算法训练营 图论基础
图论简介
- 图通常以一个二元组 G = < V , E > G =
- ∣ V ∣ |V| ∣V∣表示节点集中元素的个数,即节点数,也被称为图 G G G的阶。
- ∣ E ∣ |E| ∣E∣表示边集中元素的个数,即边数。
- 若图每条边都是没有方向的,则称之为无向图;若图每条边都是有方向的,则称之为有向图;
- 在无向图中,每条边都是由两个节点组成的无序对。例如节点v_{1}和节点v_{2}之间的边,记为(v_1,v_3)或(v_3,v_1)。
- 在有向图中,有向边也被称为弧,每条弧都是由两个节点组成的有序对,例如从节点 v 1 v_{1} v1到节点 v 3 v_{3} v3的弧,记为 < v 1 , v 3 >
- 节点的度指与该节点相关联的边数,记为 T D ( v ) TD(v) TD(v)。
- 所有节点的度数之和等于边数的两倍,即: ∑ i = 1 n T D ( v i ) = 2 e \sum^{n}_{i = 1}TD(v_{i}) = 2e ∑i=1nTD(vi)=2e
- 在有向图中,节点的度又被分为入度和出度。节点 v v v的入度是以节点 v v v为终点的有向边的数量,记为 I D ( v ) ID(v) ID(v),即进来的边数。节点 v v v的出度是以节点 v v v为始点的有向边的数量,记为 O D ( v ) OD(v) OD(v),即发出的边数。
10.所有节点的入度之和等于出度之和,又因为所有节点的度数之和等于边的2倍,因此: ∑ i = 1 n T D ( v i ) = ∑ i = 1 n O D ( v i ) = e \sum^{n}_{i = 1}TD(v_{i}) = \sum^{n}_{i = 1}OD(v_{i}) = e ∑i=1nTD(vi)=∑i=1nOD(vi)=e
图的存储
- 图的存储分为顺序存储和链式存储。顺序存储包括邻接矩阵和边集数组,链式存储包括邻接表、链式前向星、十字链表和邻接多重表
邻接矩阵
- 领接矩阵通常采用一个一维数组存储图中节点的信息,采用一个二维数组存储图中节点之间的邻接关系
无向图的邻接矩阵
- 在无向图中,若从节点 v i v_{i} vi到节点 v j v_{j} vj有边,则邻接矩阵 M [ i ] [ j ] = M [ i ] [ j ] = 1 M[i][j] = M[i][j] = 1 M[i][j]=M[i][j]=1,否则 M [ i ] [ j ] M[i][j] M[i][j]
- 例如,一个无向图的节点信息如图,在该无向图中,节点 a a a到节点 b b b有边,从节点 b b b到节点 a a a也有边,节点 a a a、 b b b、 c c c、 d d d在一维数组中的存储位置分别为0、1、2、3,则 M [ 0 ] [ 1 ] = M [ 1 ] [ 0 ] = 1 M[0][1] = M[1][0] = 1 M[0][1]=M[1][0]=1。
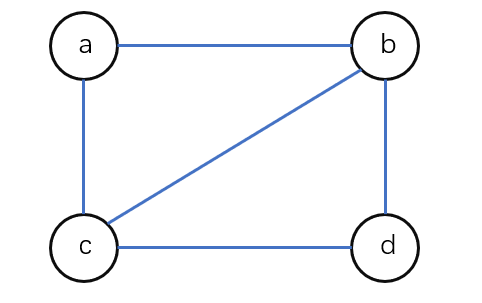
- 无向图的邻接矩阵特点:无向图的邻接矩阵是对称矩阵,并且是唯一的。第 i i i行或第 i i i列的非零元素的个数正好是第 i i i个节点的度。
有向图的邻接矩阵
- 在有向图中,若从节点 v i v_{i} vi到节点 v j v_{j} vj有边,则邻接矩阵 M [ i ] [ j ] = 1 M[i][j] = 1 M[i][j]=1,否则 M [ i ] [ j ] = 0 M[i][j] = 0 M[i][j]=0
- 例如在如下有向图中,从节点 a a a到节点 b b b有边,节点 a a a、 b b b在一维数组中的存储位置分别为0、1,因此 M [ 0 ] [ 1 ] = 1 M[0][1] = 1 M[0][1]=1。有向图中的变是有向边,从节点 a a a到节点 b b b右边,从节点 b b b到节点 a a a不一定有边,因此有向图的邻接矩阵不一定是对称的。
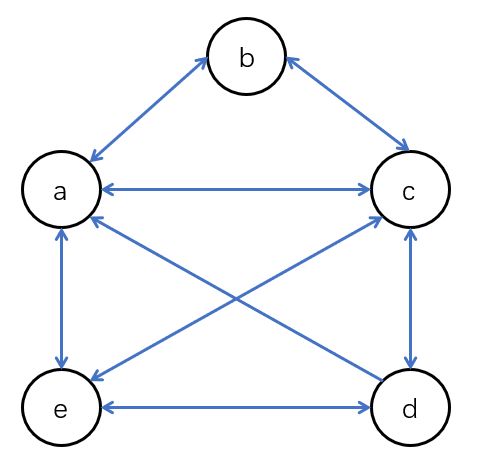
- 有向图的邻接矩阵特点:有向图的邻接矩阵不一定对称。第 i i i行非零元素的个数正好是第 i i i个节点的出度,第 i i i列非零元素的个数正好是第 i i i个节点的入度。
网的邻接矩阵
- 网是带权图,需要存储边的权值,则邻接矩阵表示为: M [ i ] [ j ] = w i j M[i][j] = w_{ij} M[i][j]=wij,否则 M [ i ] [ j ] = ∞ M[i][j] = \infty M[i][j]=∞
邻接矩阵的数据结构定义
- 定义邻接矩阵的数据结构:
#include邻接矩阵的存储方法
