MybatisPlus学习
一.引言
MybatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工具,旨在简化开发、提供效率。根据所学知识,有以下三种开发方式 :
基于MyBatis使用MyBatisPlus
基于Spring使用MyBatisPlus
基于SpringBoot使用MyBatisPlus
首先Mybatis基于boot整合时的步骤如下
1.创建boot工程,勾选所需要的技术
2.设置dataSource相关的属性
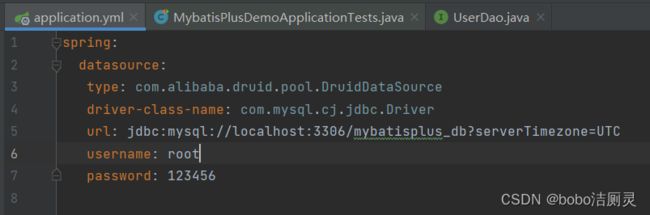
3.定义数据层接口映射配置(UserDao)

二.Boot整合MybatisPlus步骤
1.创建Boot工程,勾选所需技术

由于MP并未被收录到idea的系统内置配置,无法直接选择加入,需要手动在pom.xml中配置添加
2.pom文件导入依赖
com.baomidou
mybatis-plus-boot-starter
3.4.1
从MP的依赖关系可以看出,通过依赖传递已经将MyBatis与MyBatis整合Spring的jar包导入, 所以不需要额外在添加MyBatis的相关jar包
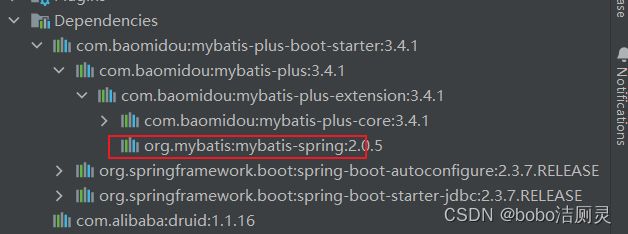
3.添加配置信息
修改resource文件夹下的application.propertes为application.yml文件

4.根据数据库创建实体类User
在domain路径下创建User类
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
//getter,setter,toString方法
}5.在dao路径下创建UserDao接口(数据层操作接口)
继承BaseMapper
@Mapper
public interface UserDao extends BaseMapper {
} 6.测试类下测试dao功能
自动装配UserDao
编写测试功能
@SpringBootTest
class MybatisPlusDemoApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll() {
List userList = userDao.selectList(null);
System.out.println(userList);
}
} 这一步可以发现,userDao中因为继承BaseMapper,可以选择很多方法
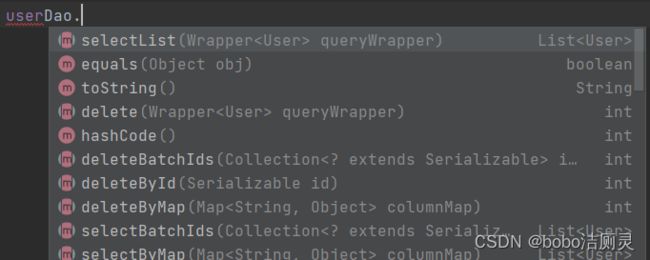
总结:MP的开发过程中,和mybatis不同在于数据层接口需要继承BaseMapper<>,不需要手动写增删改查语句了
三.MP数据层开发
数据层开发的需要实现的功能是增删改查,也就是标准CRUD(增删改查)开发。
对于标准的CRUD功能开发,MP提供了以下的方法来实现

1.新增
对应了MP中提供的insert()方法,
@Test
void testSave() {
User user = new User();
user.setName("黑马程序员");
user.setPassword("itheima");
user.setAge(12);
user.setTel("4006184000");
userDao.insert(user);
}
在新增功能中,没有set对应的id,此时会自动生成一个id,但是不会对应主键自增,这是MP的主键生成策略。
2.删除
int deleteById (Serializable id)参数类型是一个序列化类Serializable,
String和Number是Serializable的子类,Number又是Float,Double,Integer等类的父类
MP使用Serializable作为参数类型,就好比我们可以用Object接收任何数据类型一样。
@Test
void testDelete() {
userDao.deleteById(1401856123725713409L);
}3.修改
@Test
void testUpdate() {
User user = new User();
user.setId(1L);
user.setName("Tom888");
user.setPassword("tom888");
userDao.updateById(user);
}updateById()是根据Id进行修改,所以传入的对象中需要有Id属性值
4.根据id查询
@Test
void testGetById() {
User user = userDao.selectById(2L);
System.out.println(user);
}
5.全部查询
selectList()方法返回的是一个List类型的数据
@Test
void testGetAll() {
List userList = userDao.selectList(null);
System.out.println(userList);
} 6.分页查询
selectPage() ,查看源码(ctrl+鼠标左键)发现,这个方法返回的是一个Ipage对象

