Sub-Image Anomaly Detection with DeepPyramid Correspondences 基于深金字塔对应的子图像异常检测(KNN)
期刊:
作者:Niv Cohen and Yedid Hoshen
评价:简单易于部署 待部署了再看看
创新点:不需要特征训练,可以在非常小的数据集上工作
术语:deep projection深度投影、distributional modeling分布式建模、adversarial training对抗性训练、promising有前途的、complementary strengths互补优势、the state-of-the-art 最先进的、as explained above 如上所述、ablation Study消融研究、segmentation maps分割图、
目 录
Abstract
1 Introduction
2 Previous Work
3 Correspondence-based Sub-Image Anomaly Detection基于对应关系的子图像异常检测
3.1 Feature Extraction特征提取
3.2 K Nearest Neighbor Normal Image Retrieval K最近邻正常图像检索
3.3 Sub-image Anomaly Detection via Image Alignment 通过图像对齐进行子图像异常检测
3.4 Feature Pyramid Matching 特征金字塔匹配
3.5 Implementation Details 实施细节
4 Experiments 实验
4.2 Shanghai Tech Campus Dataset
4.3 Ablation Study 消融研究
5 Discussion
通过对齐进行异常检测
上下文在异常检测中的作用
优化运行性能
预训练的功能与学习的功能
6 Conclusion
Abstract
利用深度预训练特征的最近邻(kNN)方法在应用于整个图像时表现出非常强的异常检测性能。kNN方法的一个局限性是缺乏描述图像中异常位置的分割图。在这项工作中,我们提出了一种新的异常分割方法,该方法基于异常图像和常数数量的相似正常图像之间的对齐。我们的方法,语义金字塔异常检测(SPADE)使用基于多分辨率特征金字塔的对应关系。SPADE在无监督异常检测和定位方面达到了最先进的性能,同时几乎不需要训练时间。
Q:最先进的性能?
几乎不需要训练时间?
1 Introduction
在本文中,我们处理在训练时只观察到正常数据(但没有异常)的设置。这是一个实际有用的设置,因为获取正常数据(例如,不包含故障的产品)通常很容易。这种设置有时称为半监督([7])。由于这个符号是模糊的,我们将把这个设置称为普通的训练设置。
视觉异常检测(而非非图像异常检测方法)的另一个挑战是异常的定位,即分割算法认为异常的图像部分。这对于算法决策的可解释性以及在操作员和新型AI系统之间建立信任非常重要。
方法包括的2个阶段:i)使用预训练的深度神经网络(例如ImageNet训练的ResNet)提取图像特征;ii)最近的K个normal图像到目标的最近邻检索;iii)在目标和normal图像之间找到密集的像素级对应关系,在检索到的normal图像中没有近匹配的目标图像区域被标记为异常。
方法在工业产品数据集(MVTech)和校园环境(上海理工大学校园)的监控数据集上进行了广泛的评估。方法在图像级和像素级异常检测上都达到了最先进的性能。
2 Previous Work
本文概述了图像级和子图像异常检测方法。
回顾了检测图像是否异常的方法,这些方法不是专门为分割图像中的异常而设计的。
图像级异常检测主要有三类方法:基于重建的方法、基于分布的方法和基于分类的方法。
- 基于重建的方法在训练数据上学习一组基函数,并尝试使用这些基函数的稀疏集来重建测试图像。如果不能使用基函数忠实地重建测试图像,则将其表示为异常,因为它很可能来自与正常训练数据不同的基。基函数的常用选择包括:K-means、K个最近邻kNN、主成分分析PCA。基于重建的损失函数的主要缺点是:i)对用于评估重建质量的特定损失度量的敏感性,使其设计不明显并损害性能;ii)确定正确的函数基础。
- 基于分布的。主要原理是对正态数据分布的概率密度函数(PDF)进行建模。测试样本使用PDF进行评估,具有低概率密度值的测试样本被指定为异常。参数方法包括高斯方法或高斯混合方法(GMM)。最近邻居也可以被视为一种分布(因为它执行密度估计),但请注意,我们也将其指定为一种基于重建的方法。对抗性训练,也被应用于异常检测,例如ADGAN。分布方法也存在一些关键的缺点:i)真实图像数据很少遵循简单的参数分布假设;ii)非参数方法具有较高的样本复杂性,并且通常需要大量的训练集,而这些训练集在实践中往往不可用。
- 最近,基于分类的方法在图像级异常检测中占据了主导地位。范例:支持向量机(OC-SVM)、支持向量数据描述(SVDD),SVDD可以被视为找到至少包含给定部分数据的最小球体。
- 子图像方法。分割包含异常的特定像素的任务对图像来说是特殊的。最近,Venkataramanan等人使用了一种注意力引导的VAE方法,该方法结合了多种方法(GAN损失,GRADCAM)。我们提出了一种新的子图像对齐方法,该方法比以前的方法更准确、更快、更稳定,并且不需要专门的训练阶段。
Q:去了解下ADGAN
基于kNN(或有效近似)的简单方法显著优于这种自监督方法(对输入数据执行几何变换,并训练一个试图识别所使用变换的网络)。
数据集介绍:MVTech:一个模拟工业故障检测的数据集,其目标是检测产品图像中包含凹痕或缺失零件等故障的部分。ShanghaiTech校园数据集:一个模拟监控环境的数据集,在监控环境中,摄像机观察繁忙的校园,目的是检测异常物体和活动,如打架。
3 Correspondence-based Sub-Image Anomaly Detection基于对应关系的子图像异常检测
方法由3个部分组成:i)图像特征提取;ii)K最近邻正常图像检索;iii)具有深度特征金字塔对应的像素对齐
3.1 Feature Extraction特征提取
第一阶段是提取强图像级特征。小型训练数据集上学习的特征是否足以作为高质量的相似性度量,这一点并不明显。我们使用了在ImageNet数据集上预先训练的ResNet特征提取器。作为图像级特征,我们使用了全局池化后的最后一个卷积层之后获得的特征向量。初始化时,计算并存储所有训练图像(都是正常的)的特征。在推断时,仅提取目标图像的特征。
全局特征提取器F、给定的图像xi、提取的特征fi
Q:什么是强图像级特征?
