全文搜索技术 Lucene & solr & es (一)Lucene
学习视频地址:https://www.bilibili.com/video/av45567492?from=search&seid=14848044148453483902
本篇博客是基于此学习视频以及课程笔记进行学习
- 了解什么是全文检索技术?
- 想明白字典的出现是为了什么?
- 全文检索技术可以用来做什么?
- 搜索引擎:百度、谷歌、搜狗等
- 站内搜索:小说网站、电商网站、论坛等等
- 文件系统搜索:Windows文件系统搜索
- 有哪些主流的Java全文检索技术?
- Lucene:这是Java语言全局检索技术的底层实现(开山鼻祖)
- Solr:基于Lucene,简化开发,提示性能、扩展性。通过SolrCloud可以实现分布式搜索
- ElasticSearch(ES):基于Lucene,更倾向于实现实时搜索。
- 这些技术应该如何选择?
- 需要搞清楚每个技术的特点及缺点。
- 分别学习不同的全文检索技术 是什么?
- 为了沟通
- 安装和配置
- 使用(Java开发)
壹、全文搜索技术
一、什么是全文检索技术
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据:指不定长或无固定格式的数据,如 互联网数据、邮件,word文档等。
非结构化数据又一种叫法叫全文数据
按照数据的分类,搜索也分为两种:
- 对结构化数据的搜索: 如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件 名,类型,修改时间进行搜索等。
- 对非结构化数据的搜索: 如用Google和百度可以搜索大量内容数据。
对非结构化数据也即全文数据的搜索主要有两种方法:顺序扫描法和反向索引法。
- 顺序扫描法:所谓顺序扫描法,就是顺序扫描每个文档内容,看看是否有要搜索的关键字,实现查找文档的 功能,也就是根据文档找词。
- 反向索引法:所谓反向索引,就是提前将搜索的关键字建成索引,然后再根据索引查找文档,也就是根据词 找文档。
这种先建立 索引 ,再对索引进行 搜索文档的过程就叫 全文检索(Full-text Search) 。
二、全文检索场景
- 搜索引擎
- 站内搜索
- 系统文件搜索
三、全文检索的相关技术
- Lucene:如果使用该技术实现,需要对Lucene的API和底层原理非常了解,而且需要编写大量的Java代码。
- Solr:使用java实现的一个web应用,可以使用rest方式的http请求,进行远程API的调用。
- ElasticSearch(ES):可以使用rest方式的http请求,进行远程API的调用。
贰、Solr和ES的比较
一、ElasticSearch vs Solr 检索速度
1、当单纯对已有数据进行搜索时,Solr更快
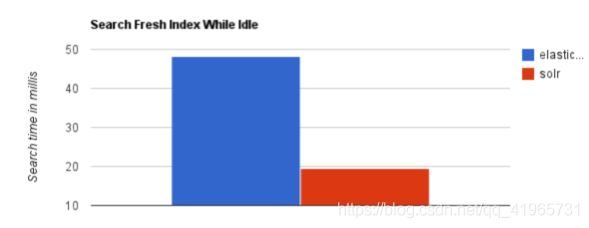
2、当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
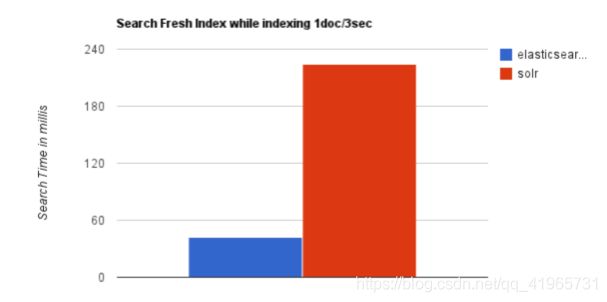
3、随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化。
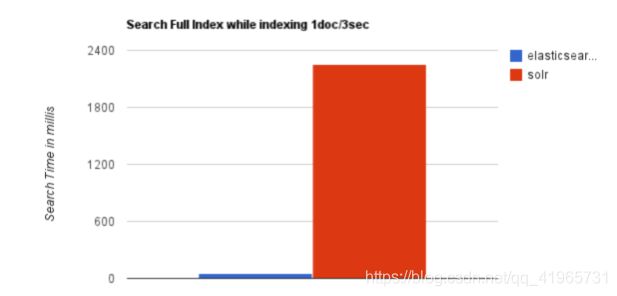
4、大型互联网公司(特大公司),实际生产环境测试,将搜索引擎从Solr转到Elasticsearch以后的平均查询速度有了50倍的 提升。
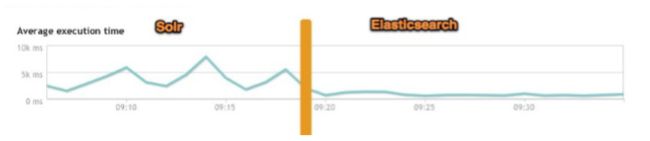
二、Elasticsearch 与 Solr 的比较总结
- 二者安装都很简单;
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
最终的结论:
Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
三、实时搜索与传统搜索
