5.Spark 学习成果转化—机器学习—使用Spark ML的线性回归来预测商品销量 (线性回归问题)
本文目录如下:
- 第5例 使用Spark ML的线性回归来预测商品销量
-
- 5.1 数据准备
-
- 5.1.1 数据集文件准备
- 5.1.2 数据集字段解释(按列来划分)
- 5.2 使用 Spark ML 实现代码
-
- 5.2.1 引入项目依赖
- 5.2.2 加载并解析数据
- 5.2.3 对 DtaFrame 中的数据进行筛选与处理
- 5.2.4 将特征列合并为特征向量
- 5.2.5 创建 测试集 和 训练集
- 5.2.6 设置 回归参数 和 正则化参数
- 5.2.7 生成训练模型 并 对测试集进行预测
- 5.2.9 项目完整代码
- 附: 数据集文件: sale.csv
第5例 使用Spark ML的线性回归来预测商品销量
- 这是一个 线性回归 问题。
- 有关
Spark ML的介绍与知识点请参考: Spark ML学习笔记—Spark MLlib 与 Spark ML。
5.1 数据准备
5.1.1 数据集文件准备
-
(1) 该项目并为使用数据库当做数据源,而是直接将数据文件放在项目目录中, 这是一个结构化的简化数据集。
-
(2) 本项目使用的数据集
house.csv将在本博客末尾处给出。
5.1.2 数据集字段解释(按列来划分)
- 略…
5.2 使用 Spark ML 实现代码
注: 使用
Spark ML的过程中一定会涉及到对DataFrame格式的数据进行处理, 并且需要转换DataFrame格式与RDD格式, 因此需要对DataFrame相关知识有一定的了解。关于DataFrame的知识可以参考: SparkSQL基础—Spark SQL核心编程—DataFrame 中第2.2小节的描述。
5.2.1 引入项目依赖
使用的依赖包多数来自于 Spark ML, 而非 Spark MLlib。
import org.apache.spark.SparkConf
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.regression.LinearRegression
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
5.2.2 加载并解析数据
// 如果是已经处理好的结构化数据, 则可以直接使用这种方式读入数据, 但仍需要一些处理
// 文件读取出来就是 DataFrame 格式, 而不是 RDD 格式
val file: DataFrame = spark.read.format("csv").option("sep", "\t").option("header", "true").load("datas3/sale.csv")
file.show()
5.2.3 对 DtaFrame 中的数据进行筛选与处理
import spark.implicits._
// 对DtaFrame 中的数据进行筛选与处理, 并最后转化为一个新的 DataFrame
val dataPre = file.select("Sales", "TV", "Radio", "Newspaper")
.map(row => (row.getAs[String](0).toDouble, row.getString(1).toDouble, row.getAs[String](2).toDouble, row.getString(3).toDouble))
val data: DataFrame = dataPre.toDF("Sales", "TV", "Radio", "Newspaper")
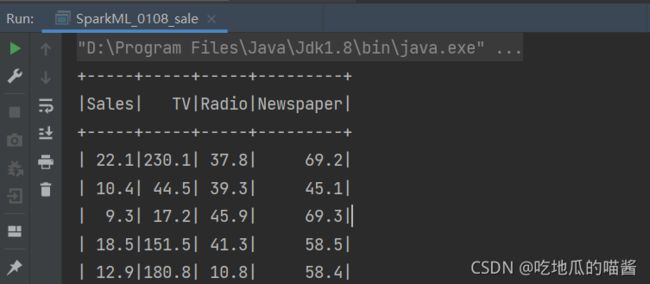
data.show()
转换后的数据帧如下图所示:
5.2.4 将特征列合并为特征向量
将特征列合并成为 特征向量:
// VectorAssembler 是一个转换器
val assembler = new VectorAssembler()
.setInputCols(Array("TV", "Radio", "Newspaper"))
.setOutputCol("features")
val dataset = assembler.transform(data)
dataset.show()
添加了特征向量的数据帧如下图所示 (最右侧一列为特征向量):

5.2.5 创建 测试集 和 训练集
//拆分成训练集和测试集
val Array(train, test) = dataset.randomSplit(Array(0.9,0.1),1234L)
5.2.6 设置 回归参数 和 正则化参数
// 设置线性回归参数
val lr1 = new LinearRegression()
.setLabelCol("Sales")
.setFeaturesCol("features")
.setFitIntercept(true) // 是否有w0截距
// 设置正则化参数
