n> b(s,pos,n);
在定义bitset时,要明确bitset有多少位,必须在尖括号内给出它的长度值,给出的长度值必须是常量表达式。“bitset<32> bitvec;”表示定义bitvec为32位的bitset对象,bitvec的位序自右向左为0~31。
训练 集合运算
题目描述(POJ2443): 给定N 个集合,第i 个集合S i 有C i 个元素(集合可以包含两个相同的元素)。集合中的每个元素都用1~10 000的正数表示。查询两个给定元素i 和j 是否同时属于至少一个集合。换句话说,确定是否存在一个数字k (1≤k ≤N ),使得元素i 和元素j 都属于S k 。
输入: 输入的第1行包含一个整数N (1≤N ≤1000),表示集合的数量。第2~N +1行,每行都以数字Ci (1≤C i ≤10 000)开始,后面有C i 个数字,表示该集合中的元素。第N +2行包含一个数字Q (1≤Q ≤200 000),表示查询数。接下来的Q 行,每行都包含一对数字i 和j(1≤i , j ≤10 000,i 可以等于j ),表示待查询的元素。
输出: 对于每个查询,如果存在这样的数字k ,则输出“Yes”,否则输出“No”
\1. 算法设计
本题查询两个元素是否同属于一个集合(至少一个)。所属集合可以用二进制表示法
每个元素都可以用一个二进制数记录所属的集合。最右侧为低位0位,自右向左。例如,1属于第1个集合,就将1对应的二进制数的第1位置为1,即s [1]=0010;1还属于第2个集合,就将1对应的二进制数的第2位置为1,即s [1]=0110;s [1]=0110表示元素1属于1、2两个集合。同理,s [2]=0110,s [3]=0010,s [5]=0100,s [10]=1000。
可以采用bitset解决。
1)定义一个bitset数组,对每个数都用二进制表示。
(2)根据输入数据,将元素所属集合对应的位置为1。
(3)根据查询输入的两个数x 、y ,统计s [x ]&s [y ]运算后二进制数中1的个数,如果大于或等于1,则输出“Yes”,否则输出“No”。
- 算法实现
#include xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
1 2
1
2 3
1.2.3
2 2
1 1
2 2
1.2
训练2 并行处理
题目描述(POJ1281): 并行处理中的编程范型之一是生产者/消费者范型,可以使用具有管理者进程和多个客户进程的系统来实现。客户可以是生产者、消费者等,管理者跟踪客户进程。每个进程都有一个成本(正整数,范围是1~10 000)。具有相同成本的进程数不能超过10 000。队列根据三种类型的请求进行管理,如下所述。
a x :将成本为x 的进程添加到队列中。
r :根据当前管理者策略从队列中删除进程(如果可能)
p i :执行管理者的策略i ,其中i 是1或2。1表示删除最小成本进程;2表示删除最大成本进程。默认管理者策略为1。
e :结束请求列表。
只有在删除列表中包含已删除进程的序号时,管理者才会输出已删除进程的成本。编写一个程序来模拟管理者进程
输入: 输入中的每个数据集都有以下格式。
进程的最大成本
删除列表的长度
删除列表。查询已删除进程的序号列表;例如1 4,表示查询第1个和第4个已删除进程的成本。
每个请求列表,各占一行
每个数据集都以e 请求结束。数据集以空行分隔。
输出: 如果删除请求的序号在列表中,并且此时队列不为空,则单行输出删除的每个进程的成本。如果队列为空,则输出-1。以空行分隔不同数据集的结果。
\1. 算法设计
因为可能有多个相同成本,因此使用multiset解决。
(1)用vis[]标记删除列表要显示的序号。
(2)默认管理者策略,p =1。
(3)读入字符,判断执行相应的操作。
(4)进行删除操作时,如果队列为空,则输出-1;判断管理者策略,如果p =1,则删除最小成本,否则删除最大成本。如果删除的成本序号在删除列表中,则输出该成本。
\2. 算法实现
#includemap/multimap
map的键和值可以是不同的类型,键是唯一的,每个键都对应一个值。multimap与map类似,只是允许一个键对应多个值。map可被当作哈希表使用,它建立了从键(关键字)到值的映射。map是键和值的一一映射,multimap是一对多映射。使用map或multimap时需要引入头文件#include。
map的迭代器和set类似,支持双向访问,不支持随机访问,执行一次“++”和“–”操作的时间复杂度均为O (logn )。默认的元素顺序为升序,也可以通过第3个模板参数设置为降序
map<string int>a //升序
map<string int,greater<string>>a;//降序
上述map模板的第1个参数为键的类型,第2个参数为值的类型,第3个参数可选,用于对键进行排序的比较函数或对象。
在map中,键和值是一对数,可以使用make_pair生成一对数(键,值)进行插入。
a.insert(make_pair(s, i));
输出时,可以分别输出第1个元素(键)和第2个元素(值)
for (map<string, int>::iterator it=a.begin () ,it!=a.end() ,it++)
cout<<it->first<<"\t"<<it->second<<end1;
成员函数如下。
size/empty/clear:元素个数、判空、清空。
begin/end:开始位置和结束位置。
insert(x ):将元素x 插入集合(x 为二元组)
erase(x ):删除所有等于x 的元素(x 为二元组)
erase(it):删除it指向的元素(it为指向二元组的迭代器)
find(k ):查找键为k 的二元组的位置,若不存在,则返回尾指针
可以通过“[ ]”操作符直接得到键映射的值,也可以通过赋值操作改变键映射的值,例如h[key]=val。是不是特别像哈希表?
例如,可以用map统计字符串出现的次数
map<string,int>mp;
string word;
for(int i = 0;i<n;i++)
{
cin>>s;
mp[s]++;
}
cout<<"输入字符串 s, 查询该字符串出现的次数:"<<endl:
cin>>s;
cout<<mp[s]<<endl;
需要特别注意的是,如果查找的key不存在,则执行h[key]之后会自动新建一个二元组(key,0)并返回0,进行多次查找之后,有可能包含很多无用的二元组。因此使用查找时最好先查询key是否存在。
if(mp.find(s) !=mp.end())
cout<<mp[s]<<endl;
else
cout<<"不存在"<<endl;
multimap和map类似,不同的是一个键可以对应多个值。由于是一对多的映射关系,multimap不能使用“[ ]”操作符。
例如,可以添加多个关于X国的数据
训练1 硬木种类
题目描述(POJ2418): 某国有数百种硬木树种,该国自然资源部利用卫星成像技术编制了一份特定日期每棵树的物种清单。计算每个物种占所有种群的百分比。
输入: 输入包括每棵树的物种清单,每行一棵树。物种名称不超过30个字符,不超过10 000种,不超过1 000 000棵树。
输出: 按字母顺序输出植物种群中代表的每个物种的名称,然后是占所有种群的百分比,保留小数点后4位。
\1. 算法设计
本题统计每个物种的数量,计算占所有种群的百分比。可以在排序后统计并输出结果,也可以利用map自带的排序功能轻松统计。
\2. 算法实现
#include 训练2 双重队列
题目描述(POJ3481): 银行的每个客户都有一个正整数标识K ,到银行请求服务时将收到一个正整数优先级P 。银行经理提议打破传统,有时为优先级最低的客户服务,而不是为优先级最高的客户服务。系统将收到以下类型的请求
0:系统需要停止服务
1 K P :将客户K 及其优先级P 添加到等待列表中。
2:为优先级最高的客户提供服务,并将其从等待名单中删除。
3:为优先级最低的客户提供服务,并将其从等待名单中删除。
输入: 输入的每一行都包含一个请求,只有最后一行包含停止请求(代码0)。假设在列表中包含新客户的请求时(代码1),在列表中没有同一客户的其他请求或有相同的优先级。标识符K 小于106 ,优先级P 小于107 。客户可以多次到银行请求服务,并且每次都可以获得不同的优先级。
输出: 对于代码为2或3的每个请求,都单行输出所服务客户的标识。如果请求时等待列表为空,则输出0。
\1. 算法设计
本题包括插入、删除优先级最大元素和删除优先级最小元素这3种操作。map本身按第1元素(键)有序,因此将优先级作为第1元素即可。
\2. 算法实现
#include 训练3 水果
题目描述(HDU1263): Joe经营着一家水果店,他想要一份水果销售情况明细表,这样就可以很容易掌握所有水果的销售情况了。
输入: 第1行输入正整数N (0<N ≤10),表示有N 组测试数据。每组测试数据的第1行都是一个整数M (0<M ≤100),表示共有M 次成功的交易。其后有M 行数据,每行都表示一次交易,由水果名称(小写字母组成,长度不超过80)、水果产地(由小写字母组成,长度不超过80)和交易的水果数量(正整数,不超过100)组成。
输出: 对每组测试数据,都按照输出样例输出水果销售情况明细表。这份明细表包括所有水果的产地、名称和销售数量的信息。水果先按产地分类,产地按照字母顺序排列;同一产地的水果按照名称排序,名称按照字母顺序排序。每两组测试数据之间都有一个空行。最后一组测试数据之后没有空行。
\1. 算法设计
本题统计水果销售情况(产地、名称和销售数量)。水果按产地分类,产地按照字母顺序排序;同一产地的水果按照名称排序,名称按照字母顺序排序。可以利用map的有序性和映射关系轻松解决。
(1)定义一个map,其第1元素(键)为产地,第2元素(值)也是一个map,记录名称和销售数量。“map
(2)根据输入信息,统计销售数量, m p [ p l a c e ] [ n a m e ] + = n u m mp[place][name]+=num mp[place][name]+=num。
(3)按顺序输出统计信息。
\2. 算法实现
#include STL的常用函数
STL提供了一些常用函数,包含在头文件#include中,如下所述
(1)min(x ,y ):求两个元素的最小值。
(2)max(x ,y ):求两个元素的最大值。
(3)swap(x ,y ):交换两个元素。
(4)find(begin,end,x ):返回指向区间[begin,end)第1个值为x 的元素指针。如果没找到,则返回end。
(5)count(begin,end,x ):返回指向区间[begin,end)值为x 的元素数量,返回值为整数。
(6)reverse(begin,end):翻转一个序列。
(7)random_shuffle(begin,end):随机打乱一个序列。
(8)unique(begin,end):将连续的相同元素压缩为一个元素,返回去重后的尾指针。不连续的相同元素不会被压缩,因此一般先排序后去重。
(9)fill(begin,end,val):将区间[begin,end)的每个元素都设置为val。
(10)sort(begin,end,compare):对一个序列排序,参数begin和end表示一个范围,分别为待排序数组的首地址和尾地址;compare表示排序的比较函数,可省略,默认为升序。stable_sort (begin, end, compare)为稳定排序,即保持相等元素的相对顺序。
(11**)** nth_element(begin,begin+k ,end,compare):使区间[begin,end)第k 小的元素处在第k 个位置上,左边元素都小于或等于它,右边元素都大于或等于它,但并不保证其他元素有序。
(12)lower_bound(begin,end,x )/upper_bound(begin,end,x ):两个函数都是利用二分查找的方法,在有序数组中查找第1个满足条件的元素,返回指向该元素的指针。
(13)next_permutation(begin,end)/pre_permutation(begin,end):next_permutation()是求按字典序的下一个排列的函数,可以得到全排列。pre_permutation()是求按字典序的上一个排列的函数。
下面详细讲解后5种函数。
\1. fill(begin,end,val)
fill(begin,end,val)将区间[begin,end)的每个元素都设置为val。与#include中的memset不同,memset是按字节填充的。例如,int占4字节,因此memset(a ,0x3f,sizeof(a ))按字节填充相当于将0x3f3f3f3f赋值给数组a []的每个元素。memset经常用来初始化一个int型数组为0、-1,或者最大值、最小值,也可以初始化一个bool型数组为true(1)或false(0)。
不可以用memset初始化一个int型数组为1,因为memset(a ,1,sizeof(a ))相当于将每个元素都赋值为0000 0001 0000 0001 0000 0001 0000 0001,即将0000 0001分别填充到4字节中。布尔数组可以赋值为true,是因为布尔数组中的每个元素都只占1字节。
memset (a, 0,sizeof(a));//初始化为0
memset (a,-1,sizeof(a)) ;//初始化为-1
memset (a, 0x3f,sizeof(a)) ; //初始化为最大值 0x3f3f3f3f
memset (a, 0xcf,sizeof(a)); //初始化为最小值 0xcfcfcfcf
需要注意的是,动态数组或数组作为函数参数时,不可以用sizeof(a )测量数组空间,因为这样只能测量到首地址的空间。可以用memset(a ,0x3f,n ×sizeof(int))的方法处理,或者用fill函数填充。
如果用memset(a ,0x3f,sizeof(a ))填充double类型的数组,则经常会得到一个连1都不到的小数。double类型的数组填充极值时需要用fill(a ,a +n ,0x3f3f3f3f)。
尽管0x7fffffff是32-bit int的最大值,但是一般不使用该值初始化最大值,因为0x7fffffff不能满足“无穷大加一个有穷的数依然是无穷大”,它会变成一个很小的负数。0x3f3f3f3f的十进制是1061109567,也就是109 级别的(和0x7fffffff在一个数量级),而一般情况下的数据都是小于109 的,所以它可以作为无穷大使用而不至于出现数据大于无穷大的情形。另一方面,由于一般的数据都不会大于109 ,所以当把无穷大加上一个数据时,它并不会溢出(这就满足了“无穷大加一个有穷的数依然是无穷大”)。事实上,0x3f3f3f3f+0x3f3f3f3f=2122219134,这非常大但却没有超过32-bit int的表示范围,所以0x3f3f3f3f还满足了“无穷大加无穷大还是无穷大”的需求。
\2. sort(begin,end,compare)
(1)使用默认的函数排序。
#include (2)自定义比较函数。sort函数默认为升序排序。如何用sort函数实现降序排序呢?自己可以编写一个比较函数来实现,接着调用含3个参数的sort(begin,end,compare),前两个参数分别为待排序数组的首地址和尾地址,最后一个参数表示比较的类型。自定义比较函数同样适用于结构体类型,可以指定按照结构体的某个成员进行升序或降序排序。
#include xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
421 213 41 21 12 3 3 2 2 1
(3)利用functional标准库。其实对于这么简单的任务(类型支持“<”“>”等比较运算符),完全没必要自己写一个类出来,引入头文件#include即可。functional提供了一些基于模板的比较函数对象。
equal_to:等于。
not_equal_to:不等于。
greater:大于
greater_equal:大于或等于。
less:小于
less_equal:小于或等于。
升序:sort(begin,end,less())。
降序:sort(begin,end,greater())
#include \3. nth_element(begin,begin+k ,end,compare)
当省略最后一个参数时,该函数使区间[begin,end)第k (k 从0开始)小的元素处在第k 个位置上。当最后一个参数为greater()时,该函数使区间[begin,end)第k 大的元素处在第k个位置上。特别注意:在函数执行后会改变原序列,但不保证其他元素有序。
xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
4 2 5 6 20 15 7 //第2 小的数 5 在第 2 个位置上
15 20 7 6 4 5 2 //第2 大的数 7 在第 2 个位置上
- lower_bound(begin,end,x )/upper_bound(begin,end,x ) lower_bound()和upper_bound()都是用二分查找的方法在一个有序数组中查找第1个满足条件的元素。
1)在从小到大的排序数组中
lower_bound(begin,end,x ):从数组的begin位置到end-1位置二分查找第1个大于或等于x 的元素,找到后返回该元素的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到元素在数组中的下标。
upper_bound(begin,end,x ):从数组的begin位置到end-1位置二分查找第1个大于x 的元素,找到后返回该元素的地址,不存在则返回end。
2)在从大到小的排序数组中
lower_bound(begin,end,x ,greater()):从数组的begin位置到end-1位置二分查找第1个小于或等于x 的元素,找到后返回该元素的地址,不存在则返回end。
upper_bound(begin,end,x ,greater()):从数组的begin位置到end-1位置二分查找第1个小于x 的元素,找到后返回该元素的地址,不存在则返回end。
#include \5. next_permutation(begin,end)/pre_permutation(begin,end)
next_permutation()是求按字典序排序的下一个排列的函数,可以得到全排列。pre_permutation()是求按字典序排序的上一个排列的函数。
1)int类型的next_permutation
#include xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
如果改成“while(next_permutation(a ,a +2));”,则输出:
xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
1 2 3
2 1 3
只对前两个元素进行字典序排序。显然,如果改成“while(next_permutation(a ,a+1));”,则只输出
xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
1 2 3
若排列本来就最大且没有后继,则在next_permutation执行后,对排列进行字典升序排序,相当于循环。
2)char类型的next_permutation
#include xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
123
123
132
213
231
312
321
3)string类型的next_permutation
#include xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
qw as sd
qw
wq
as
sa
ds
sd
训练1 差的中位数
题目描述(POJ3579): 给定N 个数$X^1 , X^2 ,…, X^N , 计 算 每 一 对 数 字 的 差 : ,计算每一对数字的差: ,计算每一对数字的差:|X_i -X_j |,1≤i <j ≤N$ 。请尽快找到差的中位数!