所以我们先定义一个IPage对象,但是IPage是一个接口无法创建对象,所以需要一个IPage的实现类,查看IPage的源码(ctrl+alt+b)
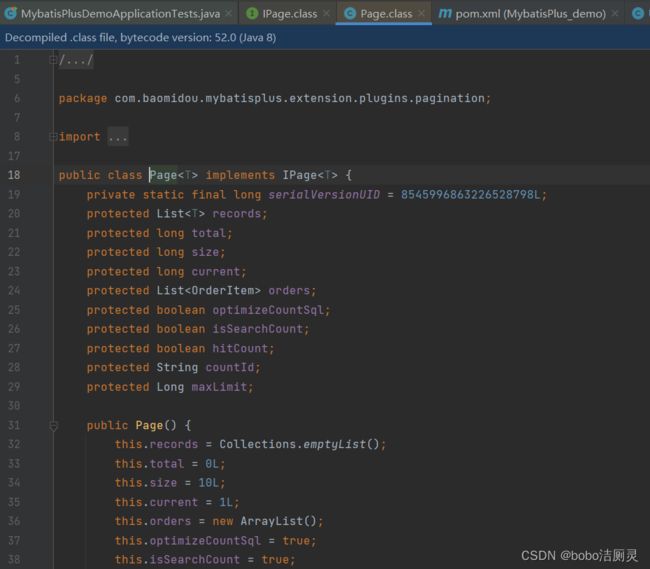
发现其实现类只有一个Page,那么就用Page实现类来实现Ipage。
将实现的Ipage传入selectPage()方法中,实现按页查询。
Ipage中存在的查询方法如下
//分页查询
@Test
void testSelectPage(){
//1 创建IPage分页对象,设置分页参数,1为当前页码,2为每页显示的记录数
IPage page=new Page<>(1,2);
//2 执行分页查询
userDao.selectPage(page,null);
//3 获取分页结果
System.out.println("当前页码值:"+page.getCurrent());
System.out.println("每页显示数:"+page.getSize());
System.out.println("一共多少页:"+page.getPages());
System.out.println("一共多少条数据:"+page.getTotal());
System.out.println("数据:"+page.getRecords());
}
执行后发现,还是将所有的数据查询了出来 ,按照参数应该查询第一页的两条数据。

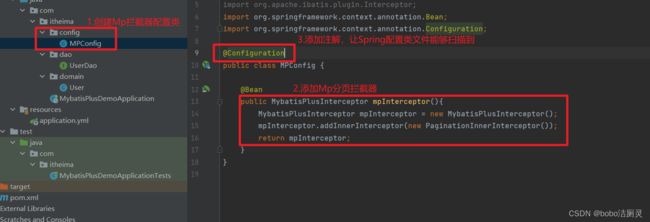
设置分页拦截器即可解决以上问题,MP已经将拦截器设置好,我们只需配置成Spring管理的Bean对象即可。
配置类的写法
修改配置文件,打开MP执行的SQL日志
#打印sql日志到控制台
mybatis-plus:
configuration:
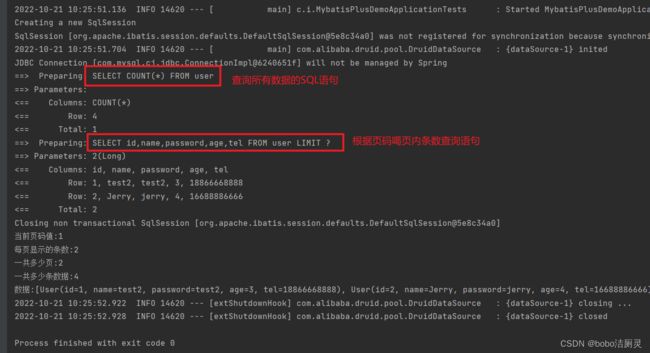
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl再次运行测试类,就可以看到SQL日志
select id,name,password,age,tel from user limit ?,?
//根据页码参数查询,limit?,?表示需要进行两次运算,查询第?(>1)页,
limit?表示查询第一页。
四.Lombok
Lombok是一个java库,提供了一组注解,简化了POJO实体类开发
就是实体类中的getter,setter,toString,构造函数方法,私有属性可以在Lombok的帮助下,不用书写了
1.添加Lombok依赖
pom文件中导入lombok坐标
2.实体类中添加lombok注解
@Setter
@Getter
@ToString
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
}
@Setter:为模型类的属性提供setter方法
@Getter:为模型类的属性提供getter方法
@ToString:为模型类的属性提供toString方法
@EqualsAndHashCode:为模型类的属性提供equals和hashcode方法
@Data:是个组合注解,包含上面的注解的功能
@NoArgsConstructor:提供一个无参构造函数
@AllArgsConstructor:提供一个包含所有参数的构造函数
Lombok的注解还有很多,最后三个是比较常用的。
当然,也可以使用自己编写的构造方法和Lombok注解同时存在。
自己定义一个有参的构造方法,同时也存在Lombok插件的案例如下:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
public User(String name, String password) {
this.name = name;
this.password = password;
}
}五.DQL编程控制
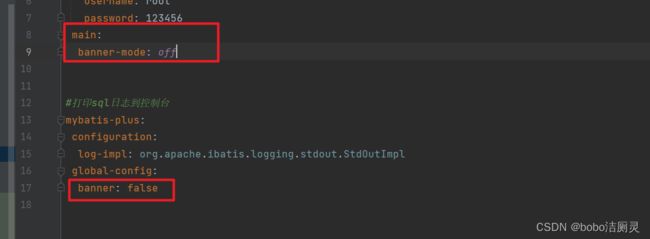
1.取消Spring初始日志打印
新建logback.xml文件

