COCO数据集解析
1 简介
官方网站:http://cocodataset.org/
全称:Microsoft Common Objects in Context (MS COCO)
支持任务:Detection、Keypoints、Stuff、Panoptic、Captions
说明:COCO数据集目前有三个版本,即2014、2015和2017,其中2015版只有测试集,其他两个有训练集、验证集和测试集。

MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。

微软构建的 COCO 关节点检测数据集包括训练集、验证集和测试集,包含 20 万张图像和 25 万个均被标注好 17 个关节点信息的人体目标,其中被公开的训练数据集和验证数据集包含 15 万人和 170 万个关节标注点。
微软的COCO比赛官网,发现它包含了如下任务,
(1)目标检测(80类);
COCO数据集共有小类80个,类别id号不连续,最大为90,分别为:
[‘person’, ‘bicycle’, ‘car’, ‘motorcycle’, ‘airplane’, ‘bus’, ‘train’, ‘truck’, ‘boat’, ‘traffic light’, ‘fire hydrant’, ‘stop sign’, ‘parking meter’, ‘bench’, ‘bird’, ‘cat’, ‘dog’, ‘horse’, ‘sheep’, ‘cow’, ‘elephant’, ‘bear’, ‘zebra’, ‘giraffe’, ‘backpack’, ‘umbrella’, ‘handbag’, ‘tie’, ‘suitcase’, ‘frisbee’, ‘skis’, ‘snowboard’, ‘sports ball’, ‘kite’, ‘baseball bat’, ‘baseball glove’, ‘skateboard’, ‘surfboard’, ‘tennis racket’, ‘bottle’, ‘wine glass’, ‘cup’, ‘fork’, ‘knife’, ‘spoon’, ‘bowl’, ‘banana’, ‘apple’, ‘sandwich’, ‘orange’, ‘broccoli’, ‘carrot’, ‘hot dog’, ‘pizza’, ‘donut’, ‘cake’, ‘chair’, ‘couch’, ‘potted plant’, ‘bed’, ‘dining table’, ‘toilet’, ‘tv’, ‘laptop’, ‘mouse’, ‘remote’, ‘keyboard’, ‘cell phone’, ‘microwave’, ‘oven’, ‘toaster’, ‘sink’, ‘refrigerator’, ‘book’, ‘clock’, ‘vase’, ‘scissors’, ‘teddy bear’, ‘hair drier’, ‘toothbrush’]
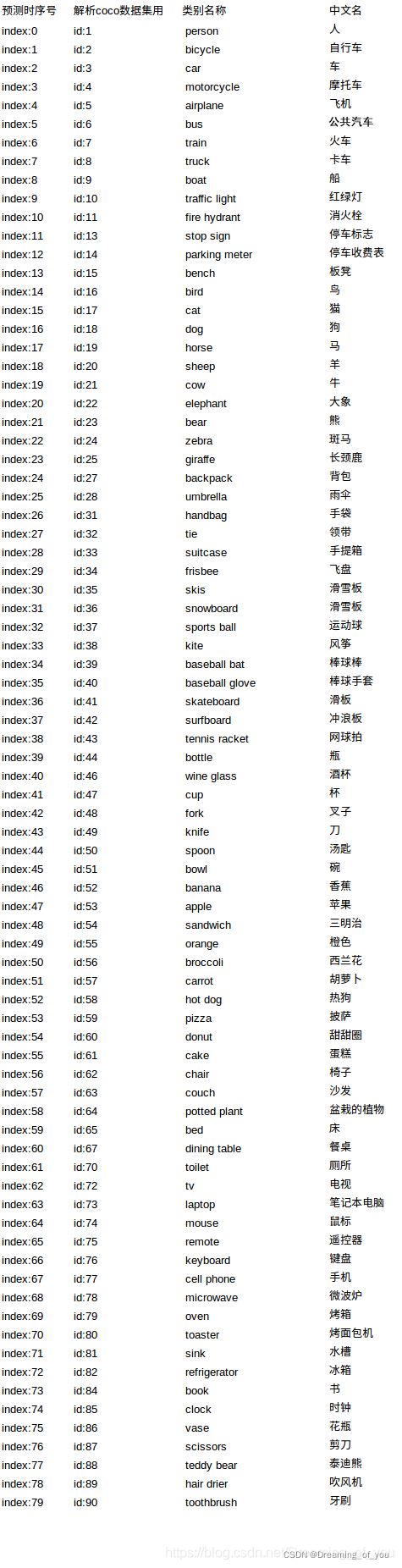
大类12个,分别为:
[‘appliance’, ‘food’, ‘indoor’, ‘accessory’, ‘electronic’, ‘furniture’, ‘vehicle’, ‘sports’, ‘animal’, ‘kitchen’, ‘person’, ‘outdoor’]
(2)人体关节点检测(17个点);
(3)Stuff分割(也即semantic分割,指代不规则目标的分割,比如grass、wall、sky、人群等);
(4)全景分割(包含了semantic分割 和 instance分割);
数据分为三部分:训练、验证和测试,每部分分别包含 118287, 5000 和 40670张图片,总大小约25g。其中测试数据集没有标注信息,所以注释部分只有训练和验证的。
关于COCO的测试集:2017年COCO测试集包含〜40K个测试图像。 测试集被分成两个大致相同大小的split约20K的图像:test-dev 和test-challenge。
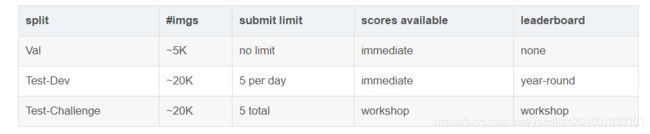
Test-Dev:test-dev split 是在一般情况下测试的默认测试数据。通常应该在test-dev集中报告论文的结果,以便公正公开比较。
Test-Challenge:test-challenge split被用于每年托管的COCO挑战。
下载地址:
2017 Train images [118K/18GB]:http://images.cocodataset.org/zips/train2017.zip
2017 Val images [5K/1GB]:http://images.cocodataset.org/zips/val2017.zip
2017 Test images [41K/6GB]: http://images.cocodataset.org/zips/test2017.zip