通常来说,传统搜索都是一些“静态”的搜索,即用户搜索的只是从信息库里边筛选出来的信息。而百度推出 的实时搜索功能,改变了传统意义上的静态搜索模式,用户对于搜索的结果是实时变化的。
举个例子,用户在搜索“华山”、“峨眉山”等景点时,实时观看各地景区画面。以华山景区为例,当用户在搜索 框中输入“华山”时,点击右侧“实时直播——华山”,即可实时观看华山靓丽风景,并能在华山长空栈道、北峰 顶、观日台三个视角之间切换。同时,该直播引入广受年轻人欢迎的“弹幕”模式,用户在观看风景时可以同 时发表评论,甚至进行聊天互动。
叁、全文检索流程的分析
一、流程的总览
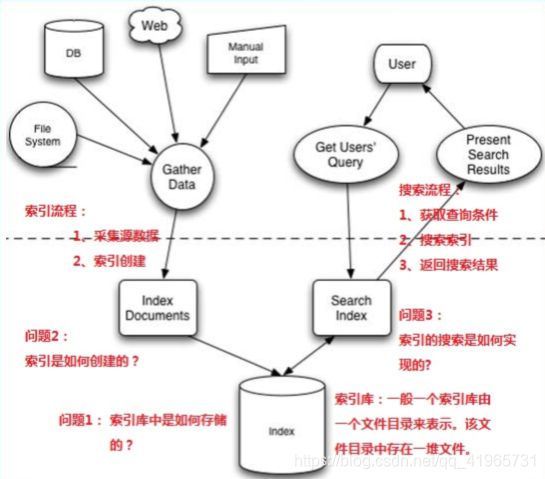
全文检索的流程分为两大流程:索引创建、搜索索引
- 索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
- 搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程
想搞清楚全文检索,必须要搞清楚下面三个问题:
- 索引库里面究竟存些什么?(Index)
- 如何创建索引?(Indexing)
- 如何对索引进行搜索?(Search)
二、索引表的创建流程
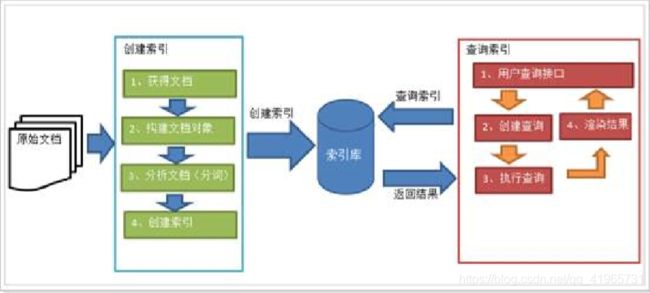
一次索引,多次使用
1、原始内容
原始内容是指要索引和搜索的内容。
原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
2、获得文档
也就是采集数据,从互联网上、数据库、文件系统中等获取需要搜索的原始信息,这个过程就是信息采集。
采集数据的目的是为了将原始内容存储到Document对象中。
如何采集数据?
- 对于互联网上网页,可以使用工具将网页抓取到本地生成html文件。
- 数据库中的数据,可以直接连接数据库读取表中的数据。
- 文件系统中的某个文件,可以通过I/O操作读取文件的内容。
3 、创建文档
创建文档的目的是统一数据格式(Document),方便文档分析
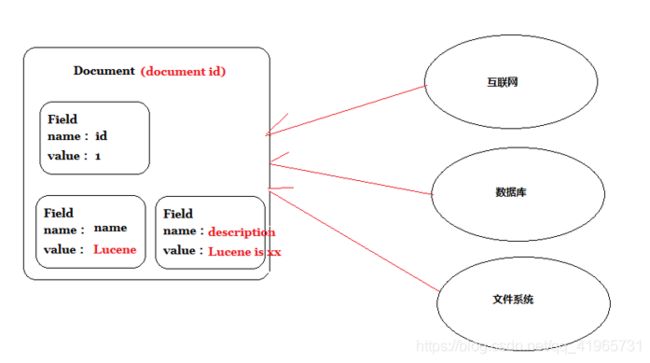
说明:
- 一个Document文档中包括多个域(Field),域(Field)中存储内容。
- 这里我们可以将数据库中一条记录当成一个Document,一列当成一个Field。
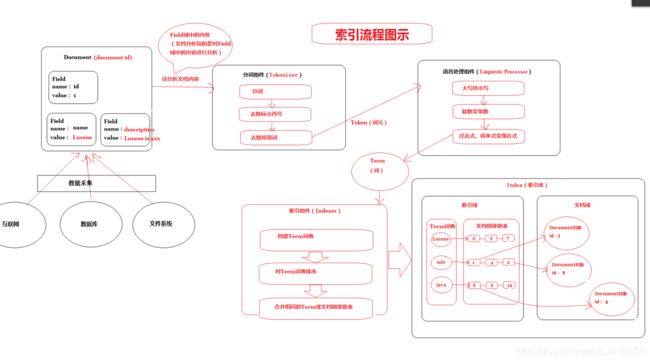
4 、分析文档(重点)
分析文档主要是对Field域进行分析,分析文档的目的是为了索引。
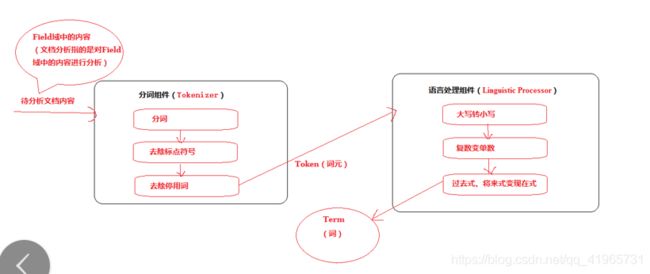
分析文档主要通过分词组件(Tokenizer)和语言处理组件(Linguistic Processor)完成。 分词组件
1)分词组件(Tokenizer)
分词组件工作流程(此过程称之为Tokenize)
- 将Field域中的内容进行分词(不同语言有不同的分词规则)。
- 去除标点符号。
- 去除停用词(stop word)
经过分词(Tokenize)之后得到的结果成为 词元(Token) 。
所谓停词(Stop word)就是一种语言中最普通的一些单词,由于没有特别的意义,因而大多数情况下不能成 为搜索的关键词,因而创建索引时,这种词会被去掉而减少索引的大小。
英语中停词(Stop word)如:“the”,“a”,“this”等。
对于每一种语言的分词组件(Tokenizer),都有一个停词(stop word)集合。
示例(Document1的Field域和Document2的Field域是同名的):
Document1的Field域:
Students should be allowed to go out with their friends, but not allowed to drink beer
Document2的Field域:
My friend Jerry went to school to see his students but found them drunk which is not allowed.