2.取消Spring日志打印banner,取消Mp日志启动banner
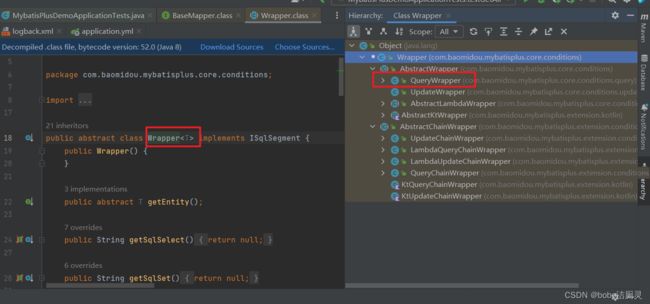
3.Wrapper条件查询
查看接口的实现类:ctrl H
实现类也有很多,说明有多种构建查询条件对象的方式,
第一种
lt;小于
//按条件查询
QueryWrapper qw = new QueryWrapper();
//SELECT id,name,password,age,tel FROM user WHERE (age < ?),lt:小于,
qw.lt("age",18);
List userList = userDao.selectList(qw);
System.out.println(userList); 第二种;lambda方式,改善了条件语句种参数容易写错的问题(注意泛型)
//lambda按条件查询
QueryWrapper qw = new QueryWrapper();
qw.lambda().lt(User::getAge,10);
List userList = userDao.selectList(qw);
System.out.println(userList); 第三种:在QueryWrapper基础上升级的lambda方式
省去了qw后需要调用一层lambda()的方式
注意:构建LambdaQueryWrapper的时候泛型不能省。
LambdaQueryWrapper lqw = new LambdaQueryWrapper();
lqw.lt(User::getAge,10);
List userList = userDao.selectList(lqw);
System.out.println(userList); 4.多条件构建
需求:查询数据库表中,年龄在10岁到30岁之间的用户信息
解决方案:
SQL语句是:SELECT id,name,password,age,tel FROM user WHERE (age < ? AND age > ?)gt:大于,lt:小于
在Mp的语言规范中,实现以上sql的语法是
//多条件查询
LambdaQueryWrapper lqw = new LambdaQueryWrapper();
lqw.lt(User::getAge,30);
lqw.gt(User::getAge,10);
//构建多条件查询,可以使用链式编程
//lqw.lt(User::getAge, 30).gt(User::getAge, 10);
List userList = userDao.selectList(lqw);
System.out.println(userList); 需求:查询数据库表中,年龄小于10或年龄大于30的数据
以上需求的SQL语句是:
SELECT id,name,password,age,tel FROM user WHERE (age < ? OR age > ?)
转化为Mp风格是
LambdaQueryWrapper lqw = new LambdaQueryWrapper();
lqw.lt(User::getAge, 10).or().gt(User::getAge, 30);
List userList = userDao.selectList(lqw);
System.out.println(userList); 5.NULL判定
一般查询会在后台做两个条件,如果查询只给了一个条件,即小于**但是大于未输入,大于**但是小于未输入。
这时候未输入的条件就是空值,我们就需要做空值判定 ,否则就会出现问题
//模拟页面传递过来的查询数据
UserQuery uq = new UserQuery();
//模拟null值传入
//uq.setAge(10);
uq.setAge2(30);
//多条件查询
LambdaQueryWrapper lqw = new LambdaQueryWrapper();
lqw.lt(User::getAge,uq.getAge2()).gt(User::getAge,uq.getAge());
List userList = userDao.selectList(lqw);
System.out.println(userList); 报错如下
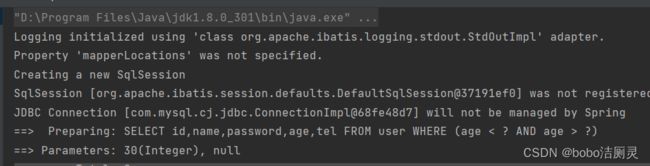
所以要进行null值判断
//模拟页面传递过来的查询数据
UserQuery uq = new UserQuery();
// uq.setAge(10);
uq.setAge2(30);
//多条件查询
LambdaQueryWrapper lqw = new LambdaQueryWrapper();
//先判断第一个参数是不是ture,如果是true再连接语句
lqw.lt(null!=uq.getAge2(),User::getAge, uq.getAge2());
lqw.gt(null!=uq.getAge(),User::getAge, uq.getAge());
List userList = userDao.selectList(lqw);
System.out.println(userList); 6.查询投影
如果想在数据库中查询某些字段,可以使用投影查询
6.1查询指定字段
//查询投影,使用lambda风格
LambdaQueryWrapper lqw = new LambdaQueryWrapper();
lqw.select(User::getName);
List userList = userDao.selectList(lqw);
System.out.println(userList);
//不使用lambda风格
QueryWrapper qw = new QueryWrapper();
qw.select("name");