注意,在这个问题中,中位数被定义为第m/2个数,m 为差的数量。
输入: 输入由几个测试用例组成。每个测试用例的第1行都为N 。然后给出N 个数字,表示X 1 , X 2 ,…, X N ( Xi ≤109 ,3≤N ≤105 )
输出: 对于每个测试,都单行输出差的中位数。
\1. 算法设计
本题数据量较大, N ≤ 1 0 5 N ≤10^5 N≤105 ,如果枚举每两个数的差,然后找中位数,则时间复杂度为O (N^2 ),N ^2 ≤10^10 ,时间限制为1秒,显然超时。可以采用二分法查找差的中位数。使用algorithm头文件中的lower_bound()函数查找第1个大于或等于a [i ]+val的数,统计有多少个数与a [i ]的差值大于或等于val,步骤如下。
(1)对序列排序。可调用algorithm头文件中的sort()。
(2)二分查找,如果差值大于或等于mid的数多于一半,则向后查找,否则向前查找。
int l = 0,r = a[n - 1] - a[0];
while(l <= r)
{
int mid = (l + r)>>1;
if(check(mid))
{
ans = mid;
l = mid + 1;
}
else
r = mid - 1;
}
check函数统计有多少个数的差大于或等于val。对于每一个a [i ],都统计有多少个数与a [i]的差大于或等于val,可以采用lower_bound(a ,a +n ,a [i ]+val)找到第1个大于或等于a [i ]+val的数a [k ](相当于a [k ]-a [i ]≥val),减去首地址a 得到该数的下标k ,n -k 即差值大于或等于val的数的个数。n 个数两两求差,差的序列共有n (n -1)/2个,该序列的一半即m ,m =n ×(n-1)/4。
bool check(int val)
{
int cnt = 0;
for(int i = 0;i<n;i++)
cnt+=n-(lower_bound(a,a+n,a[i]+val) - a);
return cnt>m;
}
(3)输出答案ans即可。
\2. 完美图解
输入样例1,包含4个数1、3、2、4,求差的中位数。
(1)排序,排序后的结果如下图所示。
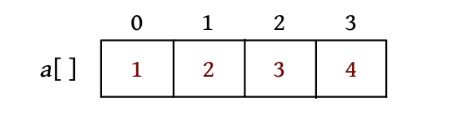
(2)二分搜索。m =n ×(n -1)/4=3;l =0,r =a [n -1]-a [0]=3,求解如下。
• mid=(l +r )/2=1,统计有多少个数的差大于或等于1。
i =0:第1个大于或等于a [0]+1的下标为1,有n -1=3个数与a [0]的差大于或等于1。
i =1:第1个大于或等于a [1]+1的下标为2,有n -2=2个数与a [1]的差大于或等于1。
i =2:第1个大于或等于a [2]+1的下标为3,有n -3=1个数与a [2]的差大于或等于1。
i =4:第1个大于或等于a [3]+1的下标为n (不存在则为n ),有n -n =0个数与a [3]的差大于或等于1。
cnt=3+2+1+0=6>m (m =3),差大于或等于1的数多于一半,说明差的中位数在后半部分,ans=mid=1;l =mid+1=2,r =3,继续求解。
• mid=(l +r )/2=2,统计有多少个数的差大于或等于2。
i =0:第1个大于或等于a [0]+2的下标为2,有n -2=2个数与a [0]的差大于或等于2。
i =1:第1个大于或等于a [1]+2的下标为3,有n -3=1个数与a [1]的差大于或等于2。
i =2:第1个大于或等于a [2]+2的下标为n (不存在则为n ),有n -n =0个数与a [2]的差大于或等于2。
i =4:第1个大于或等于a [3]+2的下标为n (不存在则为n ),有n -n =0个数与a [3]的差大于或等于2。
cnt=2+1+0+0=3不大于m (m =3),差大于或等于2的数少于等于一半,说明差的中位数在前半部分,r =mid-1=1,此时l =2,不满足二分条件l ≤r ,循环结束。
(3)输出答案ans=1。
\3. 算法分析
排序的时间复杂度为O (n logn ),二分搜索的时间复杂度为O (logX max ),lower_bound()函数内部也是二分查找,时间复杂度为O (logn ),check函数的总时间复杂度为O (n logn )。X max =109 ,log109 ≈log230 ≈30,n ≤105 ,n logn ≈106 ,在一般情况下,107 以内均可通过1秒测试。
#include训练2 中位数
题目描述(POJ2388): 约翰正在调查他的牛群以寻找产奶量最平均的奶牛。他想知道这头“中位数”奶牛的产奶量是多少:一半的奶牛产奶量与“中位数”奶牛的产奶量一样多或更多;另一半与“中位数”奶牛的产奶量一样多或更少。给定奶牛的数量N (1≤N <10 000,N 为奇数)及其牛奶产量(1~1 000 000),找产奶量的中位数。
输入: 第1行为整数N ;第2~N +1行,每行都包含一个整数,表示一头奶牛的产奶量
输出: 单行输出产奶量的中位数。
本题很简单,可以在排序后输出中位数,或者使用nth_element函数找中位数(第n /2小),后者速度更快。
#include 训练3 订单管理
**题目描述(POJ1731):**商店经理按货物标签的字母顺序对各种货物进行分类,将所有拥有以同一个字母开头的标签的货物都存储在同一个仓库中,并用该字母标记。经理收到并登记从商店发出的货物订单,每个订单只需要一种货物。商店经理按照预订的顺序处理请求。请计算经理访问仓库的所有可能方式,以便在一天中一个接一个地解决所有需求。
输入: 输入包含一行,其中包含所需货物的所有标签(随机排列)。对每种货物都用标签的起始字母表示,只使用英文字母表中的小字母。订单数量不超过200个。
输出: 输出将包含商店经理可以访问其仓库的所有可能的订单。对每个仓库都用英文字母表中的一个小字母表示——货物标签的起始字母。仓库的每个排序在输出文件中只在单独的行上写入一次,并且包含排序的所有行必须按字母顺序排序(请参见样例)。任何输出都不会超过2MB字节。
本题其实就是按顺序输出字符串的全排列,可以使用algorithm头文件中的next_permutation函数求解。这是一个求一个排序的下一个排列的函数,可以得到全排列。
#include 训练4 字谜
题目描述(POJ1256): 写程序从一组给定的字母中生成所有可能的单词。例如,给定单词“abc”,应该输出单词“abc”“acb”“bac”“bca”“cab”和“cba”。在输入的单词中,某些字母可能会出现多次。对于给定的单词,程序不应多次生成同一个单词,并且这些单词应按字母升序输出。
输入: 输入由几个单词组成。第1行包含一个数字,表示单词数。以下每行各包含一个单词。单词由a到z的大小写字母组成。大小写字母应被视为不同。每个单词的长度都小于13。
输出: 对于输入中的每个单词,输出应该包含所有可以用给定单词的字母生成的不同单词。由同一输入词生成的词应按字母升序输出。大写字母在对应的小写字母之前。
提示: 大写字母在相应的小写字母之前,所以正确的字母顺序是’A’<‘a’<‘B’<‘b’<…<‘Z’<‘z’
题解: 本题要求按正确的字母顺序输出全排列,可以使用algorithm头文件中的next_ permutation函数,需要自定义优先级。
#include xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
3
aAb
Aab
Aba
aAb
abA
bAa
baA
abc
abc
acb
bac
bca
cab
cba
acca
aacc
acac
acca
caac
caca
ccaa
线性表的应用
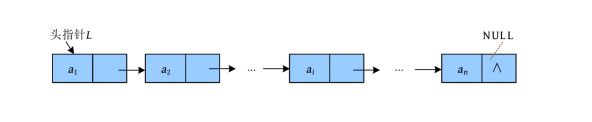
线性表是由n (n ≥0)个相同类型的数据元素组成的有限序列,它是最基本、最常用的一种线性结构。顾名思义,线性表就像是一条线,不会分叉。线性表有唯一的开始和结束,除了第1个元素,每个元素都有唯一的直接前驱;除了最后一个元素,每个元素都有唯一的直接后继,如下图所示
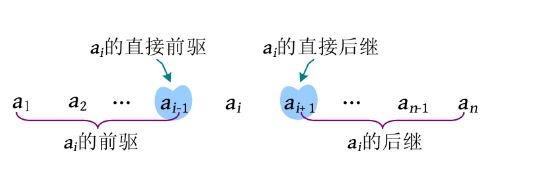
注意: 为了描述方便,在本书中提到的前驱和后继均指直接前驱和直接后继
线性表有两种存储方式:顺序存储和链式存储。采用顺序存储的线性表被称为顺序表,采用链式存储的线性表被称为链表。
顺序表
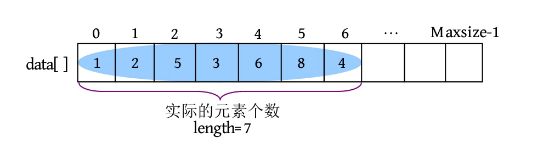
顺序表是顺序存储方式,即逻辑上相邻的数据在计算机内的存储位置也是相邻的。在顺序存储方式中,元素存储是连续的,中间不允许有空,可以快速定位某个元素,所以插入、删除时需要移动大量元素。根据分配空间方法的不同,顺序表可以分为静态分配和动态分配两种。
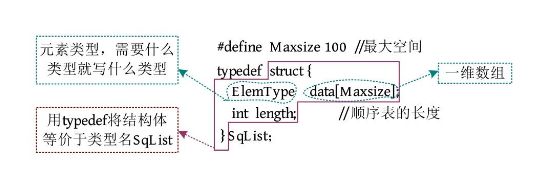
在顺序表中,最简单的方法是使用一个定长数组data[]存储数据,最大空间为Maxsize,用length记录实际的元素个数,即顺序表的长度。这种用定长数组存储的方法被称为静态分配
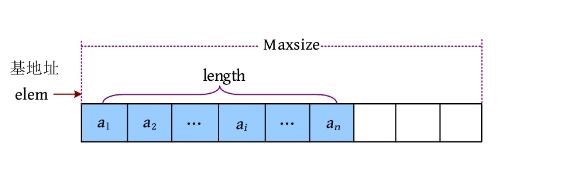
当采用静态分配的方法时,定长数组需要预先分配一段固定大小的连续空间,但是在运算过程中进行合并、插入等操作容易超过预分配的空间长度,并出现溢出。可以采用动态分配的方法解决溢出问题。
在程序运行过程中,根据需要动态分配一段连续的空间(大小为Maxsize),用elem记录该空间的基地址(首地址),用length记录实际的元素个数,即顺序表的长度。采用动态分配方法时,在运算过程中如果发生溢出,则可以另外开辟一块更大的存储空间,用来替换原来的存储空间,从而达到扩充存储空间的目的。
顺序表的动态分配结构体定义如下图所示。

\1. 插入
在顺序表中的第i 个位置之前插入一个元素e ,需要从最后一个元素开始,后移一位……直到把第i 个元素也后移一位,然后把e 放入第i 个位置,如下图所示。
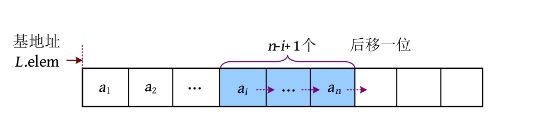
算法步骤:
(1)判断插入位置i 是否合法(1≤i ≤L .length+1),可以在第1个元素之前插入,也可以在第L .length+1个元素之前插入。
(2)判断顺序表的存储空间是否已满。
(3)将第L .length至第i 个元素依次向后移动一个位置,空出第i 个位置
(4)将要插入的新元素e 放入第i 个位置。
(5)表长加1,插入成功后返回true。
完美图解: 例如,在顺序表中的第5个位置之前插入一个元素9。
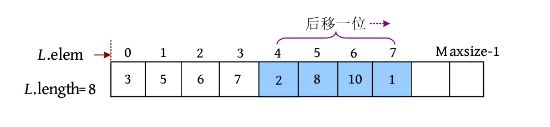
(1)移动元素。从最后一个元素(下标为L .length−1)开始后移一位,移动过程如下图所示。
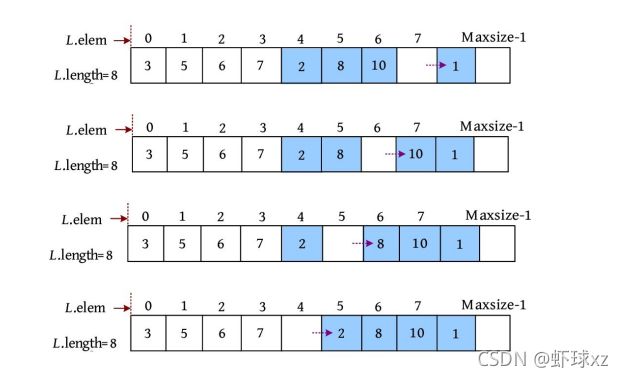
(2)插入元素。此时第5个位置空出来,将要插入的元素9放入第5个位置,表长加1。
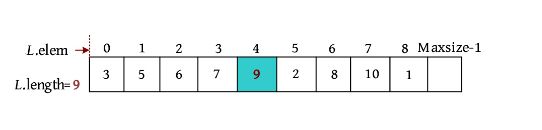
算法代码 :
bool ListInsert_Sq(SqList &L,int i,int e)
{
if(i < 1 || i>L.length + 1) return false;
if(L.length == MaxSize)return false;
for(int j=L.length - 1;j>i-1;j--)
L.elem[j+1] = L.elem[j];
L.elem[i-1] = e;
L.length++;
return true;
}
算法分析: 可以在第1个位置之前插入,也可以在第2个位置之前插入……在第n 个位置之前插入或在第n +1个位置之前插入,共有n +1种情况,每种情况下移动元素的个数都是n −i +1。把每种情况移动次数乘以其插入概率pi 并求和,即平均时间复杂度。如果插入概率均等,即每个位置的插入概率均为1/(n +1),则平均时间复杂度如下:
∑ i = 1 n + 1 p i × ( n − i + 1 ) = 1 n − 1 ∑ i = 1 n + 1 n − i + 1 = 1 n + 1 ( n + ( n − 1 ) + . . . + 1 + 0 ) = n 2 \sum_{i=1}^{n+1}p_i\times(n-i+1) = \frac{1}{n-1}\sum_{i=1}^{n+1}{n-i+1}=\frac{1}{n+1}(n+(n-1)+...+1+0) = \frac{n}{2} i=1∑n+1pi×(n−i+1)=n−11i=1∑n+1n−i+1=n+11(n+(n−1)+...+1+0)=2n
因此,假设每个位置插入的概率均等,则顺序表中插入元素算法的平均时间复杂度为O (n )。
\2. 删除
在顺序表中删除第i 个元素时,需要把该元素暂存到变量e 中,然后从第i +1个元素开始前移……直到把第n 个元素也前移一位,即可完成删除操作。
算法步骤:
(1)判断插入位置i 是否合法(1≤i ≤L .length)。
(2)将欲删除的元素保留在e 中。
(3)将第i +1至第n 个元素依次向前移动一个位置。
(4)表长减1,若删除成功则返回true。
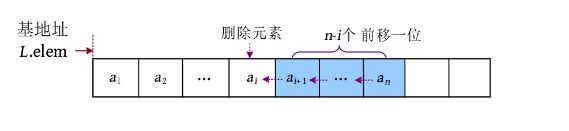
完美图解: 例如,从顺序表中删除第5个元素,如下图所示。
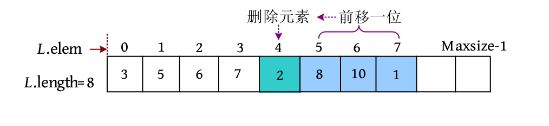
(1)移动元素。首先将待删除元素2暂存到变量e 中,以后可能有用,如果不暂存,则将被覆盖。然后从第6个元素开始前移一位,移动元素的过程如下图所示。