val lr2 = lr1.setMaxIter(30) // 最大迭代次数
.setRegParam(0.3)
.setElasticNetParam(0.8)
val regression = lr2
- 至此, 预测工作已经进行结束了, 剩下还有一些 观察训练过程 和 模型评估 的操作。
5.2.7 生成训练模型 并 对测试集进行预测
// 执行 fit() 函数生成训练模型
val model = regression.fit(train)
// 对测试集进行预测
valresult = model.transform(test)
result.show()
与其他几个案例相比,预测销售额案例的预测结果相对精准一些。预测结果如下图所示:
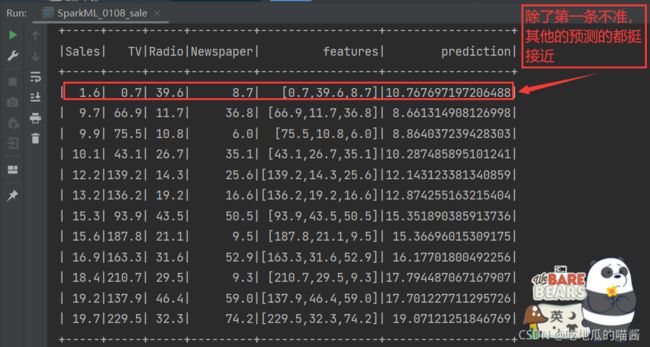
可以从图中看到,预测结果虽然相近,但还是有一定的误差的,这可能是因为训练数据集太少导致的。
5.2.9 项目完整代码
import org.apache.spark.SparkConf
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.regression.LinearRegression
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* 线性回归: 带有文件头的方式导入文件数据
*/
object SparkML_0108_sale {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("linear").setMaster("local")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// 如果是已经处理好的结构化数据, 则可以直接使用这种方式读入数据, 但仍需要一些处理
// 文件读取出来就是 DataFrame 格式, 而不是 RDD 格式
val file: DataFrame = spark.read.format("csv").option("sep", "\t").option("header", "true").load("datas3/sale.csv")
// file.show()
import spark.implicits._
// 对 DtaFrame 中的数据进行筛选与处理, 并最后转化为一个新的 DataFrame
val dataPre = file.select("Sales", "TV", "Radio", "Newspaper")
.map(row => (row.getAs[String](0).toDouble, row.getString(1).toDouble, row.getAs[String](2).toDouble, row.getString(3).toDouble))
val data: DataFrame = dataPre.toDF("Sales", "TV", "Radio", "Newspaper")
data.show()
// VectorAssembler 是一个转换器
val assembler = new VectorAssembler()
.setInputCols(Array("TV", "Radio", "Newspaper"))
.setOutputCol("features")
val dataset = assembler.transform(data)
dataset.show()
//拆分成训练集和测试集
val Array(train, test) = dataset.randomSplit(Array(0.9,0.1),1234L)
// 设置线性回归参数
val lr1 = new LinearRegression()
.setLabelCol("Sales")
.setFeaturesCol("features")
.setFitIntercept(true) // 是否有w0截距
// 设置正则化参数
val lr2 = lr1.setMaxIter(30) // 最大迭代次数
.setRegParam(0.3)
.setElasticNetParam(0.8)
val regression = lr2
val model = regression.fit(train)
val result = model.transform(test)
result.show()
/*
fit 做训练
transform 做预测
*/
}
}
附: 数据集文件: sale.csv
id TV Radio Newspaper Sales
1 230.1 37.8 69.2 22.1
2 44.5 39.3 45.1 10.4
3 17.2 45.9 69.3 9.3
4 151.5 41.3 58.5 18.5
5 180.8 10.8 58.4 12.9
6 8.7 48.9 75 7.2
7 57.5 32.8 23.5 11.8
