DDD专栏2:DDD实战:从支付功能的优化说起
02、DDD实战:从支付功能的优化说起
我们前面花了不少篇幅来分析系统老化的问题,也提出了DDD可以有效的防止系统老化。并且给大家简单的介绍了一下DDD的一些思想。
那接下来,应该就要学习DDD的抽象概念体系了。这会是一个痛苦的过程,所以这一章节,我们先不去深入DDD的概念细节。我们就会以程序员最为直观的方式,代码,来对DDD做一次近距离的接触。在这一章节中,将会以一个转账功能为切入点,让你能够对DDD先有个直观的认识,为我们后面真正去理解DDD的精髓打下一个基础。但是,希望你们明白,我们这个实例仅仅是作为演示,远不足以描述DDD的庞大理论体系。
同时,也希望你能够从今天的演示中理解到, DDD并不是一个不食人间烟火的秘密武器,他只是对于开发经验的抽象与提纯。因此,不要试图将DDD与我们以往的开发经验完全彻底的隔离开,他们的很多思想其实是一脉相承,有内在关联的。在JAVA领域如此,在其他领域依然如此。
业务案例说明
我们先来看一个简单的需求案例:用户购买商品后,向商家进行支付。
当软件团队接受这样的需求时,团队当中的产品设计人员就会尝试对这个业务进行动作拆解,最终确定出如下的步骤:
1、 从数据库中查出用户和商户的账户信息。
2、调用风控系统的微服务,进行风险评估。
3、实现转入转出操作,计算双方的金额变化,保存到数据库。
4、发送交易情况给kafka,进行后续审计和风控。
于是,开发人员使用MVC架构很快的完成了如下的伪代码:
public class PaymentController{
private PayService payService;
public Result pay(String merchantAccount,BigDecimal amount){
Long userId = (Long) session.getAttribute("userId");
return payService.pay(userId, merchantAccount, amount);
}
}
public class PayServiceImpl extends PayService{
private AccountDao accountDao;//操作数据库
private KafkaTemplate<String, String> kafkaTemplate;//操作kafka
private RiskCheckService riskCheckService;//风控微服务接口
public Result pay(Long userId,String merchantAccount,BigDecimal amount){
// 1. 从数据库读取数据
AccountDO clientDO = accountDAO.selectByUserId(userId);
AccountDO merchantDO =
accountDAO.selectByAccountNumber(merchantAccount);
// 2. 业务参数校验
if (amount>(clientDO.getAvailable()) {
throw new NoMoneyException();
}
// 3. 调用风控微服务
RiskCode riskCode = riskCheckService.checkPayment(...);
// 4. 检查交易合法性
if("0000"!= riskCode){
throw new InvalideOperException();
}
// 5. 计算新值,并且更新字段
BigDecimal newSource = clientDO.getAvailable().subtract(amount);