算法步骤
- 输入节点数和边数。
- 依次输入节点信息,将其存储到节点数组
Vex[]中。 - 初始化邻接矩阵,如果是图则将其初始化为0;如果是网,则将其初始化为 ∞ \infty ∞;
- 依次输入每条边依附的两个节点,如果是网,则还需要输入该边的权值。
- 如果是无向图,则输入 a a a b b b,查询节点 a a a、 b b b在节点数组
Vex[]中的存储下标 i i i、 j j j,令 E d g e [ i ] [ j ] = E d g e [ j ] [ i ] = 1 Edge[i][j] = Edge[j][i] = 1 Edge[i][j]=Edge[j][i]=1。 - 如果是有向图,则输入 a a a b b b,查询节点 a a a、 b b b在节点数组
Vex[]中的存储下标 i i i、 j j j,令 E d g e [ i ] [ j ] = 1 Edge[i][j] = 1 Edge[i][j]=1。 - 如果是无向网,则输入 a a a b b b w w w,查询节点 a a a、 b b b在节点数组
Vex[]中的存储下标 i i i、 j j j,令 E d g e [ i ] [ j ] = E d g e [ j ] [ i ] = w Edge[i][j] = Edge[j][i] = w Edge[i][j]=Edge[j][i]=w。 - 如果是无向网,则输入 a a a b b b w w w,查询节点 a a a、 b b b在节点数组
Vex[]中的存储下标 i i i、 j j j,令 E d g e [ i ] [ j ] = w Edge[i][j] = w Edge[i][j]=w。
算法程序
#include输入:
4
5
a b c d
a b
a d
b c
b d
c d
输出:
0 1 0 1
1 0 1 1
0 1 0 1
1 1 1 0
邻接矩阵的优缺点
- 优点
- 快速判断在两节点之间是否有边。例如, E d g e [ i ] [ j ] = 1 Edge[i][j] = 1 Edge[i][j]=1,表示有边; E d g e [ i ] [ j ] = 0 Edge[i][j] = 0 Edge[i][j]=0,表示无边。
- 方便计算各节点的度。在无向图中,邻接矩阵第 i i i行元素之和就是节点 i i i的度;在有向图中,第 i i i行元素之和就是节点 i i i的出度,第 i i i列元素之和就是节点 i i i的入度,时间复杂度为 O ( n ) O(n) O(n)
- 缺点
- 不便于增删节点。增删节点时,需要改变邻接矩阵的大小,效率较低。
- 不便于访问所有邻接点。访问第 i i i个节点的所有邻接点时,需要访问第 i i i行的所有元素,时间复杂度为 O ( n ) O(n) O(n)。访问所有节点的邻接点,时间复杂度为 O ( n 2 ) O(n^{2}) O(n2)
邻接表
- 邻接表是图的一种链式存储方法,其数据结构包括两部分:节点和邻接点
- 无向图邻接表特点:如果无向图有 n n n个节点、 e e e条边,则节点表有 n n n个节点,邻接点表有 2 e 2e 2e个节点。节点的度为该节点后面单链表中的节点数。
- 有向图邻接表特点:如果有向图有 n n n个节点、 e e e条边,则节点表有 n n n个节点,邻接点表有 e e e个节点。节点的出度为该节点后面单链表中的节点数。
- 有向图的逆邻接表:如果有向图有 n n n个节点、 e e e条边,则节点表有 n n n个节点,邻接点表有 e e e个节点。节点的入度为该节点后面单链表中的节点数。
邻接表的数据结构定义
- 邻接表的数据结构包括节点和邻接点。
- 邻接点。包括该邻接点的存储下标
v和指向下一个邻接点的指针next,如果是网的邻接点,则还需增加一个权值域w。
typedef struct AdjNode{ //定义邻接点类型
int v; //邻接点下标
struct AdjNode *next; //指向下一个邻接点
}AdjNode;
- 节点。包括节点信息
data和指向第1个邻接点的指针first
typedef char VexType;//顶点的数据类型为字符型
typedef struct VexNode{ //定义顶点类型
VexType data; // VexType为顶点的数据类型,根据需要定义
AdjNode *first; //指向第一个邻接点
}VexNode;
- 定义邻接表类型:
typedef struct{//定义邻接表类型
VexNode Vex[MaxVnum];
int vexnum,edgenum; //顶点数,边数
