Pandas.read_excel详解
文章目录
-
- 基础知识
- 语法
-
- 参数详解-index_col
- 参数详解-header
- 参数详解-usecols
- 参数详解-dtype
- 其他参数
- 多表读取
- 顺带提一句如何用pandas写数据到excel
基础知识
pandas 可以读取多种的数据格式,针对excel来说,可以使用read_excel()读取数据,如下:
import pandas as pd
df=pd.read_excel('test_xls')
print(df.head())

但是,值得注意的是:pandas在读取excel文件的时候需要调用读取第三方库(简称 引擎)
举个不太恰当的例子,张三买车得到了一次砸金蛋的机会,他当然不能用手砸,于是他顺手抄起旁边的锤子就砸了一个金蛋。这个例子里面的张三相当于pandas,金蛋就是excel文件,锤子就是读取文件的引擎。
在pandas中支持四种excel的文件读取引擎,我们用的最多的是"xlrd"和"openpyxl",其中"xlrd"是用来读取".xls"文件的,而"openpyxl"是用来读取".xlsx"及其他07版以后的新格式
其实"xlrd"和"openpyxl"都是python的库,可以单独的安装使用。命令:pip install xlrd
语法
- sheet_name:如果有多张表,这个参数可以用来指定要读取的表,如果不指定,但有多张表,那么就会读取活动的表(active worksheet)
- dtype:如果需要指定列的数据类型,则需要用到这个参数。读取文件时每列都会有默认的推断数据类型,但有时推断的会有问题;比如员工的工号如果是纯数字的,就会被推断成int,这样那些0开头的工号就会读取的有问题,这时我们就需要强制将工号列定义为str类型
- index_col:行索引所在列,详见下面的例子
- header:列名所在的行,详见后面的例子
- usecols:指定需要的列,默认所有的列都读取,如果指定其他的列就不读取
参数详解-index_col
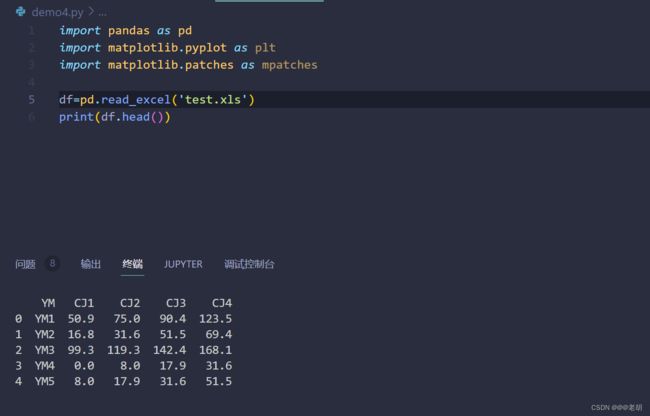
在该代码中,df.head()用来读取数据的前5行,pandas会在读取数据后自动在数据前加一行索引,也就是在YM前面的一列,这个索引一般是用来定位数据的。默认情况下,index_col=None,也就是说默认会添加一列自增的行索引。
如果数据本身有索引列,可以指定第几列为索引,如索引在第一列那我们就写index_col=0,第二列就写index_col=1
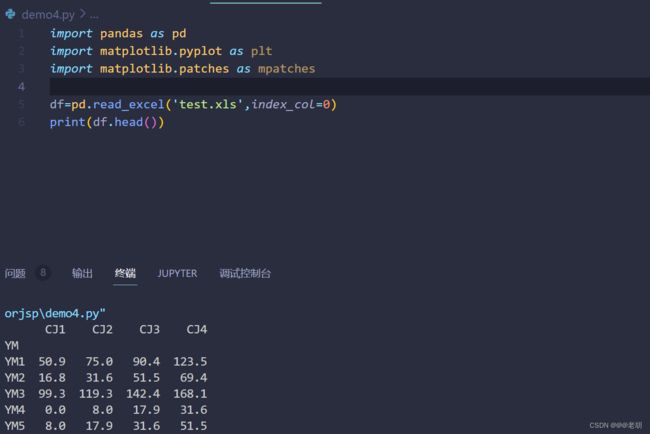
**索引可以不唯一,也可以有多层索引(MultiIndex)如果有多层索引,那么index_col需要传入一个数组,**如,df=pd.read_excel('test.xls',index_col=[0,1,3])就是说把第一列,第二列,第四列都作为索引
参数详解-header
如果不指定的话默认自动谈价一行列索引,如果一个数据中出现两个列索引,可以使用header来告诉pandas列索引所在的位置,如header=[0,1]就是告诉pandas第一列和第二列都是列索引
参数详解-usecols
如果不想显示某一列,可以使用usecols参数。代码有三张写法
- 使用列字母
- 使用列的位置序号
- 使用列名称
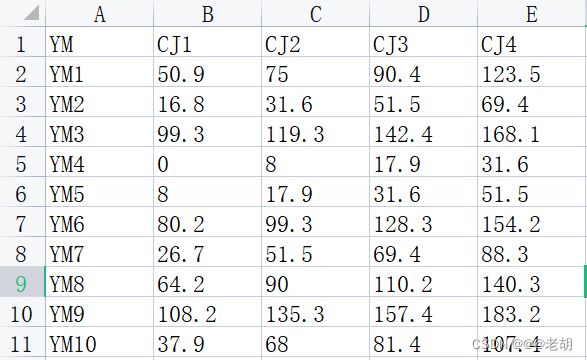
