54_pytorch GAN(生成对抗网络)、Gan代码示例、WGAN代码示例
1.54.GAN(生成对抗网络)
1.54.1.什么是GAN
2014 年,Ian Goodfellow 和他在蒙特利尔大学的同事发表了一篇震撼学界的论文。没错,我说的就是《Generative Adversarial Nets》,这标志着生成对抗网络(GAN)的诞生,而这是通过对计算图和博弈论的创新性结合。他们的研究展示,给定充分的建模能力,两个博弈模型能够通过简单的反向传播(backpropagation)来协同训练。
这两个模型的角色定位十分鲜明。给定真实数据集R,G是生成器(generator),它的任务是生成能以假乱真的假数据;而D是判别器(discriminator),它从真实数据集或者G那里获取数据,然后做出判别真假的标记。lan Goodfellow的比喻是,G就像一个赝品作坊,想要让做出来的东西尽可能接近真品,蒙混过关。而D就是文物鉴定专家,要能区分出真品和高仿(但在这个例子中,造假者G看不到原始数据,而只有D的鉴定结果—前者是在盲干)。
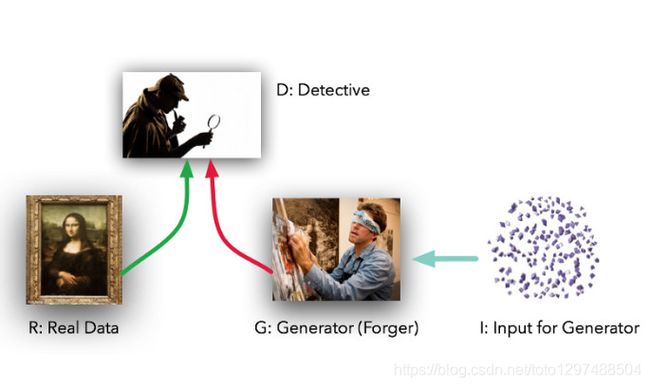
理想情况下,D和G都会随着不断训练,做的越来越好----直到G基本上成了一个”赝品制造大师”,而D因无法正确区分两种数据分布输给G。
一、GAN(Generative Adversarial Nets)
神经网络有很多种,常见的有如下几种:
1.普通的前向传播网络
2.用于分析图像的卷积神经网络。
3.用于分析语音或文字等序列信息的RNN神经网络。
以上三种网络都有一个共同点,就是通过数据和结果相关联,来实现自己网络的功能
还有一种比较特殊,可以理解为用来造数据的GAN网络 (生成对抗网络)
Generator根据随机数随机生成有意义的数据,Discriminator用来学习哪些数据是真实的,哪些数据是生成的然后反向传递给Generator,以此来生成更多有价值的数据。所以生成对抗网络就是两个网络,一个生成,一个对抗,对抗的结果是为了让生成网络达到预期的功能。
通过自己的学习过程理解,我认为G网络的目的就是输入随机数,但是可以根据随机数产生数据,产生的数据好不好由D网络说的算,D网络对于现有的数据进行学习和总结,然后指导G网络产生类似于现有的数据,D网络扮演了指导的作用。
最后就可以实现,对于输入的任意分布的随机数据,都可以产生和原数据相似的数据用于其他的用途,以上是我对GAN网络更朴素的理解
1.54.2.How to train
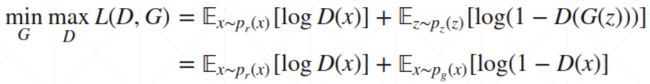
1.54.3.Gan代码示例
# -*- coding: UTF-8 -*-
import random
import numpy as np
import torch
import visdom
from matplotlib import pyplot as plt
from torch import nn, optim, autograd
h_dim = 400
batchsz = 512
viz = visdom.Visdom()
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.net = nn.Sequential(
nn.Linear(2, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, 2),
)
def forward(self, z):
output = self.net(z)
return output
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
nn.Linear(2, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, 1),
nn.Sigmoid()
)
def forward(self, x):
output = self.net(x)
return output.view(-1)
def data_generator():
scale = 2.