BigDecimal newTarget = merchantDO.getAvailable().add(amount);
clientDO.setAvailable(newSource);
merchantDO.setAvailable(newTarget);
// 6. 更新到数据库
accountDAO.update(clientDO);
accountDAO.update(merchantDO);
// 7. 发送审计消息
String message = sourceUserId + "," + targetAccountNumber + "," + targetAmount;
kafkaTemplate.send(TOPIC_AUDIT_LOG, message);
return Result.SUCCESS;
}
}
我们可以看到,在一段业务代码中包含了参数校验、数据读取、业务计算、调用外部服务、发送消息等多种逻辑。在这个案例中都写到了同一个方法中,我们在实际工作中,绝大部分代码都或多或少的类似于这样的结构。即使经常会被拆分成多个子方法,但是实际效果是一样的。这样的代码样式,就被叫做事务脚本(Transaction Script)。这种事务脚本的代码在功能上没有什么问题,但是长久来看,他就给系统带来了非常多老化的风险。
问题1:代码层面的软件老化风险
首先从代码层面来看,这段代码在以后的迭代中会不断的膨胀。
- 数据来源被固定:AccountDO类是一个纯数据结构,映射了数据库中的一个表。如果表结构改了,比如表名改了,字段改了,或者表要做Sharding分库分表,都会导致数据格式不兼容。
- 业务逻辑无法复用:数据格式不兼容的问题会导致整个业务逻辑都无法复用。每个用例中都有大量的if-else分支,以后新加入业务逻辑,可能又要添加新的if-else分支。而这众多的逻辑分支会让分析代码变得非常难以理解。
- 业务逻辑与数据存储相互依赖:当业务逻辑越来越复杂时,新加入的逻辑可能要调整表结构或者消息的格式。而这些调整都会导致原有的逻辑需要跟着一起动。甚至可能出现一个新功能的增加导致所有原有功能都需要重构的情况。
在这种事务脚本式的架构下,一般做第一个需求都会非常快。但是往后迭代的过程中,代码会不断膨胀,做一个需求需要的时间也会呈指数级上升。绝大部分时间都需要花费在老功能的重构和兼容上,最终拖慢整个项目的创新速度,直到最后不得不推翻重构。
问题2:架构层面的软件老化风险
对于这样的事务脚本,代码的外部依赖非常严重。当任何一个依赖发生变化时,这一段代码可能都要进行大改。
-
数据结构变更:这里面的AccountDO类是一个纯数据结构,映射了数据库中的一个表。从长远来看,表的结构很有可能是会改变的,甚至存储数据的介质也可能会变,例如从Oracle转向MySQL ,从关系型数据库转向NewSQL、NoSQL甚至是大数据体系。
-
JDBC依赖调整:AccountDao依赖于具体的JDBC实现。如果未来更换ORM体系,迁移成本会非常大。例如从Hibernate转为MyBatis,或者转向SpringData。
-
第三方服务变更:这里面的RiskCheckService是由风控系统提供的一个微服务接口,那未来如果微服务系统做了结构调整,这一段业务流程也需要做大量调整,成本会非常大。
-
MQ中间件调整:今天我们用kafka发消息,那未来如果改用RocketMQ呢?如果消息序列化的方式要从String改成Binary呢?
这样的案例中,每个组件的变化都足以导致整个业务逻辑的变更。而当整个项目不断变得复杂,基本上每一次功能的更迭都会需要花费大量的时间用来做各种库升级,解决jar包冲突。最终这个应用就会演变成一个不敢升级,不敢写新功能,并且随时会爆发的炸弹。