List userList = userDao.selectList(qw);
System.out.println(userList); 差距就是lambda风格是直接使用方法对字段进行查询,无需知道字段名
直接使用select需要知道字段名才能进行查询
6.2聚合查询
count:总记录数 max:最大值 min:最小值 avg:平均值 sum:求和
QueryWrapper lqw = new QueryWrapper();
//lqw.select("count(*) as count");
//SELECT count(*) as count FROM user
//lqw.select("max(age) as maxAge");
//SELECT max(age) as maxAge FROM user
//lqw.select("min(age) as minAge");
//SELECT min(age) as minAge FROM user
//lqw.select("sum(age) as sumAge");
//SELECT sum(age) as sumAge FROM user
lqw.select("avg(age) as avgAge");
//SELECT avg(age) as avgAge FROM user
List> userList = userDao.selectMaps(lqw);
System.out.println(userList); // 聚合查询
QueryWrapper qw = new QueryWrapper();
qw.select("count(*) as count,age");
qw.groupBy("age");
// List userList = userDao.selectList(qw);
List> userList2 = userDao.selectMaps(qw);
System.out.println(userList2); 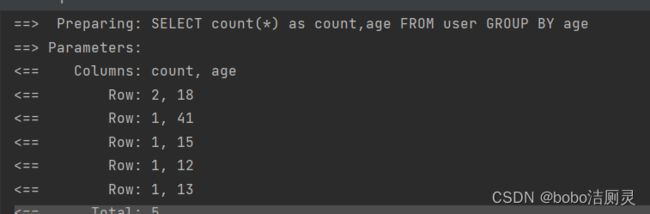
聚合与分组查询,无法使用lambda表达式来完成
MP只是对MyBatis的增强,如果MP实现不了,我们可以直接在DAO接口中使用MyBatis的方式实 现
7.查询条件
7.1等值查询
例如,登录时想要验证用户名和密码,这时候可以使用等值查询
//条件查询
LambdaQueryWrapper lqw = new LambdaQueryWrapper();
lqw.eq(User::getName,"Jerry").eq(User::getPassword,"jerry1");
User loginuser = userDao.selectOne(lqw);
System.out.println(loginuser); .eq()方法,相当于sql语句中的
SELECT id,name,password,age,tel FROM user WHERE (name = ? AND password = ?)7.2范围查询
LambdaQueryWrapper lqw = new LambdaQueryWrapper();
lqw.between(User::getAge, 10, 30);
List userList = userDao.selectList(lqw);
System.out.println(userList); .between()对应sql
//SELECT id,name,password,age,tel FROM user WHERE (age BETWEEN ? AND
?)gt():大于(>)
ge():大于等于(>=)
lt():小于(<)
lte():小于等于(<=)
between():between ? and ?
7.3模糊查询
查询名字是J开头的信息
LambdaQueryWrapper lqw = new LambdaQueryWrapper();
lqw.likeLeft(User::getName, "J");
//SELECT id,name,password,age,tel FROM user WHERE (name LIKE ?)
List userList = userDao.selectList(lqw);
System.out.println(userList); 对应到sql中的模糊查询:
like():前后加百分号,如 %J%
likeLeft():前面加百分号,如 %J
likeRight():后面加百分号,如 J%
后续的条件查询还有很多中,如有需要,查阅官方文档
https://mp.baomidou.com/guide/wrapper.html#abstractwrapper
六.后端和数据库映射匹配兼容性
我们建立的模型类中封装了属性,这些属性恰好是和数据库中的字段对应的,但是如果模型类的属性名和数据库中的字段名不一致,无法获取对象并封装到模型类中,这时候可以通过MP的注解来解决
6.1表名不一致
@TableName
如果模型类是User类,MP默认情况下会使用模型类的类名首字母小写当表名使用,那么就会直接查询user表,但是数据库中存在的是t_user,所以使用@TableName注解
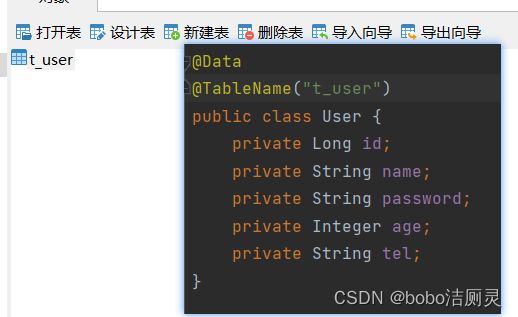
6.2表中字段不一致
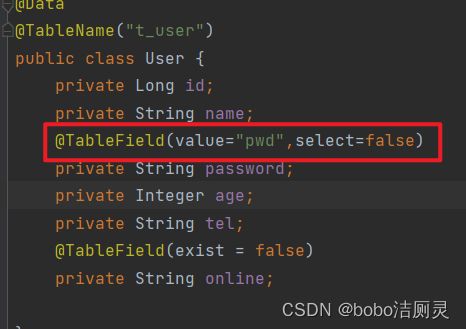
MP默认情况下会使用模型类的属性名当做表的列名使用,如果表中的字段不是password,可以使用@TableField()注解
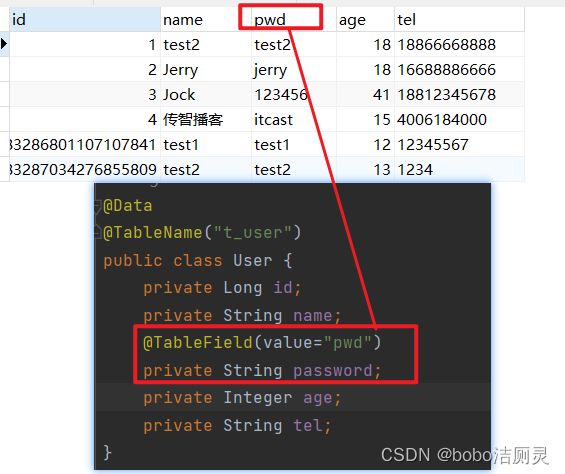
6.3数据库中不存在对应属性
MP默认情况下会查询模型类的所有属性对应的数据库表的列,这个时候如果模型类中存在某个字段,但数据库中不存在,就会报错
@TableField(exist=false)
使用该注解排除字段

