[亚麻高频题] Leetcode 139. Word Break
题目描述&链接
Leetcode 139 :判断字典中的字符能否合并成目标字符串 - 这道题只用判断可行性。进阶版Word Break II 是需要返回所有可能情况。
Note: 这题确实出的好,让你同时需要考虑算法和优化处理,这道题AC之路着实坎坷,屡屡尝试都TLE了,最后学会了优化解结果去Lintcode上写又TLE,最后终于弄明白最优解。。。
相似题目
Leetcode 140:Word Break II
Leetcode 472: Concatenated Words
题目思路
1. 常规暴力DFS
对于字符串组合类问题,就是构建隐式图的过程,然后对隐式图进行遍历求解即可。整体思路就是一道0/1组合类问题,我们遍历目标字符找到第一次匹配的位置,有两种选择:选这个单词,然后以下一个位置开始接着向下遍历下一个匹配单词;不选这个单词,再继续往下找更长可能匹配的单词,直到目标单词遍历完成。
Note: 通常这种查找字符串问题,会想到Trie求解,我个人觉得这道题没有必要,不如直接使用HashSet查找。如果单纯只是查找某个单词(非前缀)是否存在,直接HashMap即可,面试时间有限,何必大费周章写一个Trie去实现相同功能并且速度也不会变快。
- Trie的优点是在于前缀查询 or 通过前缀查找单词,我们只需要插入一次单词就能直接进行前缀或者前缀计数的问询操作 - Time:
;但是如果使用HashMap你需要遍历
(需要遍历所有前缀时
- 并且HashMap保存前缀需要给每一个前缀建立一个Key-Value Pair。但是Trie不用,这样大大节省了空间。
思路1的代码如下:
public boolean wordBreak(String s, List wordDict) {
HashSet set = new HashSet<>();
for(String i: wordDict) {
set.add(i);
}
return dfs(0, s, set);
}
private boolean dfs(int start, String s, HashSet set) {
if(start==s.length()) return true;
// 从 start index开始遍历找[start, end]匹配的单词
for(int end=start+1; end<=s.length(); end++) {
// 如果[start, end]不存在接着找
// 如果[start, end]存在,找下一个匹配单词从[end, ]开始
if(set.contains(s.substring(start, end)) && dfs(end, s, set)) return true;
// 如果没找到从上面跳出来,那么就以start开头接着往后找更长的匹配单词
}
// 如果都没找到说明以start开始后面没有匹配的答案
return false;
} 暴力DFS搜索时间复杂度:![]() , 因为0/1组合问题,最坏情况是每一次遍历都存在选与不选,遍历N次那么最后DFS搜索空间大概有
, 因为0/1组合问题,最坏情况是每一次遍历都存在选与不选,遍历N次那么最后DFS搜索空间大概有 个节点,也就是他的时间复杂度 ;空间复杂度:
个节点,也就是他的时间复杂度 ;空间复杂度: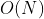 ,DFS递归时系统stack所占的空间是DFS搜索空间的深度也就是
,DFS递归时系统stack所占的空间是DFS搜索空间的深度也就是![]() 。
。
这时你一看题目 ![]() ,这时间复杂度绝壁超时了!!!不出意外TLE出现了:
,这时间复杂度绝壁超时了!!!不出意外TLE出现了:
![[亚麻高频题] Leetcode 139. Word Break_第1张图片](http://img.e-com-net.com/image/info8/dc88b7347e82472f92c6ecff169dda17.jpg)
2. 基于暴力DFS上加入记忆化剪枝
看来需要对DFS进行剪枝优化,举个例子,下面的例子中我们可以看出在隐式图遍历中你会出现很多重复子问题。下面例子中我们发现在"le" , "leet" 向下遍历时我们都会处理 "code"存在与否这个子问题,对于这种存在重复子问题,我们可以用记忆化进行优化剪枝,能够记忆化搜索的问题,动态规划也可以做,也就引出我们的后面的第三种思路。
"leetcode", words = ["leet", "le", "et", "code"]
==============隐式图======================
->找到 “le” 往下找 -> 找到 “et” 往下找 -> 找到“code”
->找到“leet” 往下找 -> 找到“code” (重复子问题)
思路2代码如下: 加入memo
public boolean wordBreak(String s, List wordDict) {