问题3 随之而来的实施及测试问题
这样强依赖的代码,还会带来随之而来的一系列测试问题:
设施搭建困难:代码中依赖了好几个外部组件,一个测试用例需要确保所有依赖都能跑起来,这在项目早期是非常困难的。
测试用例覆盖困难:这样一段由多个子步骤耦合而成的事务脚本,要完整覆盖到所有的情况,所需要的测试用例会呈指数级增长。功能组件不够独立,造成单元测试困难,而一个小小的需求变更,测试人员就需要进行完整的回归测试,这样才能覆盖到所有的情况。这种情况通常就是给线上bug埋下的伏笔。
问题总结:
这样一段我们经常写的代码其实违背了好几个软件设计的原则:
- 单一职责原则:要求每一个对象/类应该只有一个变更的原因。但是这个案例中,导致变更的原因非常多。
- 依赖翻转原则:要求在代码中依赖的只是抽象,而不是具体的实现。这个案例中,RiskCheckService虽然只是一个接口,但是与他对应的是整个具体的风控系统,也算是依赖了实现。
- 开放封闭原则:要求整个代码对扩展开放,而对修改封闭。在这个案例中,金额的计算应该属于可被修改的代码,以后随时可能加上一些收取手续费之类的逻辑。所以该逻辑应该被封装成不可修改的计算类。
支付功能重构实战
那要如何按照DDD的思想来对这个功能进行重构呢?我们先画一张流程图,来描述这一段代码:
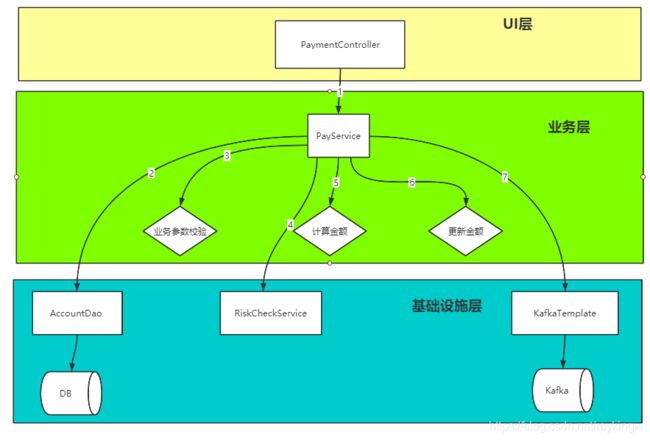
在我们现在的三层结构中,上层对于下层有直接的依赖关系,我们需要对这张图上的每个节点做抽象和整理,来降低转账业务与外部依赖的耦合度。将引起业务代码变化的因素一点一点的隔离开来。
在我们进行代码改造的过程中,会逐渐的接触到一些DDD中的概念,这会给你带来一些困惑。但是没关系,这些概念在后面的章节当中都会一点点的给你讲明白。在这里,你只需要跟上这种隔离变化的思路。
1、抽象数据存储层
这一步常见的操作是加一个数据接口层,降低系统对数据库的直接依赖。
1-1、改造Account实体类:
public class Account{
private Long id;
private Long accountNumber;
private BigDecimal available;
public void withdraw(BigDecimal money){
//转入操作
available = available + money;
}
public void deposit(BigDecimal money){
//转出操作
if(available < money){
throws new InsufficientMoneyException();
}
available = available - money;
}
}
在这一步改造过程当中:
原有的AccountDO只是单纯的和数据库表的映射,只有数据没有行为,被称为贫血模型。而新增的Account就是基于领域逻辑的实体类(Entity)。他的字段和数据库存储不需要有必然的联系。Entity中包含数据,同时也包含完全内敛的业务行为,称为充血模式。
关于贫血模型与充血模型的区别,在后面的章节会再继续进行详细讲解。但是从这里,能够看到一个最简单的好处,就是这个Account实体有哪些行为,已经可以一目了然了,而不用再去从Service中梳理。
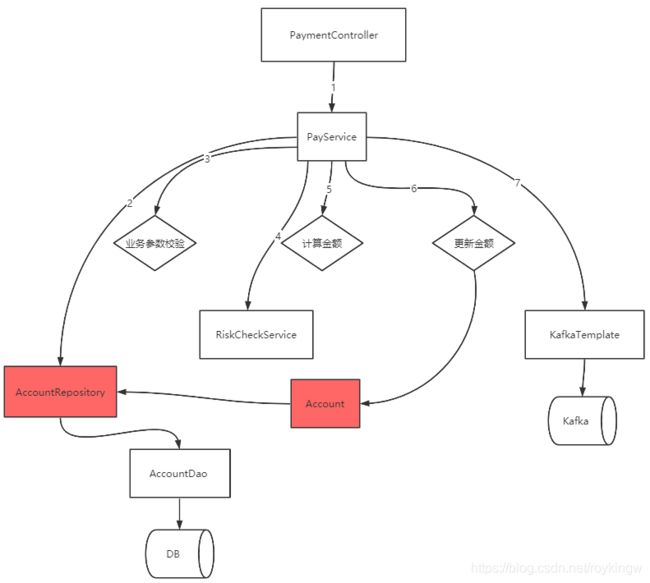
1-2、新建对象存储接口类
完成实体对象的抽取后,还需要避免业务逻辑代码和数据库的直接耦合。
public interface AccountRepository {
.......
