二、快速开始一个Go程序
本节源代码:https://github.com/goinaction/code/tree/master/chapter2/sample
本节实现一个完整的Go语言程序,这个程序从不同的数据源拉取数据,将数据内容与一组搜索项做对比,然后将匹配的内容显示在终端窗口。这个程序会读取文本文件,进行网络调用,解码XML和JSON成为结构化类型数据,并且利用Go语言的开发机制保证这些操作的速度。
1、程序架构
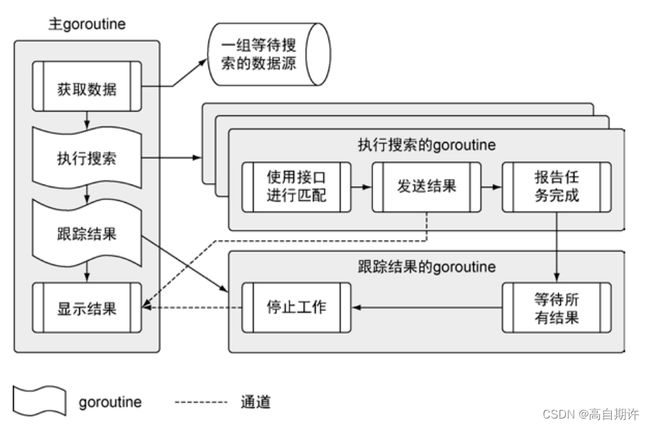
一个程序分成多个不同步骤,在多个不同的goroutine里运行,从主goroutine开始,一直到执行搜索的goroutine和跟踪结果的goroutine。最后回到主goroutine。

上图是应用程序的项目结构。
data.json主要内容是程序要拉取和处理的数据源。
rss.go中包含程序里用于支持搜索不同数据源的代码。
search文件夹中包含使用不同匹配器进行搜索的业务逻辑。
最后父级文件夹中有个main.go文件是整个程序的入口。
2、main包
下面先给出main.go文件的内容
package main
import (
//导入标准库里的log和os包
"log"
"os"
//前面加下划线对包做初始化操作,但是并不使用包里的标识符
//因为Go编译器不允许声明导入某个包却不使用,下划线让编译器接受这类导入
//并且调用对应包内的所有代码文件里定义的init函数
//这样做的目的是调用matchers包中的rss.go代码文件里定义的init函数
_ "github.com/goinaction/code/chapter2/sample/matchers"
//导入search包就可以引用其中的Run函数
"github.com/goinaction/code/chapter2/sample/search"
)
//init在main之前调用
func init() {
//将日志输出到标准输出
log.SetOutput(os.Stdout)
}
//main是整个程序的入口
func main() {
//使用特定的项做搜索
search.Run("president")
}
main函数保存在名为main的包里。如果main函数不在main包里,构建工具就不会生成可执行文件。一个包定义一组编译过的代码,包的名字类似于命名空间,可以用来间接访问包内声明的标识符。
import声明了所有的导入项,这段程序的导入就可以使main.go里的代码就可以引用search包里的Run函数。
3、search包
search.go
package search
import (
"log"
"sync"
)
//注册用于搜索的匹配器的映射
//声明为Matcher类型的映射(map),这个映射以string类型值作为键,Matcher类型值作为映射后的值,Matcher类型在代码文件matcher.go中声明。
//map是Go语言里的一个引用类型,需要make来构造
var matchers = make(map[stirng]Matcher)
func Run(searchTerm string) {
//获取需要搜索的数据源列表
//RetrieveFeeds函数返回两个值
//第一个值是一组Feed类型的切片,其是一种实现了动态数组的引用类型
//第二个值是一个错误值,检查其是不是真的错误,如果是真的,调用Fatal函数将其在终端输出
feeds, err := RetrieveFeeds()
if err != nil {
log.Fatal(err)
}
//创建一个无缓冲的通道,接受匹配后的结果
results := make(chan *Result)
//构造一个waitGroup,以便处理所有的数据源
var waitGroup sync.WaitGroup
//设置需要等待处理每个数据源的goroutine的数量
waitGroup.Add(len(feeds)
//为每个数据源启动一个goroutine来查找结果
//下划线标识符的作用是占位符,占据了保存range调用返回的索引值的变量的位置
//如果调用的函数返回多个值,而又不需要其中的某个值,就可以使用下划线标识符将其忽略
//在这里,我们不需要使用返回的索引值,所以就使用下划线标识符把它忽略掉
for _, feed := range feeds {
//获取一个匹配器用于查找
matchers, exists := matchers[feed.Type]
if !exists {
matcher = matchers["default"]
}
//启动一个goroutine来执行搜索
//这里使用关键字go启动一个**匿名函数**作为goroutine
go func(matcher Matcher, feed *Feed) {
Match(matcher, feed, searchTerm, results)
