你说精通MySQL其实很菜jī(性能调优篇):选择合适的数据类型(深入剖析常见数据类型)
你说精通MySQL其实很菜jī(性能调优篇):选择合适的数据类型(深入剖析常见数据类型)
- 一、前言
- 二、如何选择数据类型
-
- 2.1 原则一:更小的通常更好
- 2.2 原则二:简单就好
- 2.3 原则三:尽量避免存储 NULL
- 2.4 数据类型详解
-
- 2.4.1 整数类型(精确值)
-
- 2.4.1.1 合适的整数类型
- 2.4.2 实数类型
-
- 2.4.2.1 浮点类型(近似值)- FLOAT
- 2.4.2.2 浮点类型(近似值)- DOUBLE
- 2.4.2.3 定点类型(精确值)- DECIMAL, NUMERIC
- 2.4.2.4 合适的实数类型
- 2.4.3 字符串类型
-
- 2.4.3.1 CHAR 和 VARCHAR 类型
-
- 2.4.3.1.1 CHAR 类型 - 说明
- 2.4.3.1.2 CHAR 类型 - 占用字节
- 2.4.3.1.3 什么是 BMP 字符
- 2.4.3.1.4 Unicode 字符集一般特征
- 2.4.3.1.5 TINYINT(1) 、CHAR(1) 和 VARCHAR(1) 哪个更优?
- 2.4.3.1.6 VARCHAR 类型 - 说明
- 2.4.3.1.7 VARCHAR 类型 - 占用字节
- 2.4.3.1.8 VARCHAR 类型 - VARCHAR(M) 的 M 能设置多大的值,能设置最大为 65535 吗?
- 2.4.3.1.9 VARCHAR 比 CHAR 更省空间?
- 2.4.3.1.10 InnoDB存储引擎中,过长的 VARCHAR 值会存储为 BLOB?
- 2.4.3.1.11 慷慨是不明智的
- 2.4.3.1.12 合适的字符串类型
- 2.4.3.2 BLOB 和 TEXT 类型
-
- 2.4.3.2.1 BLOB 类型 - 说明
- 2.4.3.2.2 BLOB 类型 - 字节占用
- 2.4.3.2.3 TEXT 类型 - 说明
- 2.4.3.2.4 TEXT 类型 - 字节占用
- 2.4.3.2.5 在数据库中存储图像?
- 2.4.3.2.6 《高性能MySQL 第4版》存在的 BLOB 描述错误
- 2.4.3.2.6 BLOB 和 TEXT 的实际应用场景
- 2.4.3.3 枚举 类型
-
- 2.4.3.3.1 ENUM 类型的特点
- 2.4.3.3.2 使用 ENUM 类型注意事项
- 2.4.3.3.3 ENUM 类型应用场景
- 2.4.4 日期和时间 类型
-
- 2.4.4.1 什么是 fsp ?
- 2.4.4.2 日期和时间类型存储要求
- 2.4.4.3 DATE 类型
- 2.4.4.4 DATETIME 类型
- 2.4.4.5 TIMESTAMP 类型
- 2.4.4.6 TIME 类型
- 2.4.4.7 YEAR 类型
- 2.4.4.8 时间值中的小数秒
- 2.4.4.9 《高性能MySQL 第4版》存在的 DATETIME 和 TIMESTAMP 描述错误
- 2.4.4.10 合适的日期和时间类型
- 2.4.5 特殊数据 类型
-
- 2.4.5.1 IP地址处理
-
- 2.4.5.1.1 INET_ATON(expr) 函数
- 2.4.5.1.2 INET_NTOA(expr) 函数
- 2.4.5.1.3 INET6_ATON(expr) 函数
- 2.4.5.1.4 INET6_NTOA(expr) 函数
- 2.4.5.1.5 合适的特殊数据类型
- 三、总结
- 四、资料参考
一、前言
大名鼎鼎的《高性能MySQL》中文版出第 4 版新书啦!第 4 版内容主要基于 MySQL 8.0 ,向下兼容第 3 版,而第3版内容主要基于 MySQL 5.5,所以两者内容有相同,也有不同,即第 4 版的部分章节内容沿用了第 3 版的内容,但会做适当的修改和新增。笔者同时购买有第 3 版、第 4 版书籍,以此对比内容差异,并配合MySQL官网进行一些知识点的验证和探讨,能力有限,希望广大读者指出错误并纠正。
本文主要围绕MySQL性能优化中,如何选择合适的数据类型并展开探讨。选择合适的数据类型,除了可以节省大量的存储空间,对查询性能也有很重要的影响。
BIT、BINARY、VARBINARY、SET、JSON、Spatial等数据类型目前没有做详细介绍,笔者我也很少接触,后面考虑要不要补充。
本文由 CSDN@大白有点菜 原创,如需转载,请说明出处。如果觉得文章还不错,可以 点赞+收藏+关注 ,你们的肯定是我创作优质博客的最大的动力。
二、如何选择数据类型
本文主要基于MySQL官方 8.0 的文档和《高性能MySQL》第3版、第4版进行选择合适的数据类型(Data Types)探讨。为什么选择官方 8.0 的文档呢?这样的好处是,数据类型从低版本沿用至高版本,在字节存储上发生了某些变化,8.0 的官方文档会作说明。
【MySQL 8.0 官方文档,如果需要查看 5.7 的文档,只需将地址中的 8.0 改为 5.7 即可】:
https://dev.mysql.com/doc/refman/8.0/en/data-types.html
2.1 原则一:更小的通常更好
尽量使用能够正确存储的、最小的数据类型,通常更快,因为它们占用磁盘、内存和CPU缓存的空间更少,并且处理时需要的CPU周期也更少。合理预估值存储的范围,因为在 Schema 中的多个地方增加数据类型范围会很耗时。
2.2 原则二:简单就好
简单数据类型的操作通常需要更少的CPU周期。例如,整型数据比字符型数据的比较操作代价更低,因为字符型数据的比较因字符集(Character Sets)和排序规则(Collations)更复杂。
2.3 原则三:尽量避免存储 NULL
NULL 可以是列的默认属性,通常情况下最好指定列为 NOT NULL,除非明确需要存储 NULL 值。如果查询中包含可为 NULL 的列,对MySQL来说更难优化,因为列为 NULL 使得索引、索引统计和值比较都更复杂,会使用更多的存储空间,在MySQL里需要特殊处理。
为 NULL 的列被索引时,每个索引记录需要一个额外的字节,在 MyISAM 里甚至还可能导致固定大小的索引(例如只有一个整数列的索引)变成可大可小的索引。【此段内容只在高性能MySQL第3版出现,在第4版移除了,非完全的原话,语句做适当删,大概意思不变】
通常,列改为 NOT NULL 带来的性能提升比较小,所以(调优时)没有必要从现有的 Schema 中查找并修改这种情况,除非不改为 NOT NULL 会导致问题。
如果计划在列上建索引,应尽量避免设计成可为 NULL 的列。有例外,如 InnoDB 使用单独的位(bit)存储 NULL 值,所以对于稀疏数据(即很多值为 NULL ,只有少数行的列有非 NULL 值)有很好的的空间效率,但这一点不适用于 MyISAM。【此段内容只在高性能MySQL第3版出现,在第4版移除了,非完全的原话,语句做适当删减,大概意思不变】
2.4 数据类型详解
2.4.1 整数类型(精确值)
【MySQL 8.0 官方文档 - 整数类型(Integer Types)】:
https://dev.mysql.com/doc/refman/8.0/en/integer-types.html
MySQL 支持的整数类型所需的存储和范围:
| 类型 | 存储(字节) | 有符号最小值 | 无符号最小值 | 有符号最大值 | 无符号最大值 |
|---|---|---|---|---|---|
| TINYINT | 1 | -128 | 0 | 127 | 255 |
| SMALLINT | 2 | -32768 | 0 | 32767 | 65535 |
| MEDIUMINT | 3 | -8388608 | 0 | 8388607 | 16777215 |
| INT | 4 | -2147483648 | 0 | 2147483647 | 4294967295 |
| BIGINT | 8 | -263 | 0 | 263-1 | 264-1 |
从表格可以看出,存储空间(字节)最小的是 TINYINT 整数类型,只占用 1 个字节,如果是有符号的,值范围为 [-128,127],如果是无符号的,值范围为 [0,255]。注意,在数据表中定义字段为 tinyint 类型,假设长度定义为 1 ,写法为 tinyint(1),并不代表只能存储小于 10 或者大于 -10 的整数,即 [-9,9] 之间的整数,这是误解!应该正确理解为 显示宽度属性(可以看我写的另一篇博客 《你说精通MySQL其实很菜jī(基础篇):你不一定会的基本技巧或知识点(值得一看)》,第 7.1 小章关于 显示宽度属性 的说明和正确用法),而不是数值的位数,存储值的范围还是 [-128,127] 或 [0,255],就是说 tinyint(1) 和 tinyint(20) 存储和计算是相同的。
有符号和无符号类型有相同的存储空间和性能,根据数据实际范围选取合适的类型。
在开发中,我们经常使用 tinyint 或 char 或 varchar 类型存储“性别(0-男、1-女)”、“是否(0-否、1-是)”类似这样的字段的值,值要么为 0 , 要么为 1 ,要么在 0 至 9 数字范围内。到底选择 tinyint 还是 char 还是 varchar 先不探讨(到后面讲到 char 和 varchar 类型再去探讨)使用哪种类型更优,有人为了写法方便直接使用 int 类型,这肯定是糟糕的做法,因为 int 占用 4 个字节,tinyint 占用才 1 个字节,tinyint 数据存储空间占用更少,对磁盘更友好。
2.4.1.1 合适的整数类型
如果值在
[-128,255]内,选择TINYINT整数类型优于其它整数类型(SMALLINT、MEDIUMINT、INT、BIGINT)。
2.4.2 实数类型
实数类型主要分为:
1、非精确的浮点类型(Floating-Point Types),包括
FLOAT和DOUBLE类型,表示近似数值数据值。
2、精确的定点类型(Fixed-Point Types):包括DECIMAL、NUMERIC(在 MySQL 中,NUMERIC 被实现为 DECIMAL),表示精确的数字数据值。
2.4.2.1 浮点类型(近似值)- FLOAT
【MySQL 8.0 官方文档 - 浮点类型(近似值)(Floating-Point Types (Approximate Value))】:
https://dev.mysql.com/doc/refman/8.0/en/floating-point-types.html
在MySQL 8.0 官方文档描述中,单精度 FLOAT 类型占用 4 个字节,除了缺省参数的 FLOAT 语法外,还有两种语法:FLOAT(p) 和 FLOAT(M,D) ,两者区别如下:
1、
FLOAT(p):标准语法。p 指“位”,用来指定精度(但不是指数的范围),精度值仅用于确定存储大小。从 0 到 24 的精度,即 0 <= p <= 24,该列还是 FLOAT 类型。如果 25 <= p <= 53,那么该列会转换成 DOUBLE 类型。【注意】此处官方文档提到这个 p 值的范围是有问题的:从 0 到 23,从 24 到 53。下面会去验证这个问题的错误性。
【FLOAT(p)- 官方文档原文及谷歌翻译】:
For FLOAT, the SQL standard permits an optional specification of the precision (but not the range of the exponent) in bits following the keyword FLOAT in parentheses, that is,FLOAT(p). MySQL also supports this optional precision specification, but the precision value inFLOAT(p)is used only to determine storage size. A precision from 0 to 23 results in a 4-byte single-precision FLOAT column. A precision from 24 to 53 results in an 8-byte double-precision DOUBLE column.
对于 FLOAT,SQL 标准允许在括号中的关键字 FLOAT 之后以位为单位可选地指定精度(但不是指数的范围),即 FLOAT(p)。 MySQL 也支持这个可选的精度规范,但 FLOAT(p) 中的精度值仅用于确定存储大小。从 0 到 23 的精度产生 4 字节单精度 FLOAT 列。从 24 到 53 的精度导致 8 字节双精度 DOUBLE 列。
2、FLOAT(M,D):非标准语法。(M,D) 表示最多可以存储 M 位(整数位数+小数位数)的值,D 表示小数点位数。例如,FLOAT(7,4) 的列显示为 999.0099 ,整数位数为(7 - 4 = 3)位,小数位数为 4 位。MySQL 在存储值时会进行舍入,将 999.00009 插入 FLOAT(7,4) 列,近似结果为 999.0001 。
【FLOAT(M,D)- 官方文档原文及谷歌翻译】:
MySQL permits a nonstandard syntax:FLOAT(M,D)orREAL(M,D)or DOUBLE PRECISION(M,D). Here, (M,D) means than values can be stored with up to M digits in total, of which D digits may be after the decimal point. For example, a column defined as FLOAT(7,4) is displayed as -999.9999. MySQL performs rounding when storing values, so if you insert 999.00009 into a FLOAT(7,4) column, the approximate result is 999.0001.
MySQL 允许非标准语法:FLOAT(M,D) 或 REAL(M,D) 或 DOUBLE PRECISION(M,D)。这里,(M,D)表示最多可以存储M位的值,其中D位可以在小数点后。例如,定义为 FLOAT(7,4) 的列显示为 -999.9999。 MySQL 在存储值时会进行舍入,因此如果将 999.00009 插入 FLOAT(7,4) 列,则近似结果为 999.0001。
3、从 MySQL 8.0.17 开始,不推荐使用非标准的 FLOAT(M,D) 语法,在未来的 MySQL 版本中可能会删除对它的支持。
4、官方建议:为了获得最大的可移植性,需要存储近似数字数据值的代码应该使用 FLOAT ,而不指定精度或位数。
【官方文档原文及谷歌翻译】:
For maximum portability, code requiring storage of approximate numeric data values should use FLOAT or DOUBLE PRECISION with no specification of precision or number of digits.
为了获得最大的可移植性,需要存储近似数字数据值的代码应该使用 FLOAT 或 DOUBLE PRECISION,而不指定精度或位数。
FLOAT(p) 会因 p 的值不同而从 FLOAT 自动转换为 DOUBLE ,当 0 <= p <= 24 ,列还是 FLOAT 类型,当 25 <= p <= 53,列的 FLOAT 类型会转换成 DOUBLE 类型。官网文档中,说到 p 的值在 0 到 23 之间,列是 FLOAT 类型,p 值在 24 到 53 之间,由 FLOAT 类型转换成 DOUBLE 类型了,为什么说官网文档的说法有问题呢?
在 Stack Overflow 上有这么一个问题:What is the storage size required for a float(24) column with MySQL?,有网友回答到使用 show create table 表名 去进行测试,可以看到 FLOAT(24) 是浮点数,而 FLOAT(25) 是双精度数。
那就开始验证 FLOAT(p) 这种语法吧!步骤如下:
(1)使用 Navicat 工具在 MySQL 8.0 新建一个表 tb1,定义一个字段 num ,类型为 FLOAT 。
CREATE TABLE `tb1` (
`num` float DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

(2)字段 num 的长度(即 p 值)设置为 24 ,并保存,可以看到类型依然为 FLOAT ,没有变为 DOUBLE ,也不显示设置的 24 。


(3)一旦将长度(即 p 值)设置为 25 并保存,立马看到 FLOAT 类型转换为 DOUBLE 类型,不过也不显示设置的 25 。


(4)由此验证官网文档中 FLOAT 类型保持不变的 p 值范围不是 0 <= p <= 23,而是 0 <= p <= 24,由 FLOAT 转换为 DOUBLE 的 p 值临界点是 25 。

(5)p 值的最大值是 53 ,一旦超过(例如 54),那么会报错 1063 - Incorrect column specifier for column 'xxx'。


其实,官方其它文档中有介绍到 数据类型存储要求(Data Type Storage Requirements),网址为 https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html#data-types-storage-reqs-numeric,明确了 FLOAT(p) 的 p 值范围,就是当 0 <= p <= 24 ,列还是 FLOAT 类型,当 25 <= p <= 53,列的 FLOAT 类型会转换成 DOUBLE 类型。经过验证,在 https://dev.mysql.com/doc/refman/8.0/en/floating-point-types.html 上描述到 p 值范围是有问题的。

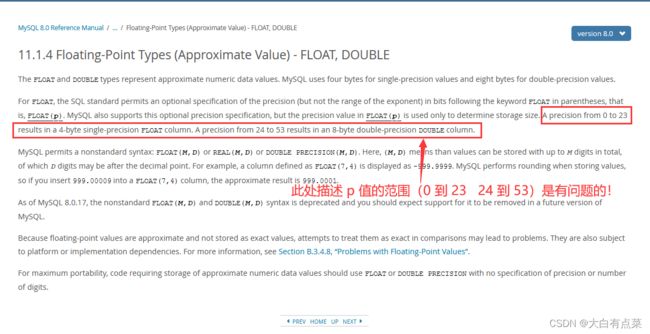
FLOAT(M,D) 用法其实也不难,可以存储一个 M 位(整数位数+小数位数)的浮点数,D 表示小数点位数。例如,FLOAT(7,4),小数部分位数为 4 ,整数部分位数为 7 - 4 = 3,存储 999.0066 是正常的,而存储 9999.0066 会报错(ERROR 1264 (22003):Out of range value for column 'xxx' at row 1)。如图所示:



还要注意,FLOAT 类型的值只是一个近似值,虽然在 FLOAT(7,4) 中 999.00668 可以存储,但是最终会进行四舍五入处理,得到近似结果 999.0067 ,就是说精度会受影响。如图所示:

如果想要了解MySQL中 FLOAT 类型,可以使用 help float 命令查看语法和值范围,如图所示,对应官网文档地址:https://dev.mysql.com/doc/refman/8.0/en/numeric-type-syntax.html 。FLOAT 的值范围为:[-3.402823466E+38, -1.175494351E-38],0,[1.175494351E-38, 3.402823466E+38] 。
mysql> help float

【FLOAT 类型语法说明,附谷歌翻译】
FLOAT(p) [UNSIGNED] [ZEROFILL]
A floating-point number. p represents the precision in bits, but MySQL uses this value only to determine whether to use FLOAT or DOUBLE for the resulting data type. If p is from 0 to 24, the data type becomes FLOAT with no M or D values. If p is from 25 to 53, the data type becomes DOUBLE with no M or D values. The range of the resulting column is the same as for the single-precision FLOAT or double-precision DOUBLE data types described earlier in this section.
一个浮点数。 p 表示精度,单位为位,但 MySQL 仅使用此值来确定结果数据类型是使用 FLOAT 还是 DOUBLE。如果 p 从 0 到 24,则数据类型变为 FLOAT,没有 M 或 D 值。如果 p 从 25 到 53,则数据类型变为 DOUBLE,没有 M 或 D 值。结果列的范围与本节前面所述的单精度 FLOAT 或双精度 DOUBLE 数据类型相同。
UNSIGNED, if specified, disallows negative values. As of MySQL 8.0.17, the UNSIGNED attribute is deprecated for columns of type FLOAT (and any synonyms) and you should expect support for it to be removed in a future version of MySQL. Consider using a simple CHECK constraint instead for such columns.
UNSIGNED,如果指定,则不允许负值。从 MySQL 8.0.17 开始,不推荐使用 FLOAT 类型(和任何同义词)类型的列的 UNSIGNED 属性,您应该期望在未来版本的 MySQL 中删除对它的支持。考虑对此类列使用简单的 CHECK 约束。
Using FLOAT might give you some unexpected problems because all calculations in MySQL are done with double precision. See Section B.3.4.7, “Solving Problems with No Matching Rows”.
使用 FLOAT 可能会给您带来一些意想不到的问题,因为 MySQL 中的所有计算都是以双精度完成的。请参阅第 B.3.4.7 节,“解决没有匹配行的问题”。
2.4.2.2 浮点类型(近似值)- DOUBLE
【MySQL 8.0 官方文档 - 浮点类型(近似值)(Floating-Point Types (Approximate Value))】:
https://dev.mysql.com/doc/refman/8.0/en/floating-point-types.html
在MySQL 8.0 官方文档描述中,双精度 DOUBLE 类型占用 8 个字节,只有一种非标准语法 DOUBLE(M,D) 写法和不写任何精度、位数的 DOUBLE。DOUBLE(M,D) 用法和 FLOAT(M,D) 是一样的,下面不做过多说明。
1、
DOUBLE(M,D):非标准语法。(M,D) 表示最多可以存储 M 位(整数位数+小数位数)的值,D 表示小数点位数。例如,DOUBLE(7,4) 的列显示为 999.0066 ,整数位数为(7 - 4 = 3)位,小数位数为 4 位。MySQL 在存储值时会进行舍入,将 999.00009 插入 DOUBLE(7,4) 列,近似结果为 999.0001 。
【DOUBLE(M,D)- 官方文档原文及谷歌翻译】:
MySQL permits a nonstandard syntax:FLOAT(M,D)orREAL(M,D)or DOUBLE PRECISION(M,D). Here, (M,D) means than values can be stored with up to M digits in total, of which D digits may be after the decimal point. For example, a column defined as FLOAT(7,4) is displayed as -999.9999. MySQL performs rounding when storing values, so if you insert 999.00009 into a FLOAT(7,4) column, the approximate result is 999.0001.
MySQL 允许非标准语法:FLOAT(M,D) 或 REAL(M,D) 或 DOUBLE PRECISION(M,D)。这里,(M,D)表示最多可以存储M位的值,其中D位可以在小数点后。例如,定义为 FLOAT(7,4) 的列显示为 -999.9999。 MySQL 在存储值时会进行舍入,因此如果将 999.00009 插入 FLOAT(7,4) 列,则近似结果为 999.0001。
2、从 MySQL 8.0.17 开始,不推荐使用非标准的 DOUBLE(M,D) 语法,在未来的 MySQL 版本中可能会删除对它的支持。
3、官方建议:为了获得最大的可移植性,需要存储近似数字数据值的代码应该使用 DOUBLE PRECISION,而不指定精度或位数。
【官方文档原文及谷歌翻译】:
For maximum portability, code requiring storage of approximate numeric data values should use FLOAT or DOUBLE PRECISION with no specification of precision or number of digits.
为了获得最大的可移植性,需要存储近似数字数据值的代码应该使用 FLOAT 或 DOUBLE PRECISION,而不指定精度或位数。
DOUBLE 类型的值也是一个近似值,在 DOUBLE(7,4) 中 999.00668 可以存储,最终会进行四舍五入处理,得到近似结果 999.0067 。如图所示:
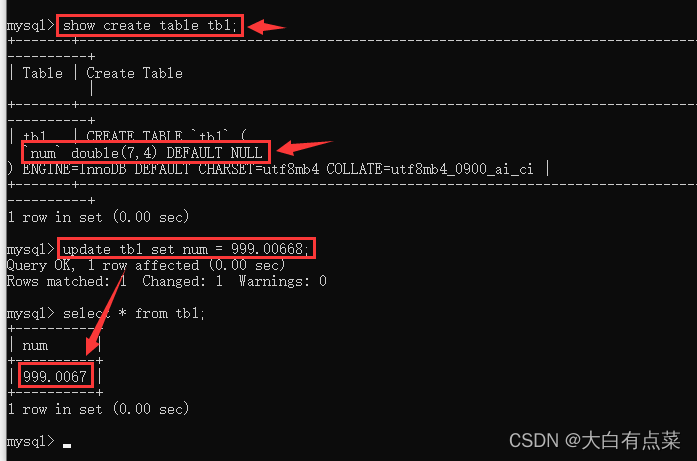
如果想要了解MySQL中 DOUBLE 类型,可以使用 help double 命令查看语法和值范围,如图所示,对应官网文档地址:https://dev.mysql.com/doc/refman/8.0/en/numeric-type-syntax.html 。DOUBLE 的值范围为:[-1.7976931348623157E+308, -2.2250738585072014E-308],0,[2.2250738585072014E-308, 1.7976931348623157E+308] 。
mysql> help double