}
public class AccountRepositoryImpl implements AccountRepository {
@Autowired
private AccountDao accountDAO;
@Autowired
private AccountBuilder accountBuilder;
@Override
public Account find(Long id) {
AccountDO accountDO = accountDAO.selectById(id);
return accountBuilder.toAccount(accountDO);
}
@Override
public Account find(Long accountNumber) {
AccountDO accountDO = accountDAO.selectByAccountNumber(accountNumber);
return accountBuilder.toAccount(accountDO);
}
@Override
public Account save(Account account) {
AccountDO accountDO = accountBuilder.fromAccount(account);
if (accountDO.getId() == null) {
accountDAO.insert(accountDO);
} else {
accountDAO.update(accountDO);
}
return accountBuilder.toAccount(accountDO);
}
在这一步的改造过程当中:
-
DAO对应的是一个特定的数据库类型的操作,相当于SQL的封装。所有操作的对象都应该是DO类,所有的接口都可以根据数据库实现的不同而改变。
-
Repository对应的是Entity对象读取存储的抽象,在领域模型中称为仓库(Repository)。在接口层面做统一,不关注底层实现。他的具体实现类都通过调用DAO实现各种操作,并通过工厂对象实现DO与领域实体的转化。
通过抽象出仓库,改变了业务代码的思维方式,让业务逻辑不再需要面向数据库编程,而是面向实体编程。他作为一个接口类,也比较容易通过Mock方式造数据进行测试。
于是,我们的代码图变成了这样:
2、抽象第三方服务
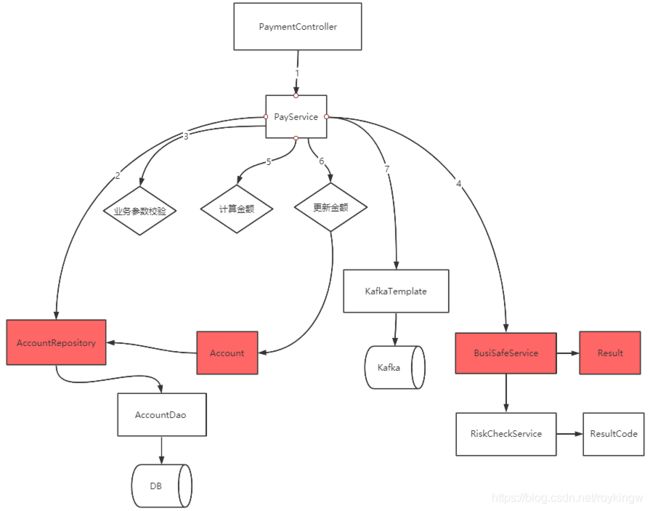
类似于数据库的抽象,所有第三方的服务也需要通过接口来进行隔离,以防止第三方服务状态不可控,入参出参强耦合的问题。例如,在这个例子中,针对交易安全,抽象出一个BusiSafeService的服务。
public interface BusiSafeService{
.......
}
public class BusiSafeServiceImpl implements BusiSafeService{
@Autowired
private RiskChkService riskChkService;
public Result checkBusi(Long userId,Long mechantAccount,BigDecimal money){
//参数封装
RiskCode riskCode = riskCheckService.checkPayment(...);
if("0000".equals(reskCode.getCode()){
return Result.SUCCESS;
}
return Result.REJECT;
}
}
很多时候我们会去依赖其他的外部系统,而被依赖的系统可能包含不合理的数据结果、API、协议或者技术实现。如果对外部系统强依赖,会导致我们的系统被"腐蚀"。这时候,适当的加入一个接口层,能够有效隔离外部依赖和内部逻辑,无论外部如何变更,内部代码可以尽可能的保持稳定。这种常见的设计模式叫做Anti-Conrruption Layer(ACL 防腐层)。