6.4隐藏查询字段
如果存在某些敏感属性,不想在查询中展示出来,同样使用注解

七.Id生成策略控制 (@TableId)
在前面的操作中,如果我们新增一条记录,这个时候不指定id的话,id的值会是一段很长的字符串,如果想要按照数据库表字段进行自增长,可以在数据库更改选项,设置自动递增的起始值,注意表中不能存在比起始值更大的数值。
如果无法修改这个选项,可以运行以下命令
ANALYZE TABLE 'table_name'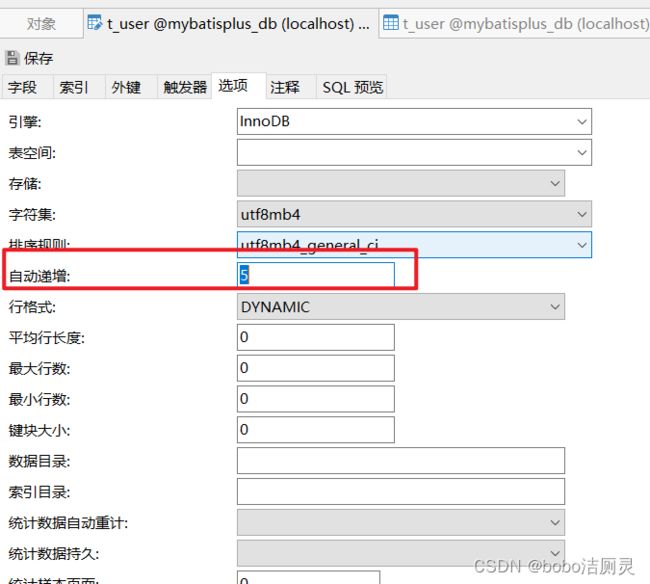
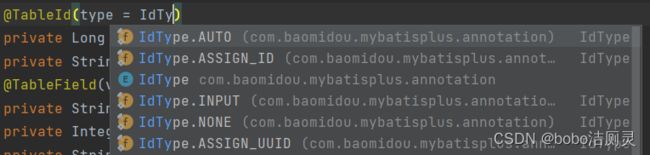
然后修改模型类,用到注解@TableId,这个注解的功能是设置主键属性的生成策略,生成策略根据实际需求可以存在多种,例如

根据不同的需求,模型类中可以添加不同的注解
7.1.AUTO生成策略
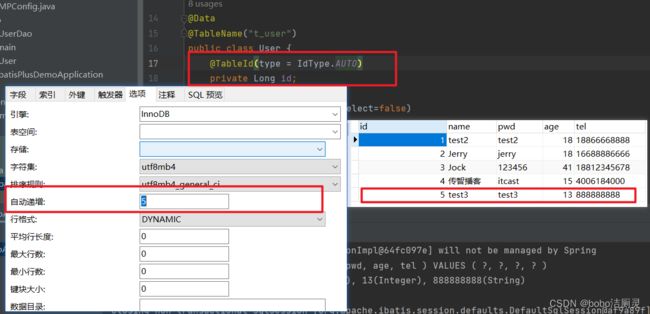
设置为数据库中默认的自动增长 ,根据数据库中的自动递增选项作为初值,我们插入记录时,主键根据这个初值自动递增。
要确保对应的 数据库表设置了ID主键自增,否则无效
查看其他的策略用法,进入源码,如果没有中文注释,点击右上角的Download Sources ,会自动把这个类的java文件下载下来,就能看到具体的注释内容。

NONE: 不设置id生成策略
INPUT:用户手工输入id
ASSIGN_ID:雪花算法生成id(可兼容数值型与字符串型)
ASSIGN_UUID:以UUID生成算法作为id生成策略
其他的几个策略均已过时,都将被ASSIGN_ID和ASSIGN_UUID代替掉。如下图已过时