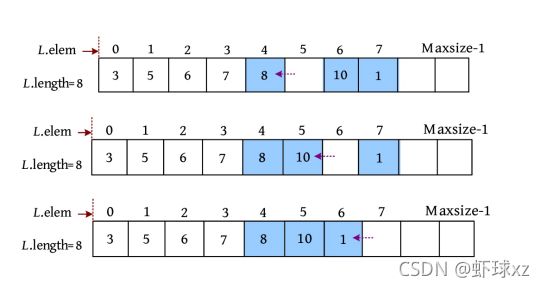
(2)表长减1,删除元素后的顺序表如下图所示。

算法代码 :
bool ListDelete_Sq(SqList &L,int i,int &e)
{
if(i<1 || i>L.length) return false; //i 值不合法
e=L.elem[i-1];//将欲删除的元素保留在 e 中
for(int j = i;j<=L.length-1;j++)
{
L.elem[j-1] = L.elem[j];//被删除元素之后的元素前移
}
L.length--;
return true;
}
算法分析: 在顺序表中删除元素共有n 种情况,每种情况移动元素的个数都是n −i。把每种情况移动次数乘以其删除概率pi 并求和,即平均时间复杂度。假设删除每个元素的概率均等,即每个元素的删除概率均为1/n ,则平均时间复杂度如下:
因此,假设每个元素删除的概率均等,则顺序表中删除元素算法的平均时间复杂度为O (n )。
单链表
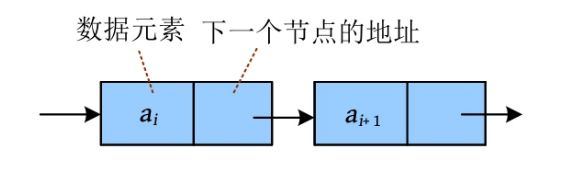
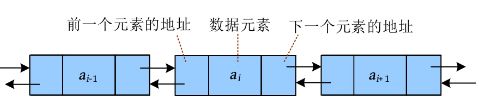
链表是线性表的链式存储方式,逻辑上相邻的数据在计算机内的存储位置不一定相邻,那么怎么表示逻辑上的相邻关系呢?可以给每个元素都附加一个指针域,指向下一个元素的存储位置。
从下图可以看出,每个节点都包含两个域:数据域和指针域。数据域存储数据元素,指针域存储下一个节点的地址,因此指针指向的类型也是节点类型。链表中的每个指针都指向下一个节点,都朝向一个方向的,这样的链表被称为单向链表或单链表。
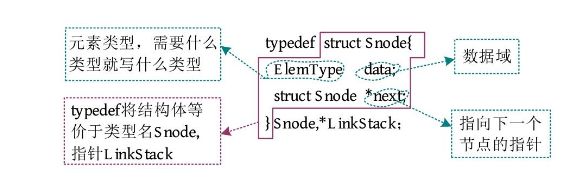
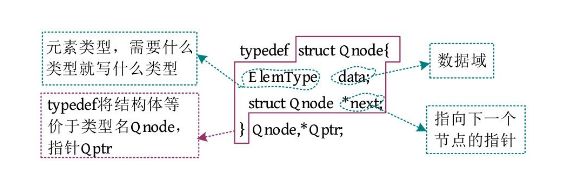
单链表的节点结构体定义如下图所示。
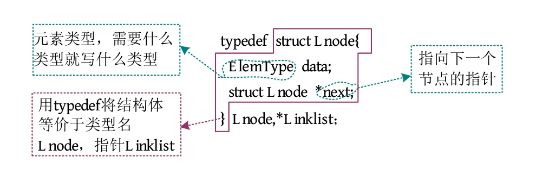
定义了节点结构体之后,就可以把若干节点连接在一起,形成一个单链表了。

不管这个单链表有多长,只要找到它的头,就可以拉起整个单链表,因此如果给这个单链表设置一个头指针,则这个单链表中的每个节点就都可以找到了。
有时为了操作方便,还会给单链表增加一个不存放数据的头节点(也可以存放表长等信息)。给单链表加上头节点,就像给铁链子加上钥匙扣。
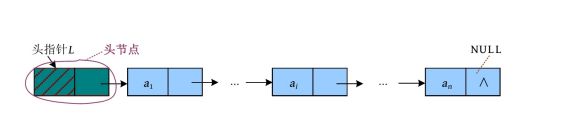
若想在顺序表中找第i 个元素,则可以立即通过L .elem[i -1]找到,想找哪个就找哪个,被称为随机存取。但若想在单链表中找第i 个元素该怎么办?答案是必须从头开始,按顺序一个一个地找,一直数到第i 个元素,被称为顺序存取。
(1)插入。在第i 个节点之前插入元素e ,相当于在第i -1个节点之后插入元素e 。假设已找到第i -1个节点,并用p 指针指向该节点,s 指向待插入的新节点,则插入操作如下图所示。
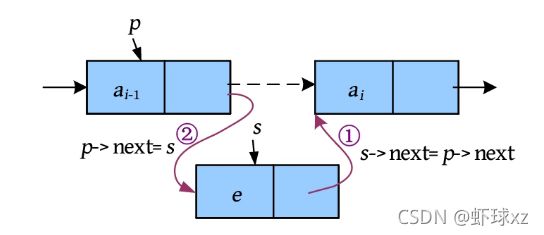
其中,“s ->next=p ->next”指将节点p 后面的节点地址赋值给节点s 的指针域,即节点s 的next指针指向p 后面的节点;“p ->next=s”指将节点s 的地址赋值给节点p的指针域,即节点p 的next指针指向节点s 。
算法代码:
bool ListInsert_T(LinkList &L,int i,int e) //单链表的插入,在第 1 个节点之前插入元素e
{
//在带头节点的单链表 L 中第 i 个位置之前插入值为 e 的新节点
int j;
LinkList p,s;
p=L;
j=0;
while(p&&j<i-1) //查找第 i-1 个节点,P 指向该节点
{
p=p->next;
j++;
}
if(!p||j>i-1)
return false;
s = new Lnode;
s->data=e;
s->next = p->next;
p->next = s;
return true;
}
(2)删除。删除一个节点,实际上是把这个节点跳过去。根据单向链表向后操作的特性,要想跳过第i 个节点,就必须先找到第i -1个节点,否则是无法跳过去的,如下图所示。
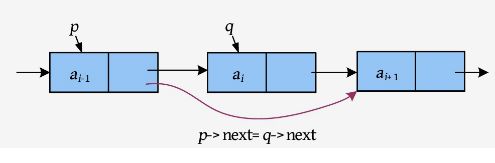
其中,“p ->next=q ->next”指将节点q 的下一个节点地址赋值给节点p 的指针域。
在这些有关指针的赋值语句中,等号的右侧是节点的地址,等号的左侧是节点的指针域,如下图所示。
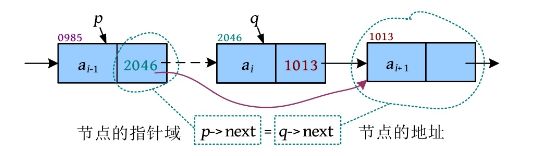
在上图中,假设节点q 的下一个节点地址为1013,该地址被存储在q ->next里面,因此等号右侧q ->next的值为1013。把该地址赋值给节点p 的next指针域,把原来的值2046覆盖,这样,p ->next的值也为1013,相当于把节点q 跳过去了。赋值之后如下图所示。然后用delete q 释放被删除节点的空间。
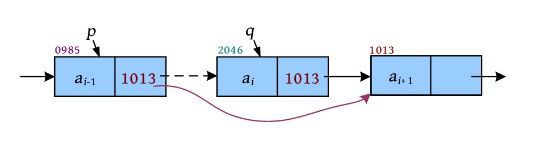
算法代码:
bool ListDelete_L(LinkList &L,int i)
{
LinkList p,q;
int j;
p=L;
j=0;
while((p->next) && (j<i-1))
{
p=p->next;
j++;
}
if(!(p->next) || (j>i-1))
{
return false;
}
}
在单链表中,每个节点除了存储自身数据,还存储下一个节点的地址,因此可以轻松访问下一个节点,以及后面的所有后继节点,但是如果想访问前面的节点就不行了,再也回不去了。例如删除节点q 时,要先找到它的前一个节点p ,然后才能删掉节点q,单链表只能向后操作,不能向前操作。如果需要向前操作,则该怎么办呢?
双向链表
在单链表中,每个元素都附加了一个指针域,指向下一个元素的存储位置。在双向链表中,每个元素都附加了两个指针域,分别指向前驱节点和后继节点。
单链表只能向后操作,不能向前操作。为了向前、向后操作方便,可以给每个元素都附加两个指针域,一个存储前一个元素的地址,一个存储下一个元素的地址。这种链表被称为双向链表,如下图所示。
从上图中可以看出,双向链表的每个节点都包含三个域:数据域和两个指针域。两个指针域分别存储前后两个元素的地址,即指向前驱节点和后继节点。
双向链表的节点结构体定义如下图所示。

(1)插入。单链表只有一个指针域,是向后操作的,不可以向前处理,因此单链表如果要在第i 个节点之前插入一个元素,则必须先找到第i -1个节点。在第i 个节点之前插入一个元素相当于把新节点放在第i -1个节点之后。而双向链表不需要,因为有两个指针,所以可以向前、后两个方向操作,直接找到第i 个节点,就可以把新节点插入第i 个节点之前。注意:这里假设第i 个节点是存在的,如果第i 个节点不存在,而第i -1个节点存在,则还是需要找到第i -1个节点,将新节点插在第i -1个节点之后,如下图所示。
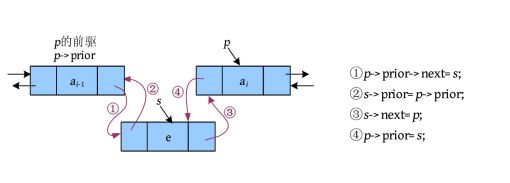
其中:
① 指将节点s 的地址赋值给p 的前驱节点的next指针域,即p 的前驱的next指针指向s ;
② 指将p 的前驱节点的地址赋值给节点s 的prior指针域,即节点s 的prior指针指向p的前驱节点;
③ 指将节点p 的地址赋值给节点s 的next指针域,即节点s 的next指针指向节点p;
④ 指将节点s 的地址赋值给节点p 的prior指针域,即节点p 的prior指针指向节点s。
因为p 的前驱节点无标记,一旦修改了节点p 的prior指针,p 的前驱节点就找不到了,因此最后修改这个指针。修改指针顺序的原则:先修改没有指针标记的那一端。
算法代码:
bool ListInsert_L(DuLinkList &L,int i,int e)
{
int j;
DuLinkList p,s;
p=L;
j=0;
while(p&&j<i)
{
p=p->next;
j++;
}
if(!p||j>i)
return false;
s = new DuLnode;
s->data=e;
p->prior->next=s;
s->prior=p->prior;
s->next=p;
s->prior=s;
return true;
}
(2)删除。删除一个节点,实际上是把这个节点跳过去。在单链表中必须先找到第i -1个节点,才能把第i 个节点跳过去。双向链表则不必如此,直接找到第i 个节点,然后修改指针即可,如下图所示。
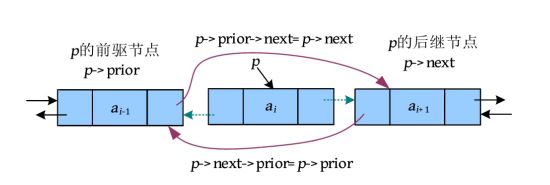
“p ->prior->next=p ->next”指将p 的后继节点的地址赋值给p 的前驱节点的next指针域。即p 的前驱节点的next指针指向p 的后继节点。注意:等号的右侧是节点的地址,等号的左侧是节点的指针域。
“p ->next->prior=p ->prior”指将p 的前驱节点的地址赋值给p 的后继节点的prior指针域。即p 的后继节点的prior指针指向p 的前驱节点。此项修改的前提是p 的后继节点是存在的,如果不存在,则不需要修改此项。
这样,就把节点p 跳过去了。然后用delete p 释放被删除节点的空间。删除节点修改指针没有顺序,先修改哪个都可以。
算法代码:
bool ListDelete_L(DuLinkList &L,int i)
{
DuLinkList p;
int j;
p=L;
j=0;
while(p&&(j<i))
{
p=p->next;
j++;
}
if(!p||(j>i))
{
return false;
}
if(p->next)
p->next->prior=p->prior;
p->prior->next=p->next;
delete p;
return true;
}
循环链表
在单链表中,只能向后操作,不能向前操作,如果从当前节点开始,则无法访问该节点前面的节点;如果最后一个节点的指针指向头节点,形成一个环,就可以从任何一个节点出发,访问所有节点,这就是循环链表。循环链表和普通链表的区别就是最后一个节点的后继指向了头节点。下面看看单链表和单向循环链表的区别。单链表如下图所示。
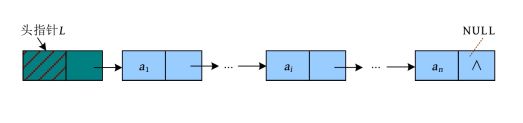
单向循环链表最后一个节点的next域不为空,而是指向了头节点,如下图所示。
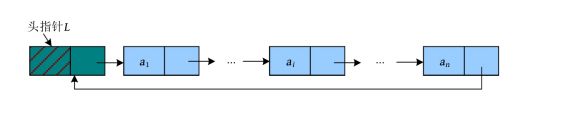
而单链表和单向循环链表判断空表的条件也发生了变化,单链表为空表时,L ->next=NULL;单向循环链表为空表时,L ->next=L ,如下图所示。

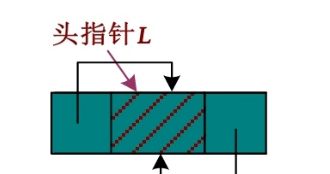
双向循环链表除了要让最后一个节点的后继指向第1个节点,还要让头节点的前驱指向最后一个节点,如下图所示。
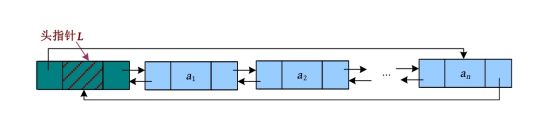
双向循环链表为空表时,L ->next=L ->prior=L ,如下图所示
链表的优点:链表是动态存储的,不需要预先分配最大空间。进行插入、删除时不需要移动元素
链表的缺点:每次都动态分配一个节点,每个节点的地址是不连续的,需要有指针域记录下一个节点的地址,指针域需要占用一个int的空间,因此存储密度低(数据所占空间/节点所占总空间)。存取元素必须从头到尾按顺序查找,属于顺序存取。
静态链表
链表还有另一种静态表示方式,可以用一个数组存储数据,用另一个数组记录当前数据的后继的下标。
例如,一个动态的单向循环链表如下图所示
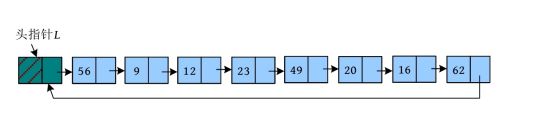
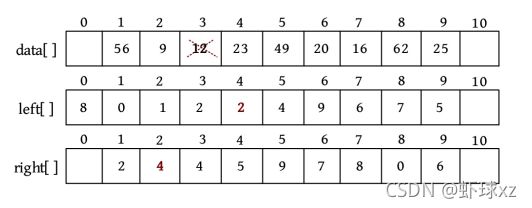
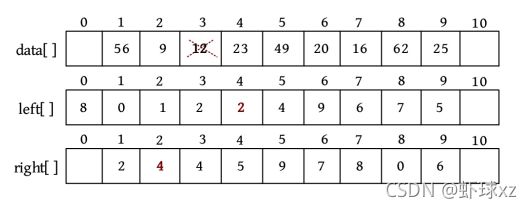
用静态链表可以先把数据存储在一维数组data[]中,然后用后继数组right[]记录每个元素的后继下标,如下图所示。
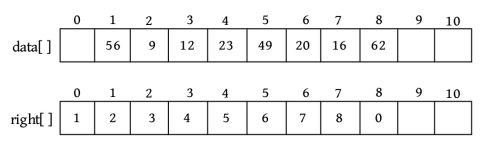
0空间没有存储数据,作为头节点。right[1]=2,代表data[1]的后继下标为2,即data[2],也就是说元素56的后继为9;right[8]=0,代表data[8]的后继为头节点。
1)插入
若在第6个元素之前插入一个元素25,则只需将25放入data[]数组的尾部,即data[9]=25,然后修改后继数组right[5]=9,right[9]=6,如下图所示。
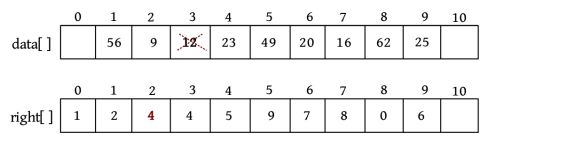
插入之后,right[5]=9,right[9]=6,也就是说节点5的后继为9,节点9的后继为6,节点6的前驱为9,节点9的后继为6。
5 − > 9 − > 6 5->9->6 5−>9−>6
相当于节点9被插入节点5和节点6之间,即插入节点6之前。也就是说,元素49的后继为25,元素25的后继为20。这就相当于把元素25插入49、20之间。是不是也很方便?不需要移动元素,只改动后继数组就可以了。
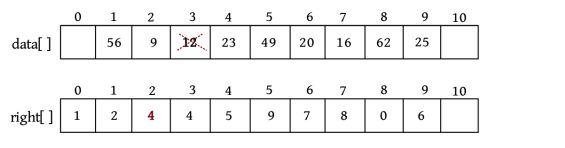
2)删除
若删除第3个元素,则只需修改后继数组right[2]=4,如下图所示。此时,2的后继为4,相当于把第3个元素跳过去了,实现了删除功能,而第3个元素并未被真正删除,只是它已不在链表中。这样做的好处是不需要移动大量的元素。
想一想:后继数组为什么不直接存储数据?