2017 Annotations:http://images.cocodataset.org/annotations/annotations_trainval2017.zip
2 数据集结构
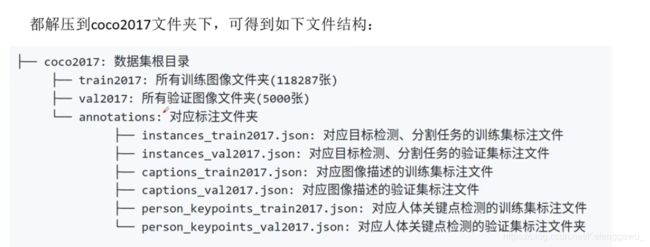
COCO数据集包括两大部分:Images和Annotations
Images:“任务+版本”命名的文件夹(例如:train2017),里面为xxx.jpg的图像文件;
Annotations:文件夹,里面为xxx.json格式的文本文件(例如:instances_train2017.json)
在本地计算机中创建一个新的文件夹存放下载到的数据集:
注意: 虽然每个json文件都有"info", “images” , “annotations”, "licenses","categories"关键字,但不同的任务对应的json文件中annotation的形式不同。

在制作自己的数据集时候,文件夹的格式可以保持一致,标注的信息要提前筛选和检查一遍,避免在标注的过程中出现标定框的高度、宽度为0的情况,影响训练进行。
上述的文件夹框架中,在标注信息文件夹下,训练涉及的主要注意文件是:含有训练集标注信息的json文件 和 验证集的验证集标注信息的json文件。
自己训练的时候,没有必要自己划分测试集。只有特别需求的时候,比如参加什么比赛有要求,防止人为修改参数在模型和数据、结果之间作弊。一般通过训练集得到模型,用验证集进行验证就可以满足基本要求了。
3 json文件格式
json是一种轻量级的数据交换格式,可以将不同信息打包成一个个模块,并将这些模块按照一定顺序存储到json文件中,读文件时只需要根据关键字对相应模块进行解析,即可得到该模块的打包信息。
因此,COCO数据集把分类、位置等标签信息存储到json格式的文件,方便训练和测试时进行解析。
person_keypoints_val2017.json和person_keypoints_train2017.json都是这种格式。
person_keypoints_val2017.json文件共有5000张图片(images),11004条注释(annotations),1条种类信息(categories)。
COCO有五种注释类型对应五种任务:目标检测、关键点检测、实物分割、全景分割和图像描述。注释使用JSON文件存储。
在python里面,读取出json标注格式文件,每一个字段虽然是list,实际上是一个dict,Object Keypoint这种格式的文件从头至尾按照顺序分为以下段落如下所示:
{
"info": info, # dict
"licenses": [license], # list ,内部是dict
"images": [image], # list ,内部是dict
"annotations": [annotation], # list ,内部是dict
"categories": # list ,内部是dict
}
对于每个标注文件,都会有anns, cats, imgs,imgToAnns, catToImgs 这5类字典dict数据结构需要生成。
3.1 通用字段
value为对应的数据类型,其中:
info是一个字典,包含了数据集的年份、版本、作者,以及描述等信息:
images是一个list,包含了图像信息,由于有多张图像,将它们的信息以序列表的形式进行存储,序列表中每张图像信息的存储形式是一样的:
licenses是一个list,包含了数据集的发布证书信息,由于有多个证书,将它们的信息以序列表的形式进行存储,序列表中每个证书的存储形式是一样的:
除annotation外,每部分的内容定义如下:
info{
"year" : int, # 数据集年份号
"version" : str, # 数据集版本
"description" : str, # 数据集描述
"contributor" : str, # 贡献者
"url" : str, # 数据集官方网址
"date_created" : datetime, # 数据集创建详细时间
}
image{
"id" : int, # 图像id
"width" : int, # 图像宽度
"height" : int, # 图像高度
"file_name" : str, # 图像文件名
"license" : int, # 许可证
"flickr_url" : str, # flickr链接
"coco_url" : str, # coco链接
"date_captured" : datetime, # 拍摄时间
}
license{
"id" : int, # license的编号,1-8
"name" : str, # 许可证名称
"url" : str, # 许可证网址
}
key为”annotation“的value对应不同的xxx.json略有不同,但表示内容含义是一样的,即对图片和实例的描述。同时除了annotation外,还有一个key为”categories“表示类别。以下分别对不同任务的annotation和categories进行说明。