7.2 INPUT生成策略
input生成策略是自己输入id,这个时候
1.需要修改数据库设置,将id的主键 自动递增选项关闭
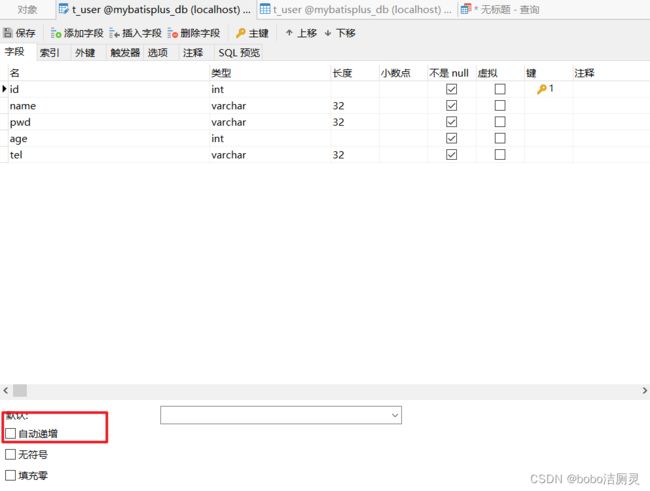
2.手动输入id

7.3 ASSIGN_ID生成策略
1.修改生成策略是ASSIGN_ID
不需要手动设置id

7.4 ASSIGN_UUID
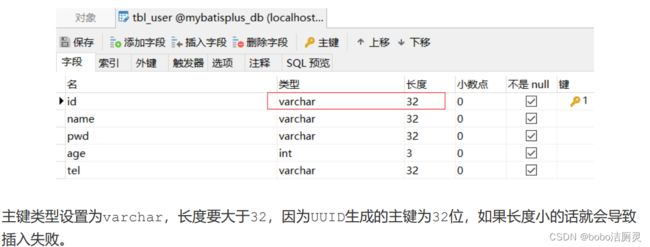
使用uuid需要注意的是,主键的类型不能是Long,而应该改成String类型
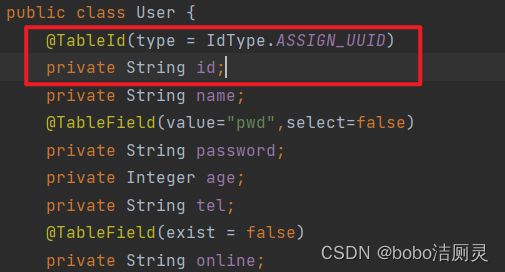
数据库中更改设置

7.5雪花算法
雪花算法(SnowFlake),是Twitter官方给出的算法实现, 是用Scala写的。其生成的结果是一个64bit大小整数,它的结构如下图:

1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数, 所以最高位固定为0。
2. 41bit-时间戳,用来记录时间戳,毫秒级
3. 10bit-工作机器id,用来记录工作机器id,其中高位5bit是数据中心ID其取值范围0-31,低位 5bit是工作节点ID其取值范围0-31,两个组合起来最多可以容纳1024个节点
4. 序列号占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096 个ID
生成策略分析
根据以下分析,确定使用何种生成策略
NONE: 不设置id生成策略,MP不自动生成,约等于INPUT,所以这两种方式都需要用户手动设 置,但是手动设置第一个问题是容易出现相同的ID造成主键冲突,为了保证主键不冲突就需要做很 多判定,实现起来比较复杂
AUTO:数据库ID自增,这种策略适合在数据库服务器只有1台的情况下使用,不可作为分布式ID使用
ASSIGN_UUID:可以在分布式的情况下使用,而且能够保证唯一,但是生成的主键是32位的字符 串,长度过长占用空间而且还不能排序,查询性能也慢
ASSIGN_ID:可以在分布式的情况下使用,生成的是Long类型的数字,可以排序性能也高,但是 生成的策略和服务器时间有关,如果修改了系统时间就有可能导致出现重复主键 综上所述,每一种主键策略都有自己的优缺点,根据自己项目业务的实际情况来选择使用才是最明 智的选择
7.6 简化配置
1.如果存在多个模型类,所有的模型类都是用一种生成策略
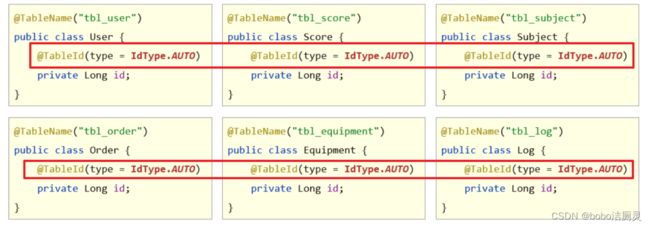
可以在配置文件中添加配置,让所有的模型类都用相同的主键生成策略
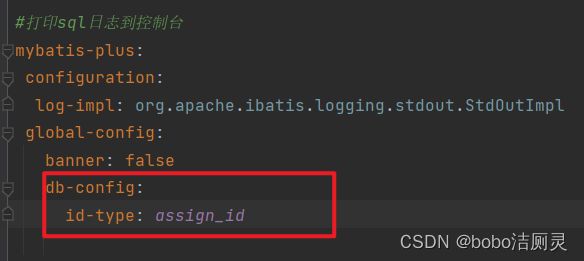
这样所有的模型类中的@TableId可以不用写了
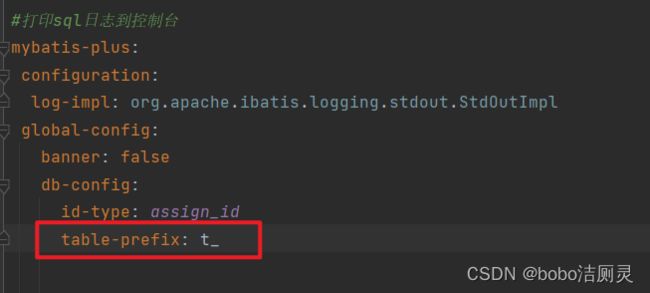
2.数据库表和模型类是存在映射关系的
一般在数据库中存在的都是相同的前缀
MP会默认将模型类的类名名首字母小写作为表名使用,假如数据库表的名称都以t_开头,那么我们 就需要将所有的模型类上添加@TableName