静态链表存储通常存储后继的下标,而不是直接存储数据,除非特殊需要。因为数组下标为int型数据,而数据有可能为long long类型或结构体类型,占的字节数更多。
静态的双向链表怎么表示呢?例如,一个动态的双向链表如下图所示。

可以先用静态的双链表把数据存储在一维数组data[]中,然后用前驱数组left[]记录每个元素的前驱下标,用后继数组right[]记录每个元素的后继下标。
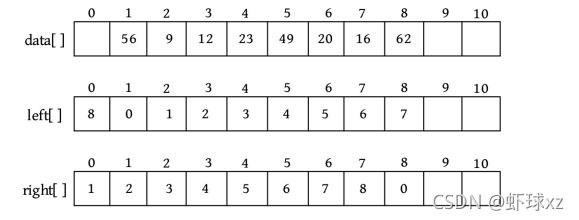
left[1]=0,代表data[1]没有前驱;right[1]=2,代表data[1]的后继下标为2,即data[2],表示元素56没有前驱,其后继为9。left[8]=7,right[8]=0,表示62的前驱为16,没有后继。
1)插入
若在第6个元素之前插入一个元素25,则只需将25放入data[]数组的尾部,即data[9]=25,然后修改前驱和后继数组,left[9]=5,right[5]=9,left[6]=9,right[9]=6,如下图所示。
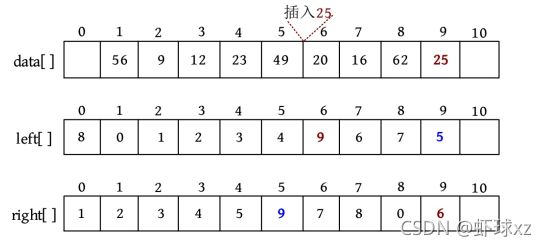
插入之后,left[9]=5,right[5]=9,left[6]=9,right[9]=6,也就是说节点5的前驱为9,节点9的后继为9,节点6的前驱为9,节点9的后继为6。
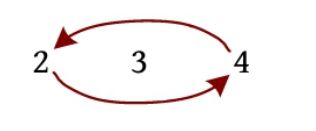
5 ⇆ 9 ⇆ 6 5 \leftrightarrows 9 \leftrightarrows 6 5⇆9⇆6
相当于节点9被插入节点5和节点6之间,即插入节点6之前。不需要移动元素,只改动前驱数组、后继数组就可以了。
2)删除
若删除第3个元素,则只需修改left[4]=2,right[2]=4,如下图所示。此时,4的前驱为2,2的后继为4,相当于跳过了第3个元素,实现了删除功能。和静态单链表一样,第3个元素并未被真正删除,只是已不在链表中。这样做的好处是不需要移动大量元素。
删除之后,left[4]=2,right[2]=4,也就是说节点2的前驱为4,节点2的后继为4,跳过了节点3。
训练1 区块世界
题目描述(UVA101): 在早期的人工智能规划和机器人研究中使用了一个区块世界,在这个世界中,机器人手臂执行涉及区块操作的任务。问题是要解析一系列命令,这些命令指导机器人手臂如何操作平板上的块。最初,有n个区块(编号为0~n −1),对于所有0≤i <n −1的情况,区块b i 与区块b i +1 相邻,如下图所示。
用于操纵块的有效命令如下。
move a onto b:把a和b上方的块全部放回初始位置,然后把a放到b上方。
move a over b:把a上方的块全部放回初始位置,然后把a放到b所在块堆的最上方。
pile a onto b:把b上方的块全部放回初始位置,然后把a和a上方所有的块整体放到b上方。
pile a over b:把a和a上方所有的块整体放到b所在块堆的最上方。
quit:结束标志。
任何a=b或a和b在同一块堆中的命令都是非法命令。所有非法命令都应被忽略。
输入: 输入的第1行为整数n (0<n <25),表示区块世界中的块数。后面是一系列块命令,每行一个命令。在遇到quit命令之前,程序应该处理所有命令。所有命令都将采用上面指定的格式,不会有语法错误的命令。
输出: 输出应该包含区块世界的最终状态。每一个区块i (0≤i <n )后面都有一个冒号。如果上面至少有一个块,则冒号后面必须跟一个空格,后面跟一个显示在该位置的块列表,每个块号与其他块号之间用空格隔开。不要在行末加空格。
题解: 初始时从左到右有n (0<n <25)个块,编号为0~n -1,要求实现一些操作。通过这些操作可以归纳总结出以下规律
move:将a上方的块全部放回初始位置。
onto:将b上方的块全部放回初始位置。
公共操作:将a和a上方所有的块整体放到b所在块堆的最上方。
而实际上,前两种可以算一个操作:将a(或b)上方的块全部放回初始位置,简称归位 。将a和a上面所有的块整体放到b所在块堆的最上方,简称移动 。
只需通过判断执行归位和移动操作就可以了。
\1. 算法设计
(1)读取操作命令s1,如果s1=“quit”,则结束;否则执行下两步;
(2)读入操作命令a s2 b,如果s2=“move”,则a归位;如果s2=“onto”,则b归位;
(3)执行移动操作,即将a和a上方所有的块整体放到b所在块堆的最上方。
那么如何执行归位和移动操作呢?
1)归位
要想使a上方的所有块归位,则首先要找到a所在的块堆,并知道a在块堆中的位置(高度),然后才能将a上方的所有块归位。
例如,块堆如下图所示,将8上方所有的块归位。首先查找到8所在的块堆为1,8所在块堆的高度为2,然后将1号块堆高度大于2的所有块放回原来的位置。
算法代码:
void goback(int p,int h) //将p 块堆高度大于 h 的所有块归位
{
for(int i = h+1;i<block[p].size();i++)
{
int k = block[p][i];
block[k].push_back(k);
}
block[p].resize(h+1);
}
2)移动
要想将a和a上方所有的块整体放到b所在块堆的最上方,则首先要找到a和b所在的块堆,如果a、b所在的块堆一样,则什么都不做。否则,将a块堆中高度大于或等于h (a的高度)的所有块移动到b所在块堆的上方。
例如,块堆如下图所示,将8和8上方所有的块整体放到9所在块堆的最上方。首先查找到8所在的块堆为5号,9所在的块堆为1号,8所在块堆的高度为1,然后将5号块堆高度大于或等于1的所有块放到1号块堆的上方,如下图所示。
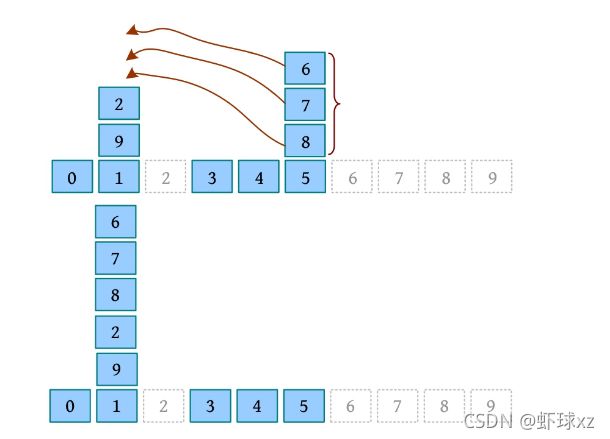
算法代码:
void moveall(int p,int h,int q) //将p 块堆高度大于或等于 h 的所有块都移动到 q 块堆的上方
{
for(int i = h;i<block[p].size();i++)
{
int k = block[p][i];
block[q].push_back(k);
}
block[p].resize(h);
}
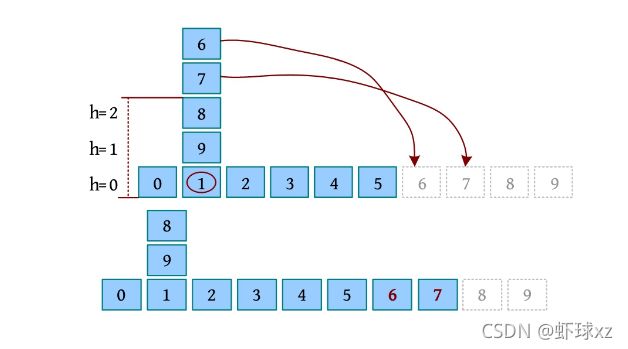
\2. 完美图解
以输入样例为例,有10个块,初始时各就其位,如下图所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pGdAHwLY-1631003942454)(/home/xz/图片/选区_492.png)]
(1)move 9 onto 1:将9和1上方的块全部放回初始位置,然后把9放到1的上方。
(2)move 8 over 1:将8上方的块全部放回初始位置,然后把8放到1的上方。
(3)move 7 over 1:将7上方的块全部放回初始位置,然后把7放到1的上方。move 6 over 1:将6上方的块全部放回初始位置,然后把6放到1的上方。
(4)pile 8 over 6:将8和8上方所有的块整体放到6所在块堆的最上方;此时8和6在同一块堆中,什么也不做。
(5)pile 8 over 5:将8和8上方所有的块整体放到5所在块堆的最上方,即将8、7、6一起放到5所在块堆的上方。
(6)move 2 over 1:将2上方的块全部放回初始位置,将2放到1所在块堆的最上方。
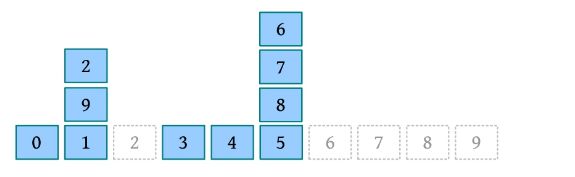
(7)move 4 over 9:将4上方的块全部放回初始位置,将4放到9所在块堆的最上方。
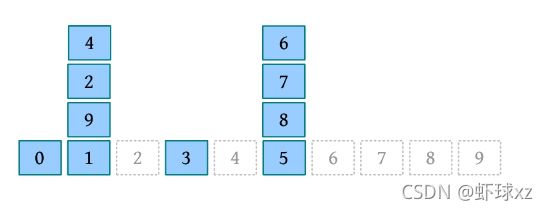
(8)quit:结束。
(9)从左到右、从下到上输出每个位置的块编号。
\3. 算法实现
因为每一个块堆的长度都发生了变化,因此可以使用变长数组vector,即对每个块堆都用一个vector存储。块堆的个数为n (0<n <25),定义一个长度比25稍大的vector数组即可。
#include 训练2 悲剧文本
题目描述(UVA11988): 假设你在用坏键盘键入一个长文本。键盘的唯一问题是有时Home键或End键会自动按下(内部)。你没有意识到这个问题,因为你只关注文本,甚至没有打开显示器!输入完毕后,你才发现屏幕上显示的是一段悲剧文本。你的任务是找到悲剧文本。
输入: 有几个测试用例。每个测试用例各占一行,包含至少一个且最多100 000个字母、下画线和两个特殊字符“[”和“]”。“[”表示内部按了Home键,“]”表示内部按下了End键。输入由文件结尾(EOF)终止。
输出: 对于每种情况,都在屏幕上输出悲剧文本。
题解 :本题涉及大量移动元素,因此使用链表比较合适。但是将盒子X 移动到盒子Y 的左侧,还需要查找盒子X和盒子Y 在链表中的位置,查找是链表不擅长的,每次查找的时间复杂度都为O (n ),而链表的长度最多为100 000,多次查找会超时,所以不能使用list链表实现。这里可以使用既具有链表特性又具有快速查找能力的静态链表实现,因为在题目中既有向前操作,也有向后操作,因此选择静态双向链表。另外,有大量元素的链表,其翻转操作的时间复杂度很高,会超时,此时只需做标记即可,不需要真的翻转。
\1. 算法设计
(1)定义一个字符类型的list,链表名为text。
(2)定义一个迭代器it,指向链表的开头。
(3)检查字符串,如果遇到“[”,则指向链表的开头,即it=text.begin();如果遇到“]”,则指向链表的尾部,即it=text.end()。
(4)如果是正常文本,则执行插入操作。
\2. 算法实现
#include xz@xiaqiu:~/study/algorithm/suanfaxunlian/study$ ./a.out