waitGroup.Done()
}(matcher, feed)
}
//启动一个goroutine来监控是否所有的工作都做完了
go func() {
//等候所有任务完成
waitGroup.Wait()
//用关闭通道的方式通知Display函数可退出程序了
close(results)
}()
//启动函数,显示返回的结果,并且在最后一个结果显示完后返回
Display(results)
}
//Register调用时会注册一个匹配器,提供给后面的程序使用
func Register(feedType string, matcher Matcher) {
if _, exists := matchers[feedType]; exists {
log.Fatalln(feedType, "Matcher already registered")
}
log.Println("Register", feedType, "matcher")
matchers[feedType] = matcher
}
注意:①、标识符以大写字母开头是公开的,任何导入这个包的代码都能直接访问,以小写字母开头的标识符是不公开的。
②、在Go语言中,所有变量都被初始化为其零值。对于数值类型,零值是0;对于字符串类型,零值是空字符串;对于布尔类型,零值是false;对于指针零值是nil。对于引用类型来说,所引用的底层数据结构会被初始化为对应的零值。
③、:=是简化变量声明运算符,这个运算符用于声明一个变量,同时给这个变量赋予初始值。
④、在Go语言中,如果main函数返回,整个程序也就终止了。Go程序终止时,还会关闭所有之前启动的goroutine。写并发程序的时候,最佳做法是在main函数返回之前清理并终止所有之前启动的goroutine。
这个程序使用sync包的WaitGroup跟踪所有启动的goroutine。非常推荐Waitgroup来跟踪goroutine的工作是否完成。WaitGroup是一个计数信号量,我们可以利用它来统计所有的goroutine是不是都完成了工作。
⑤、下划线标识符作为占位符使用时,占据了保存range调用返回的索引值的变量的位置。如果调用的函数返回多个值,而又不需要其中的某个值,就可以使用下划线标识符将其忽略。在这里,我们不需要使用返回的索引值,所以就使用下划线标识符把它忽略掉
⑥、一个goroutine是一个独立于其他函数运行的函数。使用关键字go启动一个goroutine
⑦、匿名函数也可以接受声明时指定的参数。这里我们指定匿名函数要接受两个参数,一个类型为Matcher,另一个是指向一个Feed类型值的指针。
feed.go
package search
//json包提供编解码JSON的功能
//os包能提供访问操作系统的功能
import (
"encoding/json"
"os"
)
const dataFile = "data/data.json"
//Feed包含我们需要处理的数据源的信息
type Feed struct {
Name string 'json:"site"'
URI string 'json:"link"'
TYPE string 'json:"type"'
}
//读取并反序列化源数据文件
func RetrieveFeeds() ([]*Feed, error) {
//打开文件
file, err := os.Open(dataFile)
if err != nil {
return nil, err
}
//当函数返回时关闭文件
defer file.Close()
//将文件解码到一个切片里
//这个切片的每一项是一个指向一个Feed类型值的指针
var feeds []*Feed
err = json.NewDecoder(file).Decode(&feeds)
//这个函数不需要检查错误,调用者会做这件事
return feeds, err
}
①Go编译器可以根据赋值运算符右边的值来推导类型,声明常量的时候不需要指定类型
②关键字defer会安排随后的函数调用在函数返回时才执行
data.json
[
{
"site" : "npr",
"link" : "http://www.npr.org/rss/rss.php?id=1001",
"type" : "rss"
},
{
"site" : "npr",
"link" : "http://www.npr.org/rss/rss.php?id=1008",
"type" : "rss"
},
{
"site" : "npr",
"link" : "http://www.npr.org/rss/rss.php?id=1006",
"type" : "rss"
},
{
"site" : "npr",
"link" : "http://www.npr.org/rss/rss.php?id=1007",
"type" : "rss"
}
...
