HDFS学习笔记 【Namenode/数据块管理】
说明
Namenode关于数据块管理主要做两方面的事情。
文件系统对应数据块
数据块对应数据节点
Block的数据结构
通过Block,BlockInfo,BlocksMap,replica等数据结构表示数据块。
Block
唯一标识一个数据块
包含有比较方法,通过blockId进行比较
BlockInfo
block的补充说明,包括block的副本在哪个HDFS文件
Object[] triplets,包含一个隐形的双链表。DatanodeStorageInfo, 前一个BlockInfo,后一个BlockInfo.
BlocksMap
管理Namenode上数据块的元数据,包括当前数据块属于哪一个HDFS文件,当前数据块保存在哪些Datanode上。
保存了什么信息
获取数据块对应的hdfs文件
获取数据块对应的datanode节点
何时保存的
datanode启动时,扫描本地磁盘。
如何保存的
维护 block-> blockInfo信息对应关系
blockInfo是通过上报更新的,无论是datanode启动上报还是增量上报
replica
replicastate表示副本的状态
FINALIZED,RBW,RUR,RWR,TEMPORARY
Block状态类
Block也包含有不同的状态。
通过副本的状态来判断是否可以读取,是否可以关闭文件。
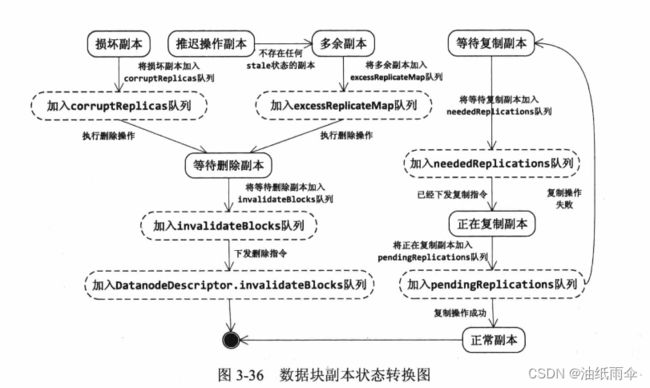
数据块副本的状态
在文件系统中的数据称为数据块,在datanode中的数据称为副本。对于副本的不同状态,NN需要做不同的操作。
通过BlockManager类,
不同状态的副本类,
副本所在datanode状态来实现状态转移。
BlockManager数据结构
BlockManager维护多个不同状态的副本
损坏的副本
多余的副本
无效的副本
需要复制的副本
需要等待切换汇报的Block队列(防止HA切换多删除)
不同状态的副本通过不同的数据结构保存,比如损坏的,使用CorruptReplicasMap会记录损坏的原因。
需要复制的副本,会使用优先队列使用独立线程进行处理。为了防止失败,先在内存中保存,等待增量汇报后进行处理。
数据块副本状态
数据块的状态和BlockManager描述一致
只不过增加了两个正在进行时的状态
正在构建状态(客户端写入)
恢复状态(客户端写入失败)
状态转移
通过队列的修改实现状态转移
元数据管理
集群中所有数据块的数据称为元数据。
通过BlockManager类实现复制管理和状态管理来完成元数据管理。
不同状态队列处理
PendingReplications线程: 处理超时块复制
replicationThread线程: 处理块复制
复制操作
replicationThread循环执行两个操作:
computeDatanodework
从neededReplicaitons里面取复制任务执行,里面包含两个任务,增加或者是删除。逻辑差不多,以增加为例。
computeReplicationWorkForBlocks方法
包含四个小步骤
- 找到需要复制的块
neededReplications优先队列执行 - 找到复制的源节点
chooseSource,找到符合条件的节点。 - 找到复制的目的节点
chooseTarget,机架感知法 - 保存复制命令(心跳执行)
加入到心跳的任务队列中
加入到等待确认的队列中。pendingReplications
processpendingreplications
pendingReplications队列中超时操作的重新加到neetedReplications队列中。
数据块的增删改查
BlockManager管理两个块映射关系
块映射节点 blockInfo
节点映射块 datastorage.blocklist
增加数据块
客户端向NN申请增加数据块
NN检查文件系统状态,选择DN,构造Block对象,加入到INode对应的对象中。
再构造BlockInfo,加入到BlockManager.BlocksMap中
增加副本
dn上增加了副本,需要在心跳时向NN同步,然后NN更改副本状态。
向NN汇报的块操作,最终会调用NN的BlockManager.addStoredBlock()方法。
- 首先维护块和DN之间的关系。BlockInfo信息
- 其次维护数据节点的块信息。 DatasetStorageInfo信息
- 数据块(Block)具有状态,如果副本块的状态是Complete,调用complete方法修改数据块状态。
- 判断是否副本满足期望,如果不满足那么修改updateneedReplicas队列
- 判断是超出了副本数,超出的副本放到excessReplicaMap队列。
- 删除损坏的副本
删除数据块
- INode中级联的找到所有的数据块
- 租约管理器删除Inode文件的租约
- deleteInternal删除所有的数据块
删除数据块,其实就是遍历加入invalidateBlocks队列。其他队列中也删除该数据块。
删除副本
三种情况下可以删除副本
- 删除数据块
- 副本数过多时
- 副本被标识为损坏副本
注意维护损坏副本的队列,corruptReplicas以及invalidateBlocks
数据块复制
needReplicatetions队列
三种情况下需要数据块复制
- 客户端完成写文件,副本数不足
- datanode撤销时
- pendingReplications任务超时
在HDFS客户端删除副本,重置副本数,或者报告副本损坏时,会进行数据块复制操作。
元数据的汇报
块的存储关系是在内存中进行动态更新的。底层依赖dn向nn进行汇报。
dn向nn汇报共有三种方式。
全量块汇报
何时汇报
启动时进行一次,定期默认6h进行一次
如何统计
Datanode上的数据结构进行统计。FsVolume中存储了所有的块信息。
如何汇报
Datanode的BPServiceActor进行汇报
NN响应汇报,分为两种,第一次和其他。
如何响应
NN第一次响应,对比NN内存中的块和DN汇报的块,以及块的不同状态,从而同步到不同的状态队列(忽略掉NN中不存在的)。
这时候内存中加载的应该仅仅是BlockId
普通块汇报
NN处理心跳,将不同的块汇报分到5中不同的队列中进行处理
什么队列
- toADD
- toRemove
副本不存在 - toInvalidate
块不存在 - toCorrupt
- toUC
构建中的块
谁处理队列
NN调用reportDiff方法,对比内存中和块汇报的副本状态
增量块汇报
何时汇报
默认300s进行一次汇报
增加数据块
调用addBlock方法
删除数据块
调用removeStorageBlock方法,修改数据块和节点的映射关系
增加副本
修改datanodeDescriptor上面BlockScheuler计数
移除pendingReplications请求
处理副本为提交状态的数据块副本
小结
Block具有状态,NN维护数据块和数据节点以及数据块和文件系统的关系。(最终目的是维护数据块和DN汇报的一致性)
NN通过不同的队列来维护数据块的不同状态。
数据块的复制是使用了两个线程处理不同的队列,复制队列和超时队列。
数据块的删除也是维护一个删除队列。BlockManager处理。
数据块具有不同的汇报方式,NN得到汇报之后,进行数据块的具体操作。