3.2 非通用字段
annotations是一个list,主要包含了图片中检测目标的分类信息和位置信息,由于有多张图片且每张图片中可能包含多个检测目标,将每个检测目标的信息以序列表的形式进行存储,序列表中每个检测目标信息的存储形式是一样的:
categories部分主要包含了检测目标的分类信息,由于检测目标总共有80个类别,将每个类别的信息以序列表的形式进行存储,序列表中每个类别信息的存储形式是一样的:
3.2.1 Object Detection(目标检测)
以检测任务为例,对于每一张图片,至少包含一个对象,COCO数据集对每一个对象进行描述,而不是对一张图片。每个对象都包含一系列字段,包括对象的类别id和mask码,mask码的分割格式取决于图像里的对象数目,当一张图像里就一个对象时(iscrowd=0),mask码用polyhon格式,当大于一个对象时(iscrowd=1),采用RLE格式。
annotation{
"id" : int, # annotation的id,每个对象对应一个annotation
"image_id" : int, # 该annotation的对象所在图片的id
"category_id" : int, # 该检测目标所属的类别id,每个对象对应一个类别
"segmentation" : RLE or [polygon], float类型,检测目标的轮廓分割级标签
"area" : float, # 检测目标的面积
"bbox" : [x,y,width,height], # x,y为左上角坐标
"iscrowd" : 0 or 1, # 0时segmentation为polygon,1为REL,目标是否被遮盖,默认为0
}
categories[{
"id" : int, # 类别id,对应以上annotations部分的category_id
"name" : str, # 类别名称,比如person、dog、cat等
"supercategory" : str, # 类别的父类,例如:bicycle的父类是vehicle,如卡车和轿车都属于机动车这个大类
}]
对于边界框的检测,请使用以下格式:
[{
"image_id" : int,
"category_id" : int,
"bbox" : [x,y,width,height],
"score" : float,
}]
框坐标是从图像左上角测量的浮点数(并且是0索引的)。官方建议将坐标舍入到最接近十分之一像素的位置,以减少JSON文件的大小。
对于对象segments的检测(实例分割),请使用以下格式:
[{
"image_id" : int,
"category_id" : int,
"segmentation" : RLE,
"score" : float,
}]在json标签文件的五大部分内容中,我们在目标检测时主要用到的是images、annotations、categories这三部分的信息,分别对应图片信息、检测目标的位置信息、检测目标的分类信息,其中:
-
images部分为序列表,序列表包含多个元素,每个元素对应数据集的一张图片。因此序列表的元素个数与数据集的图片个数一致。
-
annotations部分也为序列表,序列表包含多个元素,每个元素对应数据集的一个检测目标,该检测目标根据image_id对应到images部分的id,使检测目标与图片关联起来,同时根据category_id对应到categories部分的id,使检测目标与类别信息关联起来。因此序列表的元素个数与数据集图片中包含的所有检测目标个数一致。
-
categories部分同样为序列表,序列表包含多个元素,每个元素则对一个类别。因此序列表的元素个数与所有检测目标的类别数(80个类别)一致。

3.2.2 Keypoint Detection(关键点检测)
与检测任务一样,一个图像包干若干对象,一个对象对应一个keypoint注释,一个keypoint注释包含对象注释的所有数据(包括id、bbox等)和两个附加字段。
首先,key为”keypoints“的value是一个长度为3k的数组,其中k是类别定义的关键点总数(例如人体姿态关键点的k为17)。每个关键点都有一个0索引的位置x、y和可见性标志v(v=0表示未标记,此时x=y=0;v=1时表示标记,但不可见,不可见的原因在于被遮挡了;v=2时表示标记且可见),如果一个关键点落在对象段内,则认为是可见的。
annotation{
"keypoints" : [x1,y1,v1,...],
"num_keypoints" : int, # v=1,2的关键点的个数,即有标记的关键点个数
"[cloned]" : ...,
}
categories[{
"keypoints" : [str], # 长度为k的关键点名字符串
"skeleton" : [edge], # 关键点的连通性,主要是通过一组关键点边缘队列表的形式表示,用于可视化.