【DOUBLE 类型语法和值范围说明,附谷歌翻译】
DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
A normal-size (double-precision) floating-point number. Permissible values are -1.7976931348623157E+308 to -2.2250738585072014E-308, 0, and 2.2250738585072014E-308 to 1.7976931348623157E+308. These are the theoretical limits, based on the IEEE standard. The actual range might be slightly smaller depending on your hardware or operating system.
一个正常大小(双精度)的浮点数。允许的值为 -1.7976931348623157E+308 到 -2.2250738585072014E-308、0 和 2.2250738585072014E-308 到 1.7976931348623157E+308。这些是基于 IEEE 标准的理论限制。根据您的硬件或操作系统,实际范围可能会略小。
M is the total number of digits and D is the number of digits following the decimal point. If M and D are omitted, values are stored to the limits permitted by the hardware. A double-precision floating-point number is accurate to approximately 15 decimal places.
M 是总位数,D 是小数点后的位数。如果省略 M 和 D,则值将存储到硬件允许的限制范围内。双精度浮点数精确到大约 15 位小数。
DOUBLE(M,D) is a nonstandard MySQL extension. As of MySQL 8.0.17, this syntax is deprecated and you should expect support for it to be removed in a future version of MySQL.
DOUBLE(M,D) 是一个非标准的 MySQL 扩展。从 MySQL 8.0.17 开始,此语法已弃用,您应该期望在未来的 MySQL 版本中删除对它的支持。
UNSIGNED, if specified, disallows negative values. As of MySQL 8.0.17, the UNSIGNED attribute is deprecated for columns of type DOUBLE (and any synonyms) and you should expect support for it to be removed in a future version of MySQL. Consider using a simple CHECK constraint instead for such columns.
UNSIGNED,如果指定,则不允许负值。从 MySQL 8.0.17 开始,不推荐使用 DOUBLE 类型(和任何同义词)类型的列的 UNSIGNED 属性,您应该期望在未来版本的 MySQL 中删除对它的支持。考虑对此类列使用简单的 CHECK 约束。
DOUBLE PRECISION[(M,D)] [UNSIGNED] [ZEROFILL], REAL[(M,D)] [UNSIGNED] [ZEROFILL]
These types are synonyms for DOUBLE. Exception: If the REAL_AS_FLOAT SQL mode is enabled, REAL is a synonym for FLOAT rather than DOUBLE.
这些类型是 DOUBLE 的同义词。例外:如果启用了 REAL_AS_FLOAT SQL 模式,则 REAL 是 FLOAT 的同义词,而不是 DOUBLE。
2.4.2.3 定点类型(精确值)- DECIMAL, NUMERIC
【MySQL 8.0 官方文档 - 定点类型(精确值)(Fixed-Point Types (Exact Value) )】:
https://dev.mysql.com/doc/refman/8.0/en/fixed-point-types.html
读者可去看我之前写的一篇博客《你不一定了解MySQL中的Decimal数据类型》,里面很详细地介绍了 DECIMAL 这种数据类型,此处就不过多地重复造轮子了。
DECIMAL(M,D) 占用字节大小与参数 M 和 D 有关,可能比 BIGINT 类型大,也可能比 BIGINT 类型小,BIGINT 类型占用字节 8 bytes。
涉及到精确的数值,例如银行卡金额,某些仪器测试的精确数值,要使用 DECIMAL 类型或 BIGINT 类型去存储。什么,BIGINT 类型也能存储精确值?不是整数类型吗,不是不支持小数吗?换个角度思考,假设要存储的精确值是 6789.12345678 ,可以在代码中将其乘以 100000000 ,即 6789.12345678 x 100000000 = 678912345678,不就得到整数了吗?查询并返回数据时,在代码中将其再除以 100000000 ,那就得到真实的精确值 6789.12345678 了呀!
《阿里巴巴Java开发手册》中,OOP规约 章节有这么一条:【强制】对于任何货币金额,均以最小货币单位且整型类型存储。也就是说,开发手册强制要求金额使用整型类型存储。
《阿里巴巴Java开发手册》中,MySQL数据库 - 建表规约 章节说到:【强制】小数类型为 decimal ,禁止使用 float 和 double 类型。[说明:在存储时,float 和 double 类型存在精度损失的问题,很可能在比较值的时候,得到不正确的结果。如果存储的数据范围超过 decimal 的范围,那么建议将数据拆成整数和小数并分开存储。] 开发手册强制要求小数使用 decimal ,不能使用 float 和 double 。
在进行数值运算方面,整型的性能更好,占用的存储空间(字节)也可能更小。无符号BIGINT UNSIGNED支持的值范围很大,在某些方面替代 DECIMAL 是没问题的,不会出现超出值范围问题。
在《高性能MySQL 第3版》中第 114 页有这么一段原话,我觉得和官方文档描述有出入,在第 4 版移除了这部分内容:
MySQL 5.0 和更高版本将数字打包保存到一个二进制字符串中(每4个字节存9个数字)。例如,DECIMAL(18,9) 小数点两边将各存储 9 个数字,一共使用 9 个字节:小数点前的数字用 4 个字节,小数点后的数字用 4 个字节,小数点本身占 1 个字节。
哪里有出入呢?因为我研究过官方文档,并没有提到小数点也要占用 1 个字节,官方文档中说到 DECIMAL(18,9) 占用 8 个字节。不确定是《高性能MySQL 第3版》书中作者写错,还是官方文档遗漏把小数点也算上去,还是小数点根本就不占 1 字节。笔者我更倾向于小数点是不占用 1 字节的。
2.4.2.4 合适的实数类型
1、如果对存储的实数数值精度没有要求,那就建议使用 FLOAT 类型,占用 4 字节,更省空间,使用 DOUBLE 没有任何优势。
2、如果存储的实数数值对精度要求高(精确计算),那就使用 DECIMAL 或 BIGINT 。对于财务数据,在数据量比较大的时候,建议使用 BIGINT 代替 DECIMAL(因为 DECIMAL 精确计算代价高),将需要存储的货币单位根据小数的位数乘以相应的倍数即可。
2.4.3 字符串类型
2.4.3.1 CHAR 和 VARCHAR 类型
【MySQL 8.0 官方文档 - CHAR 和 VARCHAR 类型】:
https://dev.mysql.com/doc/refman/8.0/en/char.html
【MySQL 8.0 官方文档是这么描述 CHAR 和 VARCHAR 类型的,并附上谷歌翻译】:
The CHAR and VARCHAR types are similar, but differ in the way they are stored and retrieved. They also differ in maximum length and in whether trailing spaces are retained.
CHAR 和 VARCHAR 类型相似,但存储和检索方式不同。它们在最大长度和是否保留尾随空格方面也不同。
The CHAR and VARCHAR types are declared with a length that indicates the maximum number of characters you want to store. For example, CHAR(30) can hold up to 30 characters.
CHAR 和 VARCHAR 类型的声明长度表示要存储的最大字符数。例如,CHAR(30) 最多可以包含 30 个字符。
The length of a CHAR column is fixed to the length that you declare when you create the table. The length can be any value from 0 to 255. When CHAR values are stored, they are right-padded with spaces to the specified length. When CHAR values are retrieved, trailing spaces are removed unless the PAD_CHAR_TO_FULL_LENGTH SQL mode is enabled.
CHAR 列的长度固定为您在创建表时声明的长度。长度可以是 0 到 255 之间的任意值。当存储 CHAR 值时,它们会用空格向右填充到指定的长度。检索 CHAR 值时,将删除尾随空格,除非启用 PAD_CHAR_TO_FULL_LENGTH SQL 模式。
Values in VARCHAR columns are variable-length strings. The length can be specified as a value from 0 to 65,535. The effective maximum length of a VARCHAR is subject to the maximum row size (65,535 bytes, which is shared among all columns) and the character set used. See Section 8.4.7, “Limits on Table Column Count and Row Size”.
VARCHAR 列中的值是可变长度字符串。长度可以指定为 0 到 65,535 之间的值。 VARCHAR 的有效最大长度取决于最大行大小(65,535 字节,由所有列共享)和使用的字符集。请参阅第 8.4.7 节,“表列数和行大小的限制”。
In contrast to CHAR, VARCHAR values are stored as a 1-byte or 2-byte length prefix plus data. The length prefix indicates the number of bytes in the value. A column uses one length byte if values require no more than 255 bytes, two length bytes if values may require more than 255 bytes.
与 CHAR 不同,VARCHAR 值存储为 1 字节或 2 字节长度前缀加上数据。长度前缀指示值中的字节数。如果值需要不超过 255 个字节,一列使用一个长度字节,如果值可能需要超过 255 个字节,则使用两个长度字节。
If strict SQL mode is not enabled and you assign a value to a CHAR or VARCHAR column that exceeds the column’s maximum length, the value is truncated to fit and a warning is generated. For truncation of nonspace characters, you can cause an error to occur (rather than a warning) and suppress insertion of the value by using strict SQL mode. See Section 5.1.11, “Server SQL Modes”.
如果未启用严格的 SQL 模式,并且您为 CHAR 或 VARCHAR 列分配的值超过列的最大长度,则该值将被截断以适合并生成警告。对于非空格字符的截断,您可能会导致发生错误(而不是警告)并通过使用严格的 SQL 模式禁止插入值。请参阅第 5.1.11 节,“服务器 SQL 模式”。
For VARCHAR columns, trailing spaces in excess of the column length are truncated prior to insertion and a warning is generated, regardless of the SQL mode in use. For CHAR columns, truncation of excess trailing spaces from inserted values is performed silently regardless of the SQL mode.
对于 VARCHAR 列,超出列长度的尾随空格会在插入前被截断并生成警告,而不管使用的 SQL 模式如何。对于 CHAR 列,无论 SQL 模式如何,都会以静默方式截断插入值中多余的尾随空格。
VARCHAR values are not padded when they are stored. Trailing spaces are retained when values are stored and retrieved, in conformance with standard SQL.
VARCHAR 值在存储时不会被填充。根据标准 SQL,在存储和检索值时保留尾随空格。
The following table illustrates the differences between CHAR and VARCHAR by showing the result of storing various string values into CHAR(4) and VARCHAR(4) columns (assuming that the column uses a single-byte character set such as latin1).
下表通过显示将各种字符串值存储到 CHAR(4) 和 VARCHAR(4) 列(假设该列使用单字节字符集,如 latin1)的结果来说明 CHAR 和 VARCHAR 之间的区别。
Value( 值)CHAR(4) Storage Required( 存储要求)VARCHAR(4) Storage Required( 存储要求)‘’ ’ ’ 4 bytes( 字节)‘’ 1 bytes( 字节)‘ab’ 'ab ’ 4 bytes( 字节)‘ab’ 3 bytes( 字节)‘abcd’ ‘abcd’ 4 bytes( 字节)‘abcd’ 5 bytes( 字节)‘abcdefgh’ ‘abcd’ 4 bytes( 字节)‘abcd’ 5 bytes( 字节)The values shown as stored in the last row of the table apply only when not using strict SQL mode; if strict mode is enabled, values that exceed the column length are not stored, and an error results.
存储在表最后一行中的值仅在不使用严格 SQL 模式时适用;如果启用了严格模式,则不会存储超过列长度的值,并会导致错误。
InnoDB encodes fixed-length fields greater than or equal to 768 bytes in length as variable-length fields, which can be stored off-page. For example, a CHAR(255) column can exceed 768 bytes if the maximum byte length of the character set is greater than 3, as it is with utf8mb4.
InnoDB将长度大于或等于768字节的定长字段编码为变长字段,可以跨页存储。例如,如果字符集的最大字节长度大于 3,则 CHAR(255) 列可以超过 768 个字节,就像 utf8mb4 一样。
If a given value is stored into the CHAR(4) and VARCHAR(4) columns, the values retrieved from the columns are not always the same because trailing spaces are removed from CHAR columns upon retrieval. The following example illustrates this difference:
如果给定值存储在 CHAR(4) 和 VARCHAR(4) 列中,则从列中检索到的值并不总是相同,因为在检索时从 CHAR 列中删除了尾随空格。以下示例说明了这种差异:
mysql> CREATE TABLE vc (v VARCHAR(4), c CHAR(4));
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO vc VALUES (‘ab ‘, ‘ab ‘);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT CONCAT(’(’, v, ‘)’), CONCAT(’(’, c, ‘)’) FROM vc;
±--------------------±--------------------+
| CONCAT(‘(’, v, ‘)’) | CONCAT(‘(’, c, ‘)’) |
±--------------------±--------------------+
| (ab ) | (ab) |
±--------------------±--------------------+
1 row in set (0.06 sec)
Values in CHAR, VARCHAR, and TEXT columns are sorted and compared according to the character set collation assigned to the column.
CHAR、VARCHAR 和 TEXT 列中的值根据分配给该列的字符集排序规则进行排序和比较。
MySQL collations have a pad attribute of PAD SPACE, other than Unicode collations based on UCA 9.0.0 and higher, which have a pad attribute of NO PAD. (see Section 10.10.1, “Unicode Character Sets”).
MySQL 归类具有 PAD SPACE 的填充属性,而不是基于 UCA 9.0.0 及更高版本的 Unicode 归类具有 NO PAD 的填充属性。 (请参阅第 10.10.1 节,“Unicode 字符集”)。
To determine the pad attribute for a collation, use the INFORMATION_SCHEMA COLLATIONS table, which has a PAD_ATTRIBUTE column.
要确定排序规则的 pad 属性,请使用 INFORMATION_SCHEMA COLLATIONS 表,它有一个 PAD_ATTRIBUTE 列。
For nonbinary strings (CHAR, VARCHAR, and TEXT values), the string collation pad attribute determines treatment in comparisons of trailing spaces at the end of strings. NO PAD collations treat trailing spaces as significant in comparisons, like any other character. PAD SPACE collations treat trailing spaces as insignificant in comparisons; strings are compared without regard to trailing spaces. See Trailing Space Handling in Comparisons. The server SQL mode has no effect on comparison behavior with respect to trailing spaces.
对于非二进制字符串(CHAR、VARCHAR 和 TEXT 值),字符串归类垫属性确定比较字符串末尾尾随空格时的处理方式。与任何其他字符一样,NO PAD 排序规则在比较中将尾随空格视为重要字符。 PAD SPACE 排序规则在比较中将尾随空格视为无关紧要;比较字符串时不考虑尾随空格。请参阅比较中的尾随空格处理。服务器 SQL 模式对尾随空格的比较行为没有影响。
For those cases where trailing pad characters are stripped or comparisons ignore them, if a column has an index that requires unique values, inserting into the column values that differ only in number of trailing pad characters results in a duplicate-key error. For example, if a table contains ‘a’, an attempt to store 'a ’ causes a duplicate-key error.
对于尾随填充字符被删除或比较忽略它们的情况,如果列具有需要唯一值的索引,则将仅尾随填充字符数量不同的列值插入到列中会导致重复键错误。例如,如果表包含“a”,则尝试存储“a”会导致重复键错误。
下面的描述基于 InnoDB 存储引擎。CHAR 和 VARCHAR 类型相似,但存储和检索方式不同。它们在最大长度和是否保留尾随空格方面也不同。
2.4.3.1.1 CHAR 类型 - 说明
CHAR 类型有以下特点:
1、固定长度。
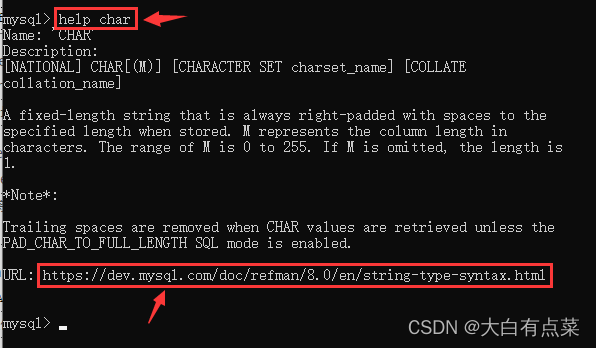
2、CHAR(M):M 代表设置的列的最大字符长度(即固定长度)。如果存储的字符实际长度小于设置的列的字符长度,不足的部分使用空格向右填充。M 的范围0 <= M <= 255,如果省略 M ,那么长度为 1。【出处】:https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html ,可以使用命令:help char查看。
3、除非启用PAD_CHAR_TO_FULL_LENGTHSQL 模式,否则在检索 CHAR 值时会删除尾随空格。【出处】:https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html ,可以使用命令:help char查看。
4、CHAR 适合存储非常短的字符串,或者适用于所有值的长度都几乎相同的情况。例如,用户密码的MD5。对于经常修改的数据,CHAR 也比 VARCHAR 更好,因为固定长度的行不容易出现碎片。对于非常短的列,CHAR 也比 VARCHAR 更高效。【出处】:《高性能MySQL 第4版》第 113 页。
5、CHAR(1) 在单字节字符集中只占 1 字节,但 VARCHAR(1) 需要 2 字节。字符串长度定义的不是字节数,而是字符数。多字节字符集可能需要多个字节来存储 1 个字符。【出处】:《高性能MySQL 第4版》第 113 页。
6、InnoDB将长度大于或等于768字节的定长字段编码为变长字段,可以跨页存储。如果字符集是 utf8mb4 ,那么最大字节长度(为 4 )大于 3,则 CHAR(255) 列可以超过 768 个字节。【出处】:https://dev.mysql.com/doc/refman/8.0/en/char.html
可以使用 help char 命令查看 CHAR 的语法。对应的官方文档网址:https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html
mysql> help char
要验证 CHAR 类型被检索时会删除尾随空格,我们新建一个表 tb1 ,字符集编码是 utf8mb4 ,字段 mychar ,类型设置为 char , 固定长度设置为 10 。新建表 tb1 如下:
CREATE TABLE `tb1` (
`id` bigint NOT NULL AUTO_INCREMENT,
`mychar` char(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
往表 tb1 中插入三条数据,第一条字符串不包含任何空格,第二条字符串前面包含2个空格,第三条字符串后面包含1个空格。SQL 语句如下:
insert into tb1(id,mychar) values(null,'没有空格');
insert into tb1(id,mychar) values(null,' 前面有2个空格');
insert into tb1(id,mychar) values(null,'后面有1个空格 ');
为了更方便看清楚空格,使用 CONCAT() 函数处理一下。检索 SQL 语句如下:
select concat("'", mychar, "'") from tb1;
tb1 表的检索结果:
mysql> select concat("'", mychar, "'") from tb1;
+--------------------------+
| concat("'", mychar, "'") |
+--------------------------+
| '没有空格' |
| ' 前面有2个空格' |
| '后面有1个空格' |
+--------------------------+
3 rows in set (0.00 sec)