3.2 K Nearest Neighbor Normal Image Retrieval K最近邻正常图像检索
第一阶段是使用DN2确定哪些图像包含异常。对于给定的测试图像y,我们从训练集中检索其K个最近的正常图像Nk(fy)。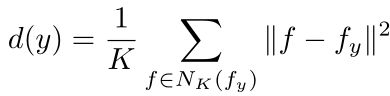 图像被标记为正常或异常。通过验证kNN距离是否大于阈值τ来确定正分类。
图像被标记为正常或异常。通过验证kNN距离是否大于阈值τ来确定正分类。
Q:什么是DN2?
3.3 Sub-image Anomaly Detection via Image Alignment 通过图像对齐进行子图像异常检测
Q:如何让图像对齐?是什么级别的对齐?
在图像级阶段被标记为异常之后,目标是定位和分割一个或多个异常的像素。考虑将测试图像与检索到的正常图像对齐,通过发现测试图像和正常图像之间的差异,我们希望能够检测到异常像素。存在的缺陷:计算图像差异将对所使用的损失函数非常敏感。
提出了一种多图像对应方法。在每个像素位置p∈P提取深度特征,在K个最近邻居G={F(x1,p)|p∈P}Ş{F(x2,p)| p∈P}}的所有像素位置上构造了一个特征库{F(xK,p)|p∈P}},像素p处的异常分数由特征F(y,p)及其与最近邻居G最近的κ个特征之间的平均距离给出。
目标图像y中像素p的异常分数:
对于给定的阈值θ,如果d(y,p)>θ,即:我们不能在K个最近邻正常图像中找到紧密对应的像素,则像素被确定为异常。
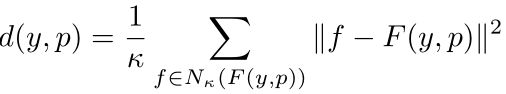
3.4 Feature Pyramid Matching 特征金字塔匹配
通过密集对应进行对准是确定图像中正常部分与异常部分的有效方法。要确定要匹配的特征。为了执行有效的对齐,我们使用来自特征金字塔不同级别的特征来描述每个位置。我们的特征对细粒度的局部特征和全局上下文进行编码,能够找到目标图像和K≥1个正常图像之间的对应关系。本文的方法实现了最先进的子图像异常分割精度。
Q:什么是细粒度?
3.5 Implementation Details 实施细节
使用Wide-ResNet50×2特征提取器(在ImageNet上预先训练的)。MVTec图像的大小调整为256×256,裁剪至224×224。所有指标都是以256×256的图像分辨率计算的。我们对MVTtec实验使用了K=50个最近邻居,对STC实验使用K=1个最近邻居(由于运行时的考虑)。在所有实验中,我们使用κ=1。在获得每个图像的逐像素异常分数后,我们使用高斯滤波器(σ=4)对结果进行平滑。
Q:二次采样:
4 Experiments 实验
用最先进的子图像异常检测技术对我们的方法进行了广泛的评估。
对于每个类,训练集都由正常图像组成。测试集由正常图像以及包含不同类型异常的图像组成。异常现象表现为轻微划伤的榛子或轻微弯曲的电缆。由于异常处于子图像级别,即仅影响图像的一部分,因此数据集提供指示异常区域的精确像素位置的分割图。
通过搜索两个图像之间的对应关系,我们的方法能够找到正常图像区域的对应关系而不能找到异常区域的对应。这导致对图像的异常区域的精确检测。
我们方法的第一阶段与DN2相同。这种比较很重要,因为它验证了深度最近邻居在这些数据集上是否有效。
证明在ImageNet(与ImageNet数据集非常不同)上训练的深度特征即使在与ImageNet非常不同的数据集上也非常有效。
目标是分割包含异常的特定像素
MVTec上的子图像异常检测精度(ROCAUC%)
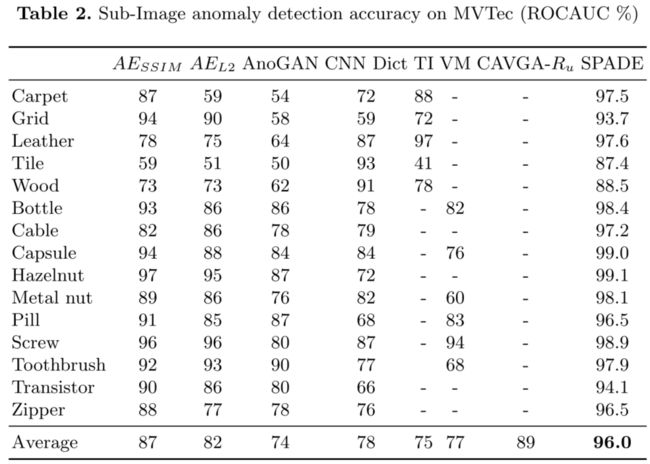
使用两个已建立的指标来评估我们的方法:逐像素ROCUC、PRO的方法。
- PRO方法。对覆盖很少像素的异常赋予了更大的权重。
异常类别被指定为阳性。
MVTec上的子图像异常检测精度(PRO%)
(i)异常图像ii)检索到的顶部正常邻居图像iii)SPADE检测到的掩码iv)预测的异常图像像素)
我们的方法能够恢复异常区域的精确掩模
SPADE是通过找到与最近邻居图像的对应关系来检测异常图像区域的。异常部分在正常图像中没有对应关系,因此被检测到。


4.2 Shanghai Tech Campus Dataset
训练视频不包含异常,而测试视频包含正常和异常图像。数据集包含12个场景,每个场景由训练视频和少量测试图像组成。异常被定义为行人进行非标准交流活动(如打架)以及任何非行人的移动物体(如摩托车)。异常监督在实践中通常不可用。
4.3 Ablation Study 消融研究
Q:什么是消融研究?
对我们的方法进行了消融研究,以了解其不同部分的相对性能。发现,在使用分辨率过高(56×56)的激活会显著损害性能然而使用较高的级别本身会导致性能下降(由于分辨率较低)。将金字塔中的所有功能组合使用可获得最佳性能。
(使用不同级别的特征金字塔进行比较)
展示了“Grid”类,以表明阶段1对某些类比其他类更重要(评估我们的kNN检索状态的有效性)

5 Discussion
通过对齐进行异常检测
我们采取了一种简单得多的方法。与图像对齐方法类似,与其他子图像异常检测方法不同,我们的方法不需要特征训练,可以在非常小的数据集上工作。我们的方法和标准图像对齐之间的区别在于,我们发现目标图像和K个正常图像的部分之间的对应关系,而不是简单对齐方法中的整个单个正常图像。
上下文在异常检测中的作用
异常图像和检索到的正常图像之间的对齐质量受到提取特征质量的强烈影响。为了实现具有高像素分辨率的分割图,需要局部上下文。
- 局部上下文。这种特征通常在深度神经网络的浅层中发现。在不了解全局环境的情况下,局部环境通常不足以进行调整。
- 全局上下文。通常存在于神经网络的最深层,全局上下文特征的分辨率较低。
优化运行性能
- 我们的方法在很大程度上依赖于K近邻算法。KNN算法复杂度的影响因素:用于搜索的数据集的大小。当数据集非常大或具有高维度时,这可能是一个问题。
- 我们的方法旨在缓解复杂性问题。在2048维向量的全局合并特征上计算初始图像级异常分类。异常分割阶段需要像素级的kNN计算,将子图像kNN搜索限制为仅异常图像的K个最近邻居,这显著限制了计算时间。
- 异常分割阶段是可解释性和与人工操作员建立信任所必需的,但在许多情况下,它不是严格时间限制的。
从复杂性和运行时的角度来看,我们的方法非常适合实际部署。
预训练的功能与学习的功能
- 我们的数值结果表明,我们的方法明显优于这些方法。这项工作所解决的仅限正常训练集的监督有限和数据集大小小,很难击败非常深入的预训练网络。
- 在许多实际环境中,我们的方法易于部署和通用,是一个很好的选择。
- 我们认为,未来的工作应该专注于为这项特定任务微调深度预训练特征的方法,并期望它比我们的方法有所改进。
6 Conclusion
- 提出了一种新的基于对齐的方法来检测和分割图像中的异常
- 方法依赖于通过预训练的深度特征提取的像素级特征金字塔的K个最近邻
- 我们的方法由两个阶段组成,旨在实现高精度和合理的计算复杂度(阶段一:使用预先训练的深度神经网络进行图像特征提取,阶段二:对距离目标最近的K个正常图像进行最近邻居检索,在检索到的正常图像中不具有接近匹配的目标图像区域被标记为异常。)
- 在两个逼真的子图像异常检测数据集上,我们的方法被证明优于目前最强的方法,同时要简单得多,且易于部署