this_isa_[Beiju]_text
Beijuthis_isa__text
[][[]]Happy_birthday
Happy_birthday
goodle[][][[ddd]]
dddgoodle
[]dsd[dsd[dsds[xiao]]]
xiaodsdsdsddsd
[]dsds[[1][2][[3]]
321dsds
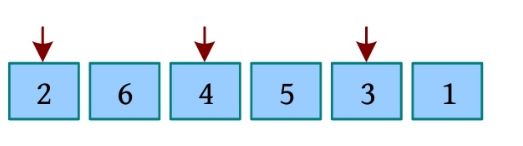
训练3 移动盒子
题目描述(UVA12657): 一行有n 个盒子,从左到右编号为1~n 。模拟以下4种命令。
1 X Y :将盒子X 移动到Y 的左侧(如果X 已经在Y 的左侧,则忽略此项)。
2 X Y :将盒子X 移动到Y 的右侧(如果X 已经在Y 的右侧,则忽略此项)。
3 X Y :交换盒子X 和Y 的位置。
4:翻转整行盒子序列。
以上命令保证有效,即X 不等于Y 。举例说明:有6个盒子,执行1 1 4,即1移动到4的左侧,变成2 3 1 4 5 6。然后执行2 3 5,即3移动到5的右侧,变成2 1 4 5 3 6。接着执行3 1 6,即交换1和6的位置,变成2 6 4 5 3 1。最后执行4,即翻转整行序列,变成1 3 5 4 6 2。
输入: 最多有10个测试用例。每个测试用例的第1行都包含两个整数n 和m (1≤n , m ≤100 000),下面的m行,每行都包含一个命令。
输出: 对于每个测试用例,都单行输出奇数索引位置的数字总和。
题解 :本题涉及大量移动元素,因此使用链表比较合适。但是将盒子X 移动到盒子Y 的左侧,还需要查找盒子X和盒子Y 在链表中的位置,查找是链表不擅长的,每次查找的时间复杂度都为O (n ),而链表的长度最多为100 000,多次查找会超时,所以不能使用list链表实现。这里可以使用既具有链表特性又具有快速查找能力的静态链表实现,因为在题目中既有向前操作,也有向后操作,因此选择静态双向链表。另外,有大量元素的链表,其翻转操作的时间复杂度很高,会超时,此时只需做标记即可,不需要真的翻转。
\1. 算法设计
(1)初始化双向静态链表(前驱数组为l [],后继数组为r []),翻转标记flag=false。
(2)读入操作指令a 。
(3)如果a =4,则标记翻转,flag=!flag,否则读入x 、y 。
(4)如果a !=3&&flag,则a =3-a 。因为如果翻转标记为真,则左右是倒置的,1、2指令正好相反,即1号指令(将x 移到y 左侧)相当于2号指令(将x 移到y 右侧)。因此如果a =1,则转换为2;如果a =2,则转换为1。
(5)对于1、2指令,如果本来位置就是对的,则什么都不做。
(6)如果a =1,则删除x ,将x 插入y 左侧。
(7)如果a =2,则删除x ,将x 插入y 右侧。
(8)如果a =3,则考虑相邻和不相邻两种情况进行处理。
算法中的基本操作如下。
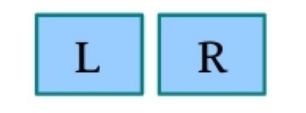
(1)链接。例如,将L和R链接起来,则L的后继为R,R的前驱为L,如下图所示。
void link(int L,int R)//将L和R 链接起来
{
r[L] = R;
l[R] = L;
}
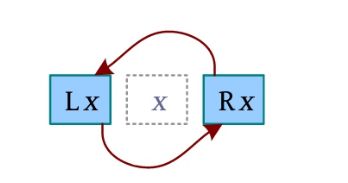
2)删除。删除x 时,只需将x 跳过去,即将x 的前驱和后继链接起来即可。
link(Lx,Rx);//删除x
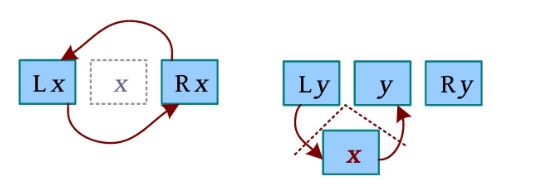
(3)插入(将x 插入y 左侧)。将x 插入y 左侧时,先删除x ,然后将x 插入y 左侧,删除操作需要1次链接,插入左侧操作需要两次链接,如下图所示。
link(Lx,Rx);//删除x
link(Lx,x);//Ly 和 x 链接
link(x,y);//x 和y 链接
(4)插入(将x 插入y 右侧)。将x 插入y 右侧时,先删除x ,然后将x 插入y 右侧,删除操作需要1次链接,插入右侧操作需要两次链接,如下图所示。
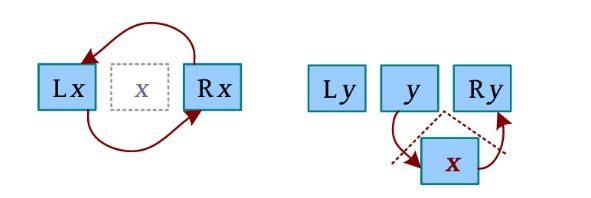
link(Lx,Rx); //删除*x*
link(y,x);//将y和x链接
link(x,Ry);//将x和Ry 链接
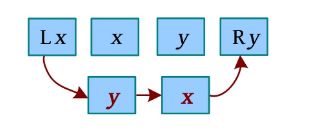
(5)交换(相邻)。将x 与y 交换位置,如果x 和y 相邻且x 在y 右侧,则先交换x 、y ,统一为x 在y 左侧处理。相邻情况的交换操作需要3次链接,如下图所示。
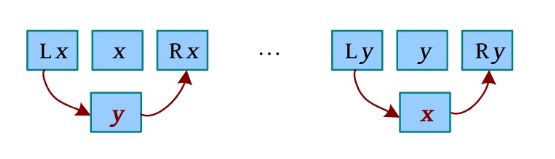
(6)交换(不相邻)。将x 与y 交换位置,如果x 和y 不相邻,则交换操作需要4次链接,如下图所示。
link(Lx,y);//LX 和y链接
link(y,Rx);//y和Rx 链接
link(Ly,x);//Ly和x链接
link(x,Ry);//x 和Ry 链接
(7)翻转。如果标记了翻转,且长度n 为奇数,则正向奇数位之和与反向奇数位之和是一样的。
如果标记了翻转,且长度n 为偶数,则反向奇数位之和等于所有元素之和减去正向奇数位之和。
因此只需统计正向奇数位之和,再判断翻转标记和长度是否为偶数即可。
\2. 完美图解
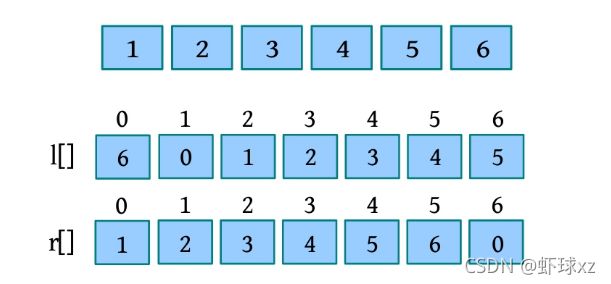
(1)以输入样例为例,n =6,初始化前驱数组和后继数组,如下图所示。
(2)1 1 4:执行1号指令(将1移到4左侧),先删除1,然后将1插入4左侧。删除操作需要1次链接,插入需要两次链接,如下图所示。
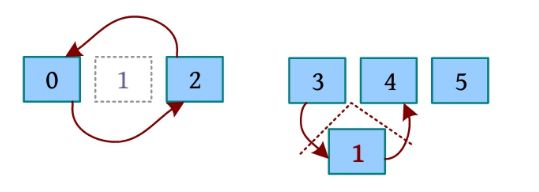
即修改2的前驱为0,0的后继为2;1的前驱为1,3的后继为1;4的前驱为1,1的后继为4,如下图所示。
(3)2 3 5:执行2号指令(将3移到5右侧),先删除3,然后将3插入5右侧。删除操作需要1次链接,插入需要两次链接,如下图所示。
即修改1的前驱为2,2的后继为1;3的前驱为5,5的后继为3;6的前驱为3,3的后继为6,如下图所示。
(4)3 1 6:执行交换(不相邻)指令,1和6不相邻,交换操作需要4次链接。
即修改4个链接:6的前驱为2,2的后继为6;4的前驱为6,6的后继为4;1的前驱为3,3的后继为1;0的前驱为1,1的后继为0。
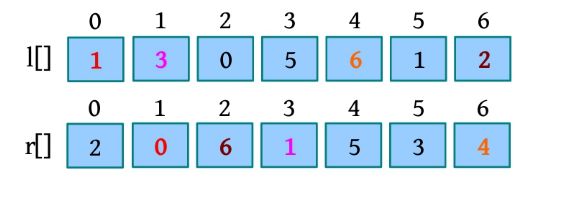
(5)4:执行翻转指令,标记翻转flag=true。
(6)如果n 为偶数且翻转为真,则反向奇数位之和等于所有数之和减去正向奇数位之和。
反向奇数位之和=所有数之和-正向奇数位之和=6×(6+1)/2-(2+4+3)=12。
\3. 算法实现
#include栈和队列的应用
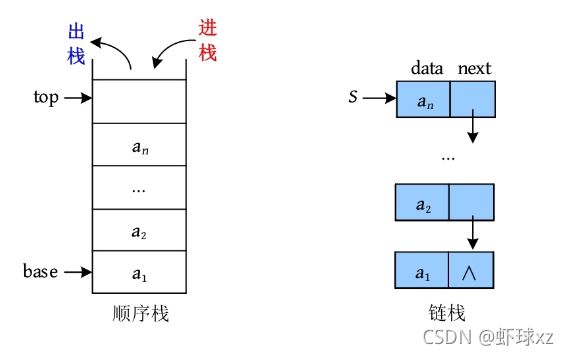
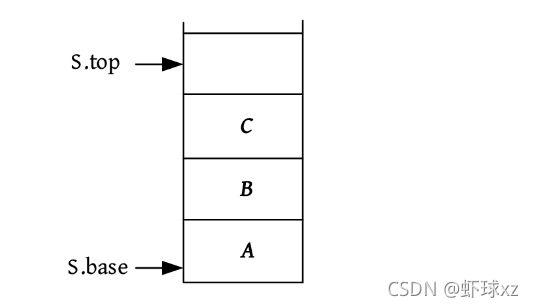
后进先出(Last In First Out,LIFO)的线性序列被称为“栈”。栈也是一种线性表,只不过是操作受限的线性表,只能在一端进行进出操作。进出的一端被称为栈顶,另一端被称为栈底。栈可以采用顺序存储,也可以采用链式存储,分别被称为顺序栈和链栈。
顺序栈
栈的顺序存储方式如下图所示
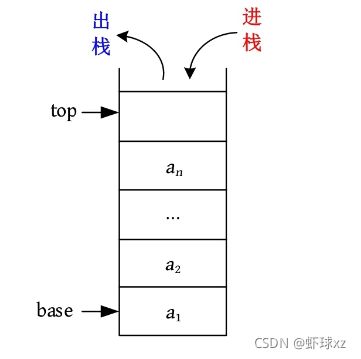
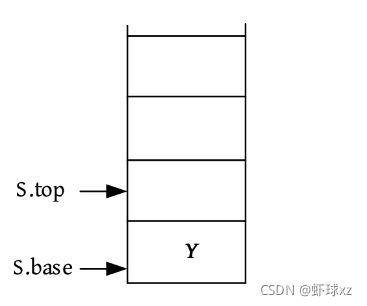
顺序栈需要两个指针,base指向栈底,top指向栈顶。顺序栈的数据结构定义(动态分配)如下图所示。

在栈定义好了之后,还要先定义一个最大的分配空间,顺序结构都是如此,需要预先分配空间,因此可以采用宏定义或常量。
#define Maxsize 100//预先分配空间,根据实际需要预估确定
const int Maxsize = 100;
上面的结构体定义采用了动态分配形式,也可以采用静态分配形式,使用一个定长数组存储数据元素,使用一个整型下标记录栈顶元素的位置。顺序栈的数据结构定义(静态分配)如下图所示。
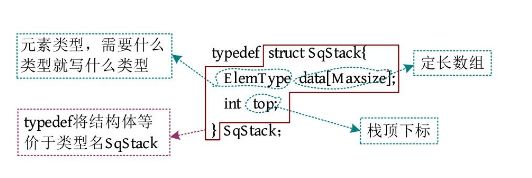
注意:栈只能在一端操作,后进先出的特性是人为规定的,也就是说不允许在中间进行查找、取值、插入、删除等操作,但顺序栈本身是按顺序存储的,确实能够从中间取出一个元素,但这样就不是栈了。
顺序栈的基本操作包括初始化、入栈、出栈和取栈顶元素等。这里以动态分配空间及int类型的元素为例进行讲解。
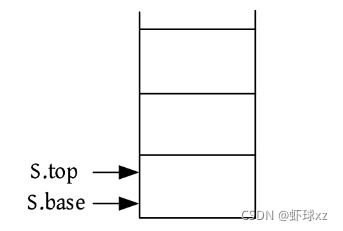
(1)初始化。初始化一个空栈,动态分配Maxsize大小的空间,S .top和S .base指向该空间的基地址。
算法代码:
bool InitStack(SqStack &S) //构造一个空栈 S
{
S.base = new int[Maxsize];//为顺序栈分配一个最大容量为 Maxsize 的空间
if(!S.base)//空间分配失败
return false;
S.top = S.base;//top 初始为基地址 base,当前为空栈
return true;
}
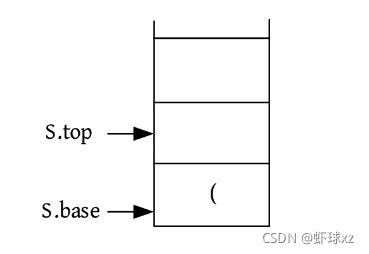
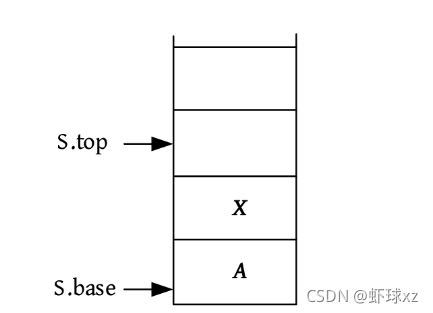
(2)入栈。入栈前要判断栈是否已满,如果栈已满,则入栈失败;否则将元素放入栈顶,栈顶指针向上移动一个位置(top++)。依次输入1、2,入栈,如下图所示。
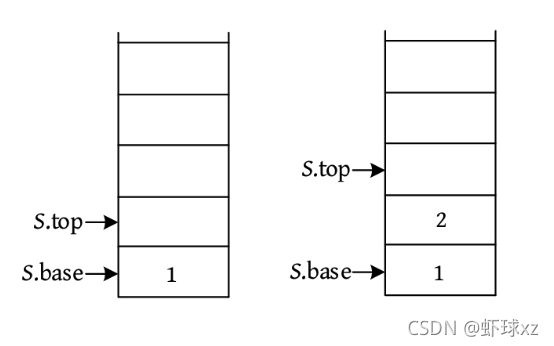
算法代码:
bool Push(SqlStack &S,int e)// 插入元素e为新的栈顶元素