8 120.2 19.6 11.6 13.2
9 8.6 2.1 1 4.8
10 199.8 2.6 21.2 10.6
11 66.1 5.8 24.2 8.6
12 214.7 24 4 17.4
13 23.8 35.1 65.9 9.2
14 97.5 7.6 7.2 9.7
15 204.1 32.9 46 19
16 195.4 47.7 52.9 22.4
17 67.8 36.6 114 12.5
18 281.4 39.6 55.8 24.4
19 69.2 20.5 18.3 11.3
20 147.3 23.9 19.1 14.6
21 218.4 27.7 53.4 18
22 237.4 5.1 23.5 12.5
23 13.2 15.9 49.6 5.6
24 228.3 16.9 26.2 15.5
25 62.3 12.6 18.3 9.7
26 262.9 3.5 19.5 12
27 142.9 29.3 12.6 15
28 240.1 16.7 22.9 15.9
29 248.8 27.1 22.9 18.9
30 70.6 16 40.8 10.5
31 292.9 28.3 43.2 21.4
32 112.9 17.4 38.6 11.9
33 97.2 1.5 30 9.6
34 265.6 20 0.3 17.4
35 95.7 1.4 7.4 9.5
36 290.7 4.1 8.5 12.8
37 266.9 43.8 5 25.4
38 74.7 49.4 45.7 14.7
39 43.1 26.7 35.1 10.1
40 228 37.7 32 21.5
41 202.5 22.3 31.6 16.6
42 177 33.4 38.7 17.1
43 293.6 27.7 1.8 20.7
44 206.9 8.4 26.4 12.9
45 25.1 25.7 43.3 8.5
46 175.1 22.5 31.5 14.9
47 89.7 9.9 35.7 10.6
48 239.9 41.5 18.5 23.2
49 227.2 15.8 49.9 14.8
50 66.9 11.7 36.8 9.7
51 199.8 3.1 34.6 11.4
52 100.4 9.6 3.6 10.7
53 216.4 41.7 39.6 22.6
54 182.6 46.2 58.7 21.2
55 262.7 28.8 15.9 20.2
56 198.9 49.4 60 23.7
57 7.3 28.1 41.4 5.5
58 136.2 19.2 16.6 13.2
59 210.8 49.6 37.7 23.8
60 210.7 29.5 9.3 18.4
61 53.5 2 21.4 8.1
62 261.3 42.7 54.7 24.2
63 239.3 15.5 27.3 15.7
64 102.7 29.6 8.4 14
65 131.1 42.8 28.9 18
66 69 9.3 0.9 9.3
67 31.5 24.6 2.2 9.5
68 139.3 14.5 10.2 13.4
69 237.4 27.5 11 18.9
70 216.8 43.9 27.2 22.3
71 199.1 30.6 38.7 18.3
72 109.8 14.3 31.7 12.4
73 26.8 33 19.3 8.8
74 129.4 5.7 31.3 11
75 213.4 24.6 13.1 17
76 16.9 43.7 89.4 8.7
77 27.5 1.6 20.7 6.9
78 120.5 28.5 14.2 14.2
79 5.4 29.9 9.4 5.3
80 116 7.7 23.1 11
81 76.4 26.7 22.3 11.8
82 239.8 4.1 36.9 12.3
83 75.3 20.3 32.5 11.3
84 68.4 44.5 35.6 13.6
85 213.5 43 33.8 21.7
86 193.2 18.4 65.7 15.2
87 76.3 27.5 16 12
88 110.7 40.6 63.2 16
89 88.3 25.5 73.4 12.9
90 109.8 47.8 51.4 16.7
91 134.3 4.9 9.3 11.2
92 28.6 1.5 33 7.3
93 217.7 33.5 59 19.4
94 250.9 36.5 72.3 22.2
95 107.4 14 10.9 11.5
96 163.3 31.6 52.9 16.9
97 197.6 3.5 5.9 11.7
98 184.9 21 22 15.5
99 289.7 42.3 51.2 25.4
100 135.2 41.7 45.9 17.2
101 222.4 4.3 49.8 11.7
102 296.4 36.3 100.9 23.8
103 280.2 10.1 21.4 14.8
104 187.9 17.2 17.9 14.7
105 238.2 34.3 5.3 20.7