防腐层的设计有非常多有效的实现方式。例如,使用适配器模式,可以扩展在不同数据类型之间进行数据转化的逻辑,降低对业务代码的侵入。另外,也可以在防腐层中添加一些对外部调用通用的逻辑,例如缓存、兜底、功能开关等。这些都可以帮助业务代码进行合理的业务抽象。
加入防腐层后,我们的代码就变成了这样:
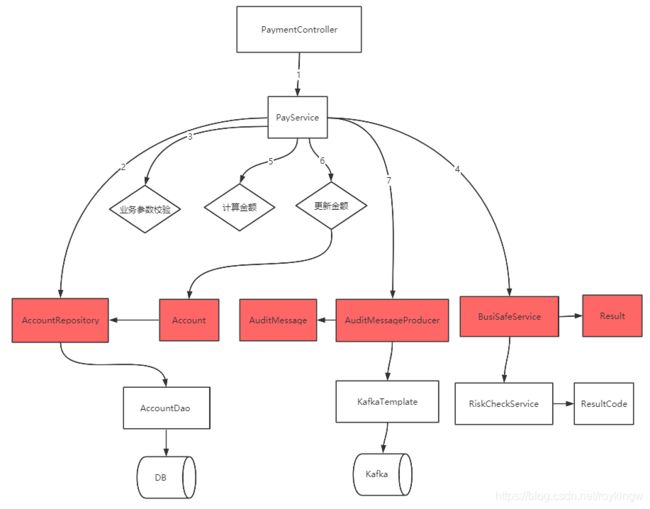
3、抽象中间件
接下来我们对kakfa发送消息这个步骤进行抽象。类似于上一步对第三方服务的抽象,可以在外部依赖的各个中间件之间设计一层ACL,让业务代码不再依赖具体的实现逻辑。这样,不管以后更换中间件或者修改消息传输协议,整个业务代码是不需要动的。
public class AuditMessage{
private Long UserId;
private Long clientAccount;
private Long merchantAccount;
private BigDecimal money;
private Date data;
.....
}
public interface AuditMessageProducer{
....
}
public class AuditMessageProducerImpl implements AuditMessageProducer{
private KafkaTemplate<String,String> kafkaTemplate;
public SendResult send(AuditMessage message){
String messageBody = message.getBody();
kafkaTemplate.send("some topic",messageBody);
return SendResult.SUCCESS;
}
}
这里的结果分析跟上一步抽象第三方服务类似。
经过抽象后,我们的代码就变成了这个样子:
4、重构业务逻辑
我们对外部依赖都一一做了梳理,已经可以减少外部依赖对核心业务的影响了。但是,还有很多业务逻辑跟外部依赖混合的代码。包括业务参数检查、账户余额校验、金额增减等。这些业务逻辑依然会影响核心代码的稳定性。这里,我们提供一种方案按照以下几个步骤来重新梳理业务逻辑。
4-1,抽象实体(Entity)和值对象(Value Object):
核心的业务方法payService.pay(Long userId,String merchantAccount,BigDecimal amount)暴露出来的参数都是不具有类型意义的基础类型,这很容易造成理解偏差。传错参数这样的问题很难在开发时被发现。
所以,我们需要将userId, merchantAccount, amount这些参数值封装成一些具有业务意义的对象,即UserId,AccountNumber, Money这样的几个类,并在这些类中封装一些空判断之类的参数校验。这些类不需要具有唯一ID这样的属性,但是却能很好的表示实体之间的关系。这些类就被称为值对象(Value Object)。这样我们原始代码中的第2步业务参数校验就可以交由值对象去统一完成。这样既让业务代码得到检查,也能避免这些类似的参数校验逻辑被分散到各个业务代码中,对整个系统形成污染。
关于值对象,这里的理解是不够深刻全面的,在后面的专栏会再进行深入分析。但是这些类确实可以理解成是值对象。
4-2:用实体(Entity)封装单对象的状态行为
在我们之前抽象数据存储层时,曾经抽象出了一个Account这样的实体类。那现在,我们可以把原代码中关于金额增减这样的单对象的状态行为封装到实体类中。然后,我们原始代码中的第5步就可以简化为
clientAccount.deposit(money);
targetAccount.withdraw(money);
4-3:用领域服务(Domain Service)封装多实体逻辑