}ALGraph;
邻接表的存储方式
- 输入节点数和边数;
- 依次输入节点信息,将其存储到节点数组
Vex[]的data域中,将Vex[]的first域置空; - 依次输入每条边依附的两个节点,如果是网,则还需要输入该边的权值。
- 如果是无向图,则输入 a a a b b b,查询节点 a a a、 b b b在节点数组
Vex[]中存储的下标 i i i、 j j j,创建一个新的邻接点 s s s,令s -> v = j,s -> next = NULL;然后将节点 s s s插入第 i i i个节点的第1个邻接点之前(头插法)。在无向图中,从节点 a a a到节点 b b b有边,从节点 b b b到节点 a a a也有边,因此还需要创建一个新的邻接点 s 2 s_{2} s2 。令s2 -> v = i;s2->next = NULL;然后将 s 2 s_2 s2节点插入第 j j j个节点的第1个邻接点之前(头插法)。 - 如果是有向图,则输入 a a a b b b,查询节点 a a a、 b b b在节点数组
Vex[]中存储的下标 i i i、 j j j,创建一个新的邻接点 s s s,令s -> v = j,s -> next = NULL;然后将节点 s s s插入第 i i i个节点的第1个邻接点之前(头插法)。 - 如果是无向网或有向网,则和无向图或有向图的处理方式一样,只是邻接点多了一个权值域。
算法实现
#include输入:
5 7
a b c d e
a b
a c
a e
b c
c d
c e
d e
输出:
a: [4] [2] [1]
b: [2]
c: [4] [3]
d: [4]
e:
邻接表的优缺点
- 优点
- 便于增删节点。
- 便于访问所有邻接点。访问所有节点的邻接点,其时间复杂度为 O ( n + e ) O(n+e) O(n+e)。
- 空间复杂度低。节点表占用 n n n个空间,无向图的邻接点表占用 n + 2 e n+2e n+2e个空间,有向图的邻接点表占用 n + e n+e n+e个空间,总体空间复杂度为 O ( n + 2 e ) O(n+2e) O(n+2e)。而邻接矩阵的空间复杂度为 O ( n 2 ) O(n^{2}) O(n2)。因此,对于稀疏图,采用邻接表存储;对于稠密图,采用邻接矩阵存储。
- 缺点
- 不便于判断在两个节点之间是否有边。要判断在两个节点之间是否有边,需要遍历该节点后面的邻节点链表。
- 不便于计算各节点的度。在无向图邻接表中,节点的度为该节点后面单链表中的节点数;在有向图邻接表中,节点的出度为该节点后面单链表中的节点数,但不易于求入度;在有向图的逆邻接表中,节点的入度为该节点后面单链表中的节点数。
链式前向星
- 链式前向星采用了一种静态链表存储方式,将边集数组和邻接表相结合,可以快速访问一个节点的所有邻接点,在算法竞赛中被广泛使用。
- 链式前向星有两种存储结构:边集数组:
edge[],edge[i]表示第 i i i条边。头节点数组:head[],head[i]存储以 i i i为起点的第1条边的下标(edge[]中的下标)
const int maxe = 100;
const int maxn = 10;
struct node{
int to,next,w;
}ledge[maxe]; //边集数组,对边数一般要设置比maxn * maxn大的数
int head[maxn]; //头节点数组
实现程序
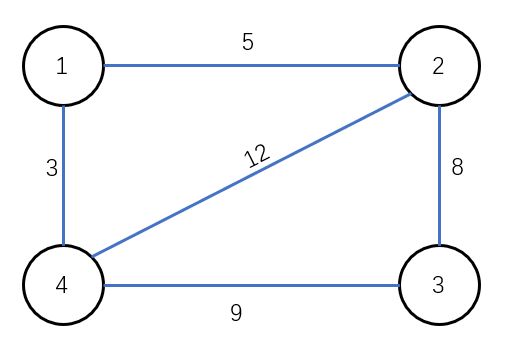
- 构建如上图所示带权值无向图
#include输入:
请输入边数:5
1 2 5
1 4 3
2 3 8
2 4 12
3 4 9
请输入需要查询的节点:2
输出:
2的邻接点: 4 3 1
对应权值:12 8 5
链式前向星的特性
- 和邻接表一样,因为采用头插法进行链接,所以边的输入顺序不同,创建的链式前向星也不同。
- 对于无向图,每输入一条边,都需要添加两条边,互为反向边。也就是说,如果一条边的下标为 i i i,则其反向边为
i^1。(^为异或运算符) - 链式前向星具有边集数组和邻接表的功能,属于静态链表,不需要频繁地创建节点,应用起来十分灵活。
训练1:最大节点
题目描述
给定有 N N N个节点、 M M M条边的有向图,对于每个节点 v v v都求 A ( v ) A(v) A(v),表示从节点 v v v出发,能到达的编号最大的节点。
输入:第1行包含两个整数 N N N、 M M M( 1 ≤ N 1 \leq N 1≤N, M ≤ 1 0 5 M \leq 10^5 M≤105).接下来的 M M M行,每行都包含两个整数 U i U_{i} Ui、 V i V_{i} Vi,表示边 ( U 1 , V i ) (U_{1},V_{i}) (U1,Vi)。节点的编号为 1 ∼ N 1 \sim N 1∼N。
