Apache Hadoop 3.x高可用集群部署
Hadoop简介
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。

Hadoop核心组件有:
- HDFS(分布式文件系统):解决海量数据存储
- YARN(作业调度和集群资源管理的框架):解决资源任务调度
- MAPREDUCE(分布式运算编程框架):解决海量数据计算
hadoop集群规划
准备3个节点,节点角色规划如下:
| 主机名 | IP地址 | 组件 | ||||||
|---|---|---|---|---|---|---|---|---|
| hadoop01 | 192.168.93.61 | Zookeeper | NameNode | DataNode | NodeManage | ResourceManager | ZKFailoverController | journalnode |
| hadoop02 | 192.168.93.62 | Zookeeper | NameNode | DataNode | NodeManage | ResourceManager | ZKFailoverController | journalnode |
| hadoop03 | 192.168.93.63 | Zookeeper | NameNode | DataNode | NodeManage | ResourceManager | ZKFailoverController | journalnode |
节点规划说明:
- zookeeper集群需要至少3个节点,并且节点数为奇数个,可以部署在任意独立节点上,NameNode及ResourceManager依赖zookeeper进行主备选举和切换
- NameNode至少需要2个节点,一主多备,可以部署在任意独立节点上,用于管理HDFS的名称空间和数据块映射,依赖zookeeper和zkfc实现高可用和自动故障转移,并且依赖journalnode实现状态同步
- ZKFailoverController即zkfc,在所有NameNode节点上启动,用于监视和管理NameNode状态,参与故障转移
- DataNode至少需要3个节点,因为hdfs默认副本数为3,可以部署在任意独立节点上,用于实际数据存储
- ResourceManager:至少需要2个节点,一主多备,可以部署在任意独立节点上,依赖zookeeper实现高可用和自动故障转移,用于资源分配和调度
- NodeManage部署在所有DataNode节点上,用于节点资源管理和监控
- journalnode至少需要3个节点,并且节点数为奇数个,可以部署在任意独立节点上,用于主备NameNode状态信息同步
hadoop环境配置
以下操作在所有节点执行。
环境初始化
配置主机名
hostnamectl set-hostname hadoop01
hostnamectl set-hostname hadoop02
hostnamectl set-hostname hadoop03
配置主机名解析
cat > /etc/hosts <<EOF
192.168.93.61 hadoop01 zookeeper01
192.168.93.62 hadoop02 zookeeper02
192.168.93.63 hadoop03 zookeeper03
EOF
关闭防火墙和selinux
systemctl disable --now firewalld
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config && setenforce 0
配置时间同步
yum install -y chrony
systemctl enable --now chronyd
配置ssh免密
所有NameNode节点需要对DataNode节点免密,用于NameNode管理DataNode进程,所有NameNode节点之间也需要相互免密,用于故障切换。
3个节点生成公钥和私钥,3个节点上分别执行
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
3个节点对hadoop01节点免密,3个节点上分别执行
ssh-copy-id hadoop01
hadoop01节点执行,分发authorized_keys文件到其他节点
scp /root/.ssh/authorized_keys hadoop02:/root/.ssh/authorized_keys
scp /root/.ssh/authorized_keys hadoop03:/root/.ssh/authorized_keys
hadoop01节点执行,所有节点公钥写入known_hosts
ssh-keyscan -t ecdsa hadoop01 hadoop02 hadoop03 > /root/.ssh/known_hosts
hadoop01节点执行,分发known_hosts文件到其他节点
scp /root/.ssh/known_hosts hadoop02:/root/.ssh/
scp /root/.ssh/known_hosts hadoop03:/root/.ssh/
验证免密成功,任意namenode节点ssh到其他节点能够免密登录
ssh hadoop01
ssh hadoop02
ssh hadoop03
安装java环境
所有节点安装java,因为zookeeper及hadoop依赖java环境。
下载openjdk
#清华源
wget https://mirrors.tuna.tsinghua.edu.cn/AdoptOpenJDK/8/jdk/x64/linux/OpenJDK8U-jdk_x64_linux_hotspot_8u292b10.tar.gz
解压安装
mkdir /opt/openjdk
tar -zxvf OpenJDK8U-jdk_x64_linux_hotspot_8u292b10.tar.gz -C /opt/openjdk --strip=1
配置环境变量
cat > /etc/profile.d/openjdk.sh <<'EOF'
export JAVA_HOME=/opt/openjdk
export PATH=$PATH:$JAVA_HOME/bin
EOF
source /etc/profile
确认安装成功
java -version
NameNode主备切换依赖fuser,所有nameNode节点安装psmisc
yum install -y psmisc
安装zookeeper集群
使用hadoop01、hadoop02及hadoop03节点部署zookeeper集群,以下操作在3个节点上执行。
创建zookeeper相关目录
mkdir -p /opt/zookeeper/{data,logs}
安装zookeeper
wget https://mirrors.aliyun.com/apache/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz -P /tmp
tar -zxvf /tmp/apache-zookeeper-*-bin.tar.gz -C /opt/zookeeper --strip=1
配置环境变量
cat > /etc/profile.d/zookeeper.sh <<'EOF'
export ZOOKEEPER_HOME=/opt/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH
EOF
source /etc/profile
复制zookeeper配置文件
cp /opt/zookeeper/conf/{zoo_sample.cfg,zoo.cfg}