{
if(S.top - S.base == Maxsize)栈满
return false;
*(S.top++)=e;//元素e压入栈顶,然后栈顶指针加1,等价于*S.top=e; S.top++;
return true;
}
(3)出栈。出栈前要判断栈是否已空,如果栈已空,则出栈失败;否则将栈顶元素暂存到一个变量中,栈顶指针向下移动一个空间(top–)。栈顶元素所在的位置实际上是S .top-1,因此把该元素取出来,暂存在变量e 中,然后S .top指针向下移动一个位置。因此可以先移动一个位置,即–S .top,然后取元素。例如,栈顶元素4出栈前后的状态如下图所示。
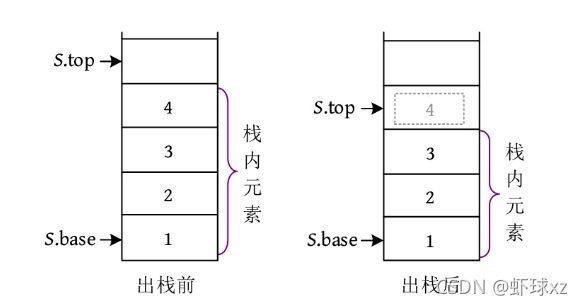
注意: 因为按顺序存储方式删除一个元素时,并没有销毁该空间,所以4其实还在那个位置,只不过下次再有元素进栈时,就把它覆盖了。相当于该元素已出栈,因为栈的内容是S .base到S .top-1。
算法代码 :
bool Pop(SqStack &S, int &e) //删除S的栈顶元素,暂存在变量e中
{
if (S.base == S.top) //栈空
return false;
e = *(--S.top); //栈顶指针减1,将栈顶元素赋给e
return true;
}
(4)取栈顶元素。取栈顶元素和出栈不同,取栈顶元素时只是把栈顶元素复制一份,栈顶指针未移动,栈内元素的个数未变。而出栈指栈顶指针向下移动一个位置,栈内不再包含这个元素。
例如,取栈顶元素*(S .top-1),即元素4,取值后S .top指针没有改变,栈内元素的个数也没有改变。
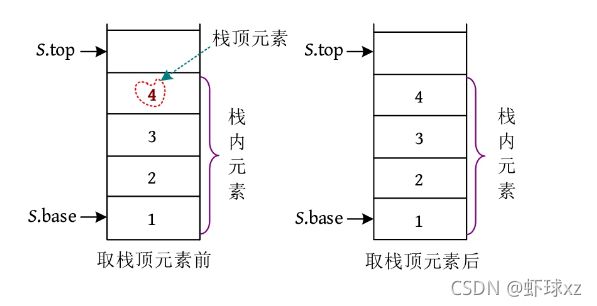
算法代码 :
int GetTop(SqlStack S) //返回S的栈顶元素,栈顶指针不变
{
if(S.top!=S.base) //栈非空
return *(S.top - 1);//返回栈顶元素的值,栈顶指针不变
else
return -1;
}
链栈
栈可以采用顺序存储(顺序栈),也可以采用链式存储(链栈)。顺序栈和链栈如下图所示。
顺序栈是分配一段连续的空间,需要两个指针,base指向栈底,top指向栈顶。而链栈每个节点的地址都是不连续的,只需一个栈顶指针即可。链栈的节点和单链表节点一样,包含两个域:数据域和指针域。可以把链栈看作一个不带头节点的单链表,但只能在头部进行插入、删除、取值等操作,不可以在中间和尾部操作。
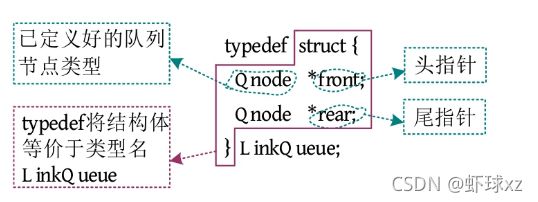
链栈的数据结构定义如下图所示。
链栈的节点定义和单链表一样,只不过它只能在栈顶那一端操作。链栈的基本操作包括初始化、入栈、出栈、取栈顶元素等(以int类型为例)。
(1)初始化。初始化一个空栈,链栈是不需要头节点的,因此只需让栈顶指针为空即可。
算法代码:
bool InitStack(LinkStack &S)
{
S = NULL;
return true;
}
(2)入栈。入栈指将新节点压入栈顶,因为链栈中的第1个节点为栈顶,因此将新节点插入第1个节点的前面,然后修改栈顶指针指向新节点即可。这有点像摞盘子,将新节点摞到栈顶之上,新节点成为新的栈顶。
完美图解:
首先,生成新节点。入栈前要创建一个新节点,将元素e 存入该节点的数据域,如下图所示。
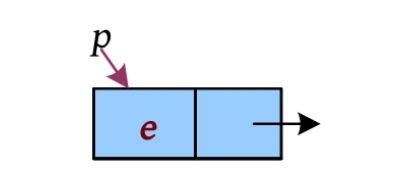
p=new Snode;//生成新节点,用 p 指针指向该节点
p->data = e;//将元素 e 放在新节点数据域
然后,将新节点插入第1个节点的前面,修改栈顶指针指向新节点,如下图所示。
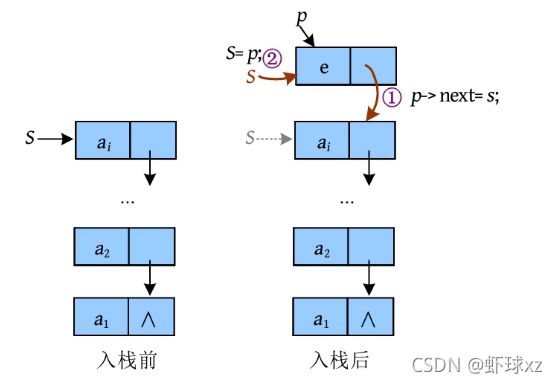
“p ->next=S ”指将S 的地址赋值给p 的指针域,即新节点p 的next指针指向S ;“S =p ”指修改新的栈顶指针为p 。
算法代码:
bool Push(LinkStack &S, int e) //入栈,在栈顶搬入元素e
{
LinkStack p;
p=new Snode;//生成新节点
p->data = e;//将e 存入新节点的数据域中
p->next = S;//将新节点P 的 next 指针指向 S,即将 s 的地址赋值给新节点的指针域
S=p;//修改新栈顶指针为
return true;
}
3)出栈。出栈指将栈顶元素删除,栈顶指针指向下一个节点,然后释放该节点空间。
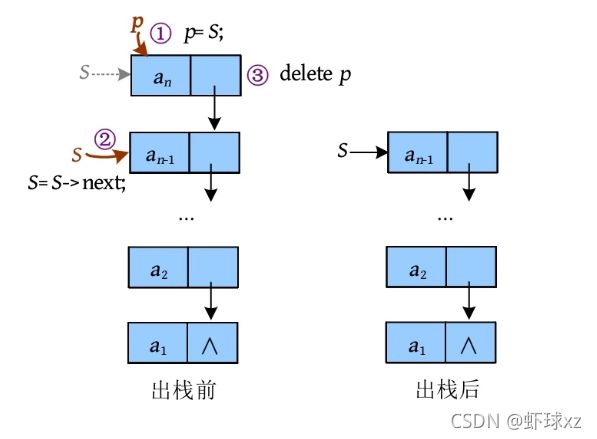
其中,“p =S ”指将S 的地址赋值给p ,即p 指向栈顶元素节点;“S =S ->next”指将S 的后继节点的地址赋值给S ,即S 指向它的后继节点;“delete p ”指最后释放p 指向的节点空间。
算法代码:
bool Pop(LinkStack &S,int &e) //出栈,删除 s 的栈顶元素,用 e 保存其值
{
LinkStack p;
if(S == NULL) //栈空
return false;
e = S->data;//用e 暂存栈顶元素数据
p=S;//用 保存栈顶元素地址,以备释放
S=S->next;//修改栈顶指针,指向下一个节点
delete p; //释放原栈顶元素的空间
return true;
}
(4)取栈顶元素。取栈顶元素和出栈不同,取栈顶元素只是把栈顶元素复制一份,栈顶指针并没有改变,如下图所示。而出栈指删除栈顶元素,栈顶指针指向下一个元素。
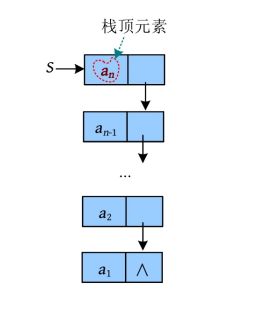
算法代码:
int GetTop(LinkStack S) //取栈顶元素,不修改栈项指针
{
if(S!=NULL)//栈非空
return S->data;//返回栈顶元素的值,栈项指针不变
else
return -1;
}
顺序栈和链栈的所有基本操作都只需常数时间,所以在时间效率上难分伯仲。在空间效率方面,顺序栈需要预先分配固定长度的空间,有可能造成空间浪费或溢出;链栈每次都只分配一个节点,除非没有内存,否则不会溢出,但是每个节点都需要一个指针域,结构性开销增加。因此,如果元素个数变化较大,则可以采用链栈,否则可以采用顺序栈。在实际应用中,顺序栈比链栈应用得更广泛。
顺序队列
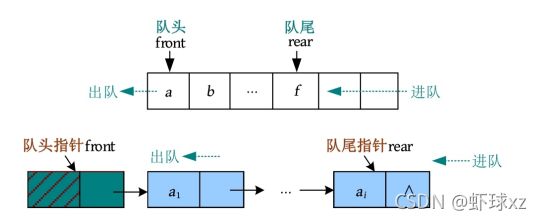
在只有一个车道的单行道上,小汽车呈线性排列,只能从一端进,从另一端出,先进先出(First In First Out,FIFO)
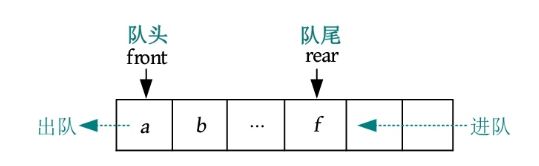
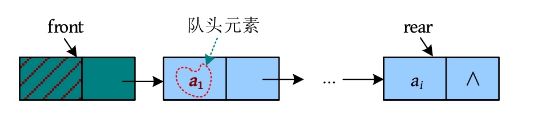
这种先进先出的线性序列,被称为“队列”。队列也是一种线性表,只不过它是操作受限的线性表,只能在两端操作:从一端进,从另一端出。进的一端被称为队尾(rear),出的一端被称为队头(front)。队列可以采用顺序存储,也可以采用链式存储。
\1. 顺序队列
队列的顺序存储指用一段连续的空间存储数据元素,用两个整型变量记录队头和队尾元素的下标。采用顺序存储方式的队列如下图所示。
顺序队列的数据结构定义(动态分配)如下图所示。
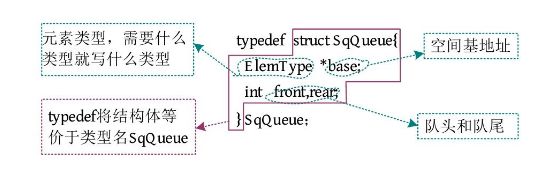
在顺序队列定义好了之后,还要先定义一个最大的分配空间,顺序结构都是如此,需要预先分配空间,因此可以采用宏定义:
#define Maxsize 100 //预先分配空间,这个数值根据实际需要预估并确定
上面的结构体定义采用了动态分配形式,也可以采用静态分配形式,使用一个定长数组存储数据元素,用两个整型变量记录队头和队尾元素的下标。顺序队列的数据结构定义(静态分配)如下图所示。
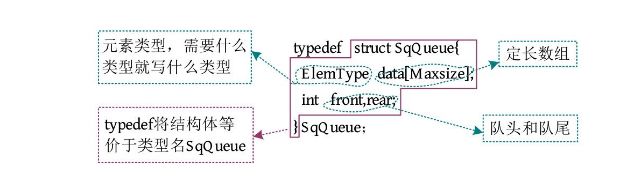
注意: 队列只能从一端进,从另一端出,不允许在中间进行查找、取值、插入、删除等操作,先进先出是人为规定的,如果破坏了此规则,就不是队列了。
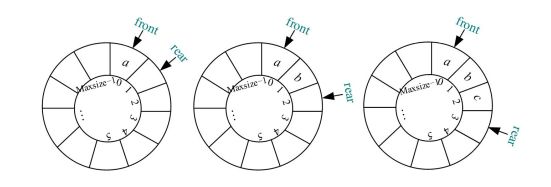
完美图解 :
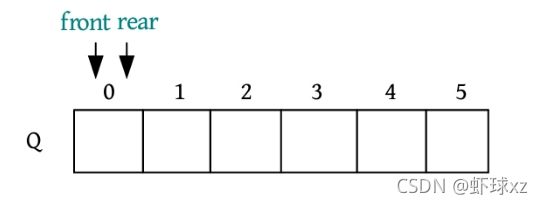
假设现在顺序队列Q分配了6个空间,然后进行入队和出队操作(Q.front和Q.rear都是整型下标)。
(1)开始时为空队,Q.front=Q.rear。
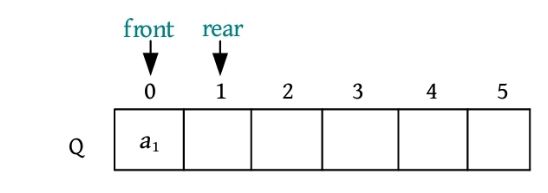
(2)元素a 1 进队,放入队尾Q.rear的位置,Q.rear后移一位。
(3)元素a 2 进队,放入队尾Q.rear的位置,Q.rear后移一位。
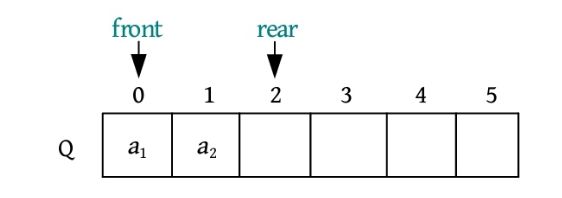
(4)元素a 3 、a 4 、a 5 分别按顺序进队,队尾Q.rear依次后移。
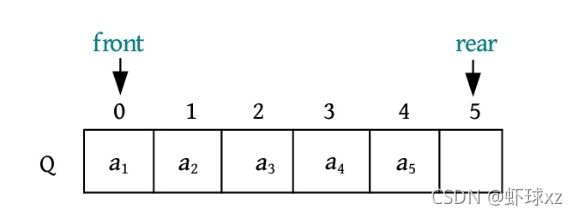
(5)元素a 1 出队,队头Q.front后移一位。
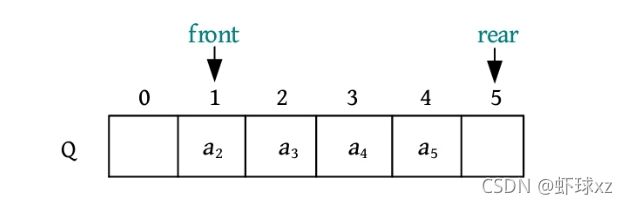
(6)元素a 2 出队,队头Q.front后移一位。
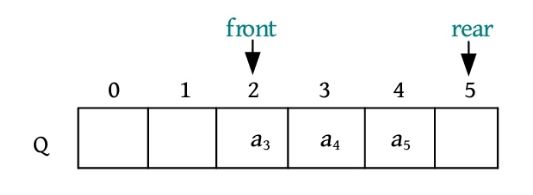
(7)元素a 6 进队,放入队尾Q.rear的位置,Q.rear后移一位。
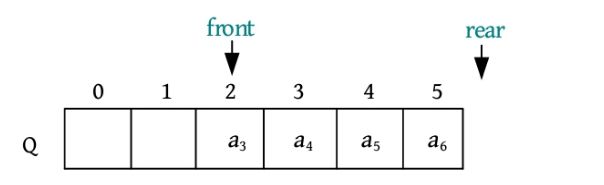
(8)元素a 7 进队,此时队尾Q.rear已经超过了数组的最大下标,无法再进队,但是前面明明有两个空间,却出现了队满的情况,这种情况被称为“假溢出”。如何解决该问题呢?能否利用前面的空间继续入队呢?