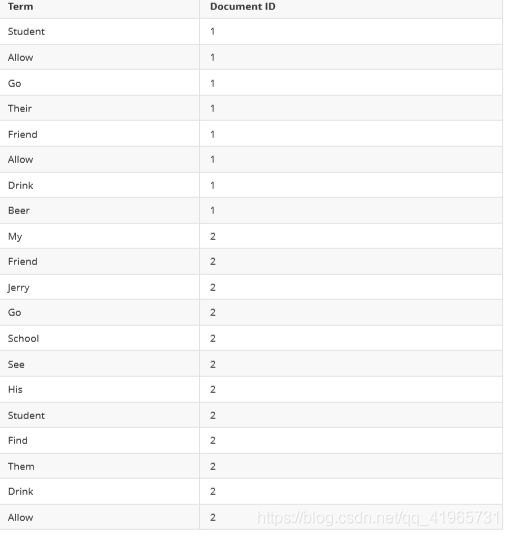
在我们的例子中,便得到以下词元(Token):
“Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“fri end”,“Jerry”,“went”,“school”,“see”,“his”,“students”,“found”,“them”,“drunk”,“al lowed”。
将得到的词元(Token)传给语言处理组件(Linguistic Processor)。
2)语言处理组件
语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些同语言相关的处理。
对于英语,语言处理组件(Linguistic Processor)一般做以下几点:
- 变为小写(Lowercase)。
- 将单词缩减为词根形式,如“cars”到“car”等。这种操作称为:stemming。
- 将单词转变为词根形式,如“drove”到“drive”等。这种操作称为:lemmatization。
语言处理组件(linguistic processor)的结果称为 词(Term) 。Term是索引库的最小单位。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“ jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
5、 索引文档
索引的目的是为了搜索。
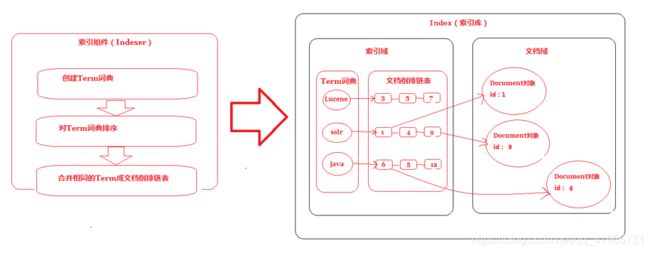
说明:将得到的词(Term)传给索引组件(Indexer),索引组件(Indexer)主要做以下几件事情:
1)创建Term字典
如上面例子的字典如下
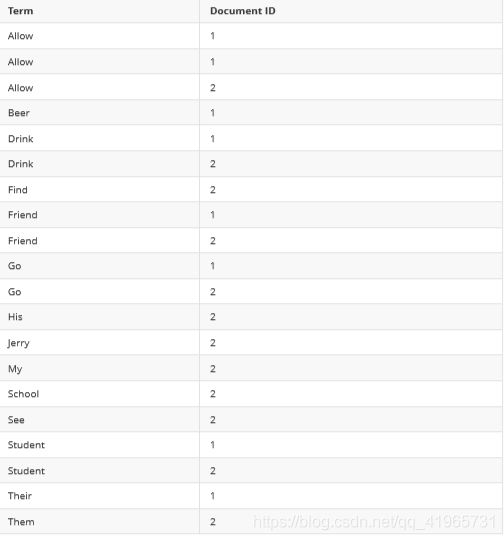
2)排序Term字典
对字典按字母顺序进行排序
3)合并Term字典
合并相同的词(Term)成为文档倒排(Posting List)链表
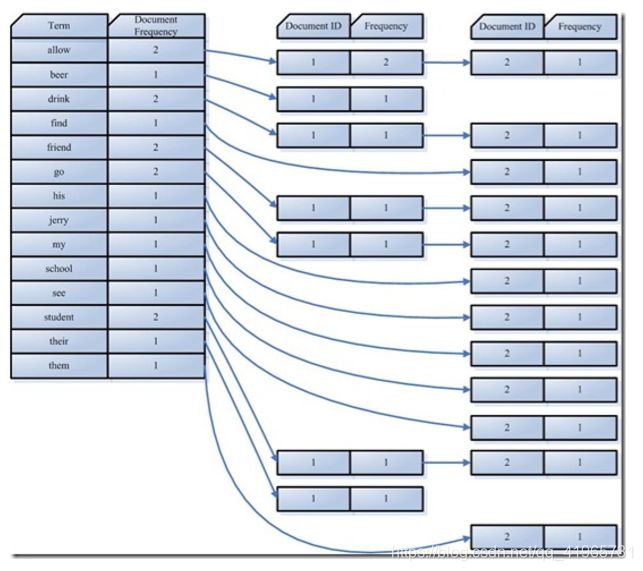
在此表中,有几个定义:
- Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)。
- Frequency 即词频率,表示此文件中包含了几个此词(Term)
到此为止,索引已经创建好了。
最终的索引结构是一种倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小, 而文档集合较大。
倒排索引结构是根据内容(词汇)找文档,如下图:
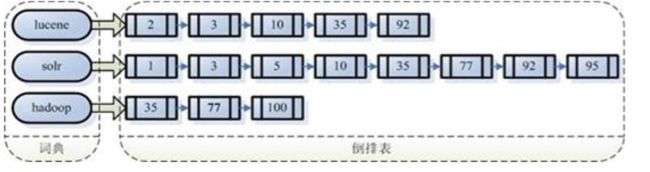
3、 搜索索引流程
1)图1:查询语句

2)图2:执行搜索
第一步:对查询语句进行词法分析、语法分析及语言处理。
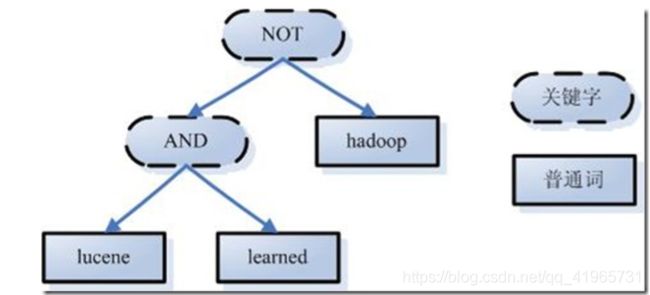
<1>、词法分析
如上述例子中,经过词法分析,得到单词有lucene,learned,hadoop, 关键字有AND, NOT。
注意:关键字必须大写,否则就作为普通单词处理。

<2>、语法分析
如果发现查询语句不满足语法规则,则会报错。如lucene NOT AND learned,则会出错。
如上述例子,lucene AND learned NOT hadoop形成的语法树如下:
<3>、语言处理
如learned变成learn等。
经过第二步,我们得到一棵经过语言处理的语法树。
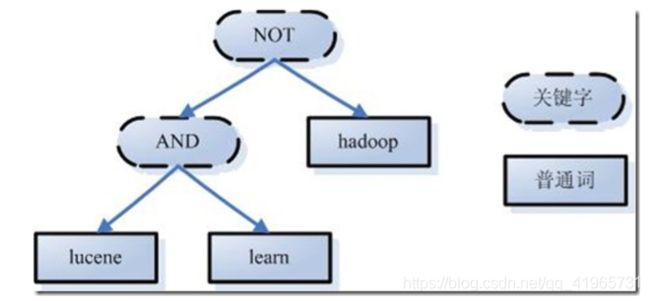
第二步:搜索索引,得到符号语法树的文档。
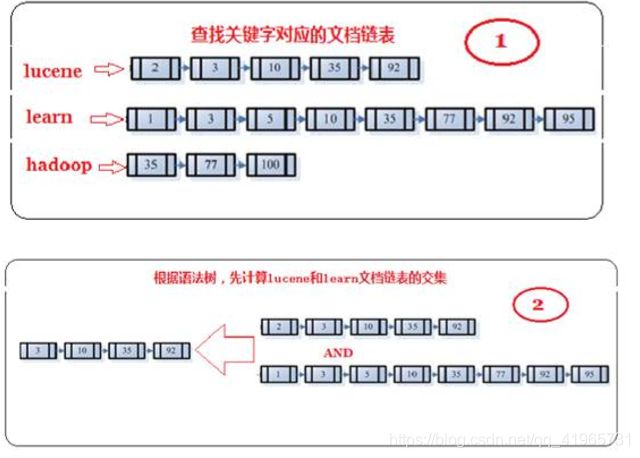
- 首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表。
- 其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
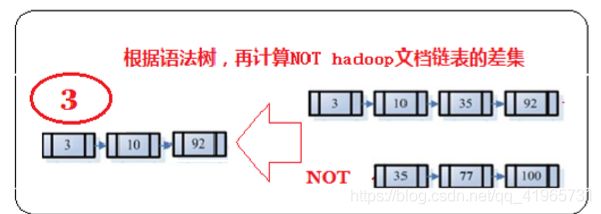
3、 然后,将此链表与hadoop的文档链表进行差操作,去除包含hadoop的文档,从而得到既包含lucene又包含 learn而且不包含hadoop的文档链表。
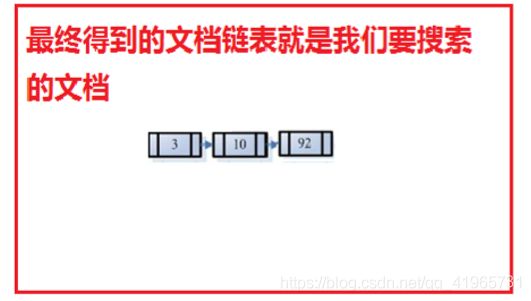
4、 此文档链表就是我们要找的文档。
第三步:根据得到的文档和查询语句的相关性,对结果进行排序。
相关度自然打分(权重越高分越高):
tf(Term Frequency)越高、权重越高
df (Document Frequency)越高、权重越低
人为影响分数:
设置Boost值(加权值)
3) Lucene相关度排序
<1> 什么是相关度排序
相关度排序是 查询结果 按照与 查询关键字 的相关性进行排序,越相关的越靠前。比如搜索“Lucene”关键字,与该 关键字最相关的文章应该排在前边。
<2> 相关度的打分
Lucene对查询关键字和索引文档的相关度进行打分,得分高的就排在前边。
如何打分呢?Lucene是在用户进行检索时实时根据搜索的关键字计算出来的,分两步:
- 计算出词(Term)的权重
- 根据词的权重值,计算文档相关度得分。
什么是词的权重?
