selenium自动化搜集信息中的xpath使用相关问题
目录
-
-
- 1.基础使用
- 2.关于xpath
-
- (1)从网页中复制一个xpath
- (2)为什么xpath长这个样子
- 3.根据需求定制xpath
-
- (1)多种xpath方式可以对应同一个HTML标签
- (2)根据标签的属性信息获取定制xpath值
- (3)获取所有符合某xpath条件的web element元素
- (4)相对路径+xpath值
- 4.隐式等待xpath对应的元素出现
- 5.`WEBELEMENT.click()`方法点击不到不可见(当前视图没有显示的)元素的解决办法
-
- 6.页面非一次性加载出所有内容
-
1.基础使用
网上很多方法使用find_element_by_xpath方法,但是根据我所用的比较新的selenium的webdriver这个方法已经不能用的,find_element_by_xpath需要改为用find_element(By.XPATH,'A XPATH Value')。
web_element = driver.find_element(By.XPATH,'A XPATH Value')
2.关于xpath
(1)从网页中复制一个xpath
本文所说使用的比较蠢的xpath值是像下面这样的xpath使用方式
直接在网页上按F12

点击左上角划线位置的图标

点击一个元素后,就会在右方显示其源码中的位置,在源码中的位置处点击右键
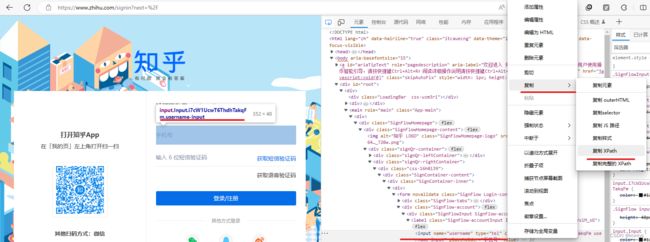
就可以得到一个xpath,但这种xpath“不好”,因为如果源码发生一些改变,很可能使这个xpath发生变化
(2)为什么xpath长这个样子
先对刚刚说的这个xpath做一下简单的分析
//*[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input
username = self.driver.find_element(By.XPATH,'//*[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input').text

上面这个xpath,结合上面的python3语句就可以解释为:在self.driver这个web element中,所有标签中(因为第一个//),找到第一个(是因为使用的是find_element方法,后面会展开说)标签中有id属性,且其value为“root”的任意(是因为*)标签,下的第一个div标签,下的第一个main标签下的,下的第一个div标签*4,下的第二个div标签…下的第一个label标签,下的第一个input标签,于是最终找到的就是这个input标签。

3.根据需求定制xpath
(1)多种xpath方式可以对应同一个HTML标签
差不多摸懂了xpath的原理,就可以根据自己的需要设计xapth上面的xpath还可以怎么去写:
①
//*[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input
改为:
//div[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input
这只是一个小改动
②再比如
该标签的完整xpath值:
/html/body/div[1]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input
其中的/html/body/div[1]与//div[@id="root"]是相同的可相互替代的。
(2)根据标签的属性信息获取定制xpath值
可以注意到:上述input标签有个属性为class,其value为"Input i7cW1UcwT6ThdhTakqFm username-input" ,在控制台中ctrl+F查找下Input i7cW1UcwT6ThdhTakqFm username-input,发现只有两个标签有class="Input i7cW1UcwT6ThdhTakqFm username-input",的标签(或者说是两个满足该条件的input标签),我们想要获得输入手机号对应的xpath(用于下面的python代码),就可以这样设计:
phone_number = self.driver.find_element(By.XPATH,'XPATH')
//input[@class="Input i7cW1UcwT6ThdhTakqFm username-input"]
或者
//*[@class="Input i7cW1UcwT6ThdhTakqFm username-input"]
含义即为:在self.driver中找到第一个class="Input i7cW1UcwT6ThdhTakqFm username-input"(限定条件,不要忽略@)input标签(本例中可以是*(任意标签))
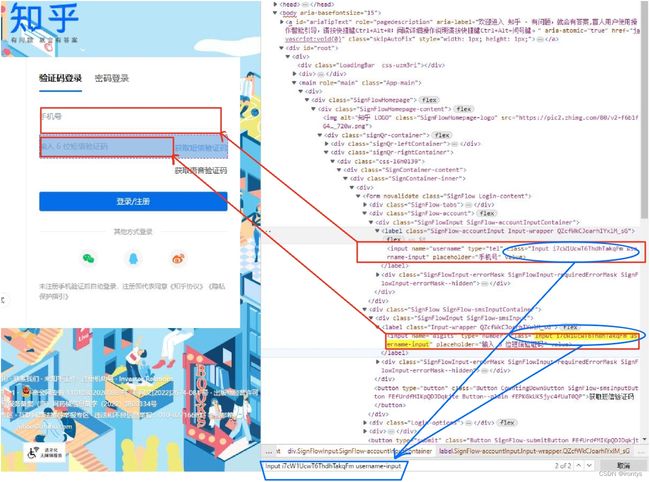
上面说到,控制台复制的xpath普遍不是很好(个人认为),因为如果源码发生一些改变,有可能使这个xpath发生变化,而某一个标签的属性通常不会发生改变,这样就提高了代码面对网页源码更改的情况下的容错性。
(3)获取所有符合某xpath条件的web element元素
使用上述根据标签属性定制的xpath值,就可以一次性获取符合某xpath条件的web element所有元素,这在批量处理类似数据时很有用,上述例子中的输入完手机号又要输入验证码,如果依然使用find_element方法+完全xpath的方式,可能需要这样设计python语句:
phone_number = self.driver.find_element(By.XPATH,'//*[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input')
code = self.driver.find_element(By.XPATH,'//*[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[3]/div/label/input')
每次都需要在网页上复制xpath值,
而使用上述根据标签属性定制的xpath值的方法,可以设计如下python代码
input_list = self.driver.find_elements(By.XPATH,'//input[@class="Input i7cW1UcwT6ThdhTakqFm username-input"]')
phone_number = input_list[0]
code = input_list[1]
使用了find_elements方法(区别于find_element,find_element即为find_elements[0]),其返回值是一个Web Element的列表,上述代码的含义为:input_list是一个包含self.driver这个web element下所有class="Input i7cW1UcwT6ThdhTakqFm username-input"的web element的列表
(4)相对路径+xpath值
有时会出现这样的需求:

需要获取该用户所有回答信息中的赞同数、标题信息、内容信息等,当然可以编写比如下面的代码:
agree_list = self.driver.find_elements(By.XPATH,'//Button[@class="Button VoteButton VoteButton--up FEfUrdfMIKpQDJDqkjte"]/span')
titles = ....
content = ...
......
for index,agree_info in enumerate(agree) :
agree = agree_list[i]
title = titles[i]
....
但是如果有时候不止回答信息里存在class="Button VoteButton VoteButton--up FEfUrdfMIKpQDJDqkjte"](赞同按钮),举个不恰当的例子:
如果下图划线位置中的按钮也是class="Button VoteButton VoteButton--up FEfUrdfMIKpQDJDqkjte"]怎么解决呢?(实际上不是的,只是举例)

下面提供一种的思路:
这种方法在某一个class
list_items = self.driver.find_elements(By.XPATH,'//div[@class="List-item"]')
for list_item in list_items :
agree = list_item.find_element(By.XPATH,'.//Button[@class="Button VoteButton VoteButton--up FEfUrdfMIKpQDJDqkjte"]/span')
...
......
注意:下面这个代码中xpath开头位置的//被替换成了../,self.driver被替换成了另一个web element(list_item)
这样就只获得了list item中的这个class的按钮。
\
4.隐式等待xpath对应的元素出现
为了防止因为网速问题,页面还没有完全加载出来,python文件就已经执行了find_element等方法,而导致程序报错异常退出,可以使用如下语句等待xpath对应的元素出现:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait(self.driver,10000).until(EC.presence_of_element_located((By.XPATH, 'XPATH')))
其中的1000是设置的最长等待时间,如果超时xpath对应的元素还是没有出现,程序依然会报错,而相比于用sleep的方法,这个方法的优点,是在页面出现了xpath对应的元素后,就会很快继续执行程序,而不会出现xpath出现后,程序还在等待不执行的问题。
5.WEBELEMENT.click()方法点击不到不可见(当前视图没有显示的)元素的解决办法
可以使用下述语句
self.driver.execute_script("arguments[0].click();", web_element_clickable)
其中web_element_clickable是一个可被d点击的web_element。
6.页面非一次性加载出所有内容
又是页面并非一次性加载出所有内容,这是需要向下滑动页面,才能加载出更多内容,可以使用如下python语句
下面的例子是如果当前页面中,xpath值为//div[@class="List-item"]的web element不足10个,就向下滚动页面,直至满足条件。
ask_answers = self.driver.find_elements(By.XPATH,'//div[@class="List-item"]')
ask_answers_count = len(ask_answers)
# Scroll down until the count is at least 10
while ask_answers_count < valid_answers_count:
# Scroll by 100 pixels
self.driver.execute_script("window.scrollBy(0, 100);")
# Get the updated ask_answers_count of div elements with class "List-item"
ask_answers = self.driver.find_elements(By.XPATH,'//div[@class="List-item"]')
ask_answers_count = len(ask_answers)