输出: N N N个整数 A ( 1 ) A(1) A(1), A ( 2 ) A(2) A(2),… A ( N ) A(N) A(N)
算法设计
- 建立原图的反向图,从最大节点u出发,对凡是能遍历到的节点v,v能到达的编号最大的节点就是u。
- 存储图的反向图
- 在反向图上进行倒序深度遍历
算法实现
#include输入:
4 3
1 2
2 4
4 3
输出:
4 4 3 4
训练2:有向图D和E
题目描述
有向图 D D D有 n n n个节点和 m m m条边,可以通过以下方式制作 D D D的Lying图 E E E。 E E E将有 m m m个节点,每个都用于表示 D D D的每条边
输入:第1行包含测试用例数 N ( N < 220 ) N(N < 220) N(N<220)。在每个测试用例的前两行都包含 m ( 0 ≤ m ≤ 300 ) m(0 \leq m \leq 300) m(0≤m≤300)和 k k k,表示图 E E E中的节点数和边数。下面的 k k k行,每行都包含两个节点 x x x和 y y y,表示在E中从 x x x到 y y y有一条边。节点编号为 0 ∼ m − 1 0 \sim m-1 0∼m−1。
输出:对每个测试用例,都输出一行Case #t,其中t表示测试用例编号,然后是Yes或者No,用于判断 E E E是否是一个有向图 D D D的Lying图。
算法设计
- 用邻接矩阵存储 E E E。
- 判断在 E E E中是否存在节点 i i i和节点 j j j有公共邻接点但是对 i i i邻接的节点而 j j j不邻接的情况。
算法实现
#include输入:
4
2
1
0 1
5
0
4
3
0 1
2 1
2 3
3
9
0 1
0 2
1 2
1 0
2 0
2 1
0 0
1 1
2 2
输出:
Case #1: Yes
Case #2: Yes
Case #3: No
Case #4: Yes
训练3:奶牛排序
题目描述
约翰想安装奶牛的产奶能力给它们排序。已知有 N ( 1 ≤ N ≤ 1000 ) N(1 \leq N \leq 1000) N(1≤N≤1000)头奶牛,而且知道这些奶牛的 M ( 1 ≤ M ≤ 10000 ) M(1 \leq M \leq 10000) M(1≤M≤10000)种关系,将每种关系都表示为“ X X X Y Y Y”,表示奶牛 X X X的产奶能力大于奶牛 Y Y Y。约翰想知道自己至少还要调查多少对关系才能完成整个排序。
输入:第1行包含两个整数 N N N和 M M M。第 2... M + 1 2...M+1 2...M+1行,每行都包含两个整数 X X X和 Y Y Y。 X X X和 Y Y Y都在 1 ∼ N 1 \sim N 1∼N范围内,表示奶牛 X X X的排名高于奶牛 Y Y Y。
输出:单行输出至少还要调查多少种关系才能完成整个排序。
算法设计
- 根据输入样例,创建一个有向图。

- 根据传递性,得到的已知关系有7种,分别是: 1 > 4 1>4 1>4、 1 > 5 1>5 1>5、 2 > 1 2>1 2>1、 2 > 3 2>3 2>3、 2 > 4 2>4 2>4、 2 > 5 2>5 2>5、 3 > 4 3>4 3>4
- 对于有 n n n个节点的图,两两之间的关系一共有 n ( n − 1 ) / 2 n(n-1)/2 n(n−1)/2种,5个节点共有 5 × 4 / 2 = 10 5 \times 4 / 2 = 10 5×4/2=10种关系,还需要知道 10 − 7 = 3 10-7 = 3 10−7=3种关系即可。
- 可以利用
bitset位运算,得到已知关系,将每个节点都用一个bitset来表示。bitset其中p[maxn] maxn表示位数,p[]表示二进制数组。
初始化时,p[i][j] = 1,即p[i]的第 i i i位为1(从右侧数第0位、1位、2位)
输入1-5,令p[1][5] = 1,则p[1] = ......100010;
输入1-4,令p[1][4] = 1,则p[1] = ......110010;
输入2-1,令p[2][1] = 1,则p[2] = ......000110;
输入2-3,令p[2][3] = 1,则p[2] = ......001110;
输入3-4,令p[3][4] = 1,则p[1] = ......011000; - 例如,