通过索引部分的学习,明确索引的最小单位是一个Term(索引词典中的一个词)。搜索也是从索引域中查询Term, 再根据Term找到文档。Term对文档的重要性称为权重,影响Term权重有两个因素:
- Term Frequency (tf):
- 指此Term在此文档中出现了多少次。tf 越大说明越重要。 词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“Lucene”这个词,在文档中出现的次数很 多,说明该文档主要就是讲Lucene技术的。
- Document Frequency (df):
- 指有多少文档包含此Term。df 越大说明越不重要。
比如,在一篇英语文档中,this出现的次数更多,就说明越重要吗?不是的,有越多的文档包含此词(Term), 说明此 词(Term)太普通,不足以区分这些文档,因而重要性越低。
- 指有多少文档包含此Term。df 越大说明越不重要。
<3> 设置boost值影响相关度排序
boost是一个加权值(默认加权值为1.0f),它可以影响权重的计算。在索引时对某个文档中的field设置加权值, 设置越高,在搜索时匹配到这个文档就可能排在前边。
肆、Lucene的Field域
一、Field属性
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field的一个承载 体,Field值即为要索引的内容,也是要搜索的内容。
1)是否分词(tokenized)
是: 作分词处理,即将Field值进行分词,分词的目的是为了索引。
比如:商品名称、商品描述等,这些内容用户要输入关键字搜索,由于搜索的内容格式大、内容多需要分词后将语 汇单元建立索引
否: 不作分词处理
比如:商品id、订单号、身份证号等
2)是否索引(indexed)
是: 进行索引。将Field分词后的词或整个Field值进行索引,存储到索引域,索引的目的是为了搜索。
比如:商品名称、商品描述分析后进行索引,订单号、身份证号不用分词但也要索引,这些将来都要作为查询条 件。
否: 不索引。
比如:图片路径、文件路径等,不用作为查询条件的不用索引
3)是否存储(stored)
是: 将Field值存储在文档域中,存储在文档域中的Field才可以从Document中取。 比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
否: 不存储Field值
比如:商品描述,内容较大不用存储。如果要向用户展示商品描述可以从系统的关系数据库中获取
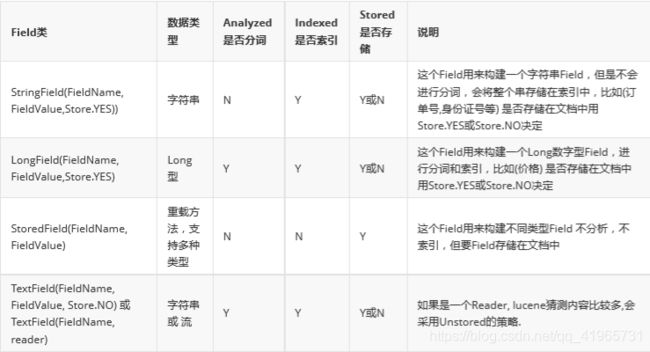
二. Field常用类型
三. Field修改
图书id:
是否分词:不用分词,因为不会根据商品id来搜索商品
是否索引:不索引,因为不需要根据图书ID进行搜索
是否存储:要存储,因为查询结果页面需要使用id这个值
图书名称:
是否分词:要分词,因为要根据图书名称的关键词搜索。
是否索引:要索引。
是否存储:要存储。
图书价格:
是否分词:要分词,lucene对数字型的值只要有搜索需求的都要分词和索引,因 为lucene对数字型的内容要特殊 分词处理,需要分词和索引。
是否索引:要索引
是否存储:要存储
图书图片地址:
是否分词:不分词
是否索引:不索引
是否存储:要存储
图书描述:
是否分词:要分词
是否索引:要索引
是否存储:因为图书描述内容量大,不在查询结果页面直接显示,不存储。
不存储是不在lucene的索引域中记录,节省lucene的索引文件空间。
如果要在详情页面显示描述,解决方案:
从lucene中取出图书的id,根据图书的id查询关系数据库(MySQL)中book表得到描述信息。
案例
最近做的,还没有完全实现功能,但是测试是暂时通过的(里面有EXCEL表的导入导出可以跳过)
实体类
/**
* @description: 基础数据的实体类
* @auther:田坤
* @date 2019/7/5 17:38
**/
@Data
public class CrmDataPojo {
private int data_Num;
private String data_Sort_;
private String data_Tiaomu;
private String data_Value;
private String data_State;
}
服务层接口
/**
* @description: 基础数据表的操作
* @auther:田坤
* @date 2019/7/5 18:12
**/
public interface CrmDataService {
/**
* 查询所有的基本数据类型
* @return
*/
List selAllData();
/**
* 增加基本数据类型
* @param crmDataPojo
* @return
*/
int addDataType(CrmDataPojo crmDataPojo);
/**
* 根据编号删除基本数据类型
* @param id
* @return
*/
int delDataType(int id);
/**
* 更新基本数据类型
* @param crmDataPojo
* @return
*/
int updDataType(CrmDataPojo crmDataPojo);
/**
* 将基础数据的信息以excel表的形式导出
* @param os
* @param list
*/
HSSFWorkbook exportExcel(OutputStream os, List list);
/**
* 导入Excel表中的数据添加到基础数据表中
* @param is 需要导入的Excel的文件输入流
*/
void importExcel(InputStream is);
/**
* 创建索引表
*/
void CreateIndex();
/**
* 在索引库中查询所以的数据字典
* @return
*/
List selAllDataByLucene(List tqs);
/**
* 向索引库中添加索引
* @param
* @return
*/
int addDataIndex(CrmDataPojo crmDataPojo);
/**
* 更改索引库中的索引信息
* @param
* @return
*/
int updatermDataIndex(CrmDataPojo crmDataPojo);
/**
* 删除索引库中的索引信息
* @param id product_Num
* @return
*/
int deletermDataIndex(int id);
}
服务层实现类
/**
* @description:
* @auther:田坤
* @date 2019/7/5 18:13
**/
@Service
public class CrmDataServiceImpl implements CrmDataService {
//工作表的名称
final String EXCEL_NAME = "基础数据表";
//工作表的列标题
final String[] EXCEL_HEAD_NAME ={"编号","类别","条目","值","是否可以编辑"};
@Resource
private CrmDataMapper crmDataMapper;
@Override
public List selAllData() {
return crmDataMapper.selAllData();
}
@Override
public int addDataType(CrmDataPojo crmDataPojo) {
addDataIndex(crmDataPojo);
return crmDataMapper.addDataType(crmDataPojo);
}
@Override
public int delDataType(int id) {
int i = deletermDataIndex(id);
return crmDataMapper.delDataType(id);
}
@Override
public int updDataType(CrmDataPojo crmDataPojo) {
updatermDataIndex(crmDataPojo);
return crmDataMapper.updDataType(crmDataPojo);
}
@Override