106 137.9 46.4 59 19.2
107 25 11 29.7 7.2
108 90.4 0.3 23.2 8.7
109 13.1 0.4 25.6 5.3
110 255.4 26.9 5.5 19.8
111 225.8 8.2 56.5 13.4
112 241.7 38 23.2 21.8
113 175.7 15.4 2.4 14.1
114 209.6 20.6 10.7 15.9
115 78.2 46.8 34.5 14.6
116 75.1 35 52.7 12.6
117 139.2 14.3 25.6 12.2
118 76.4 0.8 14.8 9.4
119 125.7 36.9 79.2 15.9
120 19.4 16 22.3 6.6
121 141.3 26.8 46.2 15.5
122 18.8 21.7 50.4 7
123 224 2.4 15.6 11.6
124 123.1 34.6 12.4 15.2
125 229.5 32.3 74.2 19.7
126 87.2 11.8 25.9 10.6
127 7.8 38.9 50.6 6.6
128 80.2 0 9.2 8.8
129 220.3 49 3.2 24.7
130 59.6 12 43.1 9.7
131 0.7 39.6 8.7 1.6
132 265.2 2.9 43 12.7
133 8.4 27.2 2.1 5.7
134 219.8 33.5 45.1 19.6
135 36.9 38.6 65.6 10.8
136 48.3 47 8.5 11.6
137 25.6 39 9.3 9.5
138 273.7 28.9 59.7 20.8
139 43 25.9 20.5 9.6
140 184.9 43.9 1.7 20.7
141 73.4 17 12.9 10.9
142 193.7 35.4 75.6 19.2
143 220.5 33.2 37.9 20.1
144 104.6 5.7 34.4 10.4
145 96.2 14.8 38.9 11.4
146 140.3 1.9 9 10.3
147 240.1 7.3 8.7 13.2
148 243.2 49 44.3 25.4
149 38 40.3 11.9 10.9
150 44.7 25.8 20.6 10.1
151 280.7 13.9 37 16.1
152 121 8.4 48.7 11.6
153 197.6 23.3 14.2 16.6
154 171.3 39.7 37.7 19
155 187.8 21.1 9.5 15.6
156 4.1 11.6 5.7 3.2
157 93.9 43.5 50.5 15.3
158 149.8 1.3 24.3 10.1
159 11.7 36.9 45.2 7.3
160 131.7 18.4 34.6 12.9
161 172.5 18.1 30.7 14.4
162 85.7 35.8 49.3 13.3
163 188.4 18.1 25.6 14.9
164 163.5 36.8 7.4 18
165 117.2 14.7 5.4 11.9
166 234.5 3.4 84.8 11.9
167 17.9 37.6 21.6 8
168 206.8 5.2 19.4 12.2
169 215.4 23.6 57.6 17.1
170 284.3 10.6 6.4 15
171 50 11.6 18.4 8.4
172 164.5 20.9 47.4 14.5
173 19.6 20.1 17 7.6
174 168.4 7.1 12.8 11.7
175 222.4 3.4 13.1 11.5
176 276.9 48.9 41.8 27
177 248.4 30.2 20.3 20.2
178 170.2 7.8 35.2 11.7
179 276.7 2.3 23.7 11.8
180 165.6 10 17.6 12.6
181 156.6 2.6 8.3 10.5
182 218.5 5.4 27.4 12.2
183 56.2 5.7 29.7 8.7
184 287.6 43 71.8 26.2
185 253.8 21.3 30 17.6
186 205 45.1 19.6 22.6
187 139.5 2.1 26.6 10.3
188 191.1 28.7 18.2 17.3
189 286 13.9 3.7 15.9
190 18.7 12.1 23.4 6.7
191 39.5 41.1 5.8 10.8
192 75.5 10.8 6 9.9
193 17.2 4.1 31.6 5.9
194 166.8 42 3.6 19.6
195 149.7 35.6 6 17.3
196 38.2 3.7 13.8 7.6
197 94.2 4.9 8.1 9.7
198 177 9.3 6.4 12.8
199 283.6 42 66.2 25.5
200 232.1 8.6 8.7 13.4