"[cloned]" : ...,
}]
其中,[cloned]表示从上面定义的Object Detection注释中复制的字段。因为keypoint的json文件包含detection任务所需的字段。
结果文件格式:
[{
"image_id" : int,
"category_id" : int,
"keypoints" : [x1,y1,v1,...,xk,yk,vk],
"score" : float,
}]关键点坐标是从左上角图像角测量的浮点数(并且是0索引的)。官方建议四舍五入坐标到最近的像素,以减少文件大小。还请注意,目前还没有使用vi的可视性标志(除了控制可视化之外),官方建议简单地设置vi=1。
3.2.3 Stuff Segmentation(实例分割)
分割任务的对象注释格式与上面的Object Detection相同且完全兼容(除了iscrowd是不必要的,默认值为0),分割任务主要字段是“segmentation”。
结果文件格式:
[{
"image_id" : int,
"category_id" : int,
"segmentation" : RLE,
}]除了不需要score字段外,Stuff 分割格式与Object分割格式相同。注意:官方建议用单个二进制掩码对图像中出现的每个标签进行编码。二进制掩码应该使用MaskApi函数encode()通过RLE进行编码。例如,参见cocostuffhelper.py中的segmentationToCocoResult()。为了方便,官方还提供了JSON和png格式之间的转换脚本。
3.2.4 Panoptic Segmentation(全景分割)
对于全景分割任务,每个注释结构是每个图像的注释,而不是每个对象的注释,与上面三个有区别。每个图像的注释有两个部分:1)存储与类无关的图像分割的PNG;2)存储每个图像段的语义信息的JSON结构。
要将注释与图像匹配,使用image_id字段(即:annotation.image_id==image.id);
对于每个注释,每个像素段的id都存储为一个单独的PNG,PNG位于与JSON同名的文件夹中。每个分割都有唯一的id,未标记的像素为0;
对于每个注释,每个语义信息都存储在annotation.segments_info. segment_info.id,该存储段存储唯一的id,并用于从PNG检索相应的掩码(ids==segment_info.id)。iscrowd表示段内包含一组对象。bbox和area字段表示附加信息。
annotation{
"image_id": int,
"file_name": str,
"segments_info": [segment_info],
}
segment_info{
"id": int,.