public HSSFWorkbook exportExcel(OutputStream os, List list) {
//创建一个工作簿
HSSFWorkbook wb = new HSSFWorkbook();
//创建一个工作表(表名为 EXCEL_NAME
HSSFSheet sheet = wb.createSheet(EXCEL_NAME);
//获取标题单元格样式
HSSFCellStyle hcs = ExcelCellStyle.getTitleStyle(wb);
//设置列宽
sheet.setColumnWidth(0,4000);
sheet.setColumnWidth(1,5000);
sheet.setColumnWidth(2,6000);
sheet.setColumnWidth(3,6000);
sheet.setColumnWidth(4,3000);
//创建一行,行的索引是从0开始的 ===》写标题
HSSFRow row = sheet.createRow(0);
HSSFCell cell = null;
for(int i = 0 ;i < EXCEL_HEAD_NAME.length; i++){
cell = row.createCell(i);
cell.setCellStyle(hcs);
cell.setCellValue(EXCEL_HEAD_NAME[i]);
}
//导出的内容
int rowCount = 1;
//获取内容单元格样式
HSSFCellStyle hcsc = ExcelCellStyle.getContentStyle(wb);
for (CrmDataPojo data:
list) {
row = sheet.createRow(rowCount);
HSSFCell cell1 = row.createCell(0);
cell1.setCellStyle(hcsc);
HSSFCell cell2 = row.createCell(1);
cell2.setCellStyle(hcsc);
HSSFCell cell3 = row.createCell(2);
cell3.setCellStyle(hcsc);
HSSFCell cell4 = row.createCell(3);
cell4.setCellStyle(hcsc);
HSSFCell cell5 = row.createCell(4);
cell5.setCellStyle(hcsc);
cell1.setCellValue(data.getData_Num());
cell2.setCellValue(data.getData_Sort_());
cell3.setCellValue(data.getData_Tiaomu());
cell4.setCellValue(data.getData_Value());
cell5.setCellValue(data.getData_State());
rowCount++;
}
return wb;
}
@Override
public void importExcel(InputStream is) {
//创建一个Excel工作簿对象
HSSFWorkbook wb = null;
try {
wb = new HSSFWorkbook(is);
//获取工作表
HSSFSheet sheet = wb.getSheetAt(0);
//获取有效的行数
int numberOfRows = sheet.getPhysicalNumberOfRows();
CrmDataPojo crmDataPojo = null ;
CrmDataPojo temp = null;
for (int i = 1 ; i < numberOfRows; i++){
crmDataPojo = new CrmDataPojo();
int data_Num = (int)sheet.getRow(i).getCell(0).getNumericCellValue();
String data_Sort = sheet.getRow(i).getCell(1).getStringCellValue();
String data_Tiaomu = sheet.getRow(i).getCell(2).getStringCellValue();
String data_Value = sheet.getRow(i).getCell(3).getStringCellValue();
String data_State = sheet.getRow(i).getCell(4).getStringCellValue();
crmDataPojo.setData_Num(data_Num);
crmDataPojo.setData_Sort_(data_Sort);
crmDataPojo.setData_Tiaomu(data_Tiaomu);
crmDataPojo.setData_Value(data_Value);
crmDataPojo.setData_State(data_State);
//如果里面存在id数据就进行修改 不存在就进行增加
if(crmDataMapper.selDataById(crmDataPojo.getData_Num())!=null){
crmDataMapper.updDataType(crmDataPojo);
}else{
crmDataMapper.addDataType(crmDataPojo);
}
}
} catch (IOException e) {
e.printStackTrace();
}catch (Exception e){
e.printStackTrace();
}
}
@Override
public void CreateIndex() {
try {
//指定索引库存放的路径
//D:\WorkSpace\IdeaWorkspaces\index\CrmProduct
Directory directory = FSDirectory.open(new File("D:\\WorkSpace\\IdeaWorkspaces\\index\\CrmData").toPath());
//索引库还可以存放到内存中
//Directory directory = new RAMDirectory();
//创建indexwriterCofig对象
IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer());
//创建indexwriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
List CrmDataPojos = selAllData();
for (CrmDataPojo cdp:CrmDataPojos
) {
//创建数据名域
//第一个参数:域的名称
//第二个参数:域的内容
//第三个参数:是否存储
StringField data_numField = new StringField("data_Num", cdp.getData_Num()+"", Field.Store.YES);
StringField data_sortField = new StringField("data_Sort", cdp.getData_Sort_(), Field.Store.YES);
StringField data_tiaomuField = new StringField("data_Tiaomu", cdp.getData_Tiaomu(), Field.Store.YES);
StringField data_valueField = new StringField("data_Value", cdp.getData_Value()+"", Field.Store.YES);
StringField data_stateField = new StringField("data_State", cdp.getData_State()+"", Field.Store.YES);
//创建document对象
Document document = new Document();
document.add(data_numField);
document.add(data_sortField);