从 tb1 表的检索结果可以看出,进行检索(select)时,空格在字符串前面的会保留,而在结尾的则被删除。
2.4.3.1.2 CHAR 类型 - 占用字节
下面内容说到的 CHAR 类型字节占用不包括索引记录字节占用,因为 InnoDB 引擎的 4 种行格式(REDUNDANT、COMPACT、DYNAMIC、COMPRESSED)对应的索引记录占用字节不一样,笔者我能力有限,很难准确地解释(其实是看不太懂^_^)某些值在有索引情况下的字节占用。读者如果有兴趣去探究 InnoDB 行格式,可移步:https://dev.mysql.com/doc/refman/8.0/en/innodb-row-format.html
在前面介绍 CHAR 类型特点有说到:多字节字符集可能需要多个字节来存储 1 个字符。是怎么理解这句话呢?如果字符集是单字节字符集,例如 latin1 字符集,M 值在合适范围内,CHAR(M) 中 M 的值设置为多少,那就占用 M+ 1 或 M + 2 字节。但是,如果是 Unicode 多字节字符集,例如 utf8mb4、utf8mb3、utf8(utf8mb3别名)、ucs2等编码,那就根据编码的不同而占用不同字节。字节占用请看第 2.4.3.1.4 小节的 Unicode 字符集一般特征 内容。
【MySQL 8.0 官方文档 - Unicode字符集】
https://dev.mysql.com/doc/refman/8.0/en/charset-unicode.html
2.4.3.1.3 什么是 BMP 字符
The Unicode Standard includes characters from the Basic Multilingual Plane (BMP) and supplementary characters that lie outside the BMP. This section describes support for Unicode in MySQL. For information about the Unicode Standard itself, visit the Unicode Consortium website.
Unicode 标准包括来自基本多文种平面 (BMP) 的字符和位于 BMP 之外的补充字符。本节介绍 MySQL 中对 Unicode 的支持。有关 Unicode 标准本身的信息,请访问 Unicode 联盟网站。
BMP characters have these characteristics:
BMP 字符具有以下特点:
- 1、Their code point values are between 0 and 65535 (or U+0000 and U+FFFF).
1、它们的代码点值介于 0 和 65535(或 U+0000 和 U+FFFF)之间。- 2、They can be encoded in a variable-length encoding using 8, 16, or 24 bits (1 to 3 bytes).
2、它们可以使用 8、16 或 24 位(1 到 3 个字节)以可变长度编码进行编码。- 3、They can be encoded in a fixed-length encoding using 16 bits (2 bytes).
3、它们可以使用 16 位(2 字节)以固定长度编码进行编码。- 4、They are sufficient for almost all characters in major languages.
4、对于主要语言中的几乎所有字符,它们都足够了。
Supplementary characters lie outside the BMP:
补充字符位于 BMP 之外:
- 1、Their code point values are between U+10000 and U+10FFFF).
1、它们的代码点值介于 U+10000 和 U+10FFFF 之间)。- 2、Unicode support for supplementary characters requires character sets that have a range outside BMP characters and therefore take more space than BMP characters (up to 4 bytes per character).
2、Unicode 对增补字符的支持要求字符集的范围在 BMP 字符之外,因此比 BMP 字符占用更多空间(每个字符最多 4 个字节)。
维基百科关于BMP的介绍:Unicode字符平面映射
https://zh.wikipedia.org/zh-hans/Unicode%E5%AD%97%E7%AC%A6%E5%B9%B3%E9%9D%A2%E6%98%A0%E5%B0%84
2.4.3.1.4 Unicode 字符集一般特征
| Unicode字符集编码 | 支持的字符1 | 每个字符占用字节(byte)1 | 支持的字符2 | 每个字符占用字节(byte)2 | 支持的字符3 | 每个字符占用字节(byte)3 |
|---|---|---|---|---|---|---|
utf8mb3, utf8 (已弃用,utf8mb3别名,有望未来成为utf8mb4别名) |
仅 BMP。拉丁字母、数字和标点符号 | 1 | 仅 BMP。扩展拉丁字母(带有波浪号、长音符、锐音符、重音符和其他重音符号)、西里尔字母、希腊字母、亚美尼亚字母、希伯来字母、阿拉伯字母、叙利亚字母等 | 2 | 仅 BMP。韩文、中文和日文表意文字 | 3 |
| ucs2(MySQL 8.0.28弃用) | 仅 BMP。 | 2 | - | - | - | - |
utf8mb4 |
BMP和补充。拉丁字母、数字和标点符号 | 1 | BMP和补充。扩展拉丁字母(带有波浪号、长音符、锐音符、重音符和其他重音符号)、西里尔字母、希腊字母、亚美尼亚字母、希伯来字母、阿拉伯字母、叙利亚字母等 | 2 | BMP和补充。韩文、中文和日文表意文字 | 3 或 4 |
| utf16 | BMP和补充。 | 2 或 4 | - | - | - | - |
| utf16le | BMP和补充。 | 2 或 4 | - | - | - | - |
| utf32 | BMP和补充。 | 4 | - | - | - | - |
从Unicode 字符集一般特征表格中,笔者无法确定Unicode字符集编码是 utf8mb4 ,字符是 韩文、中文和日文表意文字 情况下,每个字符占用的字节到底是 3 还是 4 bytes,官方文档并没有详细地说明具体的字节占用。在 information_schema 数据库的 CHARACTER_SETS 表中字符集名称(CHARACTER_SET_NAME)为 utf8mb4 的最大字节(MAXLEN)是 4 。
select CHARACTER_SET_NAME, MAXLEN from information_schema.CHARACTER_SETS where CHARACTER_SET_NAME='utf8mb4';

《阿里巴巴Java开发手册》中,MySQL数据库 - 建表规约 章节说到:【强制】如果存储的字符串长度几乎相等,则使用 char 定长字符串类型。
2.4.3.1.5 TINYINT(1) 、CHAR(1) 和 VARCHAR(1) 哪个更优?
前面说到整数类型 TINYINT 的时候,抛出了一个问题: TINYINT(1) 、CHAR(1) 和 VARCHAR(1) 哪个更优?针对这个问题,笔者也查阅不少资料,官方文档暂时找不到(能力有限)相关的问题解释,去验证它们之间的优劣的国内的博客非常少(有是有,但看起来不太可靠)。在国外的 Stack Overflow 倒是找到一个还算可靠的答案,笔者不确定那个答案是否具有权威性,不确定那个网友是否是MySQL官方相关的人员。可以肯定的是,VARCHAR(1) 性能是最差的,要占用 2 个字节,CHAR(1) 和TINYINT(1) 都只占用 1 个字节。
在 Stack Overflow 上问题是这样的:Which is faster: char(1) or tinyint(1) ? Why? 意思是 CHAR(1) 相比 TINYINT(1) 哪个更快。有个网友(Glen Solsberry)给出了一个测试结果,有关 CHAR(1) 、TINYINT(1) 和 ENUM(‘y’,‘n’) 三者之间的插入速率、查询速率比较,同时给出了测试代码,可以在 github 下载:https://github.com/gms8994/benchmark/blob/master/mysql/char_vs_tinyint.pl 。测试结果(插入速率、查询速率)如截图所示:


从测试结果中看出(不太严谨的结果,主要是测试次数不多),CHAR(1) 的插入速率时而比 TINYINT(1) 高,时而比 TINYINT(1) 低,不太好判断插入速率哪个更优。但 CHAR(1) 的查询速率整体是比 TINYINT(1) 低的。计算机处理数字的效率优于字符的处理效率,那么 TINYINT(1) 的性能应该是比 CHAR(1) 要优,VARCHAR(1) 最差。
2.4.3.1.6 VARCHAR 类型 - 说明
VARCHAR 类型有以下特点:
1、可变长度。
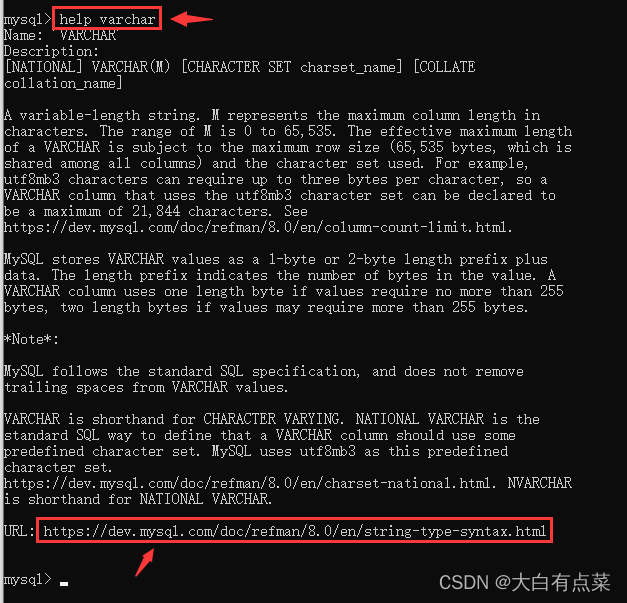
2、VARCHAR(M):M 表示以字符为单位的最大列长度。M 的范围0 <= M <= 65535。VARCHAR 的有效最大长度取决于最大行大小(65,535 字节,由所有列共享)和使用的字符集。【出处】:https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html ,可以使用命令:help varchar查看。
3、VARCHAR 值在存储时不会被填充。根据标准 SQL,在存储和检索值时保留尾随空格。【出处】:https://dev.mysql.com/doc/refman/8.0/en/char.html ,可以使用命令:help varchar查看。
4、MySQL 将 VARCHAR 值存储为 1 字节或 2 字节长度的前缀加上数据。长度前缀指示值中的字节数。如果值需要不超过 255 个字节,则 VARCHAR 列使用一个长度字节,如果值可能需要超过 255 个字节,则使用两个长度字节。【出处】:https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html
5、使用 VARCHAR 合适的情况:字符串列的最大长度远大于平均长度;列的更新很少,所以碎片不是问题;使用了像 UTF-8 这样复杂的字符集,每个字符都使用了不同的字节数进行存储。【出处】:《高性能MySQL 第4版》第 112 页。
《阿里巴巴Java开发手册》中,MySQL数据库 - 建表规约 章节说到:【强制】varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000 个字符,如果存储长度大于此值,则应定义字段类型为 text ,单独出来一张表,用主键来对应,避免影响其他字段的索引效率。
可以使用 help varchar 命令查看 VARCHAR 的语法。对应的官方文档网址:https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html
mysql> help varchar
故技重施,要验证 VARCHAR 类型被检索时不会删除尾随空格,我们新建一个表 tb2 ,字符集编码是 utf8mb4 ,字段 myvarchar ,类型设置为 varchar ,字符长度设置为 32 。新建表 tb2 如下:
CREATE TABLE `tb2` (
`id` bigint NOT NULL AUTO_INCREMENT,
`myvarchar` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
往表 tb2 中插入三条数据,第一条字符串不包含任何空格,第二条字符串前面包含2个空格,第三条字符串后面包含1个空格。SQL 语句如下:
insert into tb2(id, myvarchar) values(null,'没有空格');
insert into tb2(id, myvarchar) values(null,' 前面有2个空格');
insert into tb2(id, myvarchar) values(null,'后面有1个空格 ');
为了更方便看清楚空格,使用 CONCAT() 函数处理一下。检索 SQL 语句如下:
select concat("'", myvarchar, "'") from tb2;
tb2 表的检索结果:
mysql> select concat("'", myvarchar, "'") from tb2;
+-----------------------------+
| concat("'", myvarchar, "'") |
+-----------------------------+
| '没有空格' |
| ' 前面有2个空格' |
| '后面有1个空格 ' |
+-----------------------------+
3 rows in set (0.00 sec)

从 tb2 表的检索结果可以看出,进行检索(select)时,空格在字符串前面的会保留,在结尾的也不会被删除。
2.4.3.1.7 VARCHAR 类型 - 占用字节
在说明 VARCHAR 类型字节占用前,首先要知道一个极其非常十分重要的概念:InnoDB 存储引擎在内部支持大于 65535 字节的行大小,但 MySQL 本身对所有列的组合大小施加了 65535 的行大小限制。【出处】:https://dev.mysql.com/doc/refman/8.0/en/innodb-limits.html 。
原文:Although InnoDB supports row sizes larger than 65,535 bytes internally, MySQL itself imposes a row-size limit of 65,535 for the combined size of all columns. See Section 8.4.7, “Limits on Table Column Count and Row Size”.
谷歌翻译:尽管 InnoDB 在内部支持大于 65,535 字节的行大小,但 MySQL 本身对所有列的组合大小施加了 65,535 的行大小限制。请参阅第 8.4.7 节,“表列数和行大小的限制”。
为什么说这个概念很重要呢?因为,VARCHAR(M) 中的 M 值能设置多大,就与这个最大行大小 65535 字节和字符集有关,并不是我们想得那么简单。官方文档提到 M 的范围为 0 <= M <= 65535 ,实际上,M 的值是不可能达到最大 65535 的,后面会做详细的解释。
在 VARCHAR 类型中,字节占用分以下情况:
1、如果列的最大长度字节(用符号 L 表示)小于或等于 255 字节,即 0 <= L <= 255 bytes ,会额外使用
1 个字节记录字符串的长度。即L + 1 字节。
2、如果列的最大长度字节(用符号 L 表示)大于 255 字节,即 256 <= L <= 65533 bytes ,会额外使用2 个字节记录字符串的长度。即L + 2 字节。为什么是 65533 而不是 65535 呢?如果是 65535 ,那么 65535 + 2 = 65537 字节,那就超出了最大行大小(65535)的限制了。
3、【注意】:此处的 L 和 VARCHAR(M) 中的 M 不是一个概念,L 是列的最大长度字节,M 是字符数。
官方文档(https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html)关于字符串类型存储要求的描述中,也提到 VARCHAR 的存储要求。如图所示:

一个列为 VARCHAR 类型的实际占用字节(不包含索引记录,假设字符类型是一样的,不同的字符类型占用字节不一样,N 个字符可能是由不同字符类型组成,那么占用字节就会出现无数种组合):
| 字符集 | 实际字符长度 | 列是否为 NOT NULL | 列是否为 NULL | M 值范围 | 实际字节占用(bytes) |
|---|---|---|---|---|---|
| latin1 字符集 | a | 是 | - | 0 <= M <= 255 | a |
| latin1 字符集 | b | 是 | - | 256 <= M <= 65535 | b + 2 |
| latin1 字符集 | c | - | 是 | 0 <= M <= 255 | c + 1 |
| latin1 字符集 | d | - | 是 | 256 <= M <= 65535 | d + 2 + 1 |
| utf8mb3 字符集 | e | 是 | - | 0 <= M <= 255 | e * 1 或 e * 2 或 e * 3 |
| utf8mb3 字符集 | f | 是 | - | 256 <= M <= 65535 | f * 1 + 2 或 f * 2 + 2 或 f * 3 + 2 |
| utf8mb3 字符集 | g | - | 是 | 0 <= M <= 255 | g * 1 + 1 或 g * 2 + 1 或 g * 3 + 1 |
| utf8mb3 字符集 | h | - | 是 | 256 <= M <= 65535 | h * 1 + 2 + 1 或 h * 2 + 2 + 1 或 h * 3 + 2 + 1 |
| utf8mb4 字符集 | i | 是 | - | 0 <= M <= 255 | i * 1 或 i * 2 或 i * 3 或 i * 4 |
| utf8mb4 字符集 | j | 是 | - | 256 <= M <= 65535 | j * 1 + 2 或 j * 2 + 2 或 j * 3 + 2 或 j * 4 + 2 |
| utf8mb4 字符集 | k | - | 是 | 0 <= M <= 255 | k * 1 + 1 或 k * 2 + 1 或 k * 3 + 1 或 k * 4 + 1 |
| utf8mb4 字符集 | l | - | 是 | 256 <= M <= 65535 | l * 1 + 2 + 1 或 l * 2 + 2 + 1 或 l * 3 + 2 + 1 或 l * 4 + 2 + 1 |
2.4.3.1.8 VARCHAR 类型 - VARCHAR(M) 的 M 能设置多大的值,能设置最大为 65535 吗?
如果按照官方文档所说的,我们可能理所当然地认为 VARCHAR(M) 中 M 的值最大能设置为 65535 ,事实真的是这样吗?先说结论(基于 InnoDB 存储引擎,且列不包含索引)再去验证。下面的计算结果近似值都舍去小数部分,不进行四舍五入处理,官方并没有提到计算过程,只是笔者认为是这样运算的,可能存在错误,读者自行斟酌。减去数字 2 是笔者假设至少存在一个 VARCHAR 类型的字段情况下,那么 M 值已经超过 255 ,占用两个字节,减去 1 则是字段允许为 NULL ,占用一个字节。多字节字符集以一个字符占用最大字节去处理,例如 utf8mb3 编码的字符最大字节为 3 bytes, utf8mb4 编码的字符最大字节为 4 bytes。
【1】字符集为 latin1
1.1、如果字符集是 latin1,表只有一个字段,类型是 VARCHAR ,而且为
NOT NULL,那么最大字符长度(M 值):65535 - 2 = 65533。
【验证1.1】 str1 字段的字符集为 latin1,类型为 VARCHAR ,非 NULL,如果最大字符长度(M 值)超过 65533,则会报错。
CREATE TABLE `tb1` (
`str1` varchar(65533) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;

1.2、如果字符集是 latin1,表只有一个字段,类型是 VARCHAR ,而且允许为
NULL,那么最大字符长度(M 值):65535 - 2 - 1 = 65532。列为 NULL 占 1 个字节。
【验证1.2】 str1 字段的字符集为 latin1,类型为 VARCHAR ,允许 NULL,如果最大字符长度(M 值)超过 65532,则会报错。
CREATE TABLE `tb2` (
`str1` varchar(65532) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;

1.3、如果字符集是 latin1,表有两个字段,一个类型是 INT,为自增主键,另一个类型是 VARCHAR ,而且为
NOT NULL,那么最大字符长度(M 值):65535 - 4 - 2 = 65529。
【验证1.3】 id 字段为 INT 类型,自增主键;str1 字段的字符集为 latin1,类型为 VARCHAR ,非 NULL,如果最大字符长度(M 值)超过 65529,则会报错。
CREATE TABLE `tb3` (
`id` int NOT NULL AUTO_INCREMENT,
`str1` varchar(65529) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;

1.4、如果字符集是 latin1,表有两个字段,一个类型是 BIGINT,为自增主键,另一个类型是 VARCHAR ,而且允许为
NULL,那么最大字符长度(M 值):65535 - 8 - 2 - 1 = 65524。列为 NULL 占 1 个字节。
【验证1.4】 id 字段为 BIGINT 类型,自增主键;str1 字段的字符集为 latin1,类型为 VARCHAR ,允许 NULL,如果最大字符长度(M 值)超过 65524,则会报错。
CREATE TABLE `tb4` (
`id` bigint NOT NULL AUTO_INCREMENT,
`str1` varchar(65524) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;

1.5、如果字符集是 latin1,表有 n 个字段,m 个字段属于非 VARCHAR 类型,分三种情况:
1.5-1
VARCHAR 类型字段和非 VARCHAR 类型字段都为 NOT NULL,所有 VARCHAR 类型占用的总字节:65535 - m个非VARCHAR类型字段的总字节 - (n-m) * 2。例如,假设表 tb5 有 6 个字段,其中 2 个字段是 INT 类型,2 个 INT 类型字段总字节为 8 bytes,那么所有 VARCHAR 类型占用的总字节为:65535 - 8 - (6 - 2) * 2 = 65519 bytes。计算 65519 ÷ 4 ≈ 16379.75,那 4 个 VARCHAR 类型字段可以设置最大字符长度(M 值)分别为(假设均分):16380、16380、16380、16379。同时反过来,16380 + 16380 + 16380 + 16379 = 65519 是成立的。
【验证1.5-1】 str1、str2、str3、str4 字段的字符集都为 latin1,类型都为 VARCHAR ,都为 NOT NULL;num1 和 num2 都为 INT 类型,都为 NOT NULL。如果 4 个字符串字段设置的字符长度总字节超过 65519 bytes,则会报错。
CREATE TABLE `tb5` (
`str1` varchar(16380) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL,
`str2` varchar(16380) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL,
`str3` varchar(16380) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL,
`str4` varchar(16379) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL,
`num1` int NOT NULL,
`num2` int NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;