在以上数据中,使用一下代码有相等的效果
df = pd.read_excel("pf.xlsx",usecols=["A,C:E"])
df = pd.read_excel("pf.xlsx",usecols=[1,3,4,5])
df = pd.read_excel("pf.xlsx",usecols=["YM,CJ2,CJ3,CJ4"])
参数详解-dtype
可以用来修改某一列读取的参数类型,一般在数据读取的时候,读到某一列全部是数据,会默认把该列的数据类型定义为int类型,但是,如果遇到数据是0开头的,就会出现问题,因此,可以使用dtype来定义某一列的数据类型为想要的类型,一般是把int类型定义为str类型读取。如一个学号的数据为001,如果不使用dtype,读取的时候,在终端上显示的就是1,如果使用dtype={"学号" : str }后,输出的结果为001
其他参数
- na_values:自定义的空值,比如说张三第一学期的语文考试因为某些原因没有靠,成绩那边填写的是“缺考”。那我们就可以设置na_values=[“缺考”],这样导入后张三第一学期的成绩就会自动被识别为pandas的默认空占位符NaN
- parse_dates:如果excel表里面的日期列填写的不太规范,可以使用这个参数,告诉pandas哪一列是日期,保证日期格式读取的准确性
- true_values:指定真值,比如true_values=[“是”],那么,数据中的”是“就会被识别为True
- false_values:指定假值,比如false_values=[“否”],那么,数据中的”否“就会被识别为False
多表读取
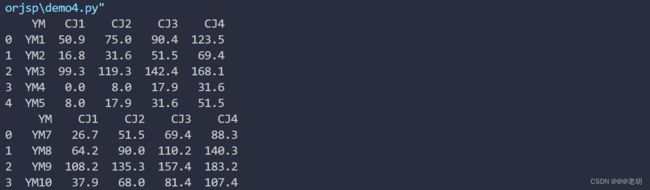
接下来让我们来看另一种情况,上面的例子中,Sheet1和Sheet2放置在同一张表的,如果想要区分为两张表,一般方法是可以读两遍read_excel,搭配sheet_name=[表名]参数。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
df1=pd.read_excel('test.xls',sheet_name='Sheet1')
print(df1.head())
df2=pd.read_excel('test.xls',sheet_name='Sheet2')
print(df2.head())
顺带提一句如何用pandas写数据到excel
import pandas as pd
# pandas 存储数据到excel
def pd_toexcel(data,filename):
dfData = { # 用字典设置DataFrame所需数据
'序号':data[0],
'项目':data[1],
'数据':data[2]
}
df = pd.DataFrame(dfData) # 创建DataFrame
df.to_excel(filename,index=False) # 存表,去除原始索引列(0,1,2...)
"""--------------数据用例---------------"""
orderIds=[1,2,3]
items=['A','B','C']
myData=[10,20,30]
testData=[orderIds,items,myData]
filename='write.xlsx'
pd_toexcel(testData,filename)

PS:这里需要用到openpyxl模块