document.add(data_tiaomuField);
document.add(data_valueField);
document.add(data_stateField);
//创建索引,并写入索引库
indexWriter.addDocument(document);
}
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}catch (Exception e){
e.printStackTrace();
}
}
@Override
public List selAllDataByLucene(List tqs) {
Directory directory = null;
IndexReader indexReader = null;
IndexSearcher indexSearcher = null;
List listc = null;
try {
directory = FSDirectory.open(new File("D:\\WorkSpace\\IdeaWorkspaces\\index\\CrmData").toPath());
indexReader = DirectoryReader.open(directory);
indexSearcher = new IndexSearcher(indexReader);
BooleanQuery.Builder booleanQuery=new BooleanQuery.Builder();
for (TermQuery tq:tqs
) {
booleanQuery.add(tq, BooleanClause.Occur.MUST);
}
BooleanQuery build = booleanQuery.build();
//执行查询
TopDocs topDocs = indexSearcher.search(build, 50);
//共查询到的document个数
System.out.println("查询结果总数量:" + topDocs.totalHits);
//遍历查询结果1
listc = new ArrayList<>();
CrmDataPojo crmDataPojo = null;
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document document = indexSearcher.doc(scoreDoc.doc);
crmDataPojo = new CrmDataPojo();
crmDataPojo.setData_Num(Integer.parseInt(document.get("data_Num")));
crmDataPojo.setData_Sort_(document.get("data_Sort"));
crmDataPojo.setData_Tiaomu(document.get("data_Tiaomu"));
crmDataPojo.setData_Value(document.get("data_Value"));
crmDataPojo.setData_State(document.get("data_State"));
listc.add(crmDataPojo);
float f = scoreDoc.score;
System.out.println("相似度:"+f);
}
//关闭indexreader
indexSearcher.getIndexReader().close();
} catch (IOException e) {
e.printStackTrace();
}finally {
//关闭indexreader
try {
indexSearcher.getIndexReader().close();
} catch (IOException e) {
e.printStackTrace();
}
return listc;
}
}
@Override
public int addDataIndex(CrmDataPojo crmDataPojo) {
Directory directory = null;
IndexWriter iw = null;
long count = 0;
try {
directory = FSDirectory.open(new File("D:\\WorkSpace\\IdeaWorkspaces\\index\\CrmData").toPath());
iw = new IndexWriter(directory,new IndexWriterConfig());
//创建数据名域
//第一个参数:域的名称
//第二个参数:域的内容
//第三个参数:是否存储
StringField data_numField = new StringField("data_Num", crmDataPojo.getData_Num()+"", Field.Store.YES);
StringField data_sortField = new StringField("data_Sort", crmDataPojo.getData_Sort_(), Field.Store.YES);
StringField data_tiaomuField = new StringField("data_Tiaomu", crmDataPojo.getData_Tiaomu(), Field.Store.YES);
StringField data_valueField = new StringField("data_Value", crmDataPojo.getData_Value()+"", Field.Store.YES);
StringField data_stateField = new StringField("data_State", crmDataPojo.getData_State()+"", Field.Store.YES);
//创建document对象
Document document = new Document();
document.add(data_numField);
document.add(data_sortField);
document.add(data_tiaomuField);
document.add(data_valueField);
document.add(data_stateField);
count = iw.addDocument(document);
iw.commit();
iw.close();
} catch (IOException e) {
e.printStackTrace();
}finally {
return (int)count;
}
}
@Override
public int updatermDataIndex(CrmDataPojo crmDataPojo) {
Directory directory = null;
IndexWriter iw = null;
long count = 0;
try {
directory = FSDirectory.open(new File("D:\\WorkSpace\\IdeaWorkspaces\\index\\CrmData").toPath());
iw = new IndexWriter(directory,new IndexWriterConfig(new IKAnalyzer()));
Term term = new Term("data_Num", crmDataPojo.getData_Num()+"");
//创建数据名域
//第一个参数:域的名称
//第二个参数:域的内容
//第三个参数:是否存储
StringField data_numField = new StringField("data_Num", crmDataPojo.getData_Num()+"", Field.Store.YES);
StringField data_sortField = new StringField("data_Sort", crmDataPojo.getData_Sort_(), Field.Store.YES);
