python-sklearn实现一个简易的智能问答机器人
随着AI的发展,各大企业采用智能问答机器人取代了人工客服。智能问答系统实现的方法有很多,本篇文章介绍之前做的一个简易的智能问答机器人。采用的方法是使用朴素贝叶斯模型进行问题分类,模糊匹配查询近似问题。
- 实现步骤
1.1 总体流程设计
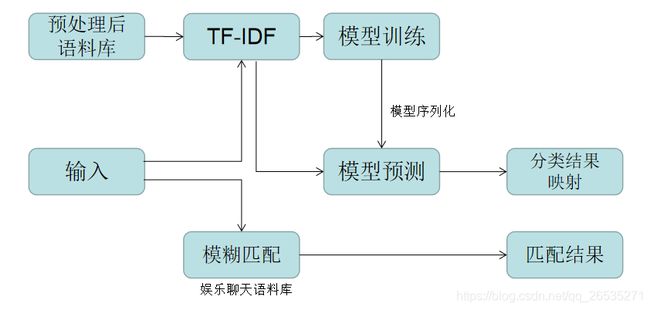
问答系统总体实现步骤如下流程图主要包括数据预处理,模型训练,结果映射以及答案匹配。数据预处理主要是对语料库进行收集,并对语料库进行筛选转换为需要的格式;然后使用朴素贝叶斯对处理好的语料库进行训练,语料库输入模型训练之前需要先对其进行预处理以及转换(去停用词,分词,TF-IDF计算),通过TF-IDF计算后则输入朴素贝叶斯中进行训练,由于我的语料库比较简易,所以采用默认参数训练即可达到较好的分类效果。在结果映射步骤中,主要是对事先确定好的类别进行映射处理(可用于脚本网页跳转使用)。答案匹配采用了模糊匹配的方法对用户提的问题进行匹配,搜索出相似的问题并给出其对应的答案。

1.2 语料库收集
语料库收集如下图。这里第一列为需要分类的类别,第二列为相关的问题。本篇中的语料库主要分为人社信息语料库以及娱乐聊天语料库。
人社信息语料库:

娱乐聊天语料库:

1.3 主要程序介绍
可视化界面GUI主要采用了tkinter工具包完成,rum_main.py程序如下:
#!/usr/bin/env python3
# _*_ coding:utf-8 _*_
from tkinter import *
import time
from speech_test import *
'''
定义消息发送函数:
1、在<消息列表分区>的文本控件中实时添加时间;
2、获取<发送消息分区>的文本内容,添加到列表分区的文本中;
3、将<发送消息分区>的文本内容清空。
'''
def msgsend():
msg = '我:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\n'
# print(msg)
txt_msglist.insert(END, msg, 'green') # 添加时间
query = txt_msgsend.get('0.0', END) #!!!!!!!!!!!!!!!11
print(query)
result = main(query) #问题输入模型入口
print('result:',result)
txt_msglist.insert(END, txt_msgsend.get('0.0', END)) # 获取发送消息,添加文本到消息列表
txt_msglist.insert(END, '\n')
txt_msgsend.delete('0.0', END) # 清空发送消息
robot = '小Y:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\n'
txt_msglist.insert(END, robot, 'red')
txt_msglist.insert(END, result+'\n')
'''定义取消发送 消息 函数'''
def cancel():
txt_msgsend.delete('0.0', END) # 取消发送消息,即清空发送消息
'''绑定up键'''
def msgsendEvent(event):
if event.keysym == 'Up':
msgsend()
tk = Tk()
tk.title('聊天窗口')
'''创建分区'''
f_msglist = Frame(height=300, width=300) # 创建<消息列表分区 >
f_msgsend = Frame(height=300, width=300) # 创建<发送消息分区 >
f_floor = Frame(height=100, width=300) # 创建<按钮分区>
f_right = Frame(height=700, width=100) # 创建<图片分区>
'''创建控件'''
txt_msglist = Text(f_msglist) # 消息列表分区中创建文本控件
txt_msglist.tag_config('green', foreground='blue') # 消息列表分区中创建标签
txt_msglist.tag_config('red', foreground='red') # 消息列表分区中创建标签
txt_msgsend = Text(f_msgsend) # 发送消息分区中创建文本控件
txt_show = Text(f_msglist) # 消息列表分区中创建文本控件
txt_show.tag_config('red', foreground='red') # 消息列表分区中创建标签
txt_showsend = Text(f_msgsend) # 发送消息分区中创建文本控件
txt_msgsend.bind('', msgsendEvent) # 发送消息分区中,绑定‘UP’键与消息发送。
'''txt_right = Text(f_right) #图片显示分区创建文本控件'''
button_send = Button(f_floor, text='Send',command=msgsend) # 按钮分区中创建按钮并绑定发送消息函数
button_cancel = Button(f_floor, text='Cancel', command=cancel) # 分区中创建取消按钮并绑定取消函数
'''分区布局'''
f_msglist.grid(row=0, column=0) # 消息列表分区
f_msgsend.grid(row=1, column=0) # 发送消息分区
f_floor.grid(row=2, column=0) # 按钮分区
f_right.grid(row=0, column=1, rowspan=3) # 图片显示分区
txt_msglist.grid() # 消息列表文本控件加载
txt_msgsend.grid() # 消息发送文本控件加载
button_send.grid(row=0, column=0, sticky=W) # 发送按钮控件加载
button_cancel.grid(row=0, column=1, sticky=W) # 取消按钮控件加载
tk.mainloop()
智能问答机器人相关程序为 speech_test.py,程序如下:
#-*- coding:utf-8 -*-
import logging
logging.getLogger("requests").setLevel(logging.WARNING)
import csv
import jieba
import pickle
from fuzzywuzzy import fuzz
import math
from scipy import sparse
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from scipy.sparse import lil_matrix
import jieba.posseg as pseg
import sys
import pandas as pd
from sklearn.naive_bayes import MultinomialNB
from speech_recognition import *
import warnings
warnings.filterwarnings("ignore")
def load_label_url():
with open('znwd_label_url.csv','r',encoding='utf-8') as f:
name_id = {}
label_url = csv.reader(f)
header = next(label_url)
for power_name_id in label_url:
name_id[power_name_id[0]] = power_name_id[1]
return name_id
def load_cut_save(filename,load = False):
jieba.load_userdict('UserDefined_words.txt')
corpus = []
label = []
