【无标题】
目录
阶段2:从网页搭建入门Java Web
1:前端基础之HTML与CSS
2:前端基础之JavaScript与综合案例
3:Java Web基础
第一节:XML是什么
XML是什么
XML与HTML的比较:xml没有预定义的标签
XML的用途
XML文档结构
XML声明
我的第一份XML
XML标签书写规则
处理理特殊字符
XML支持五种实体引用
CDATA标签:不做xml解析,原意输出
XML语义约束
Document Type Definition
DTD定义节点
DTD定义节点数量
XML引用DTD文件
创建DTD文件
XML Schem
引入Schem:在根节点引入
DOM文档对象模型
Dom4j
利用Dom4j遍历XML
利用Dom4j更新XML
XPath路径表达式
XPath基本表达式
XPath基本表达式案例
XPath谓语表达式
编辑
XPath实验室
Jaxen介绍
4:常用功能与过滤器
第1节 JSON入门
5:监听器与项目实战
阶段1:Java零基础入门
6:常用工具类(下)
第4节 Java输入输出流
File类:isDirectory()、isFile()、exists()、mkdirs()、createNewFile()
package file;
import java.io.File;
import java.io.IOException;
public class FileDemo {
public static void main(String[] args) {
//创建File对象
//File file1=new File("c:\\imooc\\io\\score.txt");
//File file1=new File("c:\\imooc","io\\score.txt");
File file=new File("d:\\imooc");
File file1=new File(file,"io\\score.txt");
//判断是文件还是目录
System.out.println("是否是目录"+file1.isDirectory());
System.out.println("是否是文件"+file1.isFile());
//创建文件
File file2=new File("d:\\imooc\\io");
if(!file2.exists()) {
file2.mkdirs();
}
//创建文件
if(!file1.exists()) {
try {
file1.createNewFile();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
PATH绝对路径和相对路径:isAbsolute(),getAbsolutePath(),f.getPath
绝对路径:是从盘符开始的路径
相对路径:是从当前路径开始的路劲
package file;
import java.io.File;
import java.io.IOException;
public class FileDemo1 {
public static void main(String[] args) {
// File f=new File("c:\\imooc\\java\\thread\\thread.txt");
// System.out.println(f.exists());
File f=new File("thread.txt");
try {
f.createNewFile();
//判断是否是绝对路径
System.out.println(f.isAbsolute());
//获取相对路径,也是file构造函数的路径
System.out.println(f.getPath());
//获取绝对路径
System.out.println(f.getAbsolutePath());
//获取文件名
System.out.println(f.getName());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
字节流
字节输入流InputStream

字节输出流OutputStream
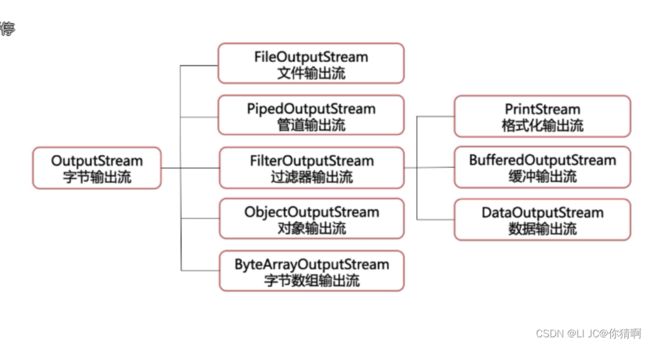
FileInputStream
从文件系统中的某个文件中获得输入字节
用于读取诸如图像数据之类的原始字节流
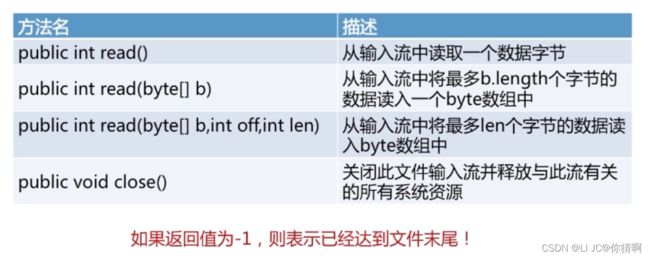
FileInputStream:read(),单个字节转换为char(byte)
package fileInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class FileInputDemo1 {
public static void main(String[] args) {
//创建一个FileInputStream对象
try {
FileInputStream fis=new FileInputStream("imooc.txt");
// int n=fis.read();
int n=0;
// while(n!=-1){
// System.out.print((char)n);
// n=fis.read();
// }
while((n=fis.read())!=-1){
System.out.print((char)n);
}
fis.close();
}catch (FileNotFoundException e) {
e.printStackTrace();
} catch(IOException e){
e.printStackTrace();
}
}
}
FileInputStream:read(byte[] b) 字节数组转换为字符串new String(byte[] b)
package fileInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class FileInputDemo2 {
public static void main(String[] args) {
// 创建一个FileInputStream对象
try {
FileInputStream fis = new FileInputStream("imooc.txt");
byte[] b=new byte[100];
fis.read(b,0,5);
System.out.println(new String(b));
fis.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
FileOutputStream:

