[图神经网络]空间关系感知关系网络(SGRN)-论文解读
原论文标题:Spatial-aware Graph Relation Network for Large-scale Object Detection
论文地址为:Spatial-aware Graph Relation Network for Large-scale Object Detection http://openaccess.thecvf.com/content_CVPR_2019/papers/Xu_Spatial-Aware_Graph_Relation_Network_for_Large-Scale_Object_Detection_CVPR_2019_paper.pdf
http://openaccess.thecvf.com/content_CVPR_2019/papers/Xu_Spatial-Aware_Graph_Relation_Network_for_Large-Scale_Object_Detection_CVPR_2019_paper.pdf
代码地址为:
SGRNhttps://github.com/simblah/SGRN_torch
一、将GNN应用于目标检测
这篇论文描述了一个由GCN加强的Faster R-CNN网络,通过自适应地发现和合并关键的语义和空间关系来增强CNN在面对大量长尾数据分布和大量混淆类别时的性能。在这篇论文之前,有两种方法解决这个问题:
1.手工图
即采用传统的图机器学习的方法针对数据集进行关系图的构建,但是其结构相对固定,严重依赖属性和关系的注释。
![[图神经网络]空间关系感知关系网络(SGRN)-论文解读_第1张图片](http://img.e-com-net.com/image/info8/917ff0a4fb4f43bea490611158516229.jpg)
2.从视觉特征隐式学习
相较于上述方法,由于其采用了机器学习,使得算法泛用性更高。但由于全图都是连通的,会有很多冗余连接和噪声,从而干扰模型的结果。
![[图神经网络]空间关系感知关系网络(SGRN)-论文解读_第2张图片](http://img.e-com-net.com/image/info8/dbcfa6144ac748b292d3071c961ccf37.jpg)
针对上面两种方法存在的问题,本文的作者提出了SGRN网络,其由稀疏图学习器模块、空间感知卷积模块两个部分构成。
在此系统中,建议区域被定义为图节点,而不是构建类别到类别图。从而可以减少了不必要的负区域(背景)开销。接下来,由可学习的空间高斯核驱动的空间感知的图卷积被执行以传播和增强区域上下文表示。
![[图神经网络]空间关系感知关系网络(SGRN)-论文解读_第3张图片](http://img.e-com-net.com/image/info8/d0fff5feca144939a76e70c619e5834c.jpg)
SGRN支持具有在学习图的区域上进行自适应图推理(不平衡类问题可以通过共享权重的方法来解决)。一些严重遮挡/类别模糊/尺寸微小的区域也可以通过这种方法来补救。
二、网络结构
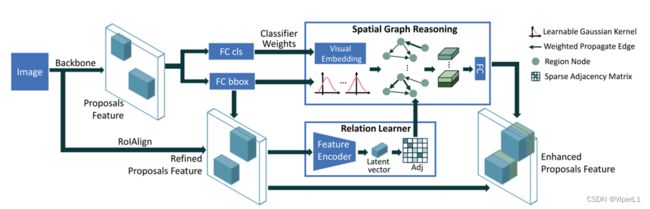
如上图所示,其相较于传统Faster R-CNN而言,将分类器和线性回归器模块增加了SGRN模块。同时在文中这个模块也被描述为可以很容易的叠加在诸如SSD、YOLO等现行的目标识别网络中。
SGRN网络会将区域关系编码为一张无向图G=(N,E)。关系图学习器会从视觉特征中学习可解释的稀疏邻接矩阵(该矩阵仅保留用于识别对象的最相关连接)。然后将前一层的权值集合起来软映射到各个区域,成为每个区域的视觉嵌入。空间感知的图推理模块会根据稀疏邻接矩阵和高斯核,进化和传播不同区域的视觉嵌入。然后将空间图推理模块的输出连接到原始区域特征以改进分类和定位。
1.关系图学习器
关系图学习器的目的是产生一个建议区域和检测目标之间的关系图。无向关系图标记为:![]() ,其中N表示节点集,
,其中N表示节点集, 表示边集。通过学习边集的邻接矩阵
表示边集。通过学习边集的邻接矩阵![]() 来确定节点的邻域。
来确定节点的邻域。
形式上,从建议区域提取视觉特征的D维向量![]() (
(![]() 特征向量
特征向量 属于尺寸为D的矩阵
属于尺寸为D的矩阵 ),将其通过非线性函数
),将其通过非线性函数 <本文使用ReLu>映射在空间
<本文使用ReLu>映射在空间 上。记作:
上。记作:
![]()
图的邻接矩阵可以记作![]() ,其中的边向量可以记作
,其中的边向量可以记作![]()
负样本问题
实际生成中,如果不加任何限制,这张图会将邻域中大量的负样本(背景)嵌入图中,故需要对矩阵的稀疏性进行限制。本文通过对每个建议区域 i ,仅保留邻接矩阵的嵌入 行(前t个最大值)向量,记作:
行(前t个最大值)向量,记作:
![]()
语义嵌入
为每个类别创建一个高级语义视觉嵌入(可以为特征向量提供额外的语义信息,进而缓解严重遮挡和模糊的问题)
可以通过从分类器中提取权重来实现(分类器的权重是所有图的激活特征,其中就很自然的包含语义信息)。权重可以表述为:![]() ;C为类别数,D为视觉维度。
;C为类别数,D为视觉维度。
映射的方式可以通过软映射,形式为:![]() :
:![]() ;转换为矩阵形式为
;转换为矩阵形式为![]()
2.空间感知推理模块
基于已学到的关系图中(节点集 和边集),采用边引导的图推理学习新的目标表示。
和边集),采用边引导的图推理学习新的目标表示。
为了捕获成对的空间信息,使用成对的伪坐标![]() 来描述位置,本文中使用极函数
来描述位置,本文中使用极函数![]() 来描述,极函数中的两个元素分别表示两个点之间的长度信息和角度信息。计算公式为:
来描述,极函数中的两个元素分别表示两个点之间的长度信息和角度信息。计算公式为: ;
;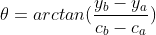
对于相邻节点的影响和传播权重,通过k阶高斯核函数来描述,其公式记作:
![]()
其中k阶高斯核函数表述为:![]()
上式中,![]() 和k
和k![]() 是可学习的2x1均值向量和2x2协方差矩阵。
是可学习的2x1均值向量和2x2协方差矩阵。![]() 即为区域的空间信息的编码。模块的结构如下:
即为区域的空间信息的编码。模块的结构如下:
