004+limou+C语言入门知识——(3)数组
1、数组是什么?
简单来说:数组是一组相同类型元素的集体。
2、创建、初始化、使用“一维数组”,以及存储
(1)创建一维数组
①伪代码
类型 数组名 [常量] = { 元素1, 元素2, … };
注意:[]里面的常量在C99标准下是可以为变量的,但是创建数组的时候不能进行初始化,且创建好变量的值后,也不能再次修改数组大小了(在C99之前,[]里放变量是不被允许的)
②代码
int arr1[10] = { 1, 2, 3, 5 };
char arr2[5] = { 'a', 'c', '\n' };
(2)初始化一维数组
①不完全初始化
int arr1[10] = { 1, 2, 3 };//数组的大小为10,但是只存了3个元素,其他7歌元素默认为'\0'
char arr2[11] = { 'A', 'b' };//存放单个字符
char arr3[30] = "abcdef";//存放一个字符串
②完全初始化
int arr4[] = {1, 3, 2, 9};//没有指定大小就初始化,会根据初始化元素的多少,默认为该数组大小,本例为4
char arr5[3] = { 'A', 'c', 'E' };
(3)使用一维数组
①可以利用[](下标引用操作符)来访问数组的饿元素,进而使用数组存储的值。
注意:这个[]和前面数组创建的[]不是一个东西,前者为运算符,后者为一种语法形式,因此前者内部可以放变量,和前面数组初始化不能放变量大小不冲突。
②数组的每个元素都有下标,下标从0开始数起。因此,比如:arr[2]访问的是数组的第三个元素。这点要尤其注意!!!
#include (4)一维数组在内存中的存储
#include 可以看到数组元素的地址是连续存储的,由低地址到高地址存储,因此我们可以通过一个数组的元素的地址“顺藤摸瓜”到其他元素地址,进而使用同一个数组里其他的元素。
4、创建、初始化、使用“二维数组”以及存储
二维数组经常被假想为一个表格,也是数学中的矩阵。
(1)(2)创建与初始化
类似于一维数组的创建和初始化,下面是二维数组的两种等价写法:
int arr[2][3] = { { 1, 2, 2 }, { 3, 2, 4 } }
int arr[2][3] = { 1, 2, 2, 3, 2, 4 }
另外:
int arr[][4] = { {2, 3}, {4, 5} };//二维数组如果有初始化,行可以省略,列不能省略
(3)二维数组的使用
#include (4)二维数组在内存中的存储
#include 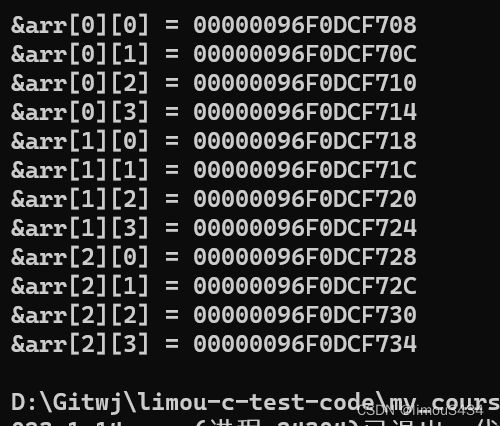
注意:不同环境不同结果,但都是连续的。 因此其实二维数组看似是多行多列的,但是其实其内存分布也是连续存储的,地址由低到高
5、多元数组
实际上还存在三维数组数组,以下是三维数组的创建,若有指针基础请参考大佬文章。
int a[2][3][4] =
{
{
{6,2,3,4},
{5,11,15,8},
{8,20,10,11}
},
{
{0,0,3,4},
{5,0,7,8},
{8,1,18,31}
}
};
6、数组越界
(1)概念
数组的下标是有范围的,如果数组有n个元素,那么下标从一开始,最多到n-1,访问的时候不可以超出这个范围,不然就非法访问数组了,即“数组越界”。
(2)注意
尤其注意的是:C语言本身并不会对数组下标合法性进行检查的(尽管有的编译器能检查出来),编译器也不一定报错,但是不报错不意味着程序是正确的,写代码的时候就需要做好数组访问是否越界的检查
7、数组作为函数的参数(冒泡排序)
(1)一种错误的写法
void function(int arr[])//两两相邻元素比较,n个数需要重复n-1次冒泡排序
{
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0])//确定使用冒泡排序的次数