"category_id": int,
"area": int,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
}
categories[{
"id": int,
"name": str,
"supercategory": str,
"isthing": 0 or 1,
"color": [R,G,B],
}]
结果文件格式:
annotation{
"image_id": int,
"file_name": str,
"segments_info": [segment_info],
}
segment_info{
"id": int,
"category_id": int,
}3.2.5 Image Captioning(图像字幕)
图像字幕任务的注释用于存储图像标题,每个标题描述指定的图像,每个图像至少有5个标题。
annotation{
"id": int,
"image_id": int,
"caption": str,
}
结果文件格式:
[{
"image_id": int,
"caption": str,
}]
4 COCOAPI
COCO数据集官方提供了COCO API用于更加方便地解析标注文件,在使用之前通过pip install pycocotools安装依赖或通过pip install git+https://github.com/cocodataset/cocoapi.git进行安装。可直接查看该COCOAPI的官方文档。在使用各API前,我们需要实例化COCO类,它接受的参数为标注文件的路径,返回类的对象。COCO中的核心单元是anno。
使用COCO时,首先需要初始化COCO类,
.__init__(self, annotation_file=None):读取val2017.json文件并解析到类中的dataset对象中去,然后.createIndex()。这里的.createIndex()步骤非常关键;
.createIndex():会在初始化的时候,为COCO类创建了5个对象非常重要的对象:
上面的初始化之后,就可以调用以下api:
.info(self):打印数据集的一些基础信息;
decodeMask:通过运行长度解码二进制掩码M进行解码;
encodeMask:使用运行长度编码对二进制掩码M进行编码;
.getAnnIds(self, imgIds=[], catIds=[], areaRng=[], iscrow=None):根据一条标注信息对应的image_id、cat_id、area_range、iscrowd来获得对应的id,这里iscrowd对应segmentation的格式
.getCatIds():获得满足给定过滤条件的category的id;
.getImgIds():得到满足给定过滤条件的imgage的id;
.loadAnns(self, ids=[]):使用指定的id加载annotation;
.loadCats(self, ids=[]):使用指定的id加载category;
.loadImgs(self, ids=[]):使用指定的id加载imgage;
annToMask:将注释中的segmentation转换为二进制mask;
.showAnns(self, anns):根据一条anno记录来进行可视化,但是返回值是None,没什么用。看吧,我就说COCO疏于维护(怕不是写api的实习生实习结束了,手动斜眼);
.loadRes(self, resFile):是我们最常用的也是最重要的方法。它做了以下工作:
1)初始化另一个COCO类DT(以下用DT指代检测类),用于存储检测数据;
2)将GT的所有image赋给DT,也就是DT所有的image和GT是完全一样的;
3)读取由我们自己生成的结果.json文件,并且判断结果.json文件必须是完全被GT的image包含的;
4)依次为DT类生成caption、bbox、segmention、keypoints,并且,重写DT类里所有anno的id,也就是不管我们有没有在我们的结果文件里生成id,它都会在这里重写这些id以保证id的唯一性;
5)返回需要的DT;
download:从mscoco.org服务器下载COCO图像。
下面展示了数据加载、解析和可视化注释等内容,步骤如下:
4.1 首先导入必要的包
%matplotlib inline
from pycocotools.coco import COCO
import numpy as np
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
4.2 定义annotation文件路径(以“instances_val2017.json”为例)
dataDir='..'
dataType='val2017'
annFile='{}/annotations/instances_{}.json'.format(dataDir,dataType)
4.3 读取instances_val2017.json文件到COCO类
# initialize COCO api for instance annotations
coco = COCO(annFile)输出如下:
loading annotations into memory…
Done (t=4.19s)
creating index…
index created!
4.4 COCO图像类别的读取
# display COCO categories and supercategories
cats = coco.loadCats(coco.getCatIds())
nms=[cat['name'] for cat in cats]
print('COCO categories: \n{}\n'.format(' '.join(nms)))
nms = set([cat['supercategory'] for cat in cats])
print('COCO supercategories: \n{}'.format(' '.join(nms)))
输出如下:
COCO categories:
person bicycle car motorcycle airplane bus train truck boat traffic light fire hydrant stop sign parking meter bench bird cat dog horse sheep cow elephant bear zebra giraffe backpack umbrella handbag tie suitcase frisbee skis snowboard sports ball kite baseball bat baseball glove skateboard surfboard tennis racket bottle wine glass cup fork knife spoon bowl banana apple sandwich orange broccoli carrot hot dog pizza donut cake chair couch potted plant bed dining table toilet tv laptop mouse remote keyboard cell phone microwave oven toaster sink refrigerator book clock vase scissors teddy bear hair drier toothbrush
COCO supercategories:
sports furniture electronic food appliance vehicle animal kitchen outdoor indoor person accessory
4.5 COCO原始图像读取
# 找到符合'person','dog','skateboard'过滤条件的category_id
catIds = coco.getCatIds(catNms=['person','dog','skateboard']);
# 找出符合category_id过滤条件的image_id
imgIds = coco.getImgIds(catIds=catIds );
# 找出imgIds中images_id为324158的image_id
imgIds = coco.getImgIds(imgIds = [324158])
# 加载图片,获取图片的数字矩阵
img = coco.loadImgs(imgIds[np.random.randint(0,len(imgIds))])[0]
# 显示图片
I = io.imread(img['coco_url'])
plt.axis('off')
plt.imshow(I)
plt.show()
输出如下:

4.6 加载并显示annotations
# load and display instance annotations
plt.imshow(I); plt.axis('off')
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns)
输出如下:

4.7 加载并显示person_keypoints_2017.json的annotations
# initialize COCO api for person keypoints annotations
annFile = '{}/annotations/person_keypoints_{}.json'.format(dataDir,dataType)
coco_kps=COCO(annFile)
# load and display keypoints annotations
plt.imshow(I); plt.axis('off')
ax = plt.gca()
annIds = coco_kps.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco_kps.loadAnns(annIds)
coco_kps.showAnns(anns)输出如下:
loading annotations into memory…
Done (t=2.08s)
creating index…
index created!