p[2][1] = 1,则p[2] = p[2] | p[1] = 001110 | 110010 = 111110。如果2和1有关系,而1和4、5有关系,则通过或运算,可以得出2和4、5也有关系。 - 通过此方法,可以找到每个点和其它点的关系。用
ans累计每个数组元素1的个数,因为初始化时自己到自己为1(p[1]初始化时第1位为1),所以ans多算了n种关系,已知关系数应为ans-n,用n(n-1)/2减去已知关系数即可。
#include输入:
5 5
2 1
1 5
2 3
1 4
3 4
输出:
3
图的遍历
- 图的遍历根据搜索方式的不同,分为广度优先遍历和深度优先遍历。
广度优先遍历
- 广度优先搜索指从某个节点(源点)出发,一次性访问所有未被访问的邻接点,再依次从这些已访问过的邻接点出发,一层一层地访问。
算法设计
- 初始化所有节点均未被访问,并初始化一个空队列。
- 从图中的某个节点 v v v出发,访问 v v v并标记其已被访问,将 v v v入队。
- 如果队列非空,则继续执行,否则算法结束。
- 将队头元素 v v v出队,依次访问 v v v的所有未被访问的邻接点,标记已被访问并入队,转向步骤3。
算法实现
基于邻接矩阵的广度优先遍历
#include输入与输出:
请输入顶点数:
6
请输入边数:
9
请输入顶点信息:
1 2 3 4 5 6
请输入每条边依附的两个顶点:
1 2
1 3
3 2
2 4
4 3
3 5
5 4
4 6
5 6
图的邻接矩阵为:
0 1 1 0 0 0
0 0 0 1 0 0
0 1 0 0 1 0
0 0 1 0 0 1
0 0 0 1 0 1
0 0 0 0 0 0
请输入遍历图的起始点:1
广度优先搜索遍历图结果:
1 2 3 4 5 6
基于邻接表的广度优先遍历
#include输入与输出:
请输入顶点数和边数:
6 9
请输入顶点信息:
1 2 3 4 5 6
请依次输入每条边的两个顶点u,v
1 2
1 3
3 2
2 4
4 3
3 5
5 4
4 6
5 6
----------邻接表如下:----------
1: [2] [1]
2: [3]
3: [4] [1]
4: [5] [2]
5: [5] [3]
6:
请输入遍历图的起始点:1
广度优先搜索遍历图结果:
1 3 2 5 4 6
深度优先遍历
- 深度优先搜索沿着一条路径一直搜索下去,在无法搜索时,回退到刚刚访问过的节点。
算法设计
- 初始化图中的所有节点均未被访问。
- 从图中的某个节点 v v v出发,访问 v v v并标记其已被访问。
- 依次检查 v v v的所有邻接点 w w w,如果 w w w未被访问,则从 w w w出发进行深度优先遍历(递归调用,重复步骤2~3)。
算法实现
基于邻接矩阵的深度优先遍历
#include输入与输出:
请输入顶点数:
8
请输入边数:
9
请输入顶点信息:
1 2 3 4 5 6 7 8
请输入每条边依附的两个顶点:
1 3
1 2
2 6
2 5
2 4
3 8
3 7
4 5
7 8
图的邻接矩阵为:
0 1 1 0 0 0 0 0
1 0 0 1 1 1 0 0
1 0 0 0 0 0 1 1
0 1 0 0 1 0 0 0
0 1 0 1 0 0 0 0
0 1 0 0 0 0 0 0
0 0 1 0 0 0 0 1
0 0 1 0 0 0 1 0
请输入遍历连通图的起始点:1
深度优先搜索遍历连通图结果:
1 2 4 5 6 3 7 8
基于邻接表的深度优先遍历
#include输入与输出:
请输入顶点数和边数:
8 9
请输入顶点信息:
1 2 3 4 5 6 7 8
请依次输入每条边的两个顶点u,v
1 3
1 2
2 6
2 5
2 4
3 8
3 7
4 5
7 8
----------邻接表如下:----------
1: [1] [2]
2: [3] [4] [5] [0]
3: [6] [7] [0]
4: [4] [1]
5: [3] [1]
6: [1]
7: [7] [2]
8: [6] [2]
请输入遍历连通图的起始点:1
深度优先搜索遍历连通图结果:
1 2 4 5 6 3 7 8
训练:油田
题目描述
某石油勘探公司正在按疾患勘探地下油田资源,在一片长方形地域中工作。他们首先将该地域划分为许多小正方形区域,然后使用勘探设备分别探测在每一小正方形区域内是否有油。含有油的区域被称为油田。如果两个油田相邻(在水平、垂直或对角线相邻),则它们是相同油藏的一部分。油藏可能非常大并可能包含许多油田(油田的个数不超过100)。你的工作是确定在这个长方形地域中包含多少不同的油藏。