for(i = 0; i < sz - 1; i++)//循环使用冒泡排序
{
int j = 0;
for(j = 0; j < sz - i - 1; j++)//一次冒号排序,每次排序后就不用排最后一个数字了,所以-i
{
if(arr[j] > arr[j + 1])
{
int num = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = num;
}
}
}
}
int main()
{
int arr[] = { 3, 4, 1, 6, 8, 9, 6, 8, 9, 7, 0 };
//排序为升序
function(arr);
int i = 0;
for(i = 0; i < sizeof(arr)/sizeof(arr[0]); i++)
{
printf("%d", arr[i]);
}
return 0;
}
上面的数组传参的时候,实际上是把数组的首元素地址传过去了,并不是整个数组,因此计算出sizeof(arr)的值是4,计算了int类型的大小。
其中要注意:
//int arr[]和int *arr的写法是等价的
但是有两个例外,数组名不是首元素地址:
①sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小;
②&数组名,这里取出来的是整个shu’zu饿地址,尽管它的值和数组的首元素地址相同,但是两者是有区别的,从下面例子结果不一样就可以看出。
#include (2)一种正确的写法
//两两相邻元素比较,n个数需要重复n-1次冒泡排序
void function(int* arr, int sz)//前者为首元素地址,后者是数组的个数
{
int i = 0;
for (i = 0; i < sz - 1; i++)//循环使用冒泡排序
{
int j = 0;
for (j = 0; j < sz - i - 1; j++)//一次冒号排序,每次排序后就不用排最后一个数字了,所以-i
{
if (arr[j] > arr[j + 1])
{
int num = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = num;
}
}
}
}
int main()
{
int arr[] = { 3, 4, 1, 6, 8, 9, 6, 8, 9, 7, 0 };
//排序为升序
int sz = sizeof(arr) / sizeof(arr[0]);//放置到这里计算了
function(arr, sz);
int i = 0;
for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("%d ", arr[i]);
}
return 0;
}
7、数组的类型
去掉名字后剩下的东西就是数组的类型
首先:
int a = 10;//去掉名字a,剩下int就是类型
同理:
int arr[10] = { 1, 2, 5, 3, 1};//去掉名字arr,剩下的int [10]就是数组的类型
8、其他
(1)字符串存储和多单字符存储,在sizeof中字符串的大于单字符,因为多了一个\0
#include
(2)字符串存储和多单字符存储,使用strlen时,后者会打印打印随机值,因为strlen需要靠\0来结束
#include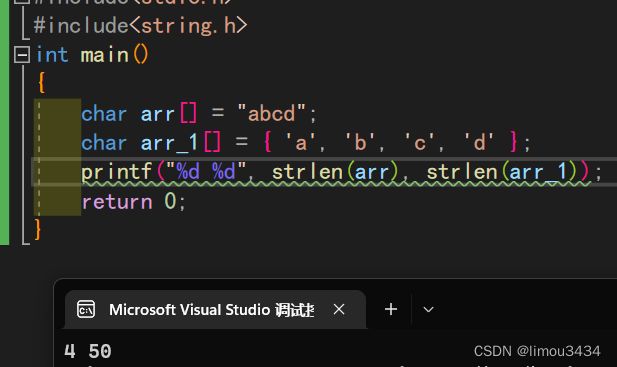
(3)字符串存储和多单字符存储,转化说明%s输出时,后者产生乱码,原因也是后者缺少\0
int main()
{
char arr[] = "abcd";
char arr_1[] = { 'a', 'b', 'c', 'd' };
printf("%s %s", arr, arr_1);
return 0;
}
