ICLR Spotlight | 卷积网络上的首个BERT/MAE预训练,ResNet也能用
“删除-再恢复” 形式的自监督预训练可追溯到 2016 年,早于 18 年的 BERT 与 21 年的 MAE。然而在长久的探索中,这种 BERT/MAE 式的预训练算法仍未在卷积模型上成功(即大幅超过有监督学习)。本篇 ICLR Spotlight 工作 “Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling” 则首次见证了 BERT/MAE 预训练在 CNN 上的成功,无论是经典 ResNet 还是新兴 ConvNeXt 均可从中受益,初步地预示了卷积网络上新一代自监督范式的未来。目前代码库和预训练模型均开源(链接见下)

论文链接:
https://arxiv.org/abs/2301.03580
开源代码和模型权重:
https://github.com/keyu-tian/SparK

一、时代背景:视觉领域的 BERT/MAE
视觉领域长期以来都在探索强大的预训练算法。
由于以 BERT/GPT 系列为代表的预训练算法研究在 NLP 领域大放异彩,视觉领域最近涌现了许多焦点工作如 BEiT,MAE,SimMIM,尝试将 BERT 这种风格的预训练从 NLP Transformer 迁移到 Vision Transformer,并在各下游任务上初步取得了成功。然而如何将 BERT 或 MAE 从 Transformers 迁移到卷积网络 CNN 上,仍然是一个未解的问题。CNN 目前只能“眼红” ViTs,无法享受到 BERT 式预训练的巨大效益。
二、问题分析:
为何 BERT/MAE 难以在 CNN 上成功
BERT 预训练算法的思想其实是通用的:将输入的一部分信息给随机删除(去掉一句话中的若干个单词,或涂黑图片中的部分像素),并希望神经网络能够还原这些被删除部分(还原单词或像素,类似做完形填空)
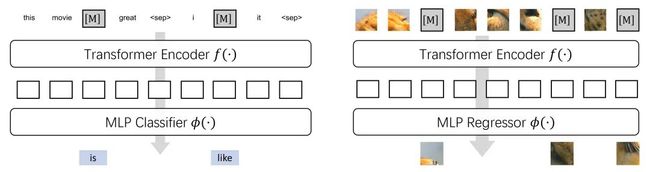
遗憾的是,让 BERT/MAE 在 CNN 上成功并非易事:2016-17年的一些尝试 [1,2] 就早于 BERT,使用 inpainting 方式预训练卷积网络,但其性能相比有监督基线落后了超过 10 个点。22年的 ConvMAE [3] 则主要在 Conv+Transformer 的混合模型上验证了 BERT,并未在 ResNet 这样的纯 CNN 上验证。最后,SparK 作者们也实际尝试了直接将 MAE [4] 的 ViT 粗暴替换为 CNN,然而结果得到了无效的预训练(性能基本与随机初始化齐平)。
问题出在哪?作者们提出将 BERT 直接运用在 CNN 上有两个问题:
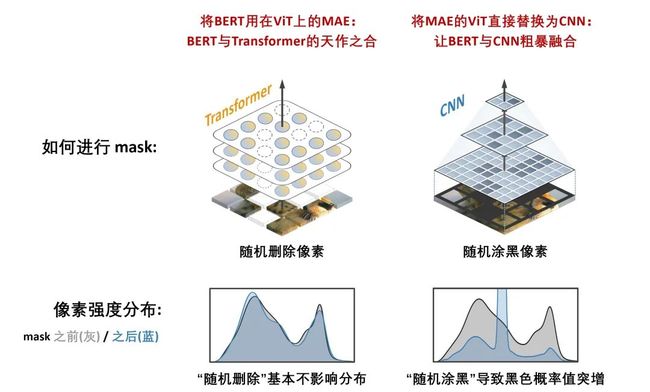
其一是 CNN 无法很好地适应被 mask 的输入。上图左侧展示的是 MAE [4],其使用的是 Transformer 模型,可以灵活处理被 mask 后、带有空洞的不规则输入,乃与 BERT “天作之合”。而如果直接将 MAE 的 ViT 替换为 CNN,我们只能通过涂黑这种操作实现 mask,而这会导致比较严重的分布偏移。当然,涂黑还有另一个问题(会导致被 mask 的区域的面积随着卷积越来越少,被“侵蚀”),可详见论文的第 3.1 节。
其二是 CNN 具备多尺度结构,而源于 NLP 领域的 BERT 预训练算法天生是单尺度的(由于语言已经具有良好结构的语义单元了)。“多尺度” 即 multi-scale 或 hierarchical,指的是 CNN 通过一系列下采样得到一系列分辨率从大到小的特征图,对检测、分割这样的下游任务很重要,不应忽视。
为解决这两个问题,作者们提出了 SparK:Sparse and hierarchical masKed modeling,接下来进行介绍。
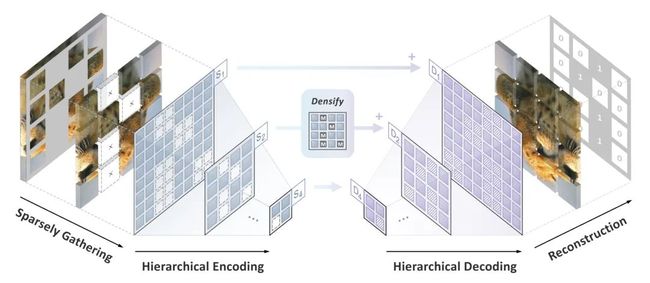
三、解决方案:SparK
针对前文两个问题,SparK 有两个针对性设计。其一,受三维点云数据处理的启发,作者们提出把经过掩码操作(挖空操作)后的“零碎”图片视为稀疏点云,并使用子流形稀疏卷积来进行编码,让卷积网络自如处理随机删除后的图像,从而避开“涂黑”操作带来的问题。
其二,受 UNet 优雅设计的启发,作者们自然地设计了一种带有横向连接的编码器-解码器模型,让多尺度特征在模型的多层级之间流动,让 BERT 算法拥抱计算机视觉的多尺度金标准。
SparK 预训练算法是通用的:其可被直接运用在任何卷积网络上,而无需对它们的结构进行任何修改,或引入任何额外的组件。不论是耳熟能详的经典 ResNet,还是近期的先进模型 ConvNeXt,均可直接从 SparK 中受益。
四、实验结果一览
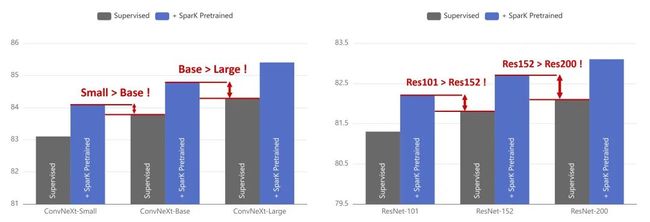
通用的 SparK 带来了跨模型尺寸级别的涨点。较小的 ResNet 或 ConvNeXt 模型,经过 SparK 预训练后,可以超过较大的基线模型:
超过 Swin-Transformer。在预训练前,ConvNeXt-B 和 Swin-B 效果接近;而在预训练后,SparK+ConvNeXt-B 超过了 SimMIM+Swin-B:

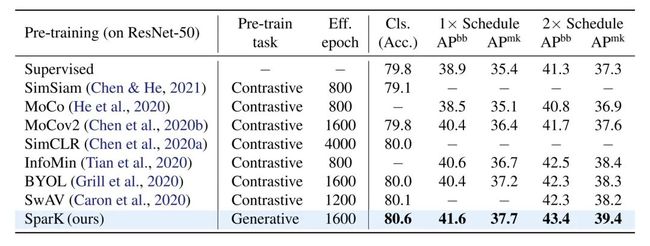
生成式SparK vs. 判别式对比学习。可以看到 SparK 这种生成式预训练在各个下游任务上有着强劲表现:
预训练可视化。可以看到对于小狗眼睛、彩袜纹理、被遮挡了大部分区域的红色水果,模型都还原的较好,体现了其对视觉语义的一定理解。

五、承上启下与未来展望
这里引用 SparK 被接受为 ICLR 2023 Spotlight 时的一句话总结:
首次验证了 BERT/MAE 这样的预训练算法可被用于任何主流的卷积网络 CNN 上,这是很有意义的
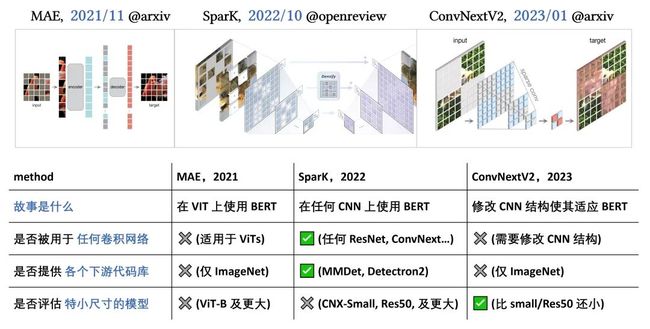
从时代轨迹看,SparK 承接了自 2021 年以来 BEiT/MAE/SimMIM/ConvMAE 等一系列优秀的工作,希望把 BERT/MAE 这样的预训练成功运用到 CNN 上。同时大家也看到在 23 年初的 ConvNeXt V2 [5] 也表达了与 SparK 相同的愿景:让 CNN 也可以享受到 BERT 预训练的好处。下图展示、对比了 MAE → SparK → ConvNeXt V2 这条脉络:
SparK 其实还是较为早期的最初探索,未来 CNN + BERT/MAE 是一个还很广阔的、待探索的研究话题。SparK 作者们希望他们的尝试与开源,可以激发出一些小启示,并助力使用卷积网络的各个真实场景、贡献社区。
参考资料
[1] Pathak, Deepak, et al. “Context encoders: Feature learning by inpainting.” CVPR 2016.
[2] Zhang, Richard, et al. “Split-brain autoencoders: Unsupervised learning by cross-channel prediction.” CVPR 2017
[3] Gao, Peng, et al. “Convmae: Masked convolution meets masked autoencoders.” arXiv 2022.
[4] He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” CVPR 2022.
[5] Woo, Sanghyun, et al. “ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders.” arXiv 2023.
Illustration by IconScout Store from IconScout
-TheEnd-