修改zookeeper配置文件
cat > /opt/zookeeper/conf/zoo.cfg <<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/logs
clientPort=2181
server.1=zookeeper01:2888:3888
server.2=zookeeper02:2888:3888
server.3=zookeeper03:2888:3888
EOF
创建myid文件,id在整体中必须是唯一的,并且应该具有1到255之间的值,主配置文件中的server id 要和其当前主节点中的myid保持一致,分别在3个节点上执行
[root@hadoop01 ~]# echo '1' >/opt/zookeeper/data/myid
[root@hadoop02 ~]# echo '2' >/opt/zookeeper/data/myid
[root@hadoop03 ~]# echo '3' >/opt/zookeeper/data/myid
创建zookeeper用户
useradd -r -s /bin/false zookeeper
chown -R zookeeper: /opt/zookeeper
使用systemd管理zookeeper服务
cat > /usr/lib/systemd/system/zookeeper.service << EOF
[Unit]
Description=Zookeeper Service
[Service]
Type=simple
WorkingDirectory=/opt/zookeeper/
PIDFile=/opt/zookeeper/data/zookeeper_server.pid
SyslogIdentifier=zookeeper
User=zookeeper
Group=zookeeper
ExecStart=/opt/zookeeper/bin/zkServer.sh start
ExecStop=/opt/zookeeper/bin/zkServer.sh stop
Restart=always
TimeoutSec=20
SuccessExitStatus=130 143
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
启动zookeeper服务,并设为开机启动
systemctl enable --now zookeeper
查看zookeeper主备状态
zkServer.sh status
下载安装hadoop
以下操作在所有3个节点执行。
下载hadoop:
wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz -P /tmp
解压安装
tar -zxvf hadoop-3.3.0.tar.gz -C /opt/
mv /opt/hadoop-3.3.0 /opt/hadoop
配置环境变量
cat >/etc/profile.d/hadoop.sh<<'EOF'
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
EOF
source /etc/profile
查看hadoop版本
hadoop version
修改hadoop-env.sh,修改环境变量JAVA_HOME为绝对路径,并将用户指定为root。
cat >> /opt/hadoop/etc/hadoop/hadoop-env.sh <<EOF
export JAVA_HOME=$JAVA_HOME
export HADOOP_PID_DIR=$HADOOP_HOME/tmp/pids
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
EOF
修改yarn-env.sh修改用户为root。
cat >> /opt/hadoop/etc/hadoop/yarn-env.sh <<EOF
export YARN_REGISTRYDNS_SECURE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
EOF
修改hadoop配置
在各个节点上安装与配置Hadoop的过程都基本相同,因此可以在每个节点上安装好Hadoop后,在第一个节点hadoop01上进行统一配置,然后通过scp 命令将修改的配置文件拷贝到各个节点上即可。
Hadoop安装目录下的etc/hadoop目录中,需修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers文件,根据实际情况修改配置信息。
以下所有配置修改操作在第一个节点hadoop01执行。
1、修改core-site.xml配置文件
配置Common组件属性
cat > /opt/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://myclustervalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/hadoop/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>4096value>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>zookeeper01:2181,zookeeper02:2181,zookeeper03:2181value>
property>
configuration>
EOF
配置说明:
- fs.defaultFS 指定HDFS中NameNode的地址
- hadoop.tmp.dir 指定hadoop运行时产生文件的存储目录,是其他临时目录的父目录
- ha.zookeeper.quorum ZooKeeper地址列表,ZKFailoverController将在自动故障转移中使用这些地址。
- io.file.buffer.size 在序列文件中使用的缓冲区大小,流文件的缓冲区为4K
更多配置信息,请参考core-site.xml。
2、修改hdfs-site.xml配置文件
配置hdfs-site.xml文件,配置HDFS组件属性
cat > /opt/hadoop/etc/hadoop/hdfs-site.xml << 'EOF
<configuration>
<property>
<name>dfs.nameservicesname>
<value>myclustervalue>
property>
<property>
<name>dfs.ha.namenodes.myclustername>
<value>nn1,nn2,nn3value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1name>
<value>hadoop01:8020value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2name>
<value>hadoop02:8020value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3name>
<value>hadoop03:8020value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1name>
<value>hadoop01:9870value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2name>