在这个案例里,我们发现两个账户的转入和转出操作实际上应该是一体的,也就是说这种行为应该要被封装到一起。特别是如果考虑到未来这个逻辑可能会发生变化,例如增加扣除手续费的逻辑。那这时这个转账操作放到PayServiec中就不合适了,而在任何一个Account中去做又无法保证操作的一体性。这时,就需要一个新的类去包含跨领域对象的行为。这种对象称为领域服务(Domain Service)。
我们创建一个AccountTransferService的领域服务类
public interface AccountTransferService{
void transfer(Account sourceAccount,Account targetAccount,Money money);
}
public class AccountTransferServiceImpl implements AccountTransferService{
public void transfer(Account sourceAccount,Account targetAccount,Money money){
sourceAccount.deposit(money);
targetAccount.withdraw(money);
}
}
这样,原始业务代码中的6和7步骤简化成了一行:
accontTransferService.transfer(clientAccount,merchantAccount,money)
整体重构后的业务代码:
public class PaymentController{
private PayService payService;
public Result pay(String merchantAccount,BigDecimal amount){
Long userId = (Long) session.getAttribute("userId");
return payService.pay(userId, merchantAccount, amount);
}
}
public class PayServiceImpl extends PayService{
private AccountRepository accountRepository;
private AuditMessageProducer auditMessageProducer;
private BusiSafeService busiSafeService;
private AccountTransferService accountTransferService;
public Result pay(Long userId,String merchantAccount,BigDecimal amount){
// 参数校验
Money money = new Money(amount);
UserId clientId = new UserId(userId);
AccountNumber merchantNumber = new AccountNumber(merchantAccount);
// 读数据
Account clientAccount = accountRepository.find(clientId);
Account merAccount = accountRepository.find(merchantNumber);
// 交易检查
Result preCheck = busiSafeService。checkBusi(clientAccount,merAccount,money);
if(preCheck != Result.SUCCESS){
return Result.REJECT;
}
// 业务逻辑
accountTransferService.transfer(clientAccount,merAccount,money);
// 保存数据
accountRepository.save(clientAccount);
accountRepository.save(merAccount);
// 发送审计消息