1.5-2
VARCHAR 类型字段和非 VARCHAR 类型字段都为 NULL,所有 VARCHAR 类型占用的总字节:65535 - m个非VARCHAR类型字段的总字节 - (n-m) * 2 - 1。列为 NULL 占 1 个字节。例如,假设表 tb6 有 6 个字段,其中 2 个字段是 INT 类型,2 个 INT 类型字段总字节为 8 bytes,那么所有 VARCHAR 类型占用的总字节为:65535 - 8 - (6 - 2) * 2 - 1 = 65518 bytes。计算 65518 ÷ 4 ≈ 16379.5,那 4 个 VARCHAR 类型字段可以设置最大字符长度(M 值)分别为(假设均分):16380、16380、16379、16379。同时反过来,16380 + 16380 + 16379 + 16379 = 65518 是成立的。
【验证1.5-2】 str1、str2、str3、str4 字段的字符集都为 latin1,类型都为 VARCHAR ,都为 NULL;num1 和 num2 都为 INT 类型,都为 NULL。如果 4 个字符串字段设置的字符长度总字节超过 65518 bytes,则会报错。
CREATE TABLE `tb6` (
`str1` varchar(16380) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL,
`str2` varchar(16380) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL,
`str3` varchar(16379) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL,
`str4` varchar(16379) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL,
`num1` int DEFAULT NULL,
`num2` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;

1.5-3
任意一个 VARCHAR 类型字段或非 VARCHAR 类型字段为 NULL,所有 VARCHAR 类型占用的总字节:65535 - m个非VARCHAR类型字段的总字节 - (n-m) * 2 - 1。无论有多少个列,只要满足任意一列为 NULL ,都只占 1 个字节。例如,假设表 tb7 有 6 个字段,其中 2 个字段是 INT 类型,2 个 INT 类型字段总字节为 8 bytes,任意一个 VARCHAR 类型字段或 INT 类型字段为 NULL ,那么所有 VARCHAR 类型占用的总字节为:65535 - 8 - (6 - 2) * 2 - 1 = 65518 bytes。计算 65518 ÷ 4 ≈ 16379.5,那 4 个 VARCHAR 类型字段可以设置最大字符长度(M 值)分别为(假设均分):16380、16380、16379、16379。同时反过来,16380 + 16380 + 16379 + 16379 = 65518 是成立的。
【验证1.5-3】 str1、str2、str3、str4 字段的字符集都为 latin1,类型都为 VARCHAR ,任意一个为 NULL ,其它为 NOT NULL;num1 和 num2 都为 INT 类型,任意一个为 NULL ,另外一个为 NOT NULL ;至少有一个字段为 NULL 。如果 4 个字符串字段设置的字符长度总字节超过 65518 bytes,则会报错。
CREATE TABLE `tb7` (
`str1` varchar(16380) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL,
`str2` varchar(16380) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL,
`str3` varchar(16379) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL,
`str4` varchar(16379) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL,
`num1` int DEFAULT NULL,
`num2` int NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
【2】字符集为 utf8mb3
2.1、如果字符集是 utf8mb3,表只有一个字段,类型是 VARCHAR ,而且为
NOT NULL,那么最大字符长度(M 值):(65535 - 2) ÷ 3 = 21844。
【验证2.1】 str1 字段的字符集为 utf8mb3,类型为 VARCHAR ,非 NULL,如果最大字符长度(M 值)超过 21844,则会报错。
CREATE TABLE `tb1` (
`str1` varchar(21844) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;

2.2、如果字符集是 utf8mb3,表只有一个字段,类型是 VARCHAR ,而且允许为
NULL,那么最大字符长度(M 值):(65535 - 2 - 1) ÷ 3 = 21844。列为 NULL 占 1 个字节。
【验证2.2】 str1 字段的字符集为 utf8mb3,类型为 VARCHAR ,允许 NULL,如果最大字符长度(M 值)超过 21844,则会报错。
CREATE TABLE `tb2` (
`str1` varchar(21844) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;

2.3、如果字符集是 utf8mb3,表有两个字段,一个类型是 INT,为自增主键,另一个类型是 VARCHAR ,而且为
NOT NULL,那么最大字符长度(M 值):(65535 - 4 - 2) ÷ 3 = 21843。
【验证2.3】 id 字段为 INT 类型,自增主键;str1 字段的字符集为 utf8mb3,类型为 VARCHAR ,非 NULL,如果最大字符长度(M 值)超过 21843,则会报错。
CREATE TABLE `tb3` (
`id` int NOT NULL AUTO_INCREMENT,
`str1` varchar(21843) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;

2.4、如果字符集是 utf8mb3,表有两个字段,一个类型是 BIGINT,为自增主键,另一个类型是 VARCHAR ,而且允许为
NULL,那么最大字符长度(M 值):(65535 - 8 - 2 - 1) ÷ 3 = 21841。列为 NULL 占 1 个字节。
【验证2.4】 id 字段为 BIGINT 类型,自增主键;str1 字段的字符集为 utf8mb3,类型为 VARCHAR ,允许 NULL,如果最大字符长度(M 值)超过 21841,则会报错。
CREATE TABLE `tb4` (
`id` bigint NOT NULL AUTO_INCREMENT,
`str1` varchar(21841) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;

2.5、如果字符集是 utf8mb3,表有 n 个字段,m 个字段属于非 VARCHAR 类型,分三种情况:
2.5-1
VARCHAR 类型字段和非 VARCHAR 类型字段都为 NOT NULL,所有 VARCHAR 类型占用的总字节:65535 - m个非VARCHAR类型字段的总字节 - (n-m) * 2。例如,假设表 tb5 有 6 个字段,其中 2 个字段是 INT 类型,2 个 INT 类型字段总字节为 8 bytes,那么所有 VARCHAR 类型占用的总字节为:65535 - 8 - (6 - 2) * 2 = 65519 bytes。计算 65519 ÷ 4 ÷ 3 ≈ 5459.92,那 4 个 VARCHAR 类型字段可以设置最大字符长度(M 值)分别为(假设均分):5460、5460、5460、5459。同时反过来,5460 * 3 + 5460 * 3 + 5460 * 3 + 5459 * 3 = 65517 < 65519 是成立的。
【验证2.5-1】 str1、str2、str3、str4 字段的字符集都为 utf8mb3,类型都为 VARCHAR ,都为 NOT NULL;num1 和 num2 都为 INT 类型,都为 NOT NULL。如果 4 个字符串字段设置的字符长度总字节超过 65519 bytes,则会报错。
CREATE TABLE `tb5` (
`str1` varchar(5460) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`str2` varchar(5460) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`str3` varchar(5460) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`str4` varchar(5459) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`num1` int NOT NULL,
`num2` int NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;

2.5-2
VARCHAR 类型字段和非 VARCHAR 类型字段都为 NULL,所有 VARCHAR 类型占用的总字节:65535 - m个非VARCHAR类型字段的总字节 - (n-m) * 2 - 1。列为 NULL 占 1 个字节。例如,假设表 tb6 有 6 个字段,其中 2 个字段是 INT 类型,2 个 INT 类型字段总字节为 8 bytes,那么所有 VARCHAR 类型占用的总字节为:65535 - 8 - (6 - 2) * 2 - 1 = 65518 bytes。计算 65518 ÷ 4 ÷ 3 ≈ 5459.83,那 4 个 VARCHAR 类型字段可以设置最大字符长度(M 值)分别为(假设均分):5460、5460、5460、5459。同时反过来,5460 * 3 + 5460 * 3 + 5460 * 3 + 5459 * 3 = 65517 < 65518 是成立的。
【验证2.5-2】 str1、str2、str3、str4 字段的字符集都为 utf8mb3,类型都为 VARCHAR ,都为 NULL;num1 和 num2 都为 INT 类型,都为 NULL。如果 4 个字符串字段设置的字符长度总字节超过 65518 bytes,则会报错。
CREATE TABLE `tb6` (
`str1` varchar(5460) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci DEFAULT NULL,
`str2` varchar(5460) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci DEFAULT NULL,
`str3` varchar(5460) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci DEFAULT NULL,
`str4` varchar(5459) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci DEFAULT NULL,
`num1` int DEFAULT NULL,
`num2` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
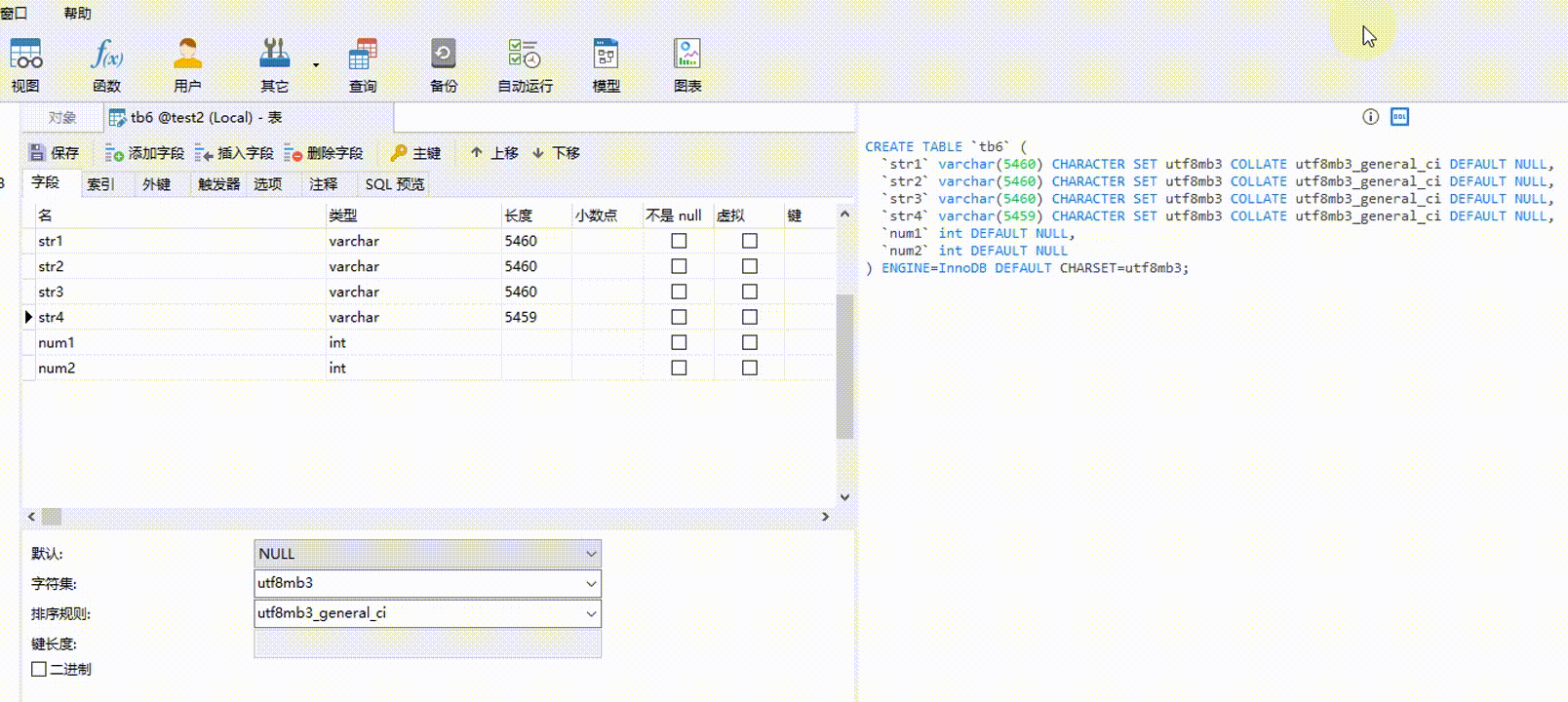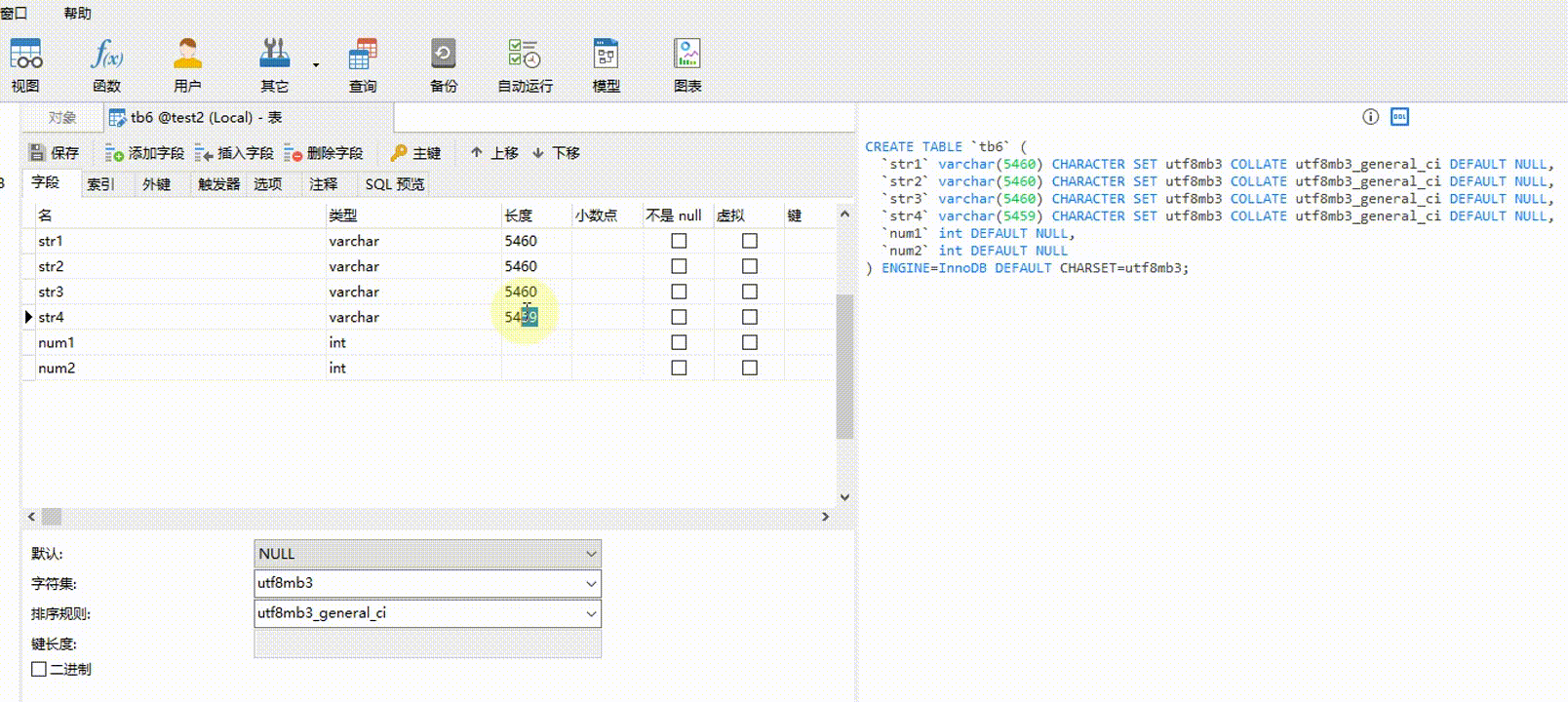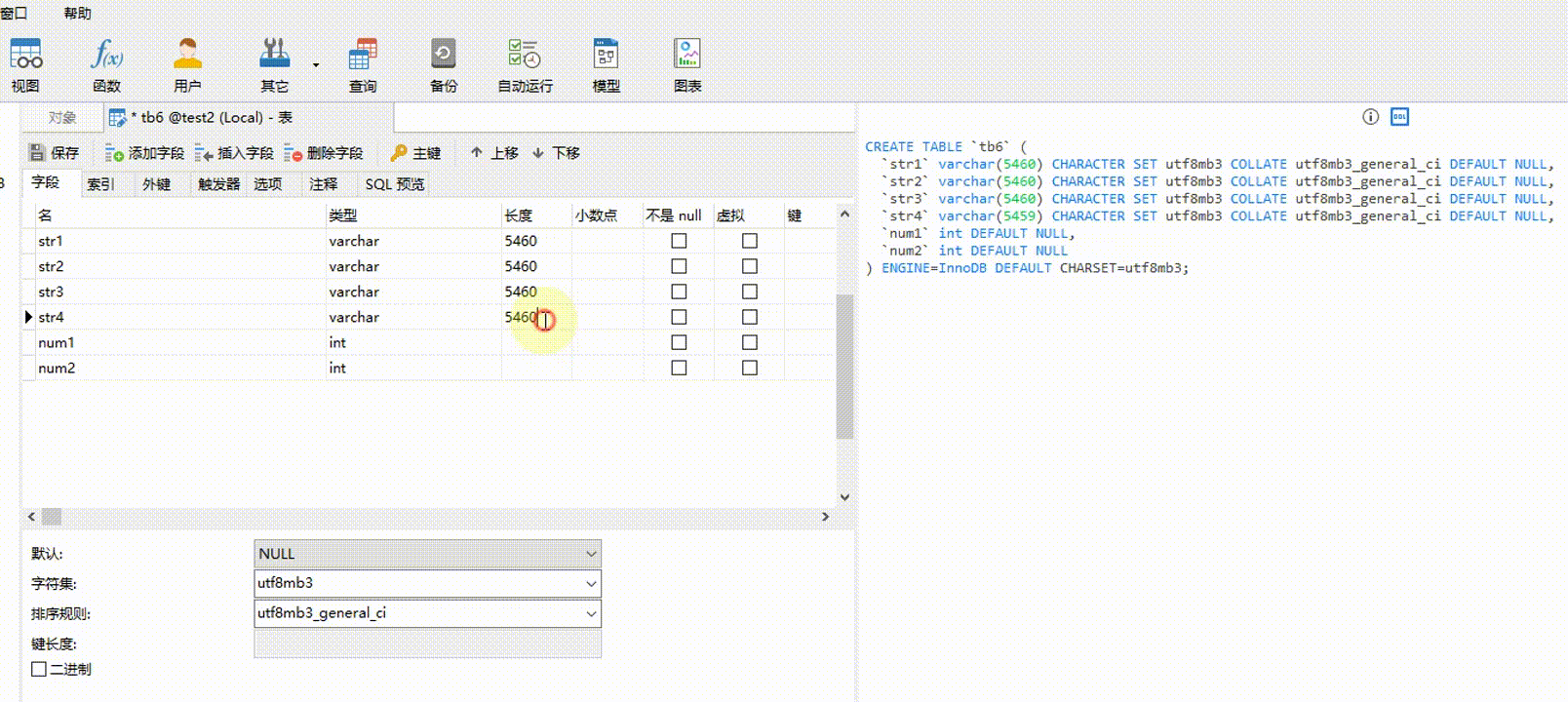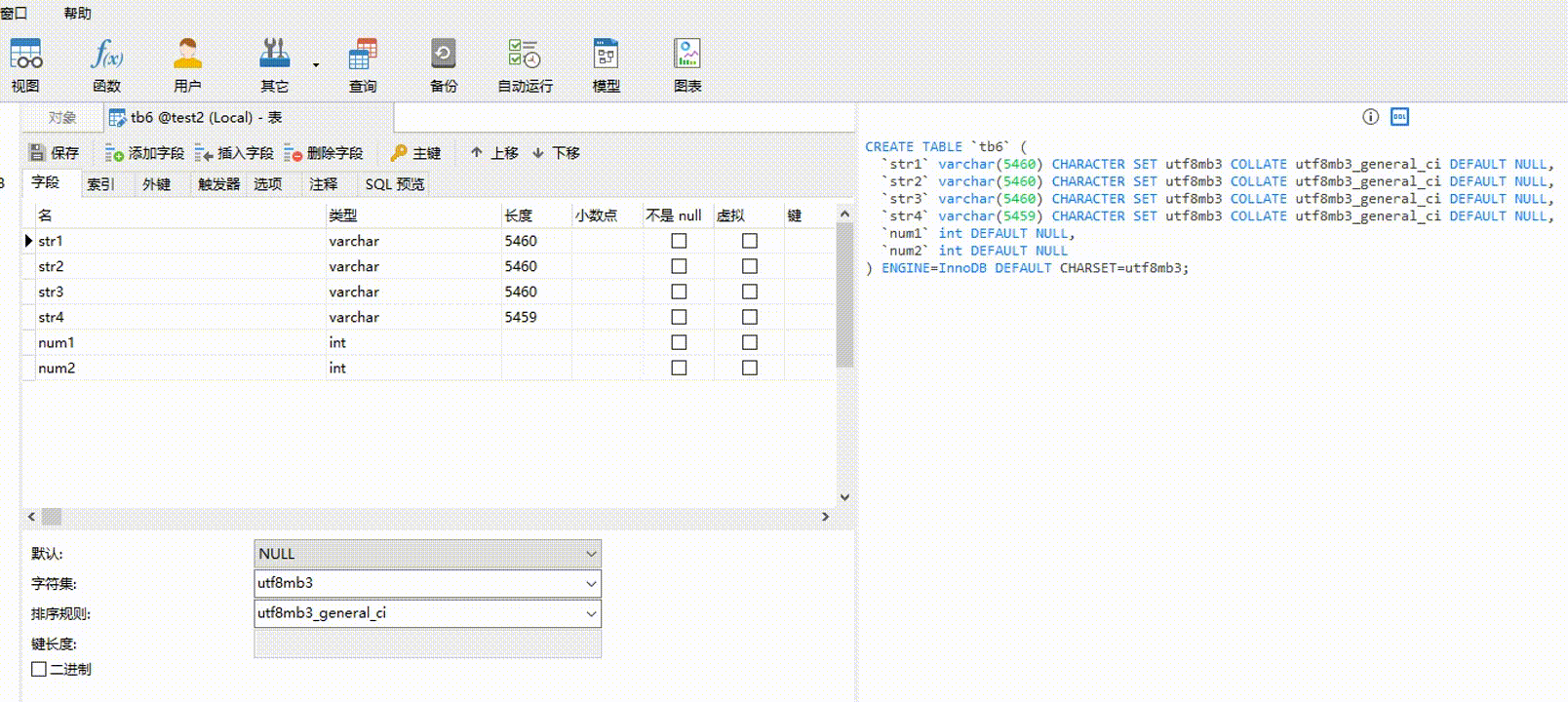
2.5-3
任意一个 VARCHAR 类型字段或非 VARCHAR 类型字段为 NULL,所有 VARCHAR 类型占用的总字节:65535 - m个非VARCHAR类型字段的总字节 - (n-m) * 2 - 1。无论有多少个列,只要满足任意一列为 NULL ,都只占 1 个字节。例如,假设表 tb7 有 6 个字段,其中 2 个字段是 INT 类型,2 个 INT 类型字段总字节为 8 bytes,任意一个 VARCHAR 类型字段或 INT 类型字段为 NULL ,那么所有 VARCHAR 类型占用的总字节为:65535 - 8 - (6 - 2) * 2 - 1 = 65518 bytes。计算 65518 ÷ 4 ÷ 3 ≈ 5459.83,那 4 个 VARCHAR 类型字段可以设置最大字符长度(M 值)分别为(假设均分):5460、5460、5460、5459。同时反过来,5460 * 3 + 5460 * 3 + 5460 * 3 + 5459 * 3 = 65517 < 65518 是成立的。
【验证2.5-3】 str1、str2、str3、str4 字段的字符集都为 utf8mb3,类型都为 VARCHAR ,任意一个为 NULL ,其它为 NOT NULL;num1 和 num2 都为 INT 类型,任意一个为 NULL ,另外一个为 NOT NULL ;至少有一个字段为 NULL 。如果 4 个字符串字段设置的字符长度总字节超过 65518 bytes,则会报错。
CREATE TABLE `tb7` (
`str1` varchar(5460) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`str2` varchar(5460) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`str3` varchar(5460) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`str4` varchar(5459) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci DEFAULT NULL,
`num1` int NOT NULL,
`num2` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;

【3】字符集为 utf8mb4
3.1、如果字符集是 utf8mb4,表只有一个字段,类型是 VARCHAR ,而且为
NOT NULL,那么最大字符长度(M 值):(65535 - 2) ÷ 4 = 16383。
【验证3.1】 str1 字段的字符集为 utf8mb4,类型为 VARCHAR ,非 NULL,如果最大字符长度(M 值)超过 16383,则会报错。
CREATE TABLE `tb1` (
`str1` varchar(16383) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

3.2、如果字符集是 utf8mb4,表只有一个字段,类型是 VARCHAR ,而且允许为
NULL,那么最大字符长度(M 值):(65535 - 2 - 1) ÷ 4 = 16383。列为 NULL 占 1 个字节。
【验证3.2】 str1 字段的字符集为 utf8mb4,类型为 VARCHAR ,允许 NULL,如果最大字符长度(M 值)超过 16383,则会报错。
CREATE TABLE `tb2` (
`str1` varchar(16383) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

3.3、如果字符集是 utf8mb4,表有两个字段,一个类型是 INT,为自增主键,另一个类型是 VARCHAR ,而且为
NOT NULL,那么最大字符长度(M 值):(65535 - 4 - 2) ÷ 4 = 16382。
【验证3.3】 id 字段为 INT 类型,自增主键;str1 字段的字符集为 utf8mb4,类型为 VARCHAR ,非 NULL,如果最大字符长度(M 值)超过 16382,则会报错。
CREATE TABLE `tb3` (
`id` int NOT NULL AUTO_INCREMENT,
`str1` varchar(16382) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

3.4、如果字符集是 utf8mb4,表有两个字段,一个类型是 BIGINT,为自增主键,另一个类型是 VARCHAR ,而且允许为
NULL,那么最大字符长度(M 值):(65535 - 8 - 2 - 1) ÷ 4 = 16381。列为 NULL 占 1 个字节。
【验证3.4】 id 字段为 BIGINT 类型,自增主键;str1 字段的字符集为 utf8mb4,类型为 VARCHAR ,允许 NULL,如果最大字符长度(M 值)超过 16381,则会报错。
CREATE TABLE `tb4` (
`id` bigint NOT NULL AUTO_INCREMENT,
`str1` varchar(16381) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

3.5、如果字符集是 utf8mb3,表有 n 个字段,m 个字段属于非 VARCHAR 类型,分三种情况:
3.5-1
VARCHAR 类型字段和非 VARCHAR 类型字段都为 NOT NULL,所有 VARCHAR 类型占用的总字节:65535 - m个非VARCHAR类型字段的总字节 - (n-m) * 2。例如,假设表 tb5 有 6 个字段,其中 2 个字段是 INT 类型,2 个 INT 类型字段总字节为 8 bytes,那么所有 VARCHAR 类型占用的总字节为:65535 - 8 - (6 - 2) * 2 = 65519 bytes。计算 65519 ÷ 4 ÷ 4 ≈ 4094.94,那 4 个 VARCHAR 类型字段可以设置最大字符长度(M 值)分别为(假设均分):4095、4095、4095、4094。同时反过来,4095 * 4 + 4095 * 4 + 4095 * 4 + 4094 * 4 = 65516 < 65519 是成立的。
【验证3.5-1】 str1、str2、str3、str4 字段的字符集都为 utf8mb4,类型都为 VARCHAR ,都为 NOT NULL;num1 和 num2 都为 INT 类型,都为 NOT NULL。如果 4 个字符串字段设置的字符长度总字节超过 65519 bytes,则会报错。
CREATE TABLE `tb5` (
`str1` varchar(4095) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`str2` varchar(4095) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`str3` varchar(4095) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`str4` varchar(4094) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`num1` int NOT NULL,
`num2` int NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

3.5-2
VARCHAR 类型字段和非 VARCHAR 类型字段都为 NULL,所有 VARCHAR 类型占用的总字节:65535 - m个非VARCHAR类型字段的总字节 - (n-m) * 2 - 1。列为 NULL 占 1 个字节。例如,假设表 tb6 有 6 个字段,其中 2 个字段是 INT 类型,2 个 INT 类型字段总字节为 8 bytes,那么所有 VARCHAR 类型占用的总字节为:65535 - 8 - (6 - 2) * 2 - 1 = 65518 bytes。计算 65518 ÷ 4 ÷ 4 ≈ 4094.88,那 4 个 VARCHAR 类型字段可以设置最大字符长度(M 值)分别为(假设均分):4095、4095、4095、4094。同时反过来,4095 * 4 + 4095 * 4 + 4095 * 4 + 4094 * 4 = 65516 < 65518 是成立的。
【验证3.5-2】 str1、str2、str3、str4 字段的字符集都为 utf8mb4,类型都为 VARCHAR ,都为 NULL;num1 和 num2 都为 INT 类型,都为 NULL。如果 4 个字符串字段设置的字符长度总字节超过 65518 bytes,则会报错。
CREATE TABLE `tb6` (
`str1` varchar(4095) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`str2` varchar(4095) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`str3` varchar(4095) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`str4` varchar(4094) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`num1` int DEFAULT NULL,
`num2` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

3.5-3
任意一个 VARCHAR 类型字段或非 VARCHAR 类型字段为 NULL,所有 VARCHAR 类型占用的总字节:65535 - m个非VARCHAR类型字段的总字节 - (n-m) * 2 - 1。无论有多少个列,只要满足任意一列为 NULL ,都只占 1 个字节。例如,假设表 tb7 有 6 个字段,其中 2 个字段是 INT 类型,2 个 INT 类型字段总字节为 8 bytes,任意一个 VARCHAR 类型字段或 INT 类型字段为 NULL ,那么所有 VARCHAR 类型占用的总字节为:65535 - 8 - (6 - 2) * 2 - 1 = 65518 bytes。计算 65518 ÷ 4 ÷ 4 ≈ 4094.88,那 4 个 VARCHAR 类型字段可以设置最大字符长度(M 值)分别为(假设均分):4095、4095、4095、4094。同时反过来,4095 * 4 + 4095 * 4 + 4095 * 4 + 4094 * 4 = 65516 < 65518 是成立的。
【验证3.5-3】 str1、str2、str3、str4 字段的字符集都为 utf8mb4,类型都为 VARCHAR ,任意一个为 NULL ,其它为 NOT NULL;num1 和 num2 都为 INT 类型,任意一个为 NULL ,另外一个为 NOT NULL ;至少有一个字段为 NULL 。如果 4 个字符串字段设置的字符长度总字节超过 65518 bytes,则会报错。
CREATE TABLE `tb7` (
`str1` varchar(4095) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`str2` varchar(4095) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`str3` varchar(4095) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`str4` varchar(4094) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`num1` int NOT NULL,
`num2` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

2.4.3.1.9 VARCHAR 比 CHAR 更省空间?
《高性能MySQL 第4版》第112 页中有这么一句:VARCHAR 比固定长度的类型(CHAR)更省空间,因为它仅使用必要的空间(即,更少的空间用于存储更短的值)。这段话有问题吗?是的,在某些情况下,CHAR 比 VARCHAR 更省空间,或者存储空间一样。
我不是说书中的内容是错误,只是描述不太准确,没把限制条件也列出来,下面的例子基于单字节字符集。例如,CHAR(1) 和 VARCHAR(1) 哪个更省空间? 显然而见,CHAR(1) 占 1 字节,VARCHAR(1) 占 2 字节。又如,CHAR(2) 和 VARCHAR(2) 哪个更省空间? 分情况去分析,假设 CHAR 类型的字段只存 1 个字符,实际上占用 2 字节,而 VARCHAR 类型的字段只存 1 个字符,那么也是占用 2 个字节,这样两者的存储空间是一样的。一般来说,字符是单字节字符集,在不考虑 M 值范围情况下且 M 值比较大,若 CHAR(M) 和 VARCHAR(M) 的 M 值是一样的,那么 VARCHAR(M) 占用字节会更少,因为 CHAR 类型字符占用 M 个字节,而 VARCHAR 类型字段由实际字符长度决定,实际字符长度 <= M ,占用字节为 实际字符长度 。
2.4.3.1.10 InnoDB存储引擎中,过长的 VARCHAR 值会存储为 BLOB?
《高性能MySQL 第4版》第113 页中有这么一句:InnoDB更为复杂,它可以将过长的 VARCHAR 值存储为 BLOB。如果有读者知道MySQL官方文档有介绍这方面的,请告知并给出对应网址,笔者我翻遍了有关 VARCHAR 类型的文档描述,也没找到文档中描述过长的 VARCHAR 值会存储为 BLOB 的内容,只是提到警告和错误。
2.4.3.1.11 慷慨是不明智的
《高性能MySQL 第4版》第114 页中说到:
使用 VARCHAR(5) 和 VARCHAR(200) 存储 “hello” 的空间开销是一样的,使用更短的列有很大的优势。
较大的列会使用更多的内存,因为 MySQL 通常会在内部分配固定大小的内存块来保存值。这对于使用内存临时表的排序或操作来说尤其糟糕。在利用磁盘临时表进行文件排序时也同样糟糕。
最好的策略是只分配真正需要的空间。
2.4.3.1.12 合适的字符串类型
1、如果要存储的字符串是定长的,使用 CHAR 类型更省空间,查询性能比 VARCHAR 要好。
2、如果存储的字符串字符长度不确定,那就使用 VARCHAR 类型,注意要预估字符串的大概长度,不要设置太大的字符串长度,分配合理的长度大小就好。
2.4.3.2 BLOB 和 TEXT 类型
2.4.3.2.1 BLOB 类型 - 说明
BLOB 是二进制大对象(Binary Large Object)的缩写。BLOB 类型有以下特点:
1、
二进制方式存储,可以存储很大可变数量的数据。四种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB。
2、可认为是二进制字符串(字节字符串),具有二进制字符集和排序规则,比较和排序基于列值中字节的数值。【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
【原文】:BLOB values are treated as binary strings (byte strings). They have the binary character set and collation, and comparison and sorting are based on the numeric values of the bytes in column values.TEXT values are treated as nonbinary strings (character strings). They have a character set other than binary, and values are sorted and compared based on the collation of the character set.
【谷歌翻译】:BLOB 值被视为二进制字符串(字节字符串)。它们具有二进制字符集和排序规则,比较和排序基于列值中字节的数值。TEXT 值被视为非二进制字符串(字符串)。它们具有二进制以外的字符集,并且根据字符集的排序规则对值进行排序和比较。
3、BLOB 列插入(insert)时没有填充,查询(select)时也没有删除字节。【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
【原文】:For TEXT and BLOB columns, there is no padding on insert and no bytes are stripped on select.
【谷歌翻译】:对于 TEXT 和 BLOB 列,插入时没有填充,查询时也没有删除字节。
4、在大多数情况下,可以将 BLOB 列视为可以任意大的 VARBINARY 列。对于 BLOB 上的索引,必须指定索引前缀长度。BLOB 列不能有 DEFAULT 值。 【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
5、MySQL对 BLOB 列的最前 max_sort_length 字节而不是整个字符串做排序。如果只需要按前面少数几个字符排序,可以减少 max_sort_length 服务器变量的值。max_sort_length 的默认值为 1024 。任何客户端都可以更改其会话 max_sort_length 变量的值。【出处】:《高性能MySQL 第4版》第 115 页、https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
mysql> SET max_sort_length = 2000;
mysql> SELECT id, comment FROM t ORDER BY comment;
6、MEMORY 存储引擎不支持 BLOB 类型,当使用使用临时表处理的查询结果中的 BLOB 列实例导致服务器使用磁盘上的表而不是内存中的表。使用磁盘会导致性能下降,因此只有在确实需要时才在查询结果中包含 BLOB 列。例如,避免使用选择所有列的 SELECT * 。【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
【原文】:Instances of BLOB or TEXT columns in the result of a query that is processed using a temporary table causes the server to use a table on disk rather than in memory because the MEMORY storage engine does not support those data types (see Section 8.4.4, “Internal Temporary Table Use in MySQL”). Use of disk incurs a performance penalty, so include BLOB or TEXT columns in the query result only if they are really needed. For example, avoid using SELECT *, which selects all columns.
【谷歌翻译】:使用临时表处理的查询结果中的 BLOB 或 TEXT 列实例导致服务器使用磁盘上的表而不是内存中的表,因为 MEMORY 存储引擎不支持这些数据类型(请参阅第 8.4.4 节, “MySQL 中的内部临时表使用”)。使用磁盘会导致性能下降,因此只有在确实需要时才在查询结果中包含 BLOB 或 TEXT 列。例如,避免使用选择所有列的 SELECT * 。
7、BLOB 对象的最大大小由其类型决定,但实际可以在客户端和服务器之间传输的最大值由可用内存量和通信缓冲区的大小决定。可以通过更改 max_allowed_packet 变量的值来更改消息缓冲区大小,但是必须对服务器和客户端程序都这样做。【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
可以使用 help blob 命令查看 BLOB 的语法。对应的官方文档网址:https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html
mysql> help blob

2.4.3.2.2 BLOB 类型 - 字节占用
【MySQL 8.0 官方文档 - 字符串数据类型语法】:
https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html
【MySQL 8.0 官方文档 - 数据类型存储要求】:
https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html
四种 BLOB 类型字节占用如下:
| 类型 | 字符串最大长度(单位:字节) |
字符串实际长度(单位:字节) |
占用字节(实际长度字节 + 长度前缀字节) |
|---|---|---|---|
| TINYBLOB | 28 - 1,即 255 bytes |
L | L + 1 < 28 |
| BLOB[(M)] | 216 - 1,即 65535 bytes |
L | L + 2 < 216 |
| MEDIUMBLOB | 224 - 1,即 16777215 bytes |
L | L + 3 < 224 |
| LONGBLOB | 232 - 1,即 4294967295 bytes |
L | L + 4 < 232 |
表格内容来源于官方文档的 字符串数据类型语法 和 数据类型存储要求 中关于 BLOB 的字节占用说明。其中 BLOB(M) 是可以带参数 M 的,也可以缺省参数 M ,M 表示以字符为单位的最大列长度。
2.4.3.2.3 TEXT 类型 - 说明
TEXT 类型有以下特点:
1、
字符方式存储,可以存储很大可变数量的数据。四种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT。
2、可视为非二进制字符串(字符串),具有二进制以外的字符集,并且根据字符集的排序规则对值进行排序和比较。【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
【原文】:BLOB values are treated as binary strings (byte strings). They have the binary character set and collation, and comparison and sorting are based on the numeric values of the bytes in column values.TEXT values are treated as nonbinary strings (character strings). They have a character set other than binary, and values are sorted and compared based on the collation of the character set.
【谷歌翻译】:BLOB 值被视为二进制字符串(字节字符串)。它们具有二进制字符集和排序规则,比较和排序基于列值中字节的数值。TEXT 值被视为非二进制字符串(字符串)。它们具有二进制以外的字符集,并且根据字符集的排序规则对值进行排序和比较。
3、TEXT 列插入(insert)时没有填充,查询(select)时也没有删除字节。【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
【原文】:For TEXT and BLOB columns, there is no padding on insert and no bytes are stripped on select.
【谷歌翻译】:对于 TEXT 和 BLOB 列,插入时没有填充,查询时也没有删除字节。
4、如果 TEXT 列被索引,则索引条目比较在末尾用空格填充。 【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
5、在大多数情况下,可以将 TEXT 列视为 VARCHAR 列。对于 TEXT 上的索引,必须指定索引前缀长度。TEXT 列不能有 DEFAULT 值。 【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
6、如果将 BINARY 属性与 TEXT 数据类型一起使用,则会为列分配列字符集的二进制 (_bin) 排序规则。 【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
7、MySQL对 TEXT 列的最前 max_sort_length 字节而不是整个字符串做排序。如果只需要按前面少数几个字符排序,可以减少 max_sort_length 服务器变量的值。max_sort_length 的默认值为 1024 。任何客户端都可以更改其会话 max_sort_length 变量的值。【出处】:《高性能MySQL 第4版》第 115 页、https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
mysql> SET max_sort_length = 2000;
mysql> SELECT id, comment FROM t ORDER BY comment;
8、MEMORY 存储引擎不支持 TEXT 类型,当使用使用临时表处理的查询结果中的 TEXT 列实例导致服务器使用磁盘上的表而不是内存中的表。使用磁盘会导致性能下降,因此只有在确实需要时才在查询结果中包含 TEXT 列。例如,避免使用选择所有列的 SELECT * 。【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
【原文】:Instances of BLOB or TEXT columns in the result of a query that is processed using a temporary table causes the server to use a table on disk rather than in memory because the MEMORY storage engine does not support those data types (see Section 8.4.4, “Internal Temporary Table Use in MySQL”). Use of disk incurs a performance penalty, so include BLOB or TEXT columns in the query result only if they are really needed. For example, avoid using SELECT *, which selects all columns.
【谷歌翻译】:使用临时表处理的查询结果中的 BLOB 或 TEXT 列实例导致服务器使用磁盘上的表而不是内存中的表,因为 MEMORY 存储引擎不支持这些数据类型(请参阅第 8.4.4 节, “MySQL 中的内部临时表使用”)。使用磁盘会导致性能下降,因此只有在确实需要时才在查询结果中包含 BLOB 或 TEXT 列。例如,避免使用选择所有列的 SELECT * 。
9、TEXT 对象的最大大小由其类型决定,但实际可以在客户端和服务器之间传输的最大值由可用内存量和通信缓冲区的大小决定。可以通过更改 max_allowed_packet 变量的值来更改消息缓冲区大小,但是必须对服务器和客户端程序都这样做。【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
可以使用 help text 命令查看 TEXT 的语法。对应的官方文档网址:https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html
mysql> help text