<value>hadoop02:9870value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3name>
<value>hadoop03:9870value>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.blocksizename>
<value>134217728value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file://${hadoop.tmp.dir}/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file://${hadoop.tmp.dir}/dfs/datavalue>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/myclustervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/opt/hadoop/tmp/dfs/journalvalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.myclustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
configuration>
EOF
配置说明:
- dfs.nameservices 配置命名空间,所有namenode节点配置在命名空间mycluster下
- dfs.replication 指定dataNode存储block的副本数量,默认值是3个
- dfs.blocksize 大型文件系统HDFS块大小为256MB,默认是128MB
- dfs.namenode.rpc-address 各个namenode的 rpc通讯地址
- dfs.namenode.http-address 各个namenode的http状态页面地址
- dfs.namenode.name.dir 存放namenode名称表(fsimage)的目录
- dfs.datanode.data.dir 存放datanode块的目录
- dfs.namenode.shared.edits.dir HA集群中多个NameNode之间的共享存储上的目录。此目录将由活动服务器写入,由备用服务器读取,以保持名称空间的同步。
- dfs.journalnode.edits.dir 存储journal edit files的目录
- dfs.ha.automatic-failover.enabled 是否启用故障自动处理
- dfs.ha.fencing.methods 处于故障状态的时候hadoop要防止脑裂问题,所以在standby机器切换到active后,hadoop还会试图通过内部网络的ssh连过去,并把namenode的相关进程给kill掉,一般是sshfence 就是ssh方式
- dfs.ha.fencing.ssh.private-key-files 配置了 ssh用的 key 的位置。
更多参数配置,请参考hdfs-site.xml。
3、修改mapred-site.xml配置文件
配置Map-Reduce组件属性
cat > /opt/hadoop/etc/hadoop/mapred-site.xml <
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>0.0.0.0:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>0.0.0.0:19888value>
property>
configuration>
EOF
配置说明
- mapreduce.framework.name 设置MapReduce运行平台为yarn
- mapreduce.jobhistory.address 历史服务器的地址
- mapreduce.jobhistory.webapp.address 历史服务器页面的地址
更多配置信息,请参考mapred-site.xml。
4、修改yarn-site.xml配置文件
Yarn的HA架构基本上和HDFS一样,也是通过zk选举RM来实现高可用,参考:ResourceManagerHA
配置yarn-site.xml文件:
cat > /opt/hadoop/etc/hadoop/yarn-site.xml <
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>cluster1value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2,rm3value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>hadoop01value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>hadoop02value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm3name>
<value>hadoop03value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>hadoop01:8088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>hadoop02:8088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3name>
<value>hadoop03:8088value>
property>
<property>
<name>hadoop.zk.addressname>
<value>zookeeper01:2181,zookeeper02:2181,zookeeper03:2181value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
configuration>
EOF
配置说明,更多配置信息,请参考yarn-site.xml。
- yarn.resourcemanager.hostname 配置yarn启动的主机名,也就是说配置在哪台虚拟机上就在那台虚拟机上进行启动
- yarn.application.classpath 配置yarn执行任务调度的类路径,如果不配置,yarn虽然可以启动,但执行不了mapreduce。执行hadoop classpath命令,将出现的类路径放在标签里
5、修改workers配置文件
cat > /opt/hadoop/etc/hadoop/workers <<EOF
hadoop01
hadoop02
hadoop03
EOF
配置说明
- workers 配置datanode工作的机器,而datanode主要是用来存放数据文件的
6、分发配置文件
分发配置文件到其他节点
scp /opt/hadoop/etc/hadoop/* hadoop02:/opt/hadoop/etc/hadoop/
scp /opt/hadoop/etc/hadoop/* hadoop03:/opt/hadoop/etc/hadoop/
启动hadoop服务
按以下顺序启动hadoop相关服务:
1、初始化zookeeper
格式化ZooKeeper集群,目的是在ZooKeeper集群上建立HA的相应节点,任意节点执行
hdfs zkfc -formatZK
验证zkfc是否格式化成功
# zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /hadoop-ha
[mycluster]