StringField data_tiaomuField = new StringField("data_Tiaomu", crmDataPojo.getData_Tiaomu(), Field.Store.YES);
StringField data_valueField = new StringField("data_Value", crmDataPojo.getData_Value()+"", Field.Store.YES);
StringField data_stateField = new StringField("data_State", crmDataPojo.getData_State()+"", Field.Store.YES);
//创建document对象
Document document = new Document();
document.add(data_numField);
document.add(data_sortField);
document.add(data_tiaomuField);
document.add(data_valueField);
document.add(data_stateField);
count = iw.updateDocument(term,document);
iw.close();
} catch (IOException e) {
e.printStackTrace();
}finally {
return (int)count;
}
}
@Override
public int deletermDataIndex(int id) {
Directory directory = null;
long count = 0;
try {
directory = FSDirectory.open(new File("D:\\WorkSpace\\IdeaWorkspaces\\index\\CrmData").toPath());
IndexWriter iw = new IndexWriter(directory,new IndexWriterConfig());
TermQuery termQuery = new TermQuery(new Term("data_Num",id+""));
count = iw.deleteDocuments(termQuery);
iw.close();
} catch (IOException e) {
e.printStackTrace();
}finally {
return (int)count;
}
}
} 服务层实现类
package com.crm.service;
import com.crm.pojo.CrmDataPojo;
import com.crm.pojo.CrmProductPojo;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.TermQuery;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import static org.junit.Assert.*;
@RunWith(SpringJUnit4ClassRunner.class) //表示继承了SpringJUnit4ClassRunner类
@ContextConfiguration(locations = {"classpath:applicationContext.xml"})
public class CrmDataServiceTest {
@Resource
private CrmDataService crmDataService;
@Test
public void selAllDataType() {
System.out.println(crmDataService.selAllData());
}
@Test
public void addDataType() {
CrmDataPojo crmDataPojo = new CrmDataPojo();
crmDataPojo.setData_Num(444);
crmDataPojo.setData_Sort_("服务类型");
crmDataPojo.setData_Tiaomu("cccc");
crmDataPojo.setData_Value("cccc");
crmDataPojo.setData_State("是");
int i = crmDataService.addDataType(crmDataPojo);
if(i==1)
System.out.println("测试成功");
}
@Test
public void delDataType() {
int id = 222;
int i = crmDataService.delDataType(id);
if(i==1)
System.out.println("测试成功");
}
@Test
public void updDataType() {
CrmDataPojo crmDataPojo = new CrmDataPojo();
crmDataPojo.setData_Num(222);
crmDataPojo.setData_Sort_("服务类型");
crmDataPojo.setData_Tiaomu("投诉");
crmDataPojo.setData_Value("投诉");
crmDataPojo.setData_State("否");
int i = crmDataService.updDataType(crmDataPojo);
if(i==1)
System.out.println("测试成功");
}
@Test
public void createIndex() {
crmDataService.CreateIndex();
}
@Test
public void selAllDataByLucene() {
List listt = new ArrayList<>();
TermQuery ageQuery10=new TermQuery(new Term("data_Sort", "测试22"));
listt.add(ageQuery10);
List crmDataPojos = crmDataService.selAllDataByLucene(listt);
if(crmDataPojos!=null){
for (CrmDataPojo cdp: crmDataPojos
) {
System.out.println(cdp);
}
}else {
System.out.println("难顶啊");
}
}
@Test
public void addDataIndex() {
CrmDataPojo crmDataPojo = new CrmDataPojo();
crmDataPojo.setData_Num(11111);
crmDataPojo.setData_Sort_("测试");
crmDataPojo.setData_Tiaomu("难受");
crmDataPojo.setData_Value("想睡觉");
crmDataPojo.setData_State("难受难受");
int i = crmDataService.addDataIndex(crmDataPojo);
System.out.println(i);
}
@Test
public void updatermDataIndex() {
CrmDataPojo crmDataPojo = new CrmDataPojo();
crmDataPojo.setData_Num(11111);
crmDataPojo.setData_Sort_("测试22");
crmDataPojo.setData_Tiaomu("难受22");
crmDataPojo.setData_Value("想睡觉22");
crmDataPojo.setData_State("难受难受22");
int i = crmDataService.updatermDataIndex(crmDataPojo);
System.out.println(i);
}
@Test
public void deletermDataIndex() {
int i = crmDataService.deletermDataIndex(11111);
System.out.println(i);
}
}