4.8 加载并显示captions_2017.json.json的annotations
# initialize COCO api for caption annotations
annFile = '{}/annotations/captions_{}.json'.format(dataDir,dataType)
coco_caps=COCO(annFile)
# load and display caption annotations
annIds = coco_caps.getAnnIds(imgIds=img['id']);
anns = coco_caps.loadAnns(annIds)
coco_caps.showAnns(anns)
plt.imshow(I); plt.axis('off'); plt.show()输出如下:
loading annotations into memory…
Done (t=0.41s)
creating index…
index created!
A man is skate boarding down a path and a dog is running by his side.
A man on a skateboard with a dog outside.
A person riding a skate board with a dog following beside.
This man is riding a skateboard behind a dog.
A man walking his dog on a quiet country road.

5 person_detection_results文件夹格式
包括COCO_test-dev2017_detr_detections.json和COCO_val2017_detr_detections.json。
表示的是由DETR得到的bbox标识记录。只包括annotations这一部分内容,具体如下所示:
ann={
"segmentation": RLE or [polygon], # 分割信息
"num_keypoints": int, # 标注的关节点数
"area": float, # 标注区域面积
"iscrowd": 0 or 1, # 是否是单人
"keypoints": [x1,y1,v1,...], # 关节点信息,按照(x,y,v)的顺序排列,即坐标为(x,y),可见性为v; v=0,没有标注;v=1,有标注不可见(被遮挡);v=2,有标注可见
"image_id": int, # 图片id
"bbox": [x,y,width,height], # 图片中人的边框,这里x,y为边框的左上角的坐标
"category_id": int, # 类别id,等于1表示人这一类
"id": int, # 对象id(每个对象id都是唯一的,即不能出现重复)
}
参考文章
COCO数据集的使用笔记_学哥斌的博客-CSDN博客_coco数据集使用COCO数据集的使用一、简介二、数据集下载三、数据集说明3.1 通用字段3.2 非通用字段3.2.1 Object Detection(目标检测)3.2.2 Keypoint Detection(关键点检测)3.2.3 Stuff Segmentation(实例分割)3.2.4 Panoptic Segmentation(全景分割)3.2.5 Image Captioning(图像字幕)四、数据集...https://blog.csdn.net/qq_29051413/article/details/103448318?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164583812516780265484463%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164583812516780265484463&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-9-103448318.pc_search_result_cache&utm_term=coco%E6%95%B0%E6%8D%AE%E9%9B%86&spm=1018.2226.3001.4187
MS COCO数据集人体关键点评估(Keypoint Evaluation)(来自官网)_南国那片枫叶的博客-CSDN博客_coco 关键点数据集COCO系列文章:MS COCO数据集目标检测评估(Detection Evaluation)(来自官网)MS COCO数据集人体关键点评估(Keypoint Evaluation)(来自官网)MS COCO数据集输出数据的结果格式(result format)和如何参加比赛(participate)(来自官网)MS COCO官网数据集(百度云)下载,COCO API、MASK A...https://blog.csdn.net/u014734886/article/details/78837961
COCO 数据集的使用,以及下载链接_m0_37644085的博客-CSDN博客_coco数据集下载转于:https://www.cnblogs.com/q735613050/p/8969452.htmlWindows 10 编译 Pycocotools 踩坑记COCO数据库简介一、下载链接[1] - train2014 images: (13GB)http://images.cocodataset.org/zips/train2014.zip[2] - v...https://blog.csdn.net/m0_37644085/article/details/81948396?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164583812516780265484463%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164583812516780265484463&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-4-81948396.pc_search_result_cache&utm_term=coco%E6%95%B0%E6%8D%AE%E9%9B%86&spm=1018.2226.3001.4187