2、启动journalnode
在hadoop01、hadoop02及hadoop03节点启动journalnode
hdfs --daemon start journalnode
3、启动namenode
在其中一个namenode节点执行格式化,以在hadoop01节点为例
hdfs namenode -format
启动hadoop01节点nameNode
hdfs --daemon start namenode
将hadoop01节点上namenode的数据同步到其他nameNode节点,在hadoop02、hadoop03节点执行:
hdfs namenode -bootstrapStandby
启动hadoop02及hadoop03节点nameNode
hdfs --daemon start namenode
浏览器访问NameNode,当前所有NameNode都是standby状态:
http://192.168.93.61:9870/
http://192.168.93.62:9870/
http://192.168.93.63:9870/
4、启动所有其他服务,包括zkfc
start-all.sh
此时再次查看nameNode界面,发现已经选举出一个active节点:
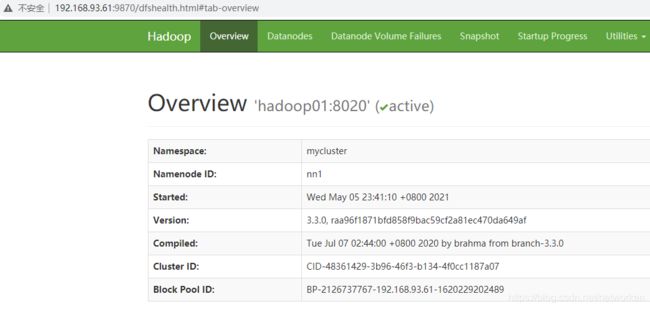
查看rm主备状态
[root@hadoop01 ~]# yarn rmadmin -getServiceState rm1
standby
[root@hadoop01 ~]# yarn rmadmin -getServiceState rm2
standby
[root@hadoop01 ~]# yarn rmadmin -getServiceState rm3
active
启动成功之后,使用jps可以看到各个节点的进程。
[root@hadoop01 ~]# jps
3329 DFSZKFailoverController
3939 NodeManager
2854 DataNode
2008 QuorumPeerMain
2424 NameNode
3784 ResourceManager
2266 JournalNode
4282 Jps
[root@hadoop02 ~]# jps
2753 ResourceManager
2836 NodeManager
2469 DataNode
2134 JournalNode
1979 QuorumPeerMain
2283 NameNode
2652 DFSZKFailoverController
3311 Jps
[root@hadoop03 ~]# jps
1971 QuorumPeerMain
2659 DFSZKFailoverController
2838 NodeManager
2760 ResourceManager
2138 JournalNode
2474 DataNode
2287 NameNode
3247 Jps
使用systemd管理hadoop服务,所有节点配置
cat > /usr/lib/systemd/system/hadoop.service <<EOF
[Unit]
Description=hadoop
After=syslog.target network.target remote-fs.target nss-lookup.target network-online.target
Requires=network-online.target
[Service]
User=root
Group=root
Type=forking
ExecStart=/opt/hadoop/sbin/start-all.sh
ExecStop=/opt/hadoop/sbin/stop-all.sh
WorkingDirectory=/opt/hadoop/
TimeoutStartSec=1min
Restart=no
RestartSec=30
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
EOF
启动hadoop服务并设为开机启动,所有节点执行
systemctl enable --now hadoop
验证hadoop功能
1、验证HDFS功能
[root@hadoop01 ~]# hadoop fs -put anaconda-ks.cfg /test
[root@hadoop01 ~]# hadoop fs -ls /test
-rw-r--r-- 3 root supergroup 1722 2021-04-18 07:07 /test
2、验证YARN功能
[root@hadoop01 ~]# hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 10 100
......
Job Finished in 3.059 seconds
Estimated value of Pi is 3.14800000000000000000
3、验证mapreduce功能
echo "hello hadoop" > wordtest
hadoop fs -put wordtest /wordtest
执行 mapreduce 后生成结果文件
hadoop jar /mywork/hadoop-3.1.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /wordtest /result
查看统计结果
hadoop fs -cat /result/part-r-00000
4、验证HA高可用性
测试是否能够完成自动故障转移。
在master1节点active namenode上执行 jps ,确定namenode进程,kill 将其杀掉
[root@hadoop01 ~]# kill -9 2424
之后刷新页面我们发现hadoop02节点(原standy)自动变成了 active namenode。

或者使用curl命令查看主备状态:
[root@hadoop01 ~]# curl http://hadoop02:9870/jmx?qry=Hadoop:service=NameNode,name=NameNodeStatus
{
"beans" : [ {
"name" : "Hadoop:service=NameNode,name=NameNodeStatus",
"modelerType" : "org.apache.hadoop.hdfs.server.namenode.NameNode",
"State" : "active",
"NNRole" : "NameNode",
"HostAndPort" : "hadoop02:8020",
"SecurityEnabled" : false,
"LastHATransitionTime" : 1620230821640,
"BytesWithFutureGenerationStamps" : 0,
"SlowPeersReport" : null,
"SlowDisksReport" : null
} ]
}
其他维护命令
如果手动方式启动可以执行以下命令:
#启动zkfc
hdfs --daemon start zkfc
#启动yarn
start-yarn.sh
#启动所有的HDFS服务
start-dfs.sh
stop-dfs.sh
#启动datanode
hdfs --daemon start datanode
#启动nodemanager
hdfs --daemon start nodemanager
访问hadoop01的8088端口查看ResourceManager的UI界面
http://192.168.93.61:8088/