1 Spark的环境搭建
1 Spark的环境搭建
1.1 Windows - Spark安装
一、下载并安装软件
\1. 下载并安装Java8:https://www.oracle.com/java/technologies/downloads/
(1) 原因:Spark由Scala语言开发。而Scala代码会被编译成Java字节码。因此Spark的运行需要Java环境
\2. 下载并安装Python:https://www.python.org/
(1) 原因:我们将利用Spark提供的Python API编程
(2) 安装时勾选“Add Python xx to Path”
\3. 下载并解压缩Spark到C盘根目录:比如 C:\Spark-3.03-bin-hadoop2.7
(1)下载版本:

\4. 在C盘根目录中创建hadoop\bin目录,并将winutils.exe放入bin目录中
(1) 该工具的作用是能让Spark更改文件(夹)权限
二、设置环境变量
(1)
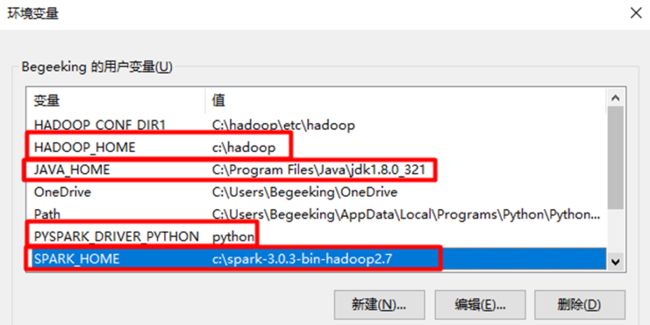
(1) 为Path环境变量添加新值

三、修改Log等级
为避免在执行Spark命令时,输出过多干扰内容,故修改Spark的Log等级。
在spark的安装目录中的conf目录中,找到log4j.properties.template文件,并复制一份,然后将该副本重命名为log4j.properties。之后打开该文件,找到第19行,将INFO更改为ERROR,然后保存关闭该文件。

四、测试是否安装成功
(1)打开cmd,然后输入 pyspark,可以看到如下界面
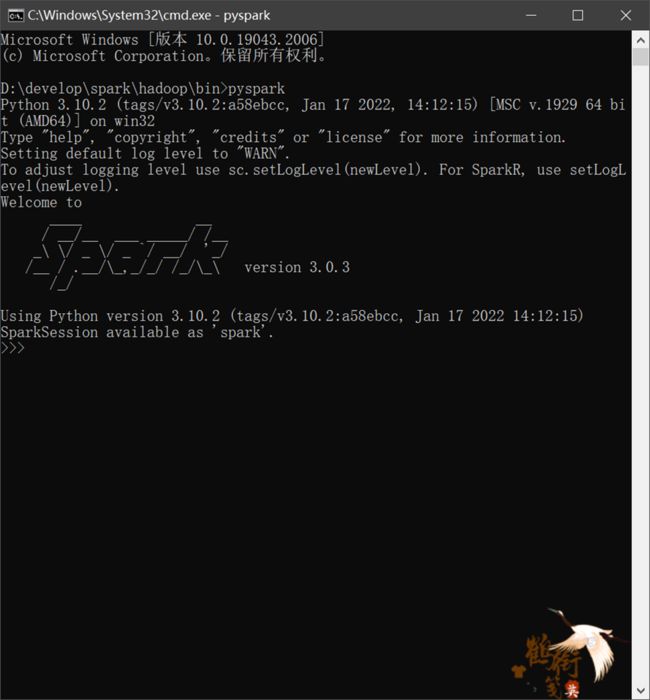
然后输入exit()命令退出
(2)在spark安装目录的\examples\src\main\python中,找到wordcount.py文件,复制到c盘跟目录。之后,再在c盘根目录中创建一个data.txt文件,任意输入一些以空格分隔的英文单词并保存。然后在cmd中输入:
spark-sumit wordcount.py data.txt
如果能统计出单词数量即可