centers = [
(1, 0),
(-1, 0),
(0, 1),
(0, -1),
(1. / np.sqrt(2), 1. / np.sqrt(2)),
(1. / np.sqrt(2), -1. / np.sqrt(2)),
(-1. / np.sqrt(2), 1. / np.sqrt(2)),
(-1. / np.sqrt(2), -1. / np.sqrt(2))
]
centers = [(scale * x, scale * y) for x, y in centers]
while True:
dataset = []
for i in range(batchsz):
point = np.random.randn(2) * .02
center = random.choice(centers)
point[0] += center[0]
point[1] += center[1]
dataset.append(point)
dataset = np.array(dataset, dtype='float32')
dataset /= 1.414 # stdev
yield dataset
# for i in range(100000//25):
# for x in range(-2, 3):
# for y in range(-2, 3):
# point = np.random.randn(2).astype(np.float32) * 0.05
# point[0] += 2 * x
# point[1] += 2 * y
# dataset.append(point)
#
# dataset = np.array(dataset)
# print('dataset:', dataset.shape)
# viz.scatter(dataset, win='dataset', opts=dict(title='dataset', webgl=True))
#
# while True:
# np.random.shuffle(dataset)
#
# for i in range(len(dataset)//batchsz):
# yield dataset[i*batchsz : (i+1)*batchsz]
def generate_image(D, G, xr, epoch):
"""
Generates and saves a plot of the true distribution, the generator, and the
critic.
"""
N_POINTS = 128
RANGE = 3
plt.clf()
points = np.zeros((N_POINTS, N_POINTS, 2), dtype='float32')
points[:, :, 0] = np.linspace(-RANGE, RANGE, N_POINTS)[:, None]
points[:, :, 1] = np.linspace(-RANGE, RANGE, N_POINTS)[None, :]
points = points.reshape((-1, 2))
# (16384, 2)
# print('p:', points.shape)
# draw contour
with torch.no_grad():
points = torch.Tensor(points).cuda() # [16384, 2]
disc_map = D(points).cpu().numpy() # [16384]
x = y = np.linspace(-RANGE, RANGE, N_POINTS)
cs = plt.contour(x, y, disc_map.reshape((len(x), len(y))).transpose())
plt.clabel(cs, inline=1, fontsize=10)
# plt.colorbar()
# draw samples
with torch.no_grad():
z = torch.randn(batchsz, 2).cuda() # [b, 2]
samples = G(z).cpu().numpy() # [b, 2]
plt.scatter(xr[:, 0], xr[:, 1], c='orange', marker='.')
plt.scatter(samples[:, 0], samples[:, 1], c='green', marker='+')
viz.matplot(plt, win='contour', opts=dict(title='p(x):%d' % epoch))
def weights_init(m):
if isinstance(m, nn.Linear):
# m.weight.data.normal_(0.0, 0.02)
nn.init.kaiming_normal_(m.weight)
m.bias.data.fill_(0)
def gradient_penalty(D, xr, xf):
"""
:param D:
:param xr:
:param xf:
:return:
"""
LAMBDA = 0.3
# only constrait for Discriminator
xf = xf.detach()
xr = xr.detach()
# [b, 1] => [b, 2]
alpha = torch.rand(batchsz, 1).cuda()
alpha = alpha.expand_as(xr)
interpolates = alpha * xr + ((1 - alpha) * xf)
interpolates.requires_grad_()
disc_interpolates = D(interpolates)
gradients = autograd.grad(outputs=disc_interpolates, inputs=interpolates,
grad_outputs=torch.ones_like(disc_interpolates),
create_graph=True, retain_graph=True, only_inputs=True)[0]
gp = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * LAMBDA
return gp
def main():
torch.manual_seed(23)
np.random.seed(23)
G = Generator().cuda()
D = Discriminator().cuda()
G.apply(weights_init)
D.apply(weights_init)