HashSet set = new HashSet<>();
for(String i: wordDict) {
set.add(i);
}
Boolean[] memo = new Boolean[s.length()+1];
return dfs(0, s, set, memo);
}
private boolean dfs(int start, String s, HashSet set, Boolean[] memo) {
if(start==s.length()) return true;
if(memo[start]!=null) return memo[start];
// 从 start index开始遍历找[start, end]匹配的单词
for(int end=start+1; end<=s.length(); end++) {
// 如果[start, end]不存在接着找
// 如果[start, end]存在,找下一个匹配单词从[end, ]开始
if(set.contains(s.substring(start, end)) && dfs(end, s, set, memo)) return memo[start]=true;
// 如果没找到从上面跳出来,那么就以start开头接着往后找更长的匹配单词
}
// 如果都没找到说明以start开始后面没有匹配的答案
return memo[start]=false;
} 时间复杂度: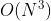 ,这个时间复杂度需要看加入memo最后的搜索空间缩减到多少,记忆化搜索等价于递归版动态规划,DP时间复杂度,所以记忆化搜索时间复杂度相同的;空间复杂度:,递归深度还是N。
,这个时间复杂度需要看加入memo最后的搜索空间缩减到多少,记忆化搜索等价于递归版动态规划,DP时间复杂度,所以记忆化搜索时间复杂度相同的;空间复杂度:,递归深度还是N。
3. 迭代版记忆化搜索 - 动态规划
DP思路和记忆化搜索相似,我们首先定义状态,这道题我们可以将状态定义为![]() :前面i-1个元素在字典中存在与否,这样状态转移方程可以表示为:
:前面i-1个元素在字典中存在与否,这样状态转移方程可以表示为:
整体实现代码如下:
public boolean wordBreak(String s, Set wordSet) {
// 状态 : dp[i] 前i-1个字符属于wordDict与否
boolean[] dp = new boolean[s.length()+1];
// 初始化
dp[0] = true;
// 状态转移
for(int end=1; end<=s.length(); end++) {
for(int start=end-1; start>=0; start--) {
// 从end-1到0遍历查看
boolean tmp = dp[start] && wordSet.contains(s.substring(start, end));
if(tmp) {
dp[end] = true;
break;
}
}
}
return dp[s.length()];
} 时间复杂度:,  时间遍历起始点和终点,进行substring组合操作;空间复杂度:。
时间遍历起始点和终点,进行substring组合操作;空间复杂度:。
4. 动态规划剪枝优化 - 更快
上面的代码中,我们可以观察到每一个遍历start都从头到尾,会有一些无意义的操作,如果[start, end]的区间长度大于字典中最大单词长度,剩下的遍历其实是无意义的,可以直接跳过。
public boolean wordBreak(String s, Set wordSet) {
// 状态 : dp[i] 前i-1个字符属于wordDict与否
boolean[] dp = new boolean[s.length()+1];
int maxL = 0;
for(String i: wordSet) {
maxL = Math.max(maxL, i.length());
}
// 初始化
dp[0] = true;
// 状态转移
for(int end=1; end<=s.length(); end++) {
for(int start=end-1; start>=0; start--) {
// 从end-1到0遍历查看
if(end-start>maxL) break;// 区间大于最长单词长度直接跳过当前遍历后面的查询
boolean tmp = dp[start] && wordSet.contains(s.substring(start, end));
if(tmp) {
dp[end] = true;
break;
}
}
}
return dp[s.length()];
} 时间复杂度:, 时间遍历起始点和终点,进行substring组合操作;空间复杂度:。