2.4.3.2.4 TEXT 类型 - 字节占用
【MySQL 8.0 官方文档 - 字符串数据类型语法】:
https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html
【MySQL 8.0 官方文档 - 数据类型存储要求】:
https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html
四种 TEXT 类型字节占用如下:
| 类型 | 字符串最大长度(单位:字符) |
字符串实际长度(单位:字节) |
占用字节(实际长度字节 + 长度前缀字节) |
|---|---|---|---|
| TINYTEXT | 28 - 1,即 255 | L | L + 1 < 28 |
| TEXT[(M)] | 216 - 1,即 65535 | L | L + 2 < 216 |
| MEDIUMTEXT | 224 - 1,即 16777215 | L | L + 3 < 224 |
| LONGTEXT | 232 - 1,即 4294967295 | L | L + 4 < 232 |
表格内容来源于官方文档的 字符串数据类型语法 和 数据类型存储要求 中关于 TEXT 的字节占用说明。表格中第二列的单位是字符。如果值包含多字节字符,则有效最大长度会更短。其中 TEXT(M) 是可以带参数 M 的,也可以缺省参数 M ,M 表示以字符为单位的最大列长度。
2.4.3.2.5 在数据库中存储图像?
《高性能MySQL 第4版》第 115 页:
在过去,图像作为 BLOB 数据存储在 MySQL 数据库中很常见。但是,随着数据大小等待增长,修改 schema 等操作会由于 BLOB 数据的大小而变得越来越慢。
如果可以避免的话,不要在数据库中存储图像这样的数据。相反,应该将它们写入单独的对象数据存储,并使用该表来跟踪图像的位置或文件名。
2.4.3.2.6 《高性能MySQL 第4版》存在的 BLOB 描述错误
《高性能MySQL 第4版》第 114 页有一段原话,描述是有错误的:
BLOB 和 TEXT 家族之间的唯一区别是,BLOB 类型存储的是二进制数据,没有排序规则或字符集,但 TEXT 类型有字符集和排序规则。
为什么说这段内容有错误呢?在 MySQL 8.0 官方文档中提到:BLOB 值被视为二进制字符串(字节字符串),它们具有二进制字符集和排序规则,比较和排序基于列值中字节的数值。以下是文档原话,并附谷歌翻译。【出处】:https://dev.mysql.com/doc/refman/8.0/en/blob.html 。
【原文】:BLOB values are treated as binary strings (byte strings). They have the binary character set and collation, and comparison and sorting are based on the numeric values of the bytes in column values.TEXT values are treated as nonbinary strings (character strings). They have a character set other than binary, and values are sorted and compared based on the collation of the character set.
【谷歌翻译】:BLOB 值被视为二进制字符串(字节字符串)。它们具有二进制字符集和排序规则,比较和排序基于列值中字节的数值。TEXT 值被视为非二进制字符串(字符串)。它们具有二进制以外的字符集,并且根据字符集的排序规则对值进行排序和比较。
所以,BLOB 是具有字符集和排序规则的,只不过是二进制字符集。
2.4.3.2.6 BLOB 和 TEXT 的实际应用场景
1、如果要存储大量字符串,例如网页内容、文章、博客等,可以考虑 TEXT 类型而不是 VARCHAR 类型。《阿里巴巴Java开发手册》中强制要求,字符长度超过 5000 个字符,使用 TEXT 类型,独立出来一张表,用主键来对应,避免影响其它字段的索引效率。
2、图像、音视频等媒体文件属于二进制文件,不适合用文本存储,虽然可以使用 BLOB 类型存储,但是更好的做法是放到文件系统或对象存储服务器上(例如阿里云的OSS、腾讯云的COS等),将文件路径存入到数据库。
2.4.3.3 枚举 类型
在日常开发中,用的最多的是 VARCHAR 、CHAR 、 TEXT 这些字符串类型,大家很少使用 ENUM 这种枚举类型。使用 ENUM 类型有什么优势呢?ENUM 是一个字符串对象。有时可以使用 ENUM 列代替常规的字符串类型。ENUM 列可以存储一组预定义的不同字符串值。MySQL 在存储枚举时非常紧凑,会根据列表值的数据压缩到 1 或 2 字节。在内部会将每个值在列表中的位置保存为整数。
【MySQL 8.0 官方文档 - 枚举类型】:
https://dev.mysql.com/doc/refman/8.0/en/enum.html
【MySQL 8.0 官方文档 - 字符串数据类型语法】:
https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html
【MySQL 8.0 官方文档 - 数据类型存储要求】:
https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html
2.4.3.3.1 ENUM 类型的特点
ENUM 类型有以下特点:
1、创建表的时候,必须显式地定义枚举的默认值,如果不定义默认值会报错。
枚举值必须是带引号的字符串文字。枚举默认值可以定义空字符串,只要使用引号括起来就行,此处正常的空字符串与无效值插入 ENUM (即允许值列表中不存在的字符串)时使用空字符串代替特殊错误值不一样,两者不是一个概念。
(1-1)错误地创建 ENUM 枚举类型字段方式。
CREATE TABLE `tb` (`e` enum() DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

(1-2)枚举默认值可以定义为空格。
CREATE TABLE `tb` (`e` enum('') DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

(1-3)创建枚举字段的表的正确方式。
CREATE TABLE `tb` (`e` enum('hello','world') DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

2、插入的字符串满足列定义的值,会自动编码为数字,即
索引号。可以使用select 列名+0 from 表名;查询索引号。此处的索引号与表的索引无关,可以看做是枚举值在列表中的位置。
(2-1)新建 tb 表,包含 ENUM 类型字段 e ,枚举默认值分别为:‘hello’,‘world’,并插入两条测试数据。
CREATE TABLE `tb` (`e` enum('hello','world') DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
insert into tb values('hello');
insert into tb values('world');

(2-2)tb 表查询 ENUM 类型的字段 e 的索引号。
select e+0 from tb;

3、每个枚举值都有一个索引号,从 1 开始。官方文档中还提到,空字符串错误值的索引值为 0 。枚举默认值列表中不定义空字符串值的话,插入或修改为空字符串是会报错的,数据被截断——ERROR 1265 (01000): Data truncated for column ‘e’ at row 1。
NULL 值的索引号为 NULL。
(3-1)tb 表的 e 字段的枚举默认值列表中不存在空字符串值,当插入空字符串时报错了。
mysql> insert into tb values('');
ERROR 1265 (01000): Data truncated for column 'e' at row 1
(3-2)向 e 字段插入 NULL 值,查询到的索引号也是 NULL 值。
mysql> insert into tb values(NULL);
Query OK, 1 row affected (0.01 sec)

4、如果将无效值插入 ENUM(即允许值列表中不存在的字符串),则会插入空字符串作为特殊错误值。可以通过该字符串的数值为 0 来将该字符串与“正常”空字符串区分开来。如果启用了严格的 SQL 模式,尝试插入无效的 ENUM 值会导致错误。如果声明 ENUM 列允许 NULL,则 NULL 值是该列的有效值,默认值为 NULL。如果 ENUM 列声明为 NOT NULL,则其默认值是允许值列表的第一个元素。【出处】 https://dev.mysql.com/doc/refman/8.0/en/enum.html
5、一个 ENUM 列最多可以有
65535 个不同的元素。单个 ENUM 元素的最大支持长度为 M <= 255 和 (M x w) <= 1020,其中 M 是元素文字长度,w 是字符集中最大长度字符所需的字节数。【出处】https://dev.mysql.com/doc/refman/8.0/en/string-type-syntax.html
【原文】 An ENUM column can have a maximum of 65,535 distinct elements.
【谷歌翻译】一个 ENUM 列最多可以有 65,535 个不同的元素。
【原文】 The maximum supported length of an individual ENUM element is M <= 255 and (M x w) <= 1020, where M is the element literal length and w is the number of bytes required for the maximum-length character in the character set.
【谷歌翻译】单个 ENUM 元素的最大支持长度为 M <= 255 和 (M x w) <= 1020,其中 M 是元素文字长度,w 是字符集中最大长度字符所需的字节数。
6、ENUM 对象的大小由不同枚举值的数量决定。枚举值的实际数量用 N 表示,那么
N <= 255 占用 1 字节,256 <= N <= 65535 占用 2 字节。【出处】https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html
【原文】 The size of an ENUM object is determined by the number of different enumeration values. One byte is used for enumerations with up to 255 possible values. Two bytes are used for enumerations having between 256 and 65,535 possible values. See Section 11.3.5, “The ENUM Type”.
【谷歌翻译】ENUM 对象的大小由不同枚举值的数量决定。一个字节用于具有最多 255 个可能值的枚举。两个字节用于具有 256 到 65,535 个可能值的枚举。请参阅第 11.3.5 节,“ENUM 类型”。
7、只要插入或修改的值不在枚举默认值的列表中,都会报列数据截断错误——
ERROR 1265 (01000): Data truncated for column 'xxx' at row 1。
mysql> insert into tb values('java');
ERROR 1265 (01000): Data truncated for column 'e' at row 1
mysql> update tb set e='spring';
ERROR 1265 (01000): Data truncated for column 'e' at row 1

8、
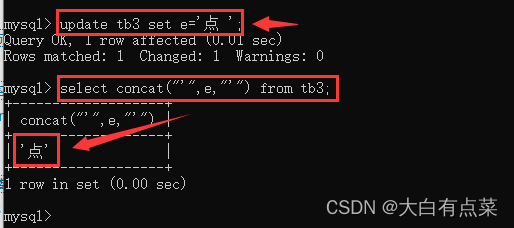
字符串尾部带有空格的,插入或修改时会自动删除空格。但空格是在字符串前面或者前后都有的,则直接报列的数据截断错误。
(8-1)创建一个 tb3 表,包含 ENUM 类型字段 e ,枚举默认值分别为:‘大’,‘白’,‘有’,‘点’,‘菜’。
CREATE TABLE `tb3` (`e` enum('大','白','有','点','菜') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
(8-2)插入字符串为“菜 ”,字符串尾部有 1 个空格,发现能正常插入。
mysql> insert into tb3 values ('菜 ');
Query OK, 1 row affected (0.00 sec)
(8-3)如果插入字符串为“ 大”,字符串前面有 1 个空格,会报错。
mysql> insert into tb3 values (' 大');
ERROR 1265 (01000): Data truncated for column 'e' at row 1
(8-4)如果插入字符串为“ 白 ”,字符串前后都有 1 个空格,同样也报错。
mysql> insert into tb3 values (' 白 ');
ERROR 1265 (01000): Data truncated for column 'e' at row 1
(8-5)尾部有空格的字符串“菜 ”,查询出来是不存在空格的,说明插入的时候被删除了。更改值同理,尾部有空格的字符串会删除尾部空格。

9、ENUM 值根据索引号排序,取决于定义枚举默认值的顺序。例如,对于 ENUM(‘b’, ‘a’),‘b’ 排在 ‘a’ 之前。空字符串排在非空字符串之前,NULL 值排在所有其他枚举值之前。为防止在 ENUM 列上使用
ORDER BY子句时出现意外结果,除了可以按字母顺序指定 ENUM 列表,还可以通过ORDER BY CAST(列名 AS CHAR)或ORDER BY CONCAT(列名)确保列按词法排序而不是按索引编号排序。中文的排序(非索引号排序)语法并不是按拼音去排序的,而是由字符集编码决定。【出处】 https://dev.mysql.com/doc/refman/8.0/en/enum.html
(9-1)创建一个 tb2 表,包含 ENUM 类型字段 e ,枚举默认值分别为:‘a’,‘b’,‘c’,‘’。最后一个是空字符串。插入5条数据,其中包含了空字符串和 NULL 。先查看 tb2 表的数据插入情况。
CREATE TABLE `tb2` (`e` enum('a','b','c','') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
insert into tb2 values ('b');
insert into tb2 values ('c');
insert into tb2 values ('a');
insert into tb2 values ('');
insert into tb2 values (null);
select e from tb2;

(9-2)在 tb2 表中,查询语句后面加上 ORDER BY ,可以看到按索引号排序,索引号为 NULL 排在最前面,不过空字符串并没有排在非空字符串前面,验证了官方提到的“意外结果”。此处的空字符串对应的索引号是 4 。
select e from tb2 order by e;

(9-3)同样新建 tb4 表,过程和 tb2 表新建一样,不再过多说明。查询时使用ORDER BY CAST(列名 AS CHAR) 或 ORDER BY CONCAT(列名)子句。从结果中,可以看到 NULL 还是排在最前面,意想不到的是,空字符串居然真的排在了非空字符串的前面,避免出现意外结果。其它值按词法排序,“alibaba”第一个字母“a”和“apple”的第一字母相同,第二个字母“l”比“p”靠前,单词“alibaba”也就排在非空字符串第一位。
CREATE TABLE `tb4` (`e` enum('apple','banana','alibaba','peach','cherry','') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
insert into tb4 values ('peach');
insert into tb4 values ('alibaba');
insert into tb4 values ('cherry');
insert into tb4 values ('apple');
insert into tb4 values ('banana');
insert into tb4 values ('');
insert into tb4 values (null);
select e from tb4;
select e+0 from tb4;
select e from tb4 order by cast(e as char);
select e from tb4 order by concat(e);

(9-4)新建 tb3 表。查询时,中文排序若按索引号排序,顺序符合我的要求。若使用ORDER BY CAST(列名 AS CHAR) 或 ORDER BY CONCAT(列名)子句进行词法排序,结果看起来很乱,顺序不能保证。ENUM 类型字段若要存储中文,想保证汉字的顺序,就按索引号来排序,按词法排序得到的可能是乱序。
CREATE TABLE `tb3` (`e` enum('大','白','有','点','菜') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
insert into tb3 values ('菜');
insert into tb3 values ('点');
insert into tb3 values ('有');
insert into tb3 values ('白');
insert into tb3 values ('大');
select e from tb3;
select e+0 from tb3;
select e from tb3 order by e;
select e from tb3 order by cast(e as char);
select e from tb3 order by concat(e);

10、可以在查询中使用 FIELD() 函数显式地指定排序顺序,但这会
导致 MySQL 无法利用索引消除排序(注:我无法理解这句话是什么意思)。【出处】《高性能MySQL 第 4 版》第 116 页
FIELD(str,str1,str2,str3,...):返回 str 在 str1, str2, str3, … 列表中的索引(位置)。如果未找到 str,则返回 0。如果 FIELD() 的所有参数都是字符串,则所有参数都作为字符串进行比较。如果所有参数都是数字,则将它们作为数字进行比较。否则,参数将作为双精度进行比较。如果 str 为 NULL,则返回值为 0,因为 NULL 无法与任何值进行相等比较。可以使用help field查看相关语法。【出处】https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_field
mysql> help field

select e from tb3 order by field(e, '大', '白', '有', '点', '菜');

11、使用
SHOW COLUMNS FROM tbl_name LIKE 'enum_col'确定 ENUM 列的所有可能值。
show columns from tb3 like 'e';

2.4.3.3.2 使用 ENUM 类型注意事项
1、
尽量避免使用数字作为 ENUM 常量,这种双重属性很容易混淆字符串和基础数字值,例如,ENUM(‘0’,‘1’,‘2’) 。
CREATE TABLE `tb1` (`e` enum('0','1','2') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
insert into tb1 values ('2');
insert into tb1 values ('1');
insert into tb1 values ('0');

明明按顺序插入数字 2、1、0 ,查询出来的索引号却是 3、2、1 ,让人很容易混淆字符串和基础数字值。
2、
枚举值不能是表达式,即使计算结果为字符串值也是如此。例如,此 CREATE TABLE 语句不起作用,因为 CONCAT 函数不能用于构造枚举值。【出处】https://dev.mysql.com/doc/refman/8.0/en/enum.html#enum-limits
CREATE TABLE `sizes` (`size` enum('small', CONCAT('med','ium'), 'large') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

3、
不能将用户变量用作枚举值,不然语句会不起作用。【出处】https://dev.mysql.com/doc/refman/8.0/en/enum.html#enum-limits
SET @mysize = 'medium';
CREATE TABLE `sizes` (`size` enum('small', @mysize, 'large') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;

4、不要将 CHAR 或 VARCHAR 列连接(JOIN)到 ENUM 列,会影响查询性能。【出处】《高性能MySQL 第4版》第 116 、117 页。
2.4.3.3.3 ENUM 类型应用场景
1、如果要存储
性别属性,可以定义 ENUM(‘男’,‘女’),只允许这两个选项之一。如果要存储类别属性,可以定义 ENUM(‘待支付’,‘已支付’,‘已完成’)。如果要存储状态属性,可以定义 ENUM(‘未验证’,‘已验证’) 。
2、完全可以使用TINYINT(1)来替代 ENUM ,我在实际开发中使用得最多的还是TINYINT(1),和前端交互比较友好些。
2.4.4 日期和时间 类型
2.4.4.1 什么是 fsp ?
【MySQL 8.0 官方文档 - 日期和时间数据类型语法】:
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-type-syntax.html
fsp 是 Fractional Seconds Precision 的缩写,意思是:小数秒精度。表示时间值的日期和时间数据类型有 DATE、TIME、DATETIME、TIMESTAMP 和 YEAR 。
MySQL 允许 TIME、DATETIME 和 TIMESTAMP 值的小数秒,精度可达微秒(6 位)。要定义包含小数秒部分的列,请使用语法 type_name(fsp),其中 type_name 是 TIME、DATETIME 或 TIMESTAMP,fsp 是小数秒精度。
fsp 值如果有设置,必须在 0 到 6 的范围内。值 0 表示没有小数部分。如果省略,则默认精度为 0。标准 SQL 默认值是 6 ,为了与 MySQL 旧版本兼容,最新的 MySQL 版本允许 fsp 这么设置。
2.4.4.2 日期和时间类型存储要求
【MySQL 8.0 官方文档 - 日期和时间类型存储要求】:
https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html#data-types-storage-reqs-date-time
对于 TIME、DATETIME 和 TIMESTAMP 列,MySQL 5.6.4 之前创建的表与 5.6.4 之后创建的表所需的存储空间不同。这是由于 5.6.4 中的更改允许这些类型具有小数部分,这需要 0 到 3 个字节。
| 数据类型 | MySQL 5.6.4 之前的存储空间(单位:bytes) |
MySQL 5.6.4 之后的存储空间(单位:bytes) |
|---|---|---|
| YEAR | 1 | 1 |
| DATE | 3 | 3 |
| TIME | 3 | 3 + 小数秒精度存储(0~3 bytes) |
| DATETIME | 8 | 5 + 小数秒精度存储(0~3 bytes) |
| TIMESTAMP | 4 | 4 + 小数秒精度存储(0~3 bytes) |
从 MySQL 5.6.4 开始,YEAR 和 DATE 的存储保持不变。但是,TIME、DATETIME 和 TIMESTAMP 的表示方式不同。 DATETIME 的打包效率更高,非小数部分需要 5 个字节而不是 8 个字节,所有三个部分都有一个需要 0 到 3 个字节的小数部分,具体取决于存储值的小数秒精度。
| 小数秒精度 | 存储空间(单位:bytes) |
|---|---|
| 0 | 0 bytes |
| 1 或 2 | 1 bytes |
| 3 或 4 | 2 bytes |
| 5 或 6 | 3 bytes |
例如,TIME(0)、TIME(2)、TIME(4) 和 TIME(6) 分别使用 3、4、5 和 6 个字节。 TIME 和 TIME(0) 是等效的,需要相同的存储空间。
2.4.4.3 DATE 类型
【MySQL 8.0 官方文档 - 日期和时间数据类型语法】:
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-type-syntax.html
【MySQL 8.0 官方文档 - DATE、DATETIME 和 TIMESTAMP 类型】:
https://dev.mysql.com/doc/refman/8.0/en/datetime.html
1、DATE 类型支持的范围是
“1000-01-01” 到 “9999-12-31”。 MySQL 以“YYYY-MM-DD”格式显示 DATE 值,只有日期部分,没有时间部分,即年、月、日,允许使用字符串或数字将值分配给 DATE 列。
CREATE TABLE `tb1` (
`_date` date DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
show create table tb1;
insert into tb1 values (now());

2、DATE 类型占用
3 字节。【出处】https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html#data-types-storage-reqs-date-time
2.4.4.4 DATETIME 类型
【MySQL 8.0 官方文档 - 日期和时间数据类型语法】:
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-type-syntax.html
【MySQL 8.0 官方文档 - DATE、DATETIME 和 TIMESTAMP 类型】:
https://dev.mysql.com/doc/refman/8.0/en/datetime.html
【MySQL 8.0 官方文档 - TIMESTAMP 和 DATETIME 的自动初始化和更新】:
https://dev.mysql.com/doc/refman/8.0/en/timestamp-initialization.html
1、DATETIME 类型的语法是:
DATETIME[(fsp)],fsp(小数秒精度) 的范围是:0 到 6。值为 0 表示没有小数部分。如果省略,则默认精度为 0 。

2、DATETIME 类型支持的范围是
“1000-01-01 00:00:00.000000” 到 “9999-12-31 23:59:59.999999”。 MySQL 以“YYYY-MM-DD hh:mm:ss[.小数]”格式显示 DATETIME 值,即年、月、日、时、分、秒…微秒,允许使用字符串或数字将值分配给 DATETIME 列。
CREATE TABLE `tb2` (
`_datetime1` datetime DEFAULT NULL,
`_datetime2` datetime(6) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
show create table tb2;
insert into tb2 values (now(),now());