with open(filename,'rt',encoding='utf-8') as f:
data_corpus = csv.reader(f)
header = next(data_corpus)
for words in data_corpus:
word = jieba.cut(words[1])
doc = []
for x in word:
if x not in stop_words and not x.isdigit():
doc.append(x)
corpus.append(' '.join(doc))
label.append(words[0])
if load == True:
with open('corpus.oj','wb') as f:
pickle.dump(corpus,f)
with open('label.oj','wb') as f:
pickle.dump(label,f)
return corpus,label
def train_model():
with open('corpus.oj','rb') as f_corpus:
corpus = pickle.load(f_corpus)
with open('label.oj','rb') as f_label:
label = pickle.load(f_label,encoding='bytes')
vectorizer = CountVectorizer(min_df=1)
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
words_frequency = vectorizer.fit_transform(corpus)
word = vectorizer.get_feature_names()
saved = input_tfidf(vectorizer.vocabulary_,sparse.csc_matrix(words_frequency),len(corpus))
model = MultinomialNB()
model.fit(tfidf,label)
with open('model.oj','wb') as f_model:
pickle.dump(model,f_model)
with open('idf.oj','wb') as f_idf:
pickle.dump(saved,f_idf)
return model,tfidf,label
class input_tfidf(object):
def __init__(self,feature_index,frequency,docs):
self.feature_index = feature_index
self.frequency = frequency
self.docs = docs
self.len = len(feature_index)
def key_count(self,input_words):
keys = jieba.cut(input_words)
count = {}
for key in keys:
num = count.get(key, 0)
count[key] = num + 1
return count
def getTdidf(self,input_words):
count = self.key_count(input_words)
result = lil_matrix((1, self.len))
frequency = sparse.csc_matrix(self.frequency)
for x in count:
word = self.feature_index.get(x)
if word != None and word>=0:
word_frequency = frequency.getcol(word)
feature_docs = word_frequency.sum()
tfidf = count.get(x) * (math.log((self.docs+1) / (feature_docs+1))+1)
result[0, word] = tfidf
return result
def model_predict(input_str):
f = open('idf.oj','rb')
idf = pickle.load(f)
f.close()
f = open('model.oj','rb')
model = pickle.load(f)
f.close()
tfidf = idf.getTdidf(input_str)
classifiction = (model.predict(tfidf))
# print(model.predict_proba(tfidf))
prob = model.predict_proba(tfidf).max()
name_id = load_label_url()
if prob >= 0.5:
answer1 = str(classifiction[0],'utf-8')
else:
answer1 = None
return answer1
def similarity(input_questions):
with open('corpus_1233.oj', 'rb') as f:
corpus = pickle.load(f,encoding='bytes')
with open('question_1233.oj', 'rb') as f:
question = pickle.load(f,encoding='bytes')
with open('answer_1233.oj', 'rb') as f:
answer = pickle.load(f,encoding='bytes')
text = {}
train = []
answer2 = []
for key, value in enumerate(corpus):
similarity = fuzz.ratio(input_questions, value)
if similarity > 40:
text[key] = similarity
if len(text) >= 3:
train = sorted(text.items(), key=lambda d: d[1], reverse=True)
# print(u"与您提的疑问相似的问题有\n")
for i in range(3):
an = {"question":question[train[i][0]],"answer":answer[train[i][0]]}
answer2.append(an)
# print("%d、" % (i + 1), \
# " 问题:%s\n" % str(question[train[i][0]],'utf-8'), \
# " 答案:%s" % str(answer[train[i][0]],'utf-8'))
elif len(text) == 2:
train = sorted(text.items(), key=lambda d: d[1], reverse=True)
# print("与您提的疑问相似的问题有\n")
for i in range(2):
an = {"question":question[train[i][0]],"answer":answer[train[i][0]]}
answer2.append(an)
# print("%d、" % (i + 1), \
# " 问题:%s\n" % str(question[train[i][0]],'utf-8'), \
# " 答案:%s" % str(answer[train[i][0]],'utf-8'))
elif len(text) == 1:
an = {"question": question[list(text.keys())[0]], "answer": answer[list(text.keys())[0]]}
answer2.append(an)
# print("与您提的疑问相似的问题有:\n", \
# " 问题:%s" % str(question[text.keys()[0]],'utf-8'), \
# " 答案:%s" % str(answer[text.keys()[0]],'utf-8'))
else:
# print("您所提的疑问无其他相似问题!")
an = {"question":None,"answer":None}
answer2.append(an)
return answer2
def get_greeting(input_questions,question,answer):
text = {}
for key, value in enumerate(question):
similarity = fuzz.ratio(input_questions, value)
if similarity > 60:
text[key] = similarity
if len(text) > 0:
train = sorted(text.items(), key=lambda d: d[1], reverse=True)
answer3 = answer[train[0][0]]
else:
answer3 = None
return answer3
def sim(doc):
input_questions = ''
input_words = jieba.cut(doc)
for x in input_words:
if x not in stop_words:
input_questions += x
answer2 = similarity(input_questions)
return answer2
def ans_show(returnSet):
if returnSet[2] is not None:
ans = "%s"%returnSet[2]
elif returnSet[0] is not None:
ans = "您的问题属于<%s>专栏\n"%returnSet[0]
ans1 = ""
if returnSet[1][0]['question'] is not None:
ans1 = "小Y还知道其他一些问题例如:\n"
ans2 = ""
for i in range(len(returnSet[1])):
ans2 = ans2 + "%d、" % (i + 1) + " 问题:%s\n" % str(returnSet[1][i]['question'],'utf-8') + " 答案:%s" % str(returnSet[1][i]['answer'],'utf-8')
ans1 = ans1 + ans2
ans = ans + ans1
elif returnSet[1][0]['question'] is not None:
ans1 = "小Y知道相似的问题:\n"
ans2 = ""
for i in range(len(returnSet[1])):
ans2 = ans2 + "%d、" % (i + 1) + " 问题:%s\n" % str(returnSet[1][i]['question'], 'utf-8') + " 答案:%s" % str(returnSet[1][i]['answer'], 'utf-8')
ans = ans1 + ans2
else:
ans = "您问的问题太过深奥,Mike才疏学浅暂时无法为您解答,待我读书破万卷后成为您的百科机器人"
return ans
with open('stop_words.txt', 'rb') as f:
stop_words = f.read().splitlines()
question_greeting = []
answer_greeting = []
with open("greeting.csv", 'r',encoding='utf-8') as f:
greeting = csv.reader(f)
header = next(greeting)
for words in greeting:
question_greeting.append(words[0])
answer_greeting.append(words[1])
filename = 'znwd_corpus.csv'
corpus, label = load_cut_save(filename,load=False)
def main(question):
if question != None:
query = question #########此处会因语音无法识别还报错
print("我 > %s" %query)
##############
answer3 = get_greeting(query,question_greeting,answer_greeting)
# print(answer3)
if answer3 is None:
answer1 = model_predict(query)
answer2 = sim(query)
else:
answer1 = None
answer2 = None
ans = [answer1,answer2,answer3]
result = ans_show(ans)
else:
result = "输入有误请重新输入!"
query = None
return result
因而,一个简单的智能问答机器人即可实现,若需要问答机器人能够回答更多的内容,可针对语料库进行修改,进而丰富智能问答机器人的聊天范围。程序中读取语料库采用了pickle工具包将预处理后的语料库进行序列化至本地,进而在下次使用语料库不需要再次进行预处理,可节省处理的时间。修改语料库后需重新覆盖序列化至本地的语料库文件和模型文件。
- 效果展示
最终效果如下,我的语料库主要用了社保卡相关的数据,该问答系统可以当作是一个社保信息方面的问答。


工程源码:https://github.com/liangjunAI/chatting_robot