在配置类中添加以下配置,模型类中的@TableName可以不用写了
八. 多记录操作
可以单独删除一条数据,单独查看,增加一条数据。如果想一次操作多条数据,可以使用BatchIds操作
8.1 删除多条数据
@Test
void testDelete(){
List list = new ArrayList<>();
list.add(1589814053571514370L);
list.add(1589819565230788610L);
userDao.deleteBatchIds(list);
} deleteBatchIds需要的是一个list类型的参数,所以首先定义一个list,然后将需要操作的记录的id加入list中,再执行方法,就可以批量操作记录
8.2 查询多条数据
@Test
void testGetByIds(){
//查询指定多条数据
List list = new ArrayList<>();
list.add(1L);
list.add(3L);
list.add(4L);
userDao.selectBatchIds(list);
} 九.逻辑删除
当数据库中存在多张表时,多张表会存在关联字段,设置外键之后,删除一张表中的某个记录,会把其他表的关联字段的记录同时删除。
如果我们需要其他表的字段数据记录,就不能使用这种删除方式。
例如以下案列

这是一个员工和其所签的合同表,关系是一个员工可以签多个合同,是一个一(员工)对多(合同) 的表
员工ID为1的张业绩,总共签了三个合同,如果此时他离职了,我们需要将员工表中的数据进行删除,
会执行delete操作 如果表在设计的时候有主外键关系,那么同时也得将合同表中的前三条数据也删除掉
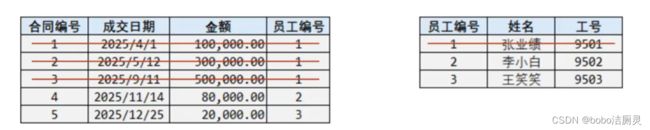
后期要统计所签合同的总金额,就会发现对不上,原因是已经将员工1签的合同信息删除掉了
如果只删除员工不删除合同表数据,那么合同的员工编号对应的员工信息不存在,那么就会出现垃圾数据,就会出现无主合同,根本不知道有张业绩这个人的存在
所以经过分析,我们不应该将表中的数据删除掉,而是需要进行保留,但是又得把离职的人和在职的人进行区分,这样就解决了上述问题,如:
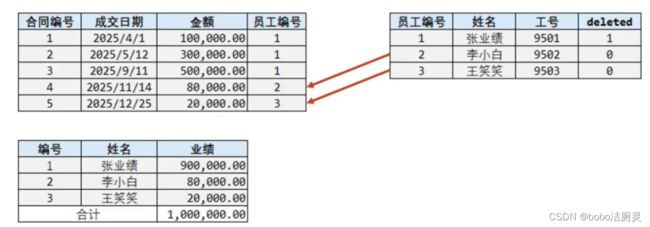
区分的方式,就是在员工表中添加一列数据deleted,如果为0说明在职员工,如果离职则将其改为1(0和1所代表的含义是可以自定义的)
物理删除:业务数据从数据库中丢弃,执行的是delete操作
逻辑删除(logic):为数据设置是否可用状态字段,删除时设置状态字段为不可用状态,数据保留在数据库 中,执行的是update操作
实现步骤
1.修改数据库表结构,添加逻辑字段
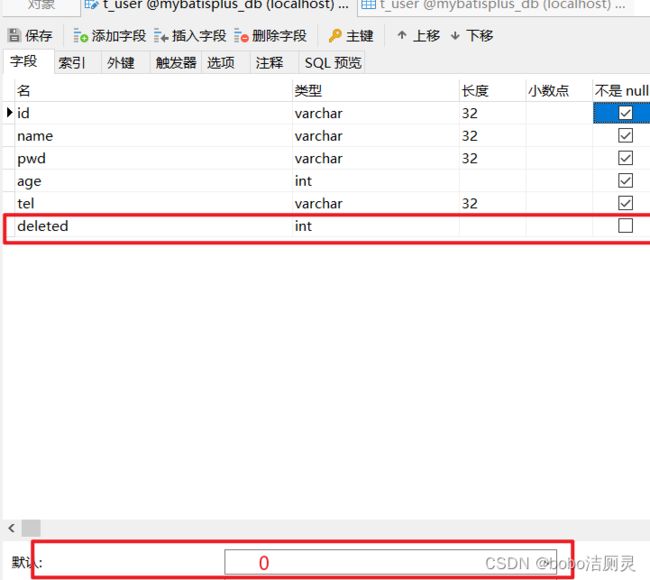
2.修改模型类,添加属性值
//逻辑删除的默认值,value为正常数据,delval为删除数据
@TableLogic(value = "0",delval = "1")
private Integer deleted;3.运行delete方法