输入:输入文件包含一个或多个长方形地域。每个地域的第1行都有两个正整数 m m m和 n ( 1 ≤ m , n ≤ 100 ) n(1 \leq m,n \leq 100) n(1≤m,n≤100),表示地域的行数和列数。如果 m = 0 m = 0 m=0,则表示输入结束;否则此后有 m m m行,每行都有 n n n个字符。每个字符都对应一个正方形区域,字符*表示没有油,字符@表示有油。
输出:对于每个长方形地域,都单行输出油藏的个数。
算法设计
- 字符矩阵中的每个位置都鸡心判断,如果未标记连通分量号且为’@’,则从该位置出发进行深度优先搜索。
- 搜索时需要判断是否出界,是否已有连通分量号或不是’@’;否则将该位置标记连通分量号为id,从位置出发,沿8个方向继续进行深度优先搜索。
算法实现
#include输入:
1 1
*
3 5
*@*@*
**@**
*@*@*
1 8
@@****@*
5 5
****@
*@@*@
*@**@
@@@*@
@@**@
0 0
输出:
0
1
2
2
训练2:理想路径
题目描述
给定一个有 n n n个节点、 m m m条边的无向图,每条边都涂有1种颜色。求节点1到 n n n的一条路径,使得经过的边数最少,在此前提下,经过边的颜色序列最小。可能有自环与重边。输入保证至少存在一条连接节点1和 n n n的路径。
输入:输入共 m + 1 m+1 m+1行。第1行包含两个整数: n n n和 m m m。之后的 m m m行,每行都包含3个整数 a i a_{i} ai、 b i b_{i} bi、 c i c_{i} ci,表示在 a i a_{i} ai、 b i b_{i} bi之间有一条颜色为 c i c_{i} ci的路径。
输出:输出共两行,第1行包含正整数 k k k,表示节点1到 n n n至少需要经过 k k k条边。第2行包含 k k k个由空格隔开的正整数,表示节点1到 n n n依次经过的边的颜色。
算法设计
- 从节点 n n n反向广度优先遍历标高,节点1的高度正好为从节点1到 n n n的最短距离。
- 从节点1正向广度优先遍历,沿着高度减1的方向遍历,找色号小的点,如果多个点的色号都最小,则考察下一个色号哪个最小,直到节点 n n n结束
算法实现
#include输入:
4 6
1 2 1
1 3 2
3 4 3
2 3 1
2 4 4
3 1 1
输出:
2
1 3
训练3:骑士的旅程
题目描述
骑士决定环游世界,其移动方式如下图。骑士的世界是他生活的棋盘,棋盘面积比普通的 8 × 8 8 \times 8 8×8棋盘小,但它任然是长方形的。你能帮助这个骑士做出旅行计划吗?找到一条道路。骑士每次都进入一个方格,可以在棋盘的任意方格上开始和结束。
输入:输入的第1行包含一个正整数 T T T,表示测试用例的数量。每个测试用例的第1行都包含两个 m m m和 n ( 1 ≤ m × n ≤ 26 ) n(1 \leq m \times n \leq 26) n(1≤m×n≤26),表示 m × n m \times n m×n的棋盘,对行数字标识( 1 ∼ m 1 \sim m 1∼m),对列用大写字母标识( A ∼ Z A \sim Z A∼Z)。
输出:每个测试用例的输出都以一个包含“$Scenario #i: $”的行开头,其中i是从1开始的测试用例编号。然后单行输出按字典顺序排列的第1条路径,该路径访问棋盘的所有方块。应通过连接访问方块的名称输出路径,每个方块的名称都由一个大写字母后跟一个数字组成。如果不存在这样的路径,则应该在一行上输出“impossible”。在测试用例之间有个空行。
算法设计
- 棋盘是 m m m行、 n n n列的,对行数字标识,对列用大写字母标识,但输出时先输出大写字母,然后输出数字。因此写程序时,可以把棋盘翻转一下,将其看作 n n n行、 m m m列的,这样就可以先行后列地进行输出了。
- 从(1,1)开始,沿8个方向进行深度优先搜索,判断是否可行,如果可行,则记录搜索步数,从当前节点出发继续进行深度优先搜索。
- 当步数达 n × m n \times m n×m时,说明找到一条路径,输出该路径。
算法实现
#include输入:
3
1 1
2 3
4 3
输出:
Scenario #1:
A1
Scenario #2:
impossible
Scenario #3:
A1B3C1A2B4C2A3B1C3A4B2C4
训练4:抓住那头牛
题目描述
约翰希望立即抓住逃亡的牛。当前约翰在节点 N N N,牛在节点 K ( 0 ≤ N , K ≤ 100000 ) K(0 \leq N,K \leq 100000) K(0≤N,K≤100000)时,他们在同一条线上。约翰有两种交通方式:步行和乘车。如果牛不知道有人在追赶自己,原地不动,那么约翰需要多长时间才能抓住牛?