AuditMessage message = new AuditMessage(clientAccount, merAccount,money);
auditMessageProducer.send(message);
return Result.SUCCESS;
}
}
经过重构后的代码有以下几个特征:
-
业务逻辑清晰,数据流转与业务逻辑完全分离。
-
Entity,ValueObject,DomainService 这些之前提到的对象都是完全独立的,没有外部依赖,却包含了所有核心业务逻辑,可以单独进行测试。他们共同构成了一个领域(Domain)
-
原有的PayService不再包含任何计算逻辑,仅仅作为组件编排
然后我们重新梳理下业务代码,整体就成了这样:
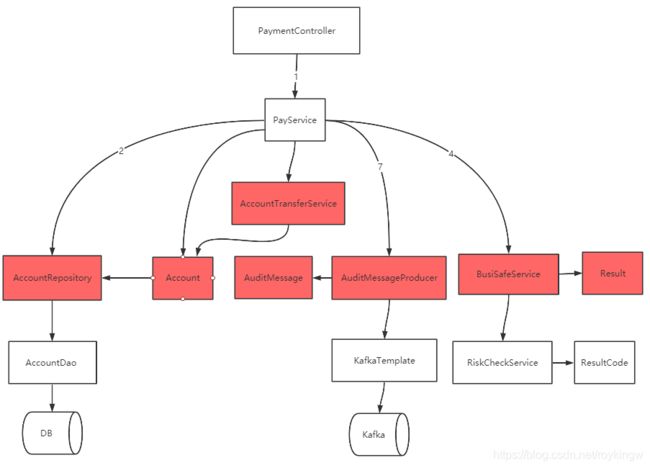
然后我们把这个图重新编排一下,就变成了这样:

这时候我们再来看整个应用的依赖关系:
- 最底层不再是数据库,而是实体(Entity),值对象(ValueObject),领域服务(Domain Service)。这些对象都不依赖任何外部服务和框架。这些对象可以打包成一个领域层(Domain Layer)。领域层没有任何外部依赖关系。
- 原有的Service层,经过重新编排后,只依赖于一些抽象出来的防腐层(ACL)和仓库工厂(Repository)。他们的具体实现都是通过依赖注入进来的。他们一起负责整个组件的编排,这样就可以把他们打包成一个应用层(Application Layer)。应用层依赖领域层,但是不依赖具体实现。
- 最后是一些与外部依赖打交道的组件。这些组件的实现通常依赖外部具体的技术实现和框架,可以统称为基础设施层(Infrastructure Layer)。
总结
这样,我们对一个基于MVC的事务脚本经过重新编排后,开发业务时,可以优先开发领域层的业务逻辑,然后再写应用层的服务编排,而具体的外部依赖与具体实现可以最后再完成。整体就形成了一种以领域优先的架构形式。最后,我们整个应用会呈现这样一种结构:
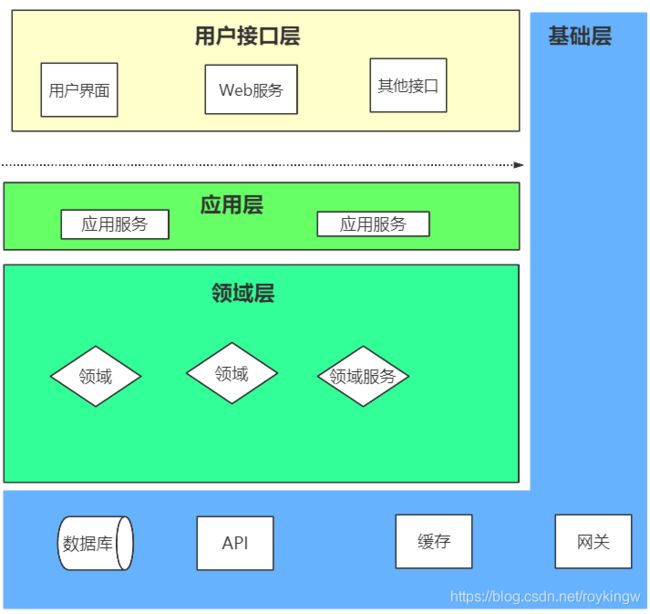
而这个结构,就是Eric Evans在《领域驱动设计-软件核心复杂性应对之道》书中提到的DDD四层架构模型。而这种组织架构和代码的方式,就是DDD 领域驱动设计。
从这个推演的过程中,我们可以看到DDD设计思想的另一种本质,其实是把软件系统中的引起系统变化的原因进行分析,将最经常需要变化的部分和变化比较少的部分抽象成不同的层次,并进行隔离,是一种面向变化的架构方式。在DDD中,随着业务的不断推进,不同的层一般有不同的演进速度,而不需要牵一发而动全身。
用户接口层是与业务关系最为紧密的部分,通常会变化得最为频繁。基础设施层需要与各种外部资源打交道,变化也会相对频繁。而领域层抽象出来的一般是企业最为核心的关键部分,一般来说变化不会过于频繁,就像淘宝永远是关注卖货,而支付宝永远是关注支付一样。
在这一章节的代码推演过程中,引出了DDD中的很多概念,像领域、实体、仓库、防腐层等。这些概念会在后面的章节进行详细的讲解,而在这里,他们确实很容易对你造成一些困惑。但是从这个过程中就能理解到,这些概念并不是凭空产生,而是在重构过程中逐步固定下来的一些抽象。
很多人在学习DDD时,会觉得DDD很难。其实其中有一个很重要的原因是大家经常会把DDD当作一个全新的架构体系,总是试图与以往的编程习惯割裂开来,所以很容易就迷失了方向。通过这节课的推演,你应该能够认识到,DDD并不是一种特殊的架构设计,他只是把所有事务脚本代码经过合理重构后沉淀下来的一种指导方法。
当然,这节课代码推演的方式,固然将DDD一些抽象的概念具象化,有助于对这些概念的理解。但是毕竟太过具体,缺乏方法层面的指导意义。而DDD的作用,也远不止指导代码设计这么简单。那接下来,我们就从更高的角度来理解下DDD是如何对我们的程序设计进行指导的。
最后,在你自己的业务中有没有类似可以往DDD进行推演进化的场景?不妨自己动手试试看。