3、DATETIME 类型可以使用以下几种子句:
DEFAULT NULL
DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP
DEFAULT CURRENT_TIMESTAMP
DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
DATETIME 列只有 ON UPDATE CURRENT_TIMESTAMP 子句,没有 DEFAULT 子句,默认值为 NULL 。此处即使不写 DEFAULT NULL 子句,创建表的时候也会自动生成 DEFAULT NULL 子句。
DATETIME 列只有 ON UPDATE CURRENT_TIMESTAMP 子句,没有 DEFAULT 子句,而且使用 NOT NULL 属性定义,默认值为 0。【注意】 使用 DEFAULT 0,这是一个默认值,它会根据是否启用 TRADITIONAL SQL 模式 或 NO_ZERO_DATE SQL模式而产生警告或错误。如下:
mysql> CREATE TABLE t1 (
-> dt DATETIME DEFAULT 0,
-> ts TIMESTAMP DEFAULT 0
-> );
ERROR 1067 (42000): Invalid default value for ‘dt’
DEFAULT 子句还可用于指定常量默认值(例如,DEFAULT 0 或 DEFAULT ‘2000-01-01 00:00:00’)。在这种情况下,该列根本没有自动属性。
DEFAULT CURRENT_TIMESTAMP 子句自动初始化设置DATETIME 列为当前时间戳。
ON UPDATE CURRENT_TIMESTAMP 子句自动更新DATETIME 列为当前时间戳。
在日常开发中,每个表都必须创建两个字段:create_time(创建时间)、update_time(更新时间),类型定义为 DATETIME 或 TIMESTAMP。“创建时间”的子句为:DEFAULT CURRENT_TIMESTAMP 。“修改时间”的子句为:DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP 。插入数据时,同时将当前时间戳设置到 create_time 和 update_time 字段。修改数据时只将当前时间戳更新到 update_time 字段,而 create_time 字段的值不变。
《阿里巴巴Java开发手册》中,MySQL数据库 - 建表规约 章节说到:【强制】表必备三个字段:id、create_time、update_time。[说明:其中 id 必为主键,类型为 bigint unsigned 、单表时自增、步长为 1 。create_time 和 update_time 的类型均为 date_time 。]
【3-1】创建一个表 tb3 ,一共有 5 个字段:name、d1、d2、create_time、update_time 。
| tb3表字段 | 数据类型 | 子句 |
|---|---|---|
| name | VARCHAR(16) | DEFAULT NULL |
| d1 | DATETIME | DEFAULT NULL |
| d2 | DATETIME | DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP |
| create_time | DATETIME | DEFAULT CURRENT_TIMESTAMP |
| update_time | DATETIME | DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP |
CREATE TABLE `tb3` (
`name` varchar(16) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`d1` datetime DEFAULT NULL,
`d2` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
【3-2】往字段 name 插入一条数据并查看 tb3 表所有列数据。此时由结果可以看出,d1 和 d2 的值都为 NULL,create_time 和 update_time 的值一样,为当前时间戳。
insert into tb3(name) values ('大白有点菜');
select * from tb3;

【3-3】更改 name 的值,看看其它字段值如何变化。结果是,d1 的值不变(NULL),d2 的值为当前时间戳,create_time 的值不变,update_time 的值为当前时间戳。
update tb3 set name = '大白一点也不菜';
select * from tb3;

4、DATETIME 类型占用
5 + 小数秒精度存储(0~3 bytes)字节,具体字节占用可以浏览 2.4.4.2 日期和时间类型存储要求 。【出处】https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html#data-types-storage-reqs-date-time
5、在 MySQL 8.0.19 及更高版本中,可以在向表中插入 DATETIME 值时指定时区偏移量。有关更多信息和示例,可以阅读 “日期和时间文字”章节内容:https://dev.mysql.com/doc/refman/8.0/en/date-and-time-literals.html 。
6、如果 SQL 模式允许此转换,则无效的 DATE、DATETIME 或 TIMESTAMP 值将转换为适当类型的“零”值(“0000-00-00”或“0000-00-00 00:00:00”)。精确的行为取决于是否启用了 TRADITIONAL SQL 模式和 NO_ZERO_DATE SQL 模式。可以阅读 “服务器 SQL 模式”章节内容:https://dev.mysql.com/doc/refman/8.0/en/sql-mode.html 。
2.4.4.5 TIMESTAMP 类型
【MySQL 8.0 官方文档 - 日期和时间数据类型语法】:
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-type-syntax.html
【MySQL 8.0 官方文档 - DATE、DATETIME 和 TIMESTAMP 类型】:
https://dev.mysql.com/doc/refman/8.0/en/datetime.html
【MySQL 8.0 官方文档 - TIMESTAMP 和 DATETIME 的自动初始化和更新】:
https://dev.mysql.com/doc/refman/8.0/en/timestamp-initialization.html
1、TIMESTAMP 类型的语法是:
TIMESTAMP[(fsp)],fsp(小数秒精度) 的范围是:0 到 6。值为 0 表示没有小数部分。如果省略,则默认精度为 0 。

2、TIMESTAMP 类型支持的范围是
“1970-01-01 00:00:01.000000” UTC 到 “2038-01-19 03:14:07.999999” UTC。 MySQL 以“YYYY-MM-DD hh:mm:ss[.小数]”格式显示 TIMESTAMP 值,即年、月、日、时、分、秒…微秒。
一个时间戳。TIMESTAMP 值存储为自纪元(‘1970-01-01 00:00:00’ UTC)以来的秒数。 TIMESTAMP不能表示值“1970-01-01 00:00:00”,因为它相当于从纪元开始的 0 秒,而值 0 保留用于表示“0000-00-00 00:00:00”, “零” TIMESTAMP 值。【出处】https://dev.mysql.com/doc/refman/8.0/en/date-and-time-type-syntax.html ,这段内容来源官方文档,使用谷歌翻译,意思是 TIMESTAMP 值存储的是从纪元以来的秒数值,而不是一个类似“1970-01-01 00:00:00”的字符串的值。
【原文】 A timestamp. The range is ‘1970-01-01 00:00:01.000000’ UTC to ‘2038-01-19 03:14:07.999999’ UTC. TIMESTAMP values are stored as the number of seconds since the epoch (‘1970-01-01 00:00:00’ UTC). A TIMESTAMP cannot represent the value ‘1970-01-01 00:00:00’ because that is equivalent to 0 seconds from the epoch and the value 0 is reserved for representing ‘0000-00-00 00:00:00’, the “zero” TIMESTAMP value.
CREATE TABLE `tb4` (
`_timestamp1` timestamp NULL DEFAULT NULL,
`_timestamp2` timestamp(6) NULL DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
show create table tb4;
insert into tb4 values (now(),now());

3、TIMESTAMP 类型可以使用以下几种子句:
DEFAULT NULL
DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP
DEFAULT CURRENT_TIMESTAMP
DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
TIMESTAMP 列只有 ON UPDATE CURRENT_TIMESTAMP 子句,没有 DEFAULT 子句,默认值为 0 。【注意】 使用 DEFAULT 0,这是一个默认值,它会根据是否启用 TRADITIONAL SQL 模式 或 NO_ZERO_DATE SQL模式而产生警告或错误。如下:
mysql> CREATE TABLE t1 (
-> ts TIMESTAMP DEFAULT 0,
-> dt DATETIME DEFAULT 0
-> );
ERROR 1067 (42000): Invalid default value for ‘ts’
TIMESTAMP 列只有 ON UPDATE CURRENT_TIMESTAMP 子句,没有 DEFAULT 子句,而且使用 NULL 属性定义,默认值为 NULL。
TIMESTAMP 子句还可用于指定常量默认值(例如,DEFAULT 0 或 DEFAULT ‘2000-01-01 00:00:00’)。在这种情况下,该列根本没有自动属性。
DEFAULT CURRENT_TIMESTAMP 子句自动初始化设置TIMESTAMP 列为当前时间戳。
ON UPDATE CURRENT_TIMESTAMP 子句自动更新TIMESTAMP 列为当前时间戳。
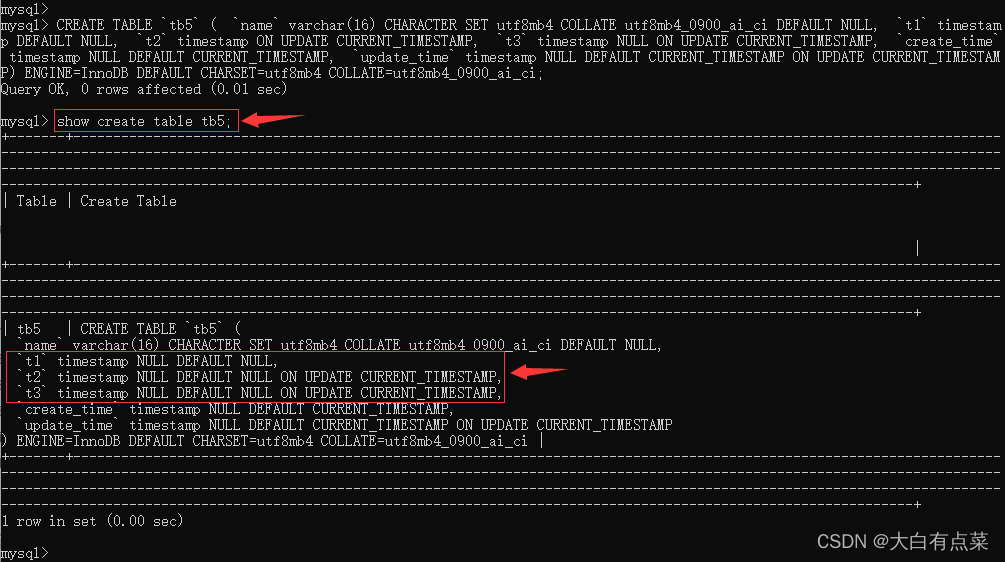
【3-1】创建一个表 tb5 ,一共有 6 个字段:name、t1、t2、t3、create_time、update_time 。
| tb3表字段 | 数据类型 | 子句 |
|---|---|---|
| name | VARCHAR(16) | DEFAULT NULL |
| t1 | TIMESTAMP | DEFAULT NULL |
| t2 | TIMESTAMP | ON UPDATE CURRENT_TIMESTAMP |
| t3 | TIMESTAMP | NULL ON UPDATE CURRENT_TIMESTAMP |
| create_time | TIMESTAMP | DEFAULT CURRENT_TIMESTAMP |
| update_time | TIMESTAMP | DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP |
CREATE TABLE `tb5` (
`name` varchar(16) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`t1` timestamp DEFAULT NULL,
`t2` timestamp ON UPDATE CURRENT_TIMESTAMP,
`t3` timestamp NULL ON UPDATE CURRENT_TIMESTAMP,
`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
虽然字段 t2 的子句(ON UPDATE CURRENT_TIMESTAMP)和 t3 的子句(NULL ON UPDATE CURRENT_TIMESTAMP)写法不一样,但是查看表结构,发现是一样的,MySQL 会自动补全子句。
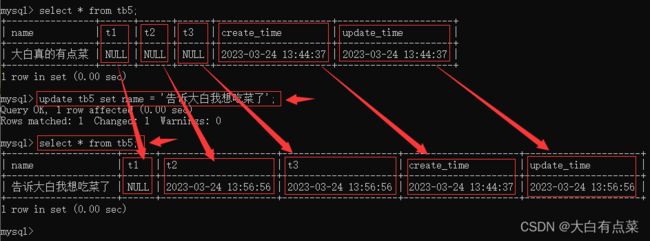
【3-2】往字段 name 插入一条数据并查看 tb5 表所有列数据。结果中,t1、t2、t3 的值都为 NULL,create_time 和 update_time 的值一样,为当前时间戳。
insert into tb5(name) values ('大白真的有点菜');
select * from tb5;

【3-3】更改 name 的值,看看其它字段值如何变化。结果是,t1 的值不变(NULL),t2、t3 的值为当前时间戳,create_time 的值不变,update_time 的值为当前时间戳。
update tb5 set name = '告诉大白我想吃菜了';
select * from tb5;
4、TIMESTAMP 类型占用
4 + 小数秒精度存储(0~3 bytes)字节,具体字节占用可以浏览 2.4.4.2 日期和时间类型存储要求。【出处】https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html#data-types-storage-reqs-date-time
5、在 MySQL 8.0.19 及更高版本中,可以在向表中插入 TIMESTAMP 值时指定时区偏移量。有关更多信息和示例,可以阅读 “日期和时间文字”章节内容:https://dev.mysql.com/doc/refman/8.0/en/date-and-time-literals.html 。
6、如果 SQL 模式允许此转换,则无效的 DATE、DATETIME 或 TIMESTAMP 值将转换为适当类型的“零”值(“0000-00-00”或“0000-00-00 00:00:00”)。精确的行为取决于是否启用了 TRADITIONAL SQL 模式和 NO_ZERO_DATE SQL 模式。可以阅读 “服务器 SQL 模式”章节内容:https://dev.mysql.com/doc/refman/8.0/en/sql-mode.html 。
7、MySQL 将 TIMESTAMP 值从当前时区转换为 UTC 进行存储,然后从 UTC 转换回当前时区进行检索。 (对于 DATETIME 等其他类型不会发生这种情况。)默认情况下,每个连接的当前时区是服务器的时间。可以在每个连接的基础上设置时区。只要时区设置保持不变,就会得到与存储的相同的值。如果存储一个 TIMESTAMP 值,然后更改时区并检索该值,则检索到的值与存储的值不同。发生这种情况是因为没有在两个方向上使用相同的时区进行转换。当前时区可用作 time_zone 系统变量的值。可参阅“MySQL 服务器时区支持”。
8、如果
启用 explicit_defaults_for_timestamp,则不会自动将 DEFAULT CURRENT_TIMESTAMP 或 ON UPDATE CURRENT_TIMESTAMP 属性分配给任何 TIMESTAMP 列,必须显式包含在列定义中。此外,任何未明确声明为 NOT NULL 的 TIMESTAMP 都允许 NULL 值。MySQL 8.0 中是默认开启的,可以通过语句查看:show variables like '%explicit_defaults_for_timestamp%';。
如果需要禁用(OFF)或启用(ON),有两种方式(当前会话和全局)。其中 off 可以用 0 代替,on 可以用 1 代替。
(1)禁用(OFF):当前 Session 会话,临时生效,退出会使设置无效:set explicit_defaults_for_timestamp = off;或set explicit_defaults_for_timestamp = 0;
(2)禁用(OFF):全局设置,永久生效:set global explicit_defaults_for_timestamp = off;或set global explicit_defaults_for_timestamp = 0;。
(3)启用(ON):当前 Session 会话,临时生效,退出会使设置无效:set explicit_defaults_for_timestamp = on;或set explicit_defaults_for_timestamp = 1;
(4)启用(ON):全局设置,永久生效:set global explicit_defaults_for_timestamp = on;或set global explicit_defaults_for_timestamp = 1;。
show variables like '%explicit_defaults_for_timestamp%';

【8-1】 禁用 explicit_defaults_for_timestamp ,在当前 Session 会话中临时生效,退出会使设置无效。
set explicit_defaults_for_timestamp = off;
或
set explicit_defaults_for_timestamp = 0
【8-2】 禁用 explicit_defaults_for_timestamp ,全局设置,永久生效。
set global explicit_defaults_for_timestamp = off;
或
set global explicit_defaults_for_timestamp = 0
9、如果
禁用 explicit_defaults_for_timestamp,则 TIMESTAMP 列默认为 NOT NULL,不能包含 NULL 值,并且分配 NULL 会分配当前时间戳。要允许 TIMESTAMP 列包含 NULL,请使用 NULL 属性显式声明它。在这种情况下,默认值也变为 NULL,除非用指定不同默认值的 DEFAULT 子句覆盖。 DEFAULT NULL 可用于显式指定 NULL 作为默认值。 (对于未使用 NULL 属性声明的 TIMESTAMP 列,DEFAULT NULL 无效。)如果 TIMESTAMP 列允许 NULL 值,分配 NULL 会将其设置为 NULL,而不是当前时间戳。第一个 TIMESTAMP 列同时具有DEFAULT CURRENT_TIMESTAMP(自动初始化)和ON UPDATE CURRENT_TIMESTAMP(更新到当前日期和时间)属性。【出处】https://dev.mysql.com/doc/refman/8.0/en/timestamp-initialization.html
如果需要禁用(OFF)或启用(ON),有两种方式(当前会话和全局)。其中 off 可以用 0 代替,on 可以用 1 代替。
(1)禁用(OFF):当前 Session 会话,临时生效,退出会使设置无效:set explicit_defaults_for_timestamp = off;或set explicit_defaults_for_timestamp = 0;
(2)禁用(OFF):全局设置,永久生效:set global explicit_defaults_for_timestamp = off;或set global explicit_defaults_for_timestamp = 0;。
(3)启用(ON):当前 Session 会话,临时生效,退出会使设置无效:set explicit_defaults_for_timestamp = on;或set explicit_defaults_for_timestamp = 1;
(4)启用(ON):全局设置,永久生效:set global explicit_defaults_for_timestamp = on;或set global explicit_defaults_for_timestamp = 1;。
【9-1】 启用 explicit_defaults_for_timestamp ,在当前 Session 会话中临时生效,退出会使设置无效。
set explicit_defaults_for_timestamp = on;
或
set explicit_defaults_for_timestamp = 1
【9-2】 启用 explicit_defaults_for_timestamp ,全局设置,永久生效。
set global explicit_defaults_for_timestamp = on;
或
set global explicit_defaults_for_timestamp = 1
2.4.4.6 TIME 类型
【MySQL 8.0 官方文档 - 日期和时间数据类型语法】:
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-type-syntax.html
【MySQL 8.0 官方文档 - TIME 类型】:
https://dev.mysql.com/doc/refman/8.0/en/time.html
1、TIME 类型的语法是:
TIME[(fsp)],fsp(小数秒精度) 的范围是:0 到 6。值为 0 表示没有小数部分。如果省略,则默认精度为 0 。

2、TIME 类型支持的范围是
“-838:59:59.000000” 到 “838:59:59.000000”。 MySQL 以“hh:mm:ss[.小数]”格式(或“hhh:mm:ss”格式用于大小时值)检索和显示 TIME 值,即时、分、秒…微秒,允许使用字符串或数字将值分配给 TIME 列。小时部分可能很大,因为 TIME 类型不仅可以用来表示一天中的时间(必须小于 24 小时),还可以用来表示经过的时间或两个事件之间的时间间隔(可能远大于24小时,甚至负数)。
CREATE TABLE `tb6` (
`_time1` time DEFAULT NULL,
`_time2` time(6) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
insert into tb6 values (now(), now());

3、将缩写值分配给 TIME 列时要小心。 MySQL 将带冒号的缩写 TIME 值解释为一天中的时间。也就是说,“11:12”表示“11:12:00”,而不是“00:11:12”。 MySQL 使用最右边的两个数字代表秒(即经过的时间而不是一天中的时间)的假设来解释没有冒号的缩写值。例如,您可能会认为“1112”和 1112 表示“11:12:00”(11 点后 12 分钟),但 MySQL 将它们解释为“00:11:12”(11 分 12 秒)。同样,‘12’ 和 12 被解释为 ‘00:00:12’。
4、默认情况下,位于 TIME 范围之外但在其他方面有效的值将被裁剪到该范围的最近端点。例如,‘-850:00:00’ 和 ‘850:00:00’ 将转换为 ‘-838:59:59’ 和 ‘838:59:59’。无效的 TIME 值将转换为“00:00:00”。请注意,因为“00:00:00”本身是一个有效的 TIME 值,所以无法根据存储在表中的“00:00:00”值判断原始值是否指定为“00:00:00’ 或是否无效。
5、TIME 类型占用
3 + 小数秒精度存储(0~3 bytes)字节,具体字节占用可以浏览 2.4.4.2 日期和时间类型存储要求。【出处】https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html#data-types-storage-reqs-date-time
2.4.4.7 YEAR 类型
【MySQL 8.0 官方文档 - 日期和时间数据类型语法】:
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-type-syntax.html
【MySQL 8.0 官方文档 - YEAR 类型】:
https://dev.mysql.com/doc/refman/8.0/en/year.html
1、YEAR 类型的语法是:
YEAR[(4)],4 位数格式的年份。从 MySQL 8.0.19 开始,不推荐使用具有显式显示宽度的 YEAR(4) 数据类型。MySQL 8.0 不支持旧版本 MySQL 中允许的 2 位 YEAR(2) 数据类型。
2、YEAR 类型支持的范围是
1901 到 2155,以及 0000。 MySQL 以“YYYY”格式显示 YEAR 值,即年。YEAR 接受多种格式的输入值:
- “1901” 到 “2155” 范围内的 4 位字符串。
- 1901 到 2155 范围内的 4 位数字。
- “0” 到 “99” 范围内的 1 位或 2 位数字字符串。 MySQL 将 “0” 到 “69” 范围内的值转换为 YEAR 值中的 2000 年到 2069 年,将 “70” 到 “99” 范围内的值转换为 YEAR 值中的 1970 年到 1999 年。
- 0 到 99 范围内的 1 位或 2 位数字。MySQL 将 1 到 69 范围内的值转换为 YEAR 值中的 2001 年到 2069 年,将 70 到 99 范围内的值转换为 YEAR 值中的 1970 年到 1999 年。
- 插入数字 0 的结果显示值为 0000,内部值为 0000。要插入零并将其解释为 2000,请将其指定为字符串“0”或“00”。
- 作为返回 YEAR 上下文中可接受的值的函数的结果,例如 NOW()。
CREATE TABLE `tb7` (
`_year` year DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
【2-1】 插入正常 4 位数年份数字或数字字符串,超出范围会报错。
mysql> insert into tb7 values (1900);
ERROR 1264 (22003): Out of range value for column '_year' at row 1
mysql> insert into tb7 values (1901);
Query OK, 1 row affected (0.01 sec)
mysql> insert into tb7 values (2156);
ERROR 1264 (22003): Out of range value for column '_year' at row 1
mysql> insert into tb7 values (2155);
Query OK, 1 row affected (0.00 sec)
mysql> insert into tb7 values ("1993");
Query OK, 1 row affected (0.01 sec)
mysql> insert into tb7 values ("2023");
Query OK, 1 row affected (0.01 sec)