- 步行:约翰可以在一分钟内从任意节点 X X X移动到节点 X − 1 X-1 X−1或 X + 1 X+1 X+1。
- 乘车:约翰可以在一分钟内从任意节点X移动到节点 2 × X 2 \times X 2×X。
输入:两个整数 N N N和 K K K。
输出:单行输出约翰抓住牛所需的最短时间(以分钟为单位)。
算法设计
深度优先搜索
- 如果 n = 0 n = 0 n=0,则先走1步到1, n = 1 n = 1 n=1,否则无法乘车,因为0的两倍还是0。
- 进行深度优先搜索,
dfs(t)表示求解约翰从初始位置 n n n到达位置 t t t的最小步数。
- 如果 t ≤ n t \leq n t≤n,因为不可以向后乘车,只能一步一步地后退,则需要 n − t n-t n−t步。
- 如果 t t t为偶数,则比较从 t / 2 t/2 t/2向前乘车到 t t t、从n一步步向前走到 t t t,采用哪种方案使得步数最少,取最小值。第1种方案的步数为从初始位置到达 t / 2 t/2 t/2的步数
dfs(t/2)加上1次乘车所需步数,第2种方案的步数为 t − n t-n t−n。 - 如果 t t t为奇数,则比较从 t − 1 t-1 t−1向前1步到 t t t(步数为
dfs(t-1)+1)、从 t + 1 t+1 t+1向后1步到 t t t(步数为dfs(t+1)+1),采用哪种方案使得步数最少,取最小值。
算法实现
#include输入:
5 17
输出:
4
广度优先搜索
- 如果 k ≤ n k \leq n k≤n,因为不可以向后乘车,只能一步一步地后退,则需要 n − k n-k n−k步,否则执行步骤2。
- 从当先节点出发进行广度优先搜索,每个节点都可以扩展3个位置,判断该位置是否为牛的位置,如果是,则返回走过的步数;否则,判断位置是否有效(未超界且未访问),如果是,则将步数加1,并将位置入队。
- 如果队列不空,则一直进行广度优先搜索,直到找到牛的位置。
算法实现
#include输入:
5 17
输出:
4
图的连通性
连通性相关知识
无向图的连通分量
- 在无向图中,如果从节点v_{i}到节点v_{j}有路径,则称节点v_{i}和节点v_{j}是连通的。
- 无向图的极大连通子图被称为图的连通分量。
- 非连通图有两个以上的连通分量
有向图的强连通分量
- 在有向图中,如果图中的任意两个节点从v_{i}到v_{j}都有路径,且从v_{j}到v_{i}也有路径,则称图为强连通图。
- 有向图的极大强连通子图被称为图的强连通分量。
无向图的桥与割点
- 如果取到无向连通图中的一条边后,图分裂为两个不相连的子图,那么那条边为图的桥或割边
- 在去掉无向连通图中的一个点v及与v关联的所有边后,图分裂为两个或两个以上不相连的子图,那么v为图的割点。
- 删除边时,只把该边删除即可,不要删除与边关联的点;而删除点时,要删除该点及其关联的所有边。
- 割点与桥的关系:有割点不一定有桥,有乔一定有割点;桥一定是割点依附的边。
无向图的双连通
- 如果在无向图中不存在桥,则称为它为边双连通图。
- 在边双连通图中,在任意两个点之间都存在两条及以上路径,且路径上的边互不重复。
- 如果在无向图中不存在割点,则称它为点双连通图。
- 无向图的极大边双连通子图被称为边双连通分量。
Tarjan算法
- 时间戳:
dfn[u]表示节点 u u u深度优先遍历的序号 - 追溯点:
low[u]表示节点 u u u或 u u u的子孙能通过非父子边追溯到的dfn最小的节点序号,即回到最早的过去。
无向图的桥
- 桥判定法则:无向边 x x x- y y y是桥,当且仅当在搜索树上存在 x x x的一个子节点y时满足 l o w [ y ] > d f n [ x ] low[y] > dfn[x] low[y]>dfn[x]。
#include输入:
7 7
1 2
2 3
3 5
5 6
6 4
4 1
5 7
输出:
5—7是桥
无向图的割点
- 割点判断法则:若 x x x不是根节点,则 x x x是割点,当且仅当在搜索树上存在 x x x的一个子节点 y y y,满足 l o w [ y ] ≥ d f n [ x ] low[y] \geq dfn[x] low[y]≥dfn[x];若 x x x是根结点,则 x x x是割点,当且仅当在搜索树在至少两个子节点,满足该条件。也就是说,如果不是根,且孩子的 l o w low low值大于或等于自己的 d f n dfn dfn值,则该节点就是割点
#include输入:
7 7
1 2
2 3