]
json数据文件包含一个JSON文档数组。数组的每一项都是一个JSON文档,包含获取数据的网站名,数据的链接以及我们期望获得的数据类型。
match.go
package search
import (
"log"
)
//Result保存搜索的结果
type Result struct {
Field string
Content string
}
//Matcher定义了要实现的新搜索类型的行为
type Matcher interface {
Search(feed *Feed, SearchTerm string)([]*Result, error)
}
//为每个数据源单独启动goroutine来执行这个函数
func Match(matcher Matcher, feed *Feed, searchTerm string, results chan<- *Result) {
searchResults, err := matcher.Search(feed, searchTerm)
if err != nil {
log.Printlf(err)
return
}
for _, result := range searchResults {
results <- result
}
}
func Display(results chan *Result) {
//通道会一直被阻塞,直到有结果写入
//一旦通道被关闭,for循环就会终止
for result := range results {
fmt.Printf("%s:\n%s\n\n", result.Field, result.Content)
}
}
①interface关键字声明了一个接口,这个接口声明了结构类型或者具名类型需要实现的行为。一个接口的行为最终由在这个接口类型中声明的方法决定
②对于Matcher这个接口来说,只声明了一个Search方法,这个方法输入一个指向Feed类型值的指针和一个string类型的搜索项。这个方法返回两个值:一个指向Result类型值的指针的切片,另一个是错误值
③Golang惯例,如果接口类型只包含一个方法,那么这个类型的名字以er结尾
default.go
package search
//defaultMatcher实现了默认匹配器
type defaultMatcher struct{}
//init函数将默认匹配器注册到程序里
func init() {
var matcher defaultMatcher
Register("default", matcher)
}
//Search实现了默认匹配器的行为
func (m defaultMatcher)Search(feed *Feed, searchTerm string)([]*Result, error){
return nil, nil
}
4、RSS匹配器
一个期望的RSS数据源文档举例
<rss xmlns:npr="http://www.npr.org/rss/" xmlns:nprml="http://api"
>
<title>Newstitle>
<link>...link>
<description>...description>
<language>enlanguage>
<copyright>Copyright 2014 NPR - For Personal Use
<image>...image>
<item>
<title>
Putin Says He'll Respect Ukraine Vote But U.S.
title>
<description>
The White House and State Department have called on the
description>
rss.go
package matchers
import (
"encoding/xml"
"errors"
"fmt"
"log"
"net/http"
"regexp"
"github.com/goinaction/code/chapter2/sample/search"
)
type (
// item根据item字段的标签,将定义的字段与rss文档的字段关联起来
item struct {
XMLName xml.Name `xml:"item"`
PubDate string `xml:"pubDate"`
Title string `xml:"title"`
Description string `xml:"description"`
Link string `xml:"link"`
GUID string `xml:"guid"`
GeoRssPoint string `xml:"georss:point"`
}
// image根据image字段的标签,将定义的字段与rss文档的字段关联起来
image struct {
XMLName xml.Name `xml:"image"`
URL string `xml:"url"`
Title string `xml:"title"`
Link string `xml:"link"`
}
// channel根据channel字段的标签,将定义的字段与rss文档的字段关联起来
channel struct {
XMLName xml.Name `xml:"channel"`
Title string `xml:"title"`
Description string `xml:"description"`
Link string `xml:"link"`
PubDate string `xml:"pubDate"`
LastBuildDate string `xml:"lastBuildDate"`
TTL string `xml:"ttl"`
Language string `xml:"language"`
ManagingEditor string `xml:"managingEditor"`
WebMaster string `xml:"webMaster"`
Image image `xml:"image"`
Item []item `xml:"item"`
}
// rss文档定义了与rss文档关联的字段
rssDocument struct {
XMLName xml.Name `xml:"rss"`
Channel channel `xml:"channel"`
}
)
// rssMatcher实现了Matcher接口
type rssMatcher struct{}
// init将匹配器注册到程序里
func init() {
var matcher rssMatcher
search.Register("rss", matcher)
}
// 在文档中查找特定的搜索项
func (m rssMatcher) Search(feed *search.Feed, searchTerm string) ([]*search.Result, error) {
var results []*search.Result
log.Printf("Search Feed Type[%s] Site[%s] For URI[%s]\n", feed.Type, feed.Name, feed.URI)
// 获取要搜索的数据
document, err := m.retrieve(feed)
if err != nil {
return nil, err
}
for _, channelItem := range document.Channel.Item {
// 检查标题部分是否包含搜索项
matched, err := regexp.MatchString(searchTerm, channelItem.Title)
if err != nil {
return nil, err
}
// 匹配则将其作为结果保存
if matched {
results = append(results, &search.Result{
Field: "Title",
Content: channelItem.Title,
})
}
// 检查描述部分是否包含搜索项
matched, err = regexp.MatchString(searchTerm, channelItem.Description)
if err != nil {
return nil, err
}
// 匹配则将其作为结果保存
if matched {
results = append(results, &search.Result{
Field: "Description",
Content: channelItem.Description,
})
}
}
return results, nil
}
// retrieve发送HTTP Get请求获取rss数据源并解码
func (m rssMatcher) retrieve(feed *search.Feed) (*rssDocument, error) {
if feed.URI == "" {
return nil, errors.New("No rss feed uri provided")
}
// 从网络获得rss数据源文档
resp, err := http.Get(feed.URI)
if err != nil {
return nil, err
}
// 一旦从函数返回,关闭返回的响应链接
defer resp.Body.Close()
//正常状态码是200
if resp.StatusCode != 200 {
return nil, fmt.Errorf("HTTP Response Error %d\n", resp.StatusCode)
}
//将rss数据源文档解码到我们定义的数据结构里
var document rssDocument
err = xml.NewDecoder(resp.Body).Decode(&document)
return &document, err
}