【2-2】 插入2 位数年份数字、0 和 “0”字符串,会转换为 4 位数年份。
insert into tb7 values (69);
insert into tb7 values (99);
insert into tb7 values (0);
insert into tb7 values ("0");

3、如果未启用严格 SQL 模式,MySQL 会将无效的 YEAR 值转换为 0000。在严格 SQL 模式下,尝试插入无效的 YEAR 值会产生错误。
4、YEAR 类型占用
1 字节。【出处】https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html#data-types-storage-reqs-date-time
2.4.4.8 时间值中的小数秒
【MySQL 8.0 官方文档 - 时间值中的小数秒】:
https://dev.mysql.com/doc/refman/8.0/en/fractional-seconds.html
MySQL 支持 TIME、DATETIME 和 TIMESTAMP 值的小数秒,精度可达微秒(6 位)。
1、要定义包含小数秒部分的列,请使用语法 type_name(fsp),其中 type_name 是 TIME、DATETIME 或 TIMESTAMP,fsp 是小数秒精度。fsp 值(如果给定)必须在 0 到 6 的范围内。值 0 表示没有小数部分。如果省略,则默认精度为 0。(这与标准 SQL 默认值 6 不同,以与以前的 MySQL 版本兼容。)
CREATE TABLE t1 (t TIME(3), dt DATETIME(6));
2、将具有小数秒部分的 TIME、DATE 或 TIMESTAMP 值插入相同类型但具有较少小数位的列会导致四舍五入。发生此类舍入时不会发出警告或错误。此行为遵循 SQL 标准。
CREATE TABLE fractest( c1 TIME(2), c2 DATETIME(2), c3 TIMESTAMP(2) );
INSERT INTO fractest VALUES ('19:28:42.678', '2023-03-24 19:28:42.678', '2023-03-24 19:28:42.678');
SELECT * FROM fractest;

3、启用 TIME_TRUNCATE_FRACTIONAL SQL 模式,时间值将被截断插入。
【3-1】 在当前会话启用 TIME_TRUNCATE_FRACTIONAL ,临时生效,客户端退出连接会失效。
将 TIME_TRUNCATE_FRACTIONAL 添加到 sql_mode 的值中,里面有很多默认参数,以逗号隔开。默认值为:ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION 。
SET @@sql_mode = sys.list_add(@@sql_mode, 'TIME_TRUNCATE_FRACTIONAL');
或者另外一种写法。
SET @@SESSION.sql_mode = sys.list_add(@@sql_mode, 'TIME_TRUNCATE_FRACTIONAL');
查看当前 SESSION 的 sql_mode。
SELECT @@SESSION.sql_mode;

注意!禁止写成下面的语句去设置 TIME_TRUNCATE_FRACTIONAL ,不然会直接覆盖 sql_mode 原来的默认值。
SET sql_mode = 'TIME_TRUNCATE_FRACTIONAL';
【3-2】 往 fractest 表插入数据。可以看到,小数本来是 3 位数(.567),被截断为 2 位数(.56)了。
INSERT INTO fractest VALUES ('19:28:42.567', '2023-03-24 19:28:42.567', '2023-03-24 19:28:42.567');

【3-3】 如果启用 TIME_TRUNCATE_FRACTIONAL ,要保持永久生效,需要将其设置为全局模式。
SET @@GLOBAL.sql_mode = sys.list_add(@@sql_mode, 'TIME_TRUNCATE_FRACTIONAL');
查看全局 GLOBAL 的 sql_mode:
SELECT @@GLOBAL.sql_mode;

注意!禁止写成下面的语句去设置 TIME_TRUNCATE_FRACTIONAL ,不然会直接覆盖 sql_mode 原来的默认值。
SET GLOBAL sql_mode = 'TIME_TRUNCATE_FRACTIONAL';
【3-4】 恢复全局的 sql_mode 默认值。
方法1:直接用默认值覆盖新值,简单粗暴。
SET GLOBAL sql_mode = 'ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
方法2:使用MySQL提供的 list_drop() 函数删除想要删除的参数。官方网址:https://dev.mysql.com/doc/refman/8.0/en/sys-list-add.html
SET @@GLOBAL.sql_mode = sys.list_drop(@@sql_mode, 'TIME_TRUNCATE_FRACTIONAL');
查看全局 GLOBAL 的 sql_mode:
SELECT @@GLOBAL.sql_mode;

2.4.4.9 《高性能MySQL 第4版》存在的 DATETIME 和 TIMESTAMP 描述错误
《高性能MySQL 第4版》第 118 页关于 DATETIME 和 TIMESTAMP 的描述,是有错误的:
DATETIME
这种类型可以保存大范围的数值,从 1000 年到 9999 年,精度为 1 微秒。它以 YYYYMMDDHHMMSS 格式存储压缩成整数的日期和时间,且与时区无关。这需要 8 字节的存储空间。
TIMESTAMP
TIMESTAMP 只使用 4 字节的存储空间,所以它的范围比 DATETIME 小得多。
…
最后,TIMESTAMP 列在默认情况下为 NOT NULL,这也和其他的数据类型不一样。
为什么说书中 DATETIME 内容有错误呢?在 MySQL 8.0 官方文档中提到:DATETIME 类型支持的范围是 “1000-01-01 00:00:00.000000” 到 “9999-12-31 23:59:59.999999”,小数秒精度范围:0 到 6 。DATETIME 类型占用字节也不是 8 bytes,而是 【5 + 小数秒精度存储(0~3 bytes)】,其中 0 精度占 0 字节,1 或 2 精度占 1 字节,3 或 4 精度占 2 字节,5 或 6 精度占 3 字节。【出处】:https://dev.mysql.com/doc/refman/8.0/en/date-and-time-type-syntax.html 和 https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html#data-types-storage-reqs-date-time 。
为什么说书中 TIMESTAMP 内容有错误呢?在 MySQL 8.0 官方文档中提到:TIMESTAMP 类型占用字节不是 4 bytes,而是 【4 + 小数秒精度存储(0~3 bytes)】,其中 0 精度占 0 字节,1 或 2 精度占 1 字节,3 或 4 精度占 2 字节,5 或 6 精度占 3 字节。TIMESTAMP 的默认值为 0,除非使用 NULL 属性定义,在这种情况下默认值为 NULL。由此可知,TIMESTAMP 列在默认情况下并不是 NOT NULL 。【出处】:https://dev.mysql.com/doc/refman/8.0/en/storage-requirements.html#data-types-storage-reqs-date-time 和 https://dev.mysql.com/doc/refman/8.0/en/timestamp-initialization.html 。


2.4.4.10 合适的日期和时间类型
1、如果只需要“年月日”,不需要“时分秒”,建议考虑 DATE 类型,占用 3 字节,节省存储空间。如果只需要“年”,那就更要使用 YEAR 类型,才占用 1 字节。
2、使用 DATETIME 还是 TIMESTAMP ,根据实际情况而定。DATETIME 类型与时区无关,TIMESTAMP 类型与时区有关,如何理解呢?DATETIME 类型的时间(如 2023-03-25 12:50:36)无论服务器是北京时区,还是美国时区,显示都是一样的。TIMESTAMP 类型的时间会随着时区的变化而自动转换为相应的时间。
3、TIMESTAMP 类型占用字节比 DATETIME 类型更小。TIMESTAMP 类型最大年限为 2038-01-19 03:14:07.999999 ,而 DATETIME 类型最大年限为 9999-12-31 23:59:59.999999 。
2.4.5 特殊数据 类型
2.4.5.1 IP地址处理
人们通常使用 VARCHAR(15) 列来存储 IP 地址,这样好吗?
IPv4 地址可被写作任何表示一个32位整数值的形式,但为了方便人类阅读和分析,它通常被写作点分十进制的形式,即四个字节被分开用十进制写出,中间用点分隔。【出处】 维基百科:https://zh.wikipedia.org/wiki/IPv4
IPv6 采用十六进制表示,具有比 IPv4 大得多的编码地址空间。这是因为 IPv6 采用128位的地址,而 IPv4 使用的是32位。因此新增的地址空间支持2128(约3.4×1038)个地址,具体数量为340,282,366,920,938,463,463,374,607,431,768,211,456 个,也可以说成1632个,因为每4位地址(128位分为32段,每段4位)可以取24=16个不同的值。【出处】 维基百科:https://zh.wikipedia.org/wiki/IPv6
MySQL 提供了 INET_ATON(expr)、INET_NTOA(expr)、INET6_ATON(expr)、INET6_NTOA(expr) 四种函数来处理 IPv4 和 IPv6 ,其中 expr 是表达式。官方关于函数功能说明:https://dev.mysql.com/doc/refman/8.0/en/miscellaneous-functions.html 。
2.4.5.1.1 INET_ATON(expr) 函数
【INET_ATON(expr) 函数】
https://dev.mysql.com/doc/refman/8.0/en/miscellaneous-functions.html#function_inet-aton
给定 IPv4 网络地址的 点分四边形(dotted-quad) 表示形式的字符串,例如 “192.168.56.1”,返回一个整数,该整数表示网络字节顺序(大端)中地址的数值。如果 INET_ATON() 不理解其参数,或者如果 expr 为 NULL,则 INET_ATON() 返回 NULL。
要存储由 INET_ATON() 生成的值,请
使用 INT UNSIGNED 列而不是已签名的 INT。如果使用带符号的列,则无法正确存储与第一个八位字节大于 127 的 IP 地址对应的值。
创建一个表 tb1 ,字段名为 ip ,类型为无符号INT类型。如下:
CREATE TABLE `tb1` (
`ip` int unsigned DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
使用 INET_ATON() 函数将 IPv4 地址转换成数值并插入到 ip 字段。
insert into tb1 values (inet_aton('192.168.56.1'));

对于此示例,返回值计算为 192×2563 + 168×2562 + 56×256 + 1 = 3232249857。
 )
)
INET_ATON() 函数会校验 IPv4 是否合法,不合法的 IPv4 会报错。如下:

2.4.5.1.2 INET_NTOA(expr) 函数
【INET_NTOA(expr) 函数】
https://dev.mysql.com/doc/refman/8.0/en/miscellaneous-functions.html#function_inet-ntoa
给定网络字节顺序的数字 IPv4 网络地址,返回地址的 点分四字符串(dotted-quad string) 表示形式作为连接字符集中的字符串。如果 INET_NTOA() 不理解其参数,则返回 NULL。
使用 INET_NTOA() 函数将数值转换成字符串形式的 IPv4 地址。
select inet_ntoa(ip) as ip_str from tb1;

INET_NTOA() 函数会解析参数是否为有效地址,不能解析的参数会返回 NULL。如下:

2.4.5.1.3 INET6_ATON(expr) 函数
【INET6_ATON(expr) 函数】
https://dev.mysql.com/doc/refman/8.0/en/miscellaneous-functions.html#function_inet6-aton
给定一个字符串形式的 IPv6 或 IPv4 网络地址,返回一个二进制字符串,该字符串表示网络字节顺序(大端)中地址的数值。因为数字格式的 IPv6 地址需要比最大整数类型更多的字节,所以此函数返回的表示具有 VARBINARY 数据类型:VARBINARY(16) 用于 IPv6 地址,VARBINARY(4) 用于 IPv4 地址。如果参数不是有效地址,或者它为 NULL,则 INET6_ATON() 返回 NULL。
使用 HEX() 以可打印形式显示 INET6_ATON() 结果:
SELECT HEX(INET6_ATON('fdfe::5a55:caff:fefa:9089'));
SELECT HEX(INET6_ATON('10.0.5.9'));

INET6_ATON() 对有效参数的几个约束。如下:
- A trailing zone ID is not permitted, as in fe80::3%1 or fe80::3%eth0.
不允许使用尾随区域 ID,如 fe80::3%1 或 fe80::3%eth0。
- A trailing network mask is not permitted, as in 2001:45f:3:ba::/64 or 198.51.100.0/24.
不允许使用尾随网络掩码,如 2001:45f:3:ba::/64 或 198.51.100.0/24。
- For values representing IPv4 addresses, only classless addresses are supported. Classful addresses such as 198.51.1 are rejected. A trailing port number is not permitted, as in 198.51.100.2:8080. Hexadecimal numbers in address components are not permitted, as in 198.0xa0.1.2. Octal numbers are not supported: 198.51.010.1 is treated as 198.51.10.1, not 198.51.8.1. These IPv4 constraints also apply to IPv6 addresses that have IPv4 address parts, such as IPv4-compatible or IPv4-mapped addresses.
对于表示 IPv4 地址的值,仅支持无类地址。拒绝 198.51.1 等有类地址。不允许使用尾随端口号,例如 198.51.100.2:8080。地址组件中不允许使用十六进制数字,如 198.0xa0.1.2。不支持八进制数:198.51.010.1 被视为 198.51.10.1,而不是 198.51.8.1。这些 IPv4 约束也适用于具有 IPv4 地址部分的 IPv6 地址,例如 IPv4 兼容地址或 IPv4 映射地址。
要将以数字形式表示为 INT 值的 IPv4 地址 expr 转换为以数字形式表示为 VARBINARY 值的 IPv6 地址,请使用以下表达式:INET6_ATON(INET_NTOA(expr))
SELECT HEX(INET6_ATON(INET_NTOA(167773449)));

如果从 mysql 客户端中调用 INET6_ATON(),二进制字符串将使用十六进制表示法显示,具体取决于 –binary-as-hex 的值。
创建一个表 tb2 ,字段名为 ipv6 ,类型为 VARBINARY(16) 。如下:
CREATE TABLE `tb2` (
`ipv6` varbinary(16) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
使用 INET6_ATON() 函数将 IPv6 地址转换成数值并插入到 ipv6 字段。
insert into tb2 values (inet6_aton('fdfe::5a55:caff:fefa:9089'));

INET6_ATON() 函数会校验 IPv6 是否合法,不合法的 IPv6 会报错。如下:

2.4.5.1.4 INET6_NTOA(expr) 函数
【INET6_NTOA(expr) 函数】
https://dev.mysql.com/doc/refman/8.0/en/miscellaneous-functions.html#function_inet6-ntoa
给定以数字形式表示为二进制字符串的 IPv6 或 IPv4 网络地址,返回地址的字符串表示形式作为连接字符集中的字符串。如果参数不是有效地址,或者它为 NULL,则 INET6_NTOA() 返回 NULL。
INET6_NTOA() 具有以下属性:
- It does not use operating system functions to perform conversions, thus the output string is platform independent.
它不使用操作系统函数来执行转换,因此输出字符串与平台无关。
- The return string has a maximum length of 39 (4 x 8 + 7). Given this statement:
返回字符串的最大长度为 39 (4 x 8 + 7)。鉴于此声明:
CREATE TABLE t AS SELECT INET6_NTOA(expr) AS c1;
CREATE TABLE t (c1 VARCHAR(39) CHARACTER SET utf8mb3 DEFAULT NULL);
- The return string uses lowercase letters for IPv6 addresses.
返回字符串对 IPv6 地址使用小写字母。
mysql> SELECT INET6_NTOA(INET6_ATON(‘fdfe::5a55:caff:fefa:9089’));
-> ‘fdfe::5a55:caff:fefa:9089’
mysql> SELECT INET6_NTOA(INET6_ATON(‘10.0.5.9’));
-> ‘10.0.5.9’
mysql> SELECT INET6_NTOA(UNHEX(‘FDFE0000000000005A55CAFFFEFA9089’));
-> ‘fdfe::5a55:caff:fefa:9089’
mysql> SELECT INET6_NTOA(UNHEX(‘0A000509’));
-> ‘10.0.5.9’

使用 INET6_NTOA() 函数将二进制字符串转换成普通字符串形式的 IPv6 地址。
select inet6_ntoa(ipv6) as ipv6_str from tb2;

如果从 mysql 客户端中调用 INET6_NTOA(),二进制字符串将使用十六进制表示法显示,具体取决于 –binary-as-hex 的值。
INET6_NTOA() 函数会解析参数是否为有效地址或为 NULL,不能解析的参数或 NULL 会返回 NULL。如下:

2.4.5.1.5 合适的特殊数据类型
1、对于存储 IP地址 这类特殊的数据类型,如果是 IPv4 ,需要使用无符号INT类型去存储。如果是 IPv6,使用 VARBINARY 类型去存储。使用 VARCHAR 类型除了占用空间大,没有任何优势。
2、使用 MySQL 自带的 INET_ATON() 和 INET6_ATON() 函数会校验 IP地址 的合法性,如果是 VARCHAR 类型,即使存储的 IP地址 是无效的,也很容易被忽略。
三、总结
对于如何选择合适的数据类型,笔者我根据深入研究MySQL数据类型和实际的工作经验总结出以下内容,不一定是正确的,读者可自行斟酌。
1、如果值在[-128,255] 内,选择 TINYINT 整数类型优于其它整数类型(SMALLINT、MEDIUMINT、INT、BIGINT)。
2、如果对存储的实数数值精度没有要求,那就建议使用 FLOAT 类型,占用 4 字节,更省空间,使用 DOUBLE 没有任何优势。
3、如果存储的实数数值对精度要求高(精确计算),那就使用 DECIMAL 或 BIGINT 。对于财务数据,在数据量比较大的时候,建议使用 BIGINT 代替 DECIMAL(因为 DECIMAL 精确计算代价高),将需要存储的货币单位根据小数的位数乘以相应的倍数即可。
4、如果要存储的字符串是定长的,使用 CHAR 类型更省空间,查询性能比 VARCHAR 要好。
5、如果存储的字符串字符长度不确定,那就使用 VARCHAR 类型,注意要预估字符串的大概长度,不要设置太大的字符串长度,分配合理的长度大小就好。
6、如果要存储大量字符串,例如网页内容、文章、博客等,可以考虑 TEXT 类型而不是 VARCHAR 类型。《阿里巴巴Java开发手册》中强制要求,字符长度超过 5000 个字符,使用 TEXT 类型,独立出来一张表,用主键来对应,避免影响其它字段的索引效率。
7、图像、音视频等媒体文件属于二进制文件,不适合用文本存储,虽然可以使用 BLOB 类型存储,但是更好的做法是放到文件系统或对象存储服务器上(例如阿里云的OSS、腾讯云的COS等),将文件路径存入到数据库。
8、如果要存储 性别属性,可以定义 ENUM(‘男’,‘女’),只允许这两个选项之一。如果要存储 类别属性,可以定义 ENUM(‘待支付’,‘已支付’,‘已完成’)。如果要存储 状态属性,可以定义 ENUM(‘未验证’,‘已验证’) 。
9、完全可以使用 TINYINT(1) 来替代 ENUM ,我在实际开发中使用得最多的还是 TINYINT(1),和前端交互比较友好些。
10、如果只需要“年月日”,不需要“时分秒”,建议考虑 DATE 类型,占用 3 字节,节省存储空间。如果只需要“年”,那就更要使用 YEAR 类型,才占用 1 字节。
11、使用 DATETIME 还是 TIMESTAMP ,根据实际情况而定。DATETIME 类型与时区无关,TIMESTAMP 类型与时区有关,如何理解呢?DATETIME 类型的时间(如 2023-03-25 12:50:36)无论服务器是北京时区,还是美国时区,显示都是一样的。TIMESTAMP 类型的时间会随着时区的变化而自动转换为相应的时间。
12、TIMESTAMP 类型占用字节比 DATETIME 类型更小。TIMESTAMP 类型最大年限为 2038-01-19 03:14:07.999999 ,而 DATETIME 类型最大年限为 9999-12-31 23:59:59.999999 。
13、对于存储 IP地址 这类特殊的数据类型,如果是 IPv4 ,需要使用无符号INT类型去存储。如果是 IPv6,使用 VARBINARY 类型去存储。使用 VARCHAR 类型除了占用空间大,没有任何优势。
14、使用 MySQL 自带的 INET_ATON() 和 INET6_ATON() 函数会校验 IP地址 的合法性,如果是 VARCHAR 类型,即使存储的 IP地址 是无效的,也很容易被忽略。
四、资料参考
1、《高性能MySQL》第 3 版、第 4 版
2、《阿里巴巴Java开发手册》第 2 版
3、MySQL 8.0 官方文档:https://dev.mysql.com/doc/refman/8.0/en/data-types.html