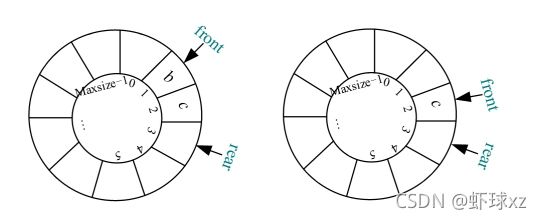
进行步骤7后,队尾Q.rear要后移一个位置,此时已经超过了数组的最大下标,即Q.rear+1=Maxsize(最大空间数6),那么如果前面有空闲,Q.rear就可以转向前面下标为0的位置,如下图所示。
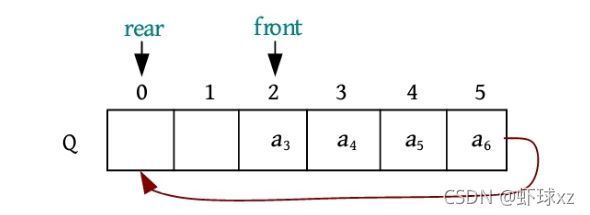
元素a 7 进队,被放入队尾Q.rear的位置,然后Q.rear后移一位,如下图所示。
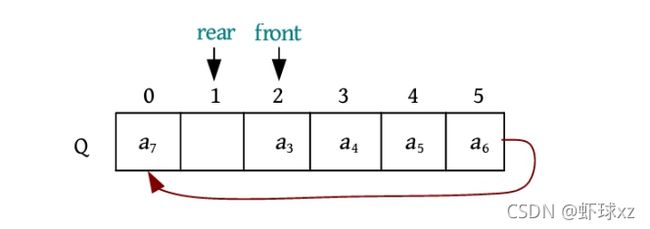
元素a 8 进队,被放入队尾Q.rear的位置,然后Q.rear后移一位,如下图所示。
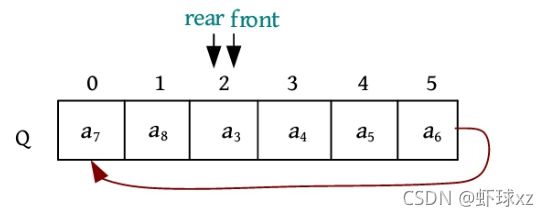
这时,虽然队列空间已存满,但是出现了一个大问题:当队满时,Q.front=Q.rear,这和队空的条件一模一样,无法区分到底是队空还是队满。如何解决呢?有两种办法:一种办法是设置一个标志,标记队空和队满;另一种办法是浪费一个空间,当队尾Q.rear的下一个位置是Q.front时,就认为队满,如下图所示。
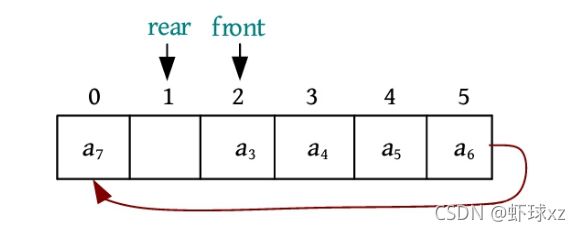
上述到达尾部又向前存储的队列被称为循环队列,为了避免“假溢出”,顺序队列通常采用循环队列。
\2. 循环队列
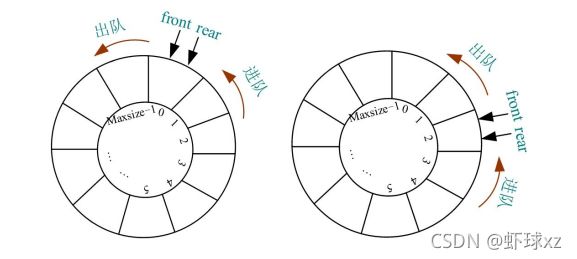
这里简单讲解循环队列队空、队满的判定条件,以及入队、出队、队列元素个数计算等基本操作方法。
1)队空
无论队头和队尾在什么位置,只要Q.rear和Q.front指向同一个位置,就认为队空。如果将循环队列中的一维数组画成环形图,则队空的情况如下图所示。
循环队列队空的判定条件为Q.front==Q.rear。
2)队满
在此采用浪费一个空间的方法,当队尾Q.rear的下一个位置是Q.front时,就认为队满。但是Q.rear向后移动一个位置(Q.rear+1)后,很可能超出了数组的最大下标,这时它的下一个位置应该为0,队满(临界状态)的情况如下图所示。其中,队列的最大空间为Maxsize,当Q.rear=Maxsize-1时,Q.rear+1=Maxsize。而根据循环队列的规则,Q.rear的下一个位置为0才对,怎么才能变为0呢?可以考虑取余运算,即(Q.rear+1)%Maxsize=0,而此时Q.front=0,即(Q.rear+1)%Maxsize=Q.front,为队满的临界状态。
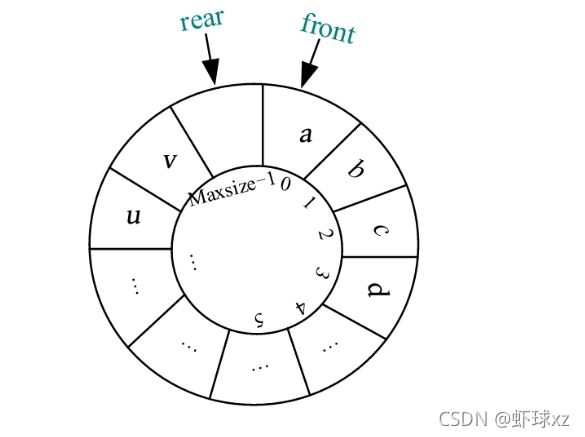
对于队满的一般状态是否也适用此方法呢?例如,循环队列队满(一般状态)的情况如下图所示。其中,假如最大空间数Maxsize=100,当Q.rear=1时,Q.rear+1=2。取余后,(Q.rear+1)%Maxsize=2, 而此时Q.front=2,即(Q.rear+1)%Maxsize=Q.front。对一般状态也可以采用此公式判断是否队满,因为一个不大于Maxsize的数,与Maxsize取余运算,结果仍然是该数本身,所以在一般状态下,取余运算没有任何影响。只有在临界状态下(Q.rear+1=Maxsize),取余运算(Q.rear+1)%Maxsize才会变为0。
因此,循环队列队满的判定条件为(Q.rear+1)%Maxsize==Q.front。
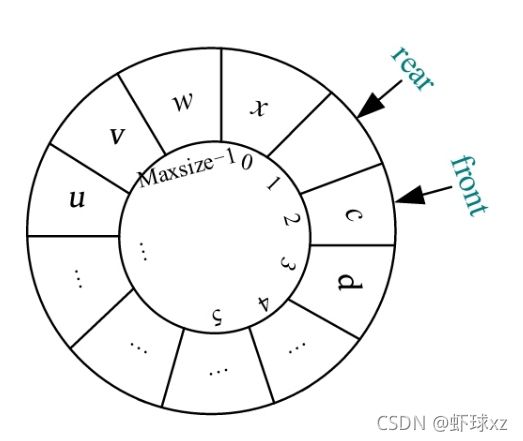
3)入队
入队时,首先将元素x 放入Q.rear所指的空间,然后Q.rear后移一位。例如,a 、b 、c 依次入队的过程如下图所示。
对于入队操作,当Q.rear后移一位时,为了处理临界状态(Q.rear+1=Maxsize),需要加1后进行取余运算。
Q.base[Q.rear] = x;//将元素x放入Q.rear 所指的空间
Q.rear = (Q.rear + 1)%Maxsize;//Q.rear后移一位
4)出队
先用变量保存队头元素,然后队头Q.front后移一位。例如,a 、b 依次出队的过程如下图所示。
对于出队操作,当Q.front后移一位时,为了处理临界状态(Q.front+1=Maxsize),需要在加1后进行取余运算。
e=Q.base[Q.front];//用变量记录@.front 所指元素,
Q.front=[Q.front+1]%Maxsize;//Q.front 后移一位
注意: 对循环队列无论是入队还是出队,在队尾、队头加1后都要进行取余运算, 主要是为了处理临界状态。
5)队列元素个数计算
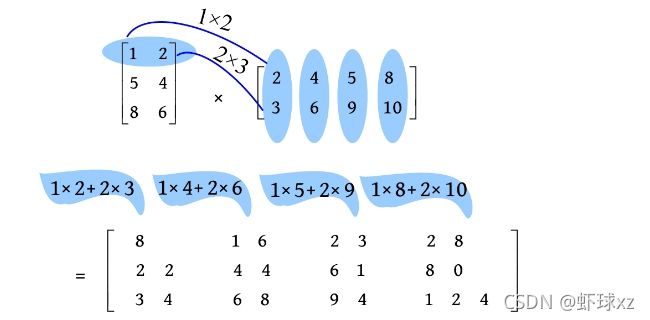
在循环队列中到底存了多少个元素呢?循环队列中的内容实际上是从Q.front到Q.rear-1这一区间的数据元素,但是不可以直接用两个下标相减得到。因为队列是循环的,所以存在两种情况:Q.rear≥Q.front,如下图(a)所示;Q.rear 在上图(b)中,Q.rear=4,Q.front=Maxsize-2,Q.rear-Q.front=6-Maxsize。但是可以看到循环队列中的元素实际上为6个,那怎么办呢?当两者之差为负数时,可以将差值加上Maxsize计算元素个数,即Q.rear-Q.front+Maxsize=6-Maxsize+Maxsize=6,元素个数为6。 在计算元素个数时,可以分两种情况进行判断:①Q.rear≥Q.front,元素个数为Q.rear-Q.front;②Q.rear 队列中元素个数的计算公式是否正确呢? 假如Maxsize=100,则在上图(a)中,Q.rear=4,Q.front=1,Q.rear-Q.front=3,(3+100)%100=3,元素个数为3;在上图(b)中,Q.rear=4,Q.front=98,Q.rear-Q.front=-94,(-94+100)%100=6,元素个数为6。所以计算公式正确。 当Q.rear-Q.front为正数时,加上Maxsize后超过了最大空间数,取余后正好是元素个数;当Q.rear-Q.front为负数时,加上Maxsize后正好是元素个数,因为元素个数小于Maxsize,所以取余运算对其无影响。 因此,%Maxsize用于防止出现Q.rear-Q.front为正数的情况,+Maxsize用于防止出现Q.rear-Q.front为负数的情况,如下图所示。 总结如下。 队空: 队满: 入队: 出队: 队列中的元素个数: \3. 循环队列的基本操作 循环队列的基本操作包括初始化、入队、出队、取队头元素、求队列长度。 (1)初始化。初始化时,首先分配一个大小为Maxsize的空间,然后令Q.front=Q.rear=0,即队头和队尾为0,队列为空。 算法代码: (2)入队。入队时,判断队列是否已满,如果已满,则入队失败;如果未满,则将新元素插入队尾,队尾后移一位。 算法代码: (3)出队。出队时,判断队列是否为空,如果队列为空,则出队失败;如果队列不为空,则用变量保存队头元素,队头后移一位。 算法代码: (4)取队头元素。取队头元素时,只是把队头元素数据复制一份,并未改变队头的位置,因此队列中的内容没有改变,如下图所示。 算法代码: 5)求队列长度。通过前面的分析,我们已经知道循环队列中的元素个数为(Q.rear- Q.front+Maxsize)% Maxsize,循环队列中的元素个数为循环队列的长度。 算法代码 : 队列除了可以采用顺序存储(顺序队列),也可以采用链式存储(链队列)。顺序队列和链队列如下图所示。 顺序队列指分配一段连续的空间,用两个整型下标front和rear分别指向队头和队尾。而链队列类似于一个单链表,需要用两个指针front和rear分别指向队头和队尾。为了在出队时删除元素方便,可以增加一个头节点。因为链队列是单链表形式,因此可以借助单链表的定义。链队列中节点的结构体定义如下图所示。 链队列的结构体定义如下图所示。 对链队列的操作和单链表一样,只不过它只能在队头删除,在队尾插入,是操作受限的单链表。对链队列的基本操作包括初始化、入队、出队和取队头元素等。 1)初始化 进行链队列的初始化,创建一个头节点,使头指针和尾指针指向头节点,如下图所示。 算法代码: 2)入队 先创建一个新节点,将元素e 存入该节点的数值域,如下图所示。 然后将新节点插入队尾,使尾指针后移,如下图所示。 其中:①“Q.rear->next=s ”指把s 节点的地址赋值给队列尾节点的next域,即尾节点的next指针指向s ;②“Q.rear=s ”指把s 节点的地址赋值给尾指针,即尾指针指向s ,尾指针永远指向队尾。 算法代码: 3)出队 出队相当于删除第1个数据元素,即将第1个数据元素节点跳过去,首先用p 指针指向第1个数据节点,然后跳过该节点,即Q.front->next=p ->next,如下图所示。 若在队列中只有一个元素,则在删除后需要修改队尾指针,如下图所示。 算法代码 : 4)取队头元素 队头实际上是Q.front->next指向的节点,即第1个数据节点,队头元素就是该节点的数据域存储的数据元素,如下图所示。 算法代码: 题目描述(P1739): 假设一个表达式由英文字母(小写)、运算符(+、-、*、/)和左右小圆括号构成,以“@”作为表达式的结束符(表达式的长度小于255,左圆括号少于20个)。请编写一个程序检查表达式中的左右圆括号是否匹配,若匹配,则返回“YES”,否则返回“NO”。 输入: 每个测试用例都对应一行表达式。 输出: 对每个测试用例都单行输出“YES” 或“NO”。 题解: 本题比较简单,只有左右小圆括号,可以将左圆括号入栈,遇到右圆括号时,弹出栈顶的左圆括号,如果栈空,则说明右圆括号多了。如果在表达式处理完毕后,在栈中还有元素,则说明左圆括号多了。结果是大写的“YES”“NO”,不要写成小写的。 \1. 算法设计 (1)初始化一个栈s 。 (2)读取字符c ,如果c !=’@’,则执行第3步,否则转向第5步。 (3)如果c =’(’,则入栈s.push(c )。 (4)如果c =’)’,则判断栈是否为空,如果栈非空,则出栈,否则输出“NO”,结束 (5)在字符串处理完毕,判断栈是否为空,如果栈为空,则说明正好配对,输出“YES”,否则输出“NO”,结束。 \2. 完美图解 (1)以输入样例“2*(x+y)/(1-x)@”为例,初始化一个栈,如下图所示。 (2)读入字符“2*(”,遇到左圆括号时入栈,如下图所示。 (3)继续读入“x+y)”,遇到右圆括号时,如果栈非空,则出栈,如下图所示 (4)继续读入“/(”,遇到左圆括号时入栈,如下图所示。 (5)继续读入“1-x)”,遇到右圆括号时,如果栈非空,则出栈,如下图所示。 (6)继续读入“@”,遇到“@”,字符串读入完毕,此时栈为空,说明括号匹配,输出“YES”。 \3. 算法实现 题目描述(UVA514): 某城市有一个火车站,铁轨铺设如下图所示。有n (n ≤1000)节车厢从A方向驶入车站,将其按进站的顺序编号为1~n 。你的任务是判断是否能让它们按照某种特定的顺序进入B方向的铁轨并驶出车站。例如,出栈顺序(5 4 1 2 3)是不可能的,但出栈顺序(5 4 3 2 1)是可能的。为了重组车厢,你可以借助中转站C。中转站C是一个可以停放任意多节车厢的车站,但由于末端封顶,驶入C的车厢必须按照相反的顺序驶出C。对于每节车厢,一旦从A移入C,就不能返回A了;一旦从C移入B,就不能返回C了。在任意时刻只有两种选择:A到C和C到B。 输入: 输入包含多组数据,对于每一组数据,第1行是一个整数n 。接下来的若干行,每行n 个数,代表1~n 车厢的出栈顺序,最后一行只有一个整数0。最后一组数据“n =0”,输入结束,不输出答案。 输出: 对每行的出栈顺序都单行输出“Yes”或“No”。对每组数据都在最后输出空行。 题解: 本题中的C就是一个栈,1~n 车厢按顺序依次从A端进来,首先和B端的字符进行比较,如果相等,则直接从B端出去,如果不相等则进入栈C。如果栈非空,则判断栈顶元素是否与B端的字符相等,如果相等则出栈,一直比较下去。如果1~n 车厢都已处理完毕,B端字符还未处理完,则输出“No”,否则输出“Yes”。 需要特别注意:输入包含多组数据,每组数据都以0结束,每组数据输出结束时都会加一个空行。最后一组数据为0,不输出。 \1. 算法设计 (1)输入n ,如果n 为0,则结束。 (2)输入第1组数据的第1个字符。 (3)如果B[1]不为0,则读入余下的字符并将其存入B[]。 (4)初始化一个栈s。 (5)1~n 车厢依次与B端的字符进行比较,如果相等,则直接从B端出栈,否则入栈。 (6)如果栈非空,则判断栈顶元素是否与B端的字符相等,相等则出栈,一直比较下去。 (7)如果1~n 车厢都已处理完毕,B端字符还未处理完,则输出“No”,否则输出“Yes” \3. 算法实现 题目描述(UVA442): 假设你必须评估一种表达式,比如 A × B × C × D × E ,其中 A 、 B 、 C 、 D 、 ***E*是矩阵。既然矩阵乘法满足结合率,那么乘法的顺序是任意的。矩阵连乘的乘法次数由相乘的顺序决定。例如, A 、B 、 C 分别是50×10、10×20和20×5的矩阵。 现在有两种方案计算 A × B × C ,即( A × B )× C 和 A ×( B × C)。第1种要进行15 000次乘法运算,而第2种只进行3 500次乘法运算。写程序,计算给定矩阵表达式需要进行多少次乘法运算。 输入: 输入包含矩阵和表达式两部分。在第1部分,第1行包含一个整数n (1≤n ≤26),代表矩阵的个数;接下来的n 行,每行都包含了一个大写字母来表示矩阵的名称,以及两个整数来表示矩阵的行数和列数。第2部分是一个矩阵或矩阵表达式 输出: 对于每一个表达式,如果乘法无法进行,则输出“Error”,否则输出所需的乘法运算次数。 1)什么是矩阵可乘 如果第1个矩阵的列等于第2个矩阵的行,那么这两个矩阵是可乘的。 2)矩阵相乘后的结果是什么 两个矩阵相乘的结果矩阵,其行、列分别等于第1个矩阵的行、第2个矩阵的列。如果有很多矩阵相乘呢? 多个矩阵相乘的结果矩阵,其行、列分别等于第1个矩阵的行、最后1个矩阵的列。而且无论矩阵的计算次序如何,都不影响它们的结果矩阵。 3)两个矩阵相乘需要多少次乘法运算 例如两个矩阵 A 3×2 、 B 2×4 相乘,结果为 C 3×4 ,要怎么计算呢? A 矩阵第1行第1个数× B 矩阵第1列第1个数:1×2。 A 矩阵第1行第2个数× B 矩阵第1列第2个数:2×3。 将两者相加并存放在 C 矩阵第1行第1列:1×2+2×3。 A 矩阵第1行第1个数× B 矩阵第2列第1个数:1×4。 A 矩阵第1行第2个数× B 矩阵第2列第2个数:2×6。 将两者相加并存放在 C 矩阵第1行第2列:1×4+2×6。 A 矩阵第1行第1个数× B 矩阵第3列第1个数:1×5。 A 矩阵第1行第2个数× B 矩阵第3列第2个数:2×9。 将两者相加并存放在 C 矩阵第1行第3列:1×5+2×9。 A 矩阵第1行第1个数× B 矩阵第4列第1个数:1×8。 A 矩阵第1行第2个数× B 矩阵第4列第2个数:2×10。 将两者相加并存放在 C 矩阵第1行第4列:1×8+2×10。 其他行以此类推,计算结果如下图所示。 可以看出,结果矩阵中的每个元素都执行了两次乘法运算,那么在结果矩阵中有3×4=12个数,共需要执行2×3×4=24次乘法运算,两个矩阵A 3×2 、A 2×4 相乘执行乘法运算的次数为3×2×4。因此,Am × n 、An × k 相乘执行乘法运算的次数为m ×n ×k 。 \1. 算法设计 (1)首先将矩阵及行列值存储在数组中。 (2)读入一行矩阵表达式。 (3)遇到矩阵名称时入栈,遇到右括号时出栈。两个矩阵m 2 、m 1 ,如果m 1 的列不等于m 2 的行,则矩阵不可乘,标记error=true并退出循环,否则计算乘法运算的次数,并将两个矩阵相乘后的结果矩阵入栈。 (4)如果error=true,则输出“error”,否则输出乘法运算的次数。 \2. 完美图解 (1)以输入样例(A(BC))为例,其中 A 50 10; B 10 20; C 20 5,字母表示矩阵名,后两个数字分别表示该矩阵的行和列。遇到左括号什么也不做,遇到矩阵名则入栈,首先 ABC 入栈,如下图所示。 (2)遇到右括号时出栈。两个矩阵 C 、 B , B 10 20; C 20 5; B 的列等于 C 的行,两个矩阵是可乘的,乘法运算的次数为10×20×5=1000,结果矩阵 X 的行为 B 的行10, X 的列为 C 的列5,即 X 10 5,将结果矩阵入栈,如下图所示。 (3)遇到右括号时出栈。两个矩阵 X 、 A , A 50 10; X 10 5; A 的列等于X的行,两个矩阵是可乘的,乘法运算的次数为50×10×5=2500,累计次数为1000+2500=3500,结果矩阵 Y 的行为 A 的行50, Y 的列为 X 的列5,即 Y 50 5,将结果矩阵入栈,如下图所示。 (4)表达式读入完毕,输出结果3500。 \3. 算法实现 题目描述(UVA12100): 在计算机学生会里只有一台打印机,但是有很多文件需要打印,因此打印任务不可避免地需要等待。有些打印任务比较急,有些不那么急,所以每个任务都有一个1~9的优先级,优先级越高表示任务越急。 打印机的运作方式:首先从打印队列里取出一个任务J,如果队列里有比J更急的任务,则直接把J放到打印队列尾部,否则打印任务J(此时不会把它放回打印队列)。输入打印队列中各个任务的优先级及你的任务在队列中的位置(队首位置为0),输出该任务完成的时刻。所有任务都需要1分钟打印。例如,打印队列为{1,1,9,1,1,1},目前处于队首的任务最终完成时刻为5。 输入: 第1行为测试用例数T (最多100个);每个测试用例的第1行都包括n (1≤n ≤100)和m (0≤m ≤n−1),其中n 为打印任务数量,m 为你的任务序号(从0开始编号)。接下来为n 个数,为n 个打印任务的优先级。 输出: 对于每个测试用例,都单行输出你的作业打印完成的分钟数。 题解: 本题需要用一个队列存储打印任务,还需要知道当前队列中优先级最高是多少。首先从队首取出一个任务J,如果J的优先级不低于队列中的最高优先级,则直接打印,否则将任务J放入队尾。怎么知道当前队列中的最高优先级呢?最简单的办法就是按优先级非递增(允许相等的递减)排序,排序的时间复杂度为O (n logn )。如果写一个函数来查找当前队列中的最高优先级,则每次查找的时间复杂度为O (n ),在最坏情况下执行n 次,时间复杂度为O (n 2)。 \1. 算法设计 (1)读入T ,表示T 组数据。 (2)读入n 、m ,表示打印任务的个数和你要打印的任务编号。 (3)读入优先级序列,将其存储在a []、b []两个数组中,并将优先级序列的下标依次(从0开始)放入队列q 。 (4)b []数组非递增排序,w =0,k =0,w 用来取最高优先级的下标,k 用来计数已打印了多少个任务。 (5)如果队列q 非空,则取出队头下标t ,它的优先级为a [t ],max=b [w ]。如果a [t ] (6)在T 组数据处理完毕后结束。 \2. 完美图解 (1)以下面的输入样例为例,n =4,m =2,即共有4个打印任务,你的打印任务编号为2。 (2)读入优先级序列,将其存储在a []、b []两个数组中,并将优先级序列的下标依次(从0开始)放入队列q ,如下图所示。 (3)b []数组非递增排序,初始化w =0,k =0,如下图所示。 (4)取队头t =0,其优先级为a [0]=1,max=b [0]=4,a [0]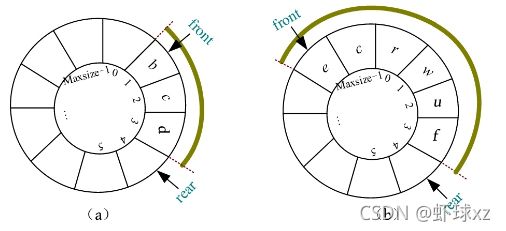

Q.front==Q.rear; //Q.rear 和Q.front 指向同一个位置
(Q.rear+1)%Maxsize == Q.front;//Q.rear 后移一位正好是 Q.front
Q.base[Q.rear]=x;//将元素x放入Q.reaz 所指的空间
Q.rear=(Q.rear+1)%Maxsize;//Q.rear 后移一位
e=Q.base[Q.front];//用变量记录 Q.front 所指的元素
Q.front=(Q.front+1)%Maxsize;//Q.front 后移一位
(Q.rear-Q.front+Maxsize)%Maxsize
bool InitQueue(SqQueue &Q)//注意使用引用参数,和否则出了函数,其改变无效
{
Q.base = new int[Maxsize];//分配 Maxsize 大小的空间
if(!Q.base) return false; //分配空间失败
Q.front=Q.rear=0;//队头和队尾为0,队列为空
return true;
}
bool EnQueue(SqQueue &Q,int e)//入队,将元素e放入@的队尾
{
if((Q.rear+1)%Maxsize == Q.front)//队尾后移一位等于队头,表明队满
return false;
Q.base[Q.rear]=e;将新元素插入队尾
Q.rear=(Q.rear+1)%Maxsize;//队尾后移一位
return true;
}
bool DeQueue(SqQueue &Q,int &e) //出队,删除 2 的队头元素,用 e 返回其值
{
if(Q.front == Q.rear)//队空
return false;
e=Q.base[Q.front];//保存队头元素
Q.front=(Q.front+1)%Maxsize;//队头后移一位
return true;
}
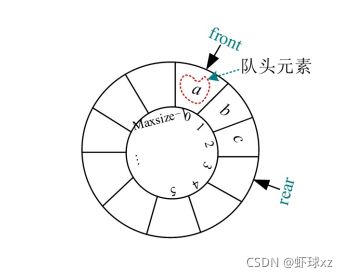
int GetHead(SqQueue Q) //取队头元素,不修改队头
{
if(Q.front != Q.rear)//队列非空
return Q.base[Q.front];
return -1;
}
int QueueLength(SqQueue Q)
{
return (Q.rear-Q.front+Maxsize)%Maxsize;
}
链队列
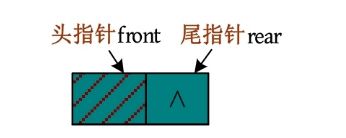
void InitQueue(LinkQueue &Q) //注意使用引用参数,否则出了函数的作用域,其改变无效
{
Q.front=Q.rear=new Qnode;//创建头节点,使头指针和尾指针指向头节点
Q.front->next=NULL;
}
p=new Snode;//生成新节点
p->data=e;//将e放在新节点的数据域
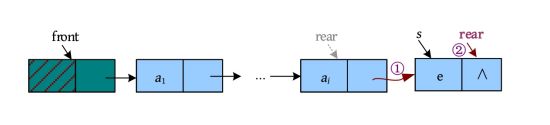
void EnQueue(LinkQueue &Q,int e)//入队,将元素 e 放入队尾
{
Qptr s;
s=new Qnode;
s->data=e;
s->next=NULL;
Q.rear->next=s;//将新节点插入队尾
Q.rear=s;//尾指针后移
}
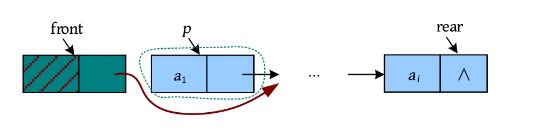
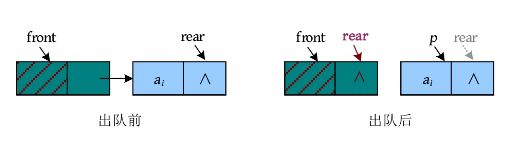
bool DeQueue(LinkQueue &Q,int &e) //出队,删除 o 的队头元素,用 e 返回其值
{
if(Q.front==Q.rear)//队空
return false;
Qptr p = Q.front->next;
e=p->data;///保存队头元素
Q.front->next=p->next;
if(Q.rear==p)//若在队列中只有一个元素,则在删除后需要修改队尾指针
Q.rear=Q.front;
delete p;
return true;
}
int GetHead(LinkQueue Q)
{
if(Q.front!=Q.rear)
return Q.front->next->data;
return -1;
}
训练1 括号匹配
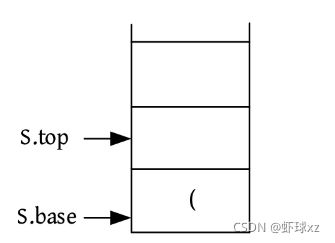
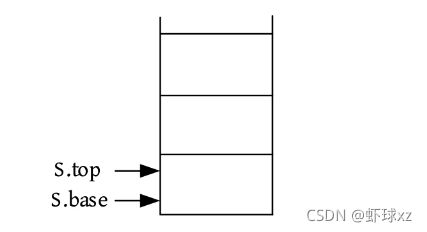
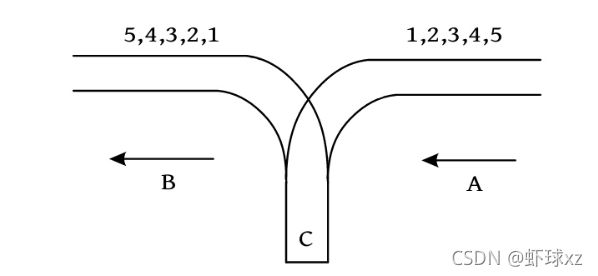
#include 训练2 铁轨
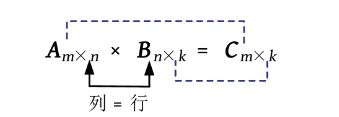
#include 训练3 矩阵连乘
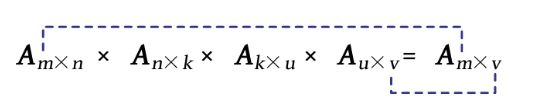
#include 训练4 打印队列
4 2
1 2 3 4