3 5
5 6
6 4
4 1
5 7
输出:
5是割点
有向图的强连通分量
- 深度优先遍历节点,在第1次访问节点 x x x时,将 x x x入栈,且
dfn[x] = low[x] = ++num。 - 遍历 x x x的所有邻接点 y y y
- 若 y y y没被访问,则递归访问 y y y,返回时更新
low[x] = min(low[x],low[y])。 - 若 y y y已被访问且在栈中,则令
low[x] = min(low[x],dfn[y])。
- 在 x x x回溯之前,如果判断
low[x] = dfn[x],则从栈中不断弹出节点,直到 x x x出栈时停止。弹出的节点就是一个连通分量。
#include输入:
5 8
1 3
1 2
3 5
3 4
3 2
4 5
4 1
5 1
输出:
low[1]=1 dfn[1]=1
low[2]=2 dfn[2]=2
强连通分量:2
update1:low[1]=1
low[3]=3 dfn[3]=3
low[4]=4 dfn[4]=4
update2:low[4]=1
low[5]=5 dfn[5]=5
update2:low[5]=1
update1:low[4]=1
update1:low[3]=1
update2:low[3]=1
update1:low[1]=1
强连通分量:5 4 3 1
#训练1:电话网络
题目描述
电话公司正在建立一个新的电话网络,每个地方都有一个电话交换机(编号为 1 ∼ N 1 \sim N 1∼N)。线路是双向的,并且总是将两个地方连接在一起,在每个地方,线路都终止于电话交换机。从每个地方都可以通过线路到达其他地方,但不需要直接连接,可以进行多次交换。有时在某个地方发生故障,会导致交换机无法运行。在这种情况下,除了无法到达失败的地方,还可以导致其他地方无法相互连接。这个地方(发生故障的地方)是至关重要的,请写程序来查找所有关键位置的数量。
输入:输入包含多个测试用例,每个测试用例都描述一个网络。每个测试用例的第1行都是 N ( N < 100 ) N(N < 100) N(N<100)。接下来最多 N N N行中的每一行都包含一个地点的编号,后面是该地方可以直达的地点的编号,每个测试用例都以一条仅包含0的行结束。 N = 0 N = 0 N=0时输入结束,不处理。
输出:对每个测试用例,都单行输出关键位置的数量。
算法设计
- 利用Tarjan算法求割点。
#include输入:
5
5 1 2 3 4
0
6
2 1 3
5 4 6 2
0
0
输出:
1
2
训练2:道路建设
题目描述
热带岛屿负责道路的人们想修理和升级岛上各个旅游景点之间的道路。道路本身也很有趣,它们从不在交叉路口汇合,而是通过桥梁和隧道相互交叉或相互通过。通过这种方式,每条道路都在两个特定的旅游景点之间运行,这样游客就不会迷失。不幸的是,当建筑公司在特定道路上工作时,该道路在任何一个方向都无法使用。如果在两个旅游景点之间无法同行,则即使建筑公司在任何特定时间只在一条道路上工作,也可能出现问题。
道路部门已经决定在景点之间建造新的道路,以便在最终配置中,如果任何一条道路正在建设,则仍然可以使用剩余的道路在任意两个旅游景点之间旅行。我们的任务是找到所需的最少数量的新道路。
输入:输入的第1行将包括正整数 n n n( 3 ≤ n ≤ 1000 3 \leq n \leq 1000 3≤n≤1000)和 r r r( 2 ≤ r ≤ 1000 2 \leq r \leq 1000 2≤r≤1000),其中 n n n是旅游景点的数量, r r r是道路的数量。旅游景点的编号为 1 ∼ n 1 \sim n 1∼n。以下 r r r行中的每一行都将由两个整数 v v v和 w w w组成,表示在 v v v和 w w w的景点之间存在道路。请注意,道路是双向的,在任何两个旅游景点之间最多有一条道路。此外,在目前的配置中,可以在任意两个旅游景点之间旅行。
输出:单行输出需要添加的最少道路数量。
算法设计
- 先运行Tarjan算法,求解边双连通分量。
- 缩点。检查每个节点u的每个,邻接点v,若
low[u]!=low[v],则将这个连通分量点low[u]的度加1,degree[low[u]]++,同一个连通分量中的节点low[]相同。 - 统计度为1的点的个数为
leaf,添加的最少边数为(leaf + 1)/2。
算法实现
#include输入:
10 12
1 2
1 3
1 4
2 5
2 6
5 6
3 7
3 8
7 8
4 9
4 10
9 10
3 3
1 2
2 3
1 3
输出:
2
0