FileOutputStream:write(int b),不太适合做字符相关的操作,会存入意想不到的东西,适合做二进制的复制,例如图片
package io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileOutputDemo {
public static void main(String[] args) {
FileOutputStream fos;
FileInputStream fis;
try {
fos = new FileOutputStream("imooc.txt",true);//true表示追加
fis=new FileInputStream("imooc.txt");
fos.write(50);//文件变为2
fos.write('a');
System.out.println(fis.read());
System.out.println((char)fis.read());//读出来又是50
fos.close();
fis.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
FileOutputStream:write(byte[] b,int i , int f)
package io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileOutputDemo1 {
public static void main(String[] args) {
// 文件拷贝
try {
FileInputStream fis=new FileInputStream("happy.gif");
FileOutputStream fos=new FileOutputStream("happycopy.gif");
int n=0;
byte[] b=new byte[1024];
while((n=fis.read(b))!=-1){
fos.write(b,0,n);//标记写入大小,fos.write文件往往会变大
}
fis.close();
fos.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}catch(IOException e){
e.printStackTrace();
}
}
}
字符流
字符输入流Reader

字符输出流Writer 字
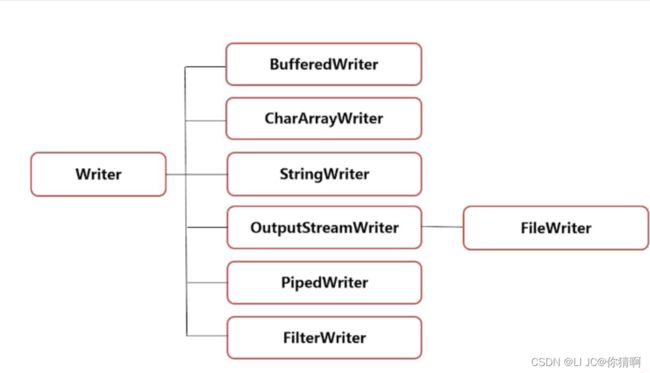
字节字符转换流
InputStreamReader:read()放回字节,read(char[] c)
OutputStreamWriter:flush()
package io;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class ReaderDemo {
public static void main(String[] args) {
try {
FileInputStream fis=new FileInputStream("imooc.txt");
InputStreamReader isr=new InputStreamReader(fis,"GBK");
//可以用FileReader代替上面这两步
BufferedReader br=new BufferedReader(isr);
FileOutputStream fos=new FileOutputStream("imooc1.txt");
OutputStreamWriter osw=new OutputStreamWriter(fos,"GBK");
BufferedWriter bw=new BufferedWriter(osw);
int n=0;
char[] cbuf=new char[10];
// while((n=isr.read())!=-1){
// System.out.print((char)n);//char数组也是通过(char)
// }
// while((n=isr.read(cbuf))!=-1){
// String s=new String(cbuf,0,n);//string类型支持char数组的偏移量
osr.writer(s,0,n)
// System.out.print(s);
// }
while((n=br.read(cbuf))!=-1){
//String s=new String(cbuf,0,n);
bw.write(cbuf, 0, n);
bw.flush();
}
fis.close();
fos.close();
isr.close();
osw.close();
br.close();
bw.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
对象序列化
ObjectInputStream
ObjectOutputStream
步骤:
-创建一个类,继承Serializable接口
-创建对象
-将对象写入文件
-从文件读取对象信
package io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class GoodsTest {
public static void main(String[] args) {
// 定义Goods类的对象
Goods goods1 = new Goods("gd001", "电脑", 3000);
try {
FileOutputStream fos = new FileOutputStream("imooc.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
FileInputStream fis = new FileInputStream("imooc.txt");
ObjectInputStream ois = new ObjectInputStream(fis);
// 将Goods对象信息写入文件
oos.writeObject(goods1);
oos.writeBoolean(true);
oos.flush();
// 读对象信息
try {
Goods goods = (Goods) ois.readObject();
System.out.println(goods);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(ois.readBoolean());
fos.close();
oos.close();
fis.close();
ois.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}

阶段2:从网页搭建入门Java Web
1:前端基础之HTML与CSS
2:前端基础之JavaScript与综合案例
3:Java Web基础
第一节:XML是什么
XML是什么
XML的全称是EXtensible Markup Language,可扩展标记语言
编写XML就是编写标签,与HTML非常类似,扩展名.xml
良好的人机可读性
hr.xml
张三
31
178
XML与HTML的比较:xml没有预定义的标签
html:
首页
xml:
三年级
1班
三年级
2班
XML的用途

XML文档结构
第一行必须是XML声明。
有且只有一个根节点。
XML标签的书写规则与HTML相同。
XML声明
XML声明说明XML文档的基本信息,包括版本号与字符集,写在 XML第一行。
version 代表版本号1.0/1.1
encoding UTF-8设置字符集,用于支持中文我的第一份XML
李铁柱
37
3600
人事部
XX大厦-B105
林海
50
7000
财务部
XX大厦-B106
安娜
24
4600
人事部
XX大厦-B105
张晓宇
29
3000
后勤部
XX大厦-B108
赵子轩
19
1500
后勤部
XX大厦-B108
张晓璇
20
1700
后勤部
XX大厦-B108
张檬
43
8700
会计部
XX大厦-B103
李梅
33
8700
工程部
XX大厦-B104
张三
31
4000
会计部
XX大厦-B103
李四
23
3000
工程部
XX大厦-B104
XML标签书写规则
合法的标签名
适当的注释与缩进
合理使用属性
特殊字符与CDATA标签
有序的子元素
处理理特殊字符
标签体中,出现"<",">"特殊字符,会破坏文档结构。 处理特殊字符
解决方案1:使用实体引用。
解决方案2:使用CDATA标签。
无效的XML:
1+4<3是否正确?
3+5>8是否正确?
XML支持五种实体引用

CDATA标签:不做xml解析,原意输出
CDATA 指的是不应由 XML 解析器进行解析 的文本数据 CDATA标签
从"<[!CDATA["开始,到"]]>"结束
首页