optim_G = optim.Adam(G.parameters(), lr=1e-3, betas=(0.5, 0.9))
optim_D = optim.Adam(D.parameters(), lr=1e-3, betas=(0.5, 0.9))
data_iter = data_generator()
print('batch:', next(data_iter).shape)
viz.line([[0, 0]], [0], win='loss', opts=dict(title='loss',
legend=['D', 'G']))
for epoch in range(50000):
# 1. train discriminator for k steps
for _ in range(5):
x = next(data_iter)
xr = torch.from_numpy(x).cuda()
# [b]
predr = (D(xr))
# max log(lossr)
lossr = - (predr.mean())
# [b, 2]
z = torch.randn(batchsz, 2).cuda()
# stop gradient on G
# [b, 2]
xf = G(z).detach()
# [b]
predf = (D(xf))
# min predf
lossf = (predf.mean())
# gradient penalty
gp = gradient_penalty(D, xr, xf)
loss_D = lossr + lossf + gp
optim_D.zero_grad()
loss_D.backward()
# for p in D.parameters():
# print(p.grad.norm())
optim_D.step()
# 2. train Generator
z = torch.randn(batchsz, 2).cuda()
xf = G(z)
predf = (D(xf))
# max predf
loss_G = - (predf.mean())
optim_G.zero_grad()
loss_G.backward()
optim_G.step()
if epoch % 100 == 0:
viz.line([[loss_D.item(), loss_G.item()]], [epoch], win='loss', update='append')
generate_image(D, G, xr, epoch)
print(loss_D.item(), loss_G.item())
if __name__ == '__main__':
main()
1.54.4.WGAN代码示例
import torch
from torch import nn, optim, autograd
import numpy as np
import visdom
from torch.nn import functional as F
from matplotlib import pyplot as plt
import random
h_dim = 400
batchsz = 512
viz = visdom.Visdom()
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.net = nn.Sequential(
nn.Linear(2, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, 2),
)
def forward(self, z):
output = self.net(z)
return output
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
nn.Linear(2, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, 1),
nn.Sigmoid()
)
def forward(self, x):
output = self.net(x)
return output.view(-1)
def data_generator():
scale = 2.
centers = [
(1, 0),
(-1, 0),
(0, 1),
(0, -1),
(1. / np.sqrt(2), 1. / np.sqrt(2)),
(1. / np.sqrt(2), -1. / np.sqrt(2)),
(-1. / np.sqrt(2), 1. / np.sqrt(2)),
(-1. / np.sqrt(2), -1. / np.sqrt(2))
]
centers = [(scale * x, scale * y) for x, y in centers]
while True:
dataset = []
for i in range(batchsz):
point = np.random.randn(2) * .02
center = random.choice(centers)
point[0] += center[0]
point[1] += center[1]
dataset.append(point)
dataset = np.array(dataset, dtype='float32')
dataset /= 1.414 # stdev
yield dataset
# for i in range(100000//25):
# for x in range(-2, 3):
# for y in range(-2, 3):
# point = np.random.randn(2).astype(np.float32) * 0.05
# point[0] += 2 * x
# point[1] += 2 * y
# dataset.append(point)
#
# dataset = np.array(dataset)
# print('dataset:', dataset.shape)
# viz.scatter(dataset, win='dataset', opts=dict(title='dataset', webgl=True))
#
# while True:
# np.random.shuffle(dataset)
#
# for i in range(len(dataset)//batchsz):
# yield dataset[i*batchsz : (i+1)*batchsz]
def generate_image(D, G, xr, epoch):
"""
Generates and saves a plot of the true distribution, the generator, and the
critic.