发现.delete()方法使用的是update语句,会将指定的字段修改成删除状态对应的逻辑值
思考:
1.逻辑删除后,再进行查询出现什么情况
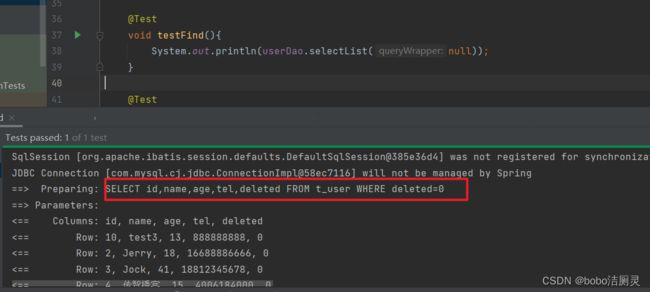
查询会自带一个where限制,不会显示将已经被删除掉的数据
如果想要查询所有数据,包括被删除的数据:
在userDao中定义一个查询全部的方法,在测试类中进行实现即可
@Mapper
public interface UserDao extends BaseMapper {
@Select("select * from t_user")
public List selectAll();
} @Test
void selectAll(){
System.out.println(userDao.selectAll());
}2.如果每个表都有逻辑删除,每个模型类都要添加@TableLogic(),可以使用修改全局配置来简化代码
#逻辑删除字段名
logic-delete-field: deleted
#逻辑删除字面值:为删除为0
logic-not-delete-value: 0
#逻辑删除字面值:删除为1
logic-delete-value: 1添加以上配置后,模型类中的注解就可以删除。
十.乐观锁
“锁”是用来处理并发问题的,乐观锁是用来防止一个记录在被a修改的同时,不被b修改
业务并发现象带来的问题:秒杀
假如有100个商品或者票在出售,为了能保证每个商品或者票只能被一个人购买,如何保证不会出现超买或者重复卖 对于这一类问题,其实有很多的解决方案可以使用
第一个最先想到的就是锁,锁在一台服务器中是可以解决的,但是如果在多台服务器下锁就没有办法控制,比如12306有两台服务器在进行卖票,在两台服务器上都添加锁的话,那也有可能会导致在同一时刻有两个线程在进行卖票,还是会出现并发问题
乐观锁这种方式是针对于小型企业的解决方案,因为数据库本身的性能就是个瓶颈,如果对其并发量超过2000以上的就需要考虑其他的解决方案了。
实现思路:
1.数据库中添加字段version,比如默认值给1
2.a线程修改数据之前,取出记录时,获取当前数据库中的version=1,b线程要修改数据之前,取出记录时,获取当前数据库中的version=1
3.线程执行时,version值的变化
a线程执行时
set version = newVersion where version = oldVersion
newVersion = version+1 [2]
oldVersion = version [1] ,
b线程执行时,
set version = newVersion where version = oldVersion
newVersion = version+1 [2]
oldVersion = version [1]无论哪个线程先执行,就会将version值加一
4.a,b开始执行
假如a线程先执行更新,会把version改为2,
b线程再更新的时候,set version = 2 where version = 1,此时数据库表的数据version已经为2,所以b线程会修改失败
假如b线程先执行更新,会把version改为2,
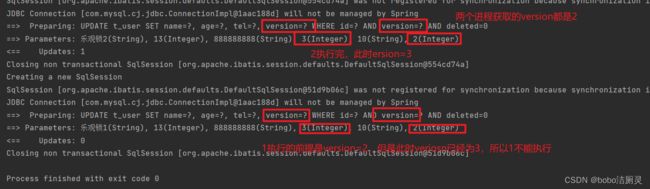
a线程再更新的时候,set version = 2 where version = 1,此时数据库表的数据version已经为2,所以a线程会修改失败不管谁先执行都会确保只能有一个线程更新数据,这就是MP提供的乐观锁的实现原理分析。
实现步骤
1.数据库表中添加version字段,默认为1
2.模型类中添加对应的属性
@Version
private Integer version;3.添加乐观锁的拦截器
@Configuration
public class MPConfig {
@Bean
public MybatisPlusInterceptor mpInterceptor(){
//1.定义MP拦截器
MybatisPlusInterceptor mpInterceptor = new MybatisPlusInterceptor();
//2.添加乐观锁拦截器
mpInterceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return mpInterceptor;
}
}拦截器的目的是拿到version值,并且自动操作version+1。
4.执行更新操作
实现乐观锁的要点是version字段,所以首先要得到version字段,再通过拦截器对version自动操作
@Test
void testUpdate(){
//首先拿到要操作记录(10)的所有信息
User user = userDao.selectById(10L);
//更新此条记录
user.setName("乐观锁1");
userDao.updateById(user);
}
观察以上日志,发现拦截器对version进行操作了,
接下来模拟两个线程操作一个记录的场景
@Test
void testUpdate(){
//首先拿到要操作记录(10)的所有信息
User user = userDao.selectById(10L);
User user2 = userDao.selectById(10L);
//将更新的数据放入
user2.setName("乐观锁2");
userDao.updateById(user2);
user.setName("乐观锁1");
userDao.updateById(user);
}
乐观锁的官方文档:
十一.代码生成器
1.创建一个Spring的maven项目
