十分钟教你用python爬取王者荣耀所有英雄皮肤
一、 明确目标
首先打开王者荣耀官网
点击“英雄资料”,按f12,f5刷新页面,点击network,搜索herolist.json,这里面都是英雄信息
我们随便打开一个英雄的主页,链接里的这个数字就是刚刚herolist里的ename,而每个英雄对应一个唯一的ename,我们通过这个ename构建每个英雄的主页链接。
接下来我们对英雄主页进行分析,分析后得知箭头处即为英雄皮肤的下载链接和皮肤名字,那我们如何获取这些链接呢?
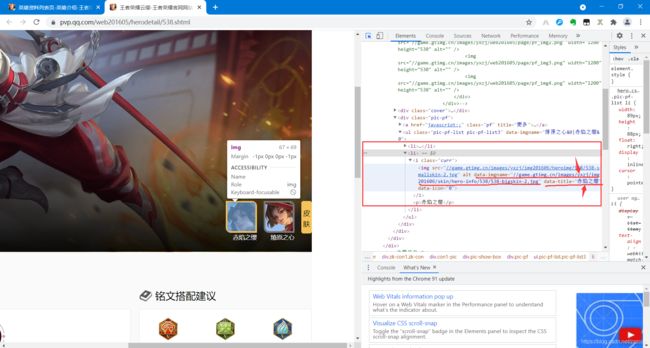
由于英雄主页为动态链接,我们通过selenium来获取英雄主页的皮肤下载链接及皮肤名字,获取后用requests库将图片保存到本地即可。
二、上代码
import os
import json
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import time
start = time.perf_counter() # 计时
url = requests.get('http://pvp.qq.com/web201605/js/herolist.json').content
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64',
'Referer': 'https://pvp.qq.com/'
}
jsonFile = json.loads(url) # 提取json
hero_dir = 'D:\王者荣耀皮肤' # 创建文件夹
if not os.path.exists(hero_dir):
os.mkdir(hero_dir)
os.chdir(hero_dir) # 切换路径
driver = webdriver.Chrome(r"E:\Python3.7\Scripts\chromedriver.exe") # 打开chrome浏览器
for m in range(len(jsonFile)):
ename = jsonFile[m]['ename'] # 英雄编号
cname = jsonFile[m]['cname'] # 英雄名字
hero_url = 'https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(ename) # 英雄链接
driver.get(hero_url)
data = driver.page_source
soup = BeautifulSoup(data, 'lxml') # 解析网页
div = soup.find('div', class_='pic-pf')
ul = div.find('ul')
li = ul.find_all('li')
for i in li:
_i = i.find('i')
for k in _i:
skin_url = 'http:' + k.get('data-imgname') # 获取皮肤下载链接
skin_name = k.get('data-title') # 获取皮肤名称
path = 'D:\王者荣耀皮肤\{}'.format(cname) # 创建文件夹,存放皮肤
if not os.path.exists(path):
os.mkdir(path)
skin = requests.get(skin_url, headers=headers).content
print('正在下载 {}-{}...'.format(cname, skin_name))
with open('{}/{}-{}.jpg'.format(path, cname, skin_name), 'wb') as f:
f.write(skin) # 下载到本地
driver.quit() # 关闭浏览器
print('下载完成,共耗时{}s。'.format(time.perf_counter() - start))
上面的方法需要安装chrome浏览器及chromedriver,当然我们也可以不用selenium来获取英雄的皮肤链接,只不过要稍微麻烦一点罢了。
我们对云缨的两个皮肤链接做分析 :
//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/538/538-bigskin-1.jpg
//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/538/538-bigskin-2.jpg
我们可以发现,除了最后皮肤编号不同之外,其他的都是一样的,当然,不同的英雄编号不同,上面的hero-info后的数字也不同。
例:艾琳女武神皮肤下载链接 //game.gtimg.cn/images/yxzj/img201606/skin/hero-info/155/155-bigskin-2.jpg
即我们只需要拿到英雄的cname及每个英雄的皮肤数量即可构造出每个皮肤的下载链接。而每个英雄的皮肤名字都在前面的ul标签中。

写到这里你是不是已经知道该怎么做了呢。废话不多说,接下来直接上代码。
代码
import requests
import json
import os
import time
from bs4 import BeautifulSoup
start = time.time() # 程序开始时间
url = requests.get('http://pvp.qq.com/web201605/js/herolist.json').content
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64',
'Referer': 'https://pvp.qq.com/'
}
jsonFile = json.loads(url) # 提取json
x = 0 # 用于记录下载的图片张数
# 目录不存在则创建
hero_dir = 'D:\王者荣耀皮肤'
if not os.path.exists(hero_dir):
os.mkdir(hero_dir)
os.chdir(hero_dir) # 切换路径
for m in range(len(jsonFile)):
ename = jsonFile[m]['ename'] # 编号
cname = jsonFile[m]['cname'] # 英雄名字
# print(ename,cname)
hero_url = 'https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(ename) # 英雄链接
# 访问英雄链接,获取英雄所有皮肤名字
res = requests.get(hero_url, headers=headers)
res.encoding = 'gbk'
text = res.text
soup = BeautifulSoup(text, 'html.parser')
div = soup.find('div', class_='pic-pf')
ul = div.find('ul')
data = ul['data-imgname'].split('|') # 切分英雄皮肤名字
skin_name_list = []
for i in data:
skin_name = i.split('&')[0] # 获取英雄所有皮肤名字
skin_name_list.append(skin_name)
skinNumber = len(skin_name_list) # 皮肤序号
# 下载图片,构造图片网址
for bigskin in range(1, skinNumber + 1):
urlPicture = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(ename) + '/' + str(
ename) + '-bigskin-' + str(bigskin) + '.jpg' # 皮肤图片下载链接
picture = requests.get(urlPicture).content # 获取图片的二进制信息
with open(cname + "-" + skin_name_list[bigskin - 1] + '.jpg', 'wb') as f: # 保存图片
f.write(picture)
x = x + 1
print('正在下载{} …'.format(skin_name_list[bigskin - 1]))
# print("正在下载第" + str(x) + "张")
end = time.time() # 程序结束时间
time_second = end - start # 执行时间
print("共下载" + str(x) + "张,共耗时" + str(time_second) + "秒")
效果图


怎么样,是不是很简单呢。来,试试看吧!