"""
N_POINTS = 128
RANGE = 3
plt.clf()
points = np.zeros((N_POINTS, N_POINTS, 2), dtype='float32')
points[:, :, 0] = np.linspace(-RANGE, RANGE, N_POINTS)[:, None]
points[:, :, 1] = np.linspace(-RANGE, RANGE, N_POINTS)[None, :]
points = points.reshape((-1, 2))
# (16384, 2)
# print('p:', points.shape)
# draw contour
with torch.no_grad():
points = torch.Tensor(points).cuda() # [16384, 2]
disc_map = D(points).cpu().numpy() # [16384]
x = y = np.linspace(-RANGE, RANGE, N_POINTS)
cs = plt.contour(x, y, disc_map.reshape((len(x), len(y))).transpose())
plt.clabel(cs, inline=1, fontsize=10)
# plt.colorbar()
# draw samples
with torch.no_grad():
z = torch.randn(batchsz, 2).cuda() # [b, 2]
samples = G(z).cpu().numpy() # [b, 2]
plt.scatter(xr[:, 0], xr[:, 1], c='orange', marker='.')
plt.scatter(samples[:, 0], samples[:, 1], c='green', marker='+')
viz.matplot(plt, win='contour', opts=dict(title='p(x):%d'%epoch))
def weights_init(m):
if isinstance(m, nn.Linear):
# m.weight.data.normal_(0.0, 0.02)
nn.init.kaiming_normal_(m.weight)
m.bias.data.fill_(0)
def gradient_penalty(D, xr, xf):
"""
:param D:
:param xr:
:param xf:
:return:
"""
LAMBDA = 0.3
# only constrait for Discriminator
xf = xf.detach()
xr = xr.detach()
# [b, 1] => [b, 2]
alpha = torch.rand(batchsz, 1).cuda()
alpha = alpha.expand_as(xr)
interpolates = alpha * xr + ((1 - alpha) * xf)
interpolates.requires_grad_()
disc_interpolates = D(interpolates)
gradients = autograd.grad(outputs=disc_interpolates, inputs=interpolates,
grad_outputs=torch.ones_like(disc_interpolates),
create_graph=True, retain_graph=True, only_inputs=True)[0]
gp = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * LAMBDA
return gp
def main():
torch.manual_seed(23)
np.random.seed(23)
G = Generator().cuda()
D = Discriminator().cuda()
G.apply(weights_init)
D.apply(weights_init)
optim_G = optim.Adam(G.parameters(), lr=1e-3, betas=(0.5, 0.9))
optim_D = optim.Adam(D.parameters(), lr=1e-3, betas=(0.5, 0.9))
data_iter = data_generator()
print('batch:', next(data_iter).shape)
viz.line([[0,0]], [0], win='loss', opts=dict(title='loss',
legend=['D', 'G']))
for epoch in range(50000):
# 1. train discriminator for k steps
for _ in range(5):
x = next(data_iter)
xr = torch.from_numpy(x).cuda()
# [b]
predr = (D(xr))
# max log(lossr)
lossr = - (predr.mean())
# [b, 2]
z = torch.randn(batchsz, 2).cuda()
# stop gradient on G
# [b, 2]
xf = G(z).detach()
# [b]
predf = (D(xf))
# min predf
lossf = (predf.mean())
# gradient penalty
gp = gradient_penalty(D, xr, xf)
loss_D = lossr + lossf + gp
optim_D.zero_grad()
loss_D.backward()
# for p in D.parameters():
# print(p.grad.norm())
optim_D.step()
# 2. train Generator
z = torch.randn(batchsz, 2).cuda()
xf = G(z)
predf = (D(xf))
# max predf
loss_G = - (predf.mean())
optim_G.zero_grad()
loss_G.backward()
optim_G.step()
if epoch % 100 == 0:
viz.line([[loss_D.item(), loss_G.item()]], [epoch], win='loss', update='append')
generate_image(D, G, xr, epoch)
print(loss_D.item(), loss_G.item())
if __name__ == '__main__':
main()
1.54.5.参考文章
https://zhuanlan.zhihu.com/p/117529144
https://blog.csdn.net/jizhidexiaoming/article/details/96485095