基于vivado(语言Verilog)的FPGA学习(4)——FPGA选择题总结(针对华为逻辑岗实习笔试)
基于vivado(语言Verilog)的FPGA学习(4)——FPGA选择题总结
文章目录
- 基于vivado(语言Verilog)的FPGA学习(4)——FPGA选择题总结
-
- 1. 消除险象
- 2. 建立时间和保持时间
- 3.ISE
- 4.DMA
- 5.仿真器
- 6.标识符
- 7.可综合电路的语句
- 8.缺省值
- 9.系统设计优化
- 10.带宽计算
1. 消除险象
办法一:修改逻辑表达式避免以上情况【需要逻辑分析能力】
办法二:采样时序逻辑,仅在时钟边沿采样【推荐,事实上也最常用】
办法三:在芯片外部并联电容消除窄脉冲【物理方法】
办法四:由于电容会降低速度,所以在高速电路中,可以利用选通的方式消除险象
2. 建立时间和保持时间
建立时间Tsu:触发器在时钟上升沿到来之前,其数据输入端的数据必须保持不变的时间。
保持时间Th:触发器在时钟上升沿到来之后,其数据输入端的数据必须保持不变的时间。

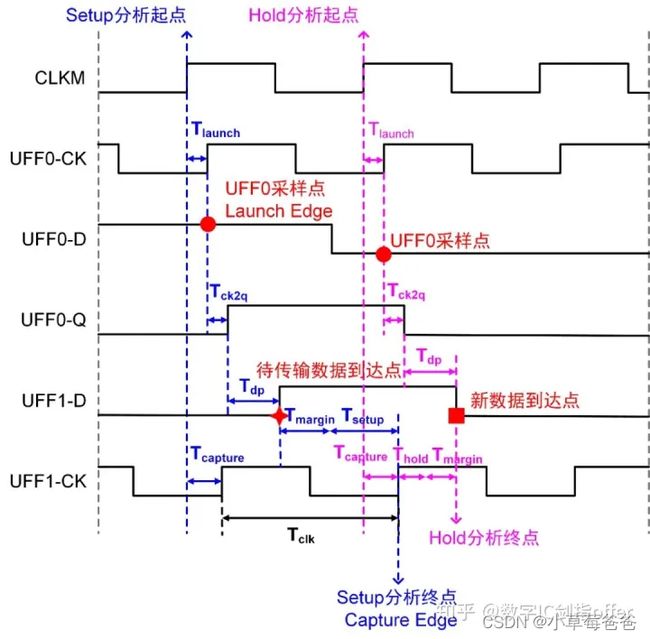
上图是第一张图的考虑延时的时序图,
CLK经过第一个触发器到第二个触发器的延时T_delay1=(第一个时钟延时时间Tlaunch+触发器内部延时Tck2q+第一个触发器到第二个触发器经过的组合逻辑电路的延时Tdp)
CLK直接到达第二个触发器的延时 T_delay2,图中的Tcapture
则时钟周期为T_CLK时,
建立时间=T_delay2+T_CLK-T_delay1
保持时间=T_delay1-T_delay2
在一个FPGA项目中,既有建立时间异常(setup violation),也有保持时间异常(hold violation),应该如何修改设计以使其正常工作?
- 对于建立时间异常:
办法一:T_CLK时钟周期:增加T_CLK,也就是降频:
这一点比较容易理解,就是增加“脉冲宽度”,增大T_CLK
办法二:T_dp组合逻辑延时(减小T_dp):优化组合逻辑延时,具体包括:
a. 增加一个中间触发器来切割Timing Path,分割组合逻辑延时(流水线结构)
b. 对于有较大负载的节点可以考虑插Buffer、逻辑复制的方法来优化扇出,减少关键路径上的负载(插Buffer,逻辑复制)
c. 小Cell换成大Cell,更换更大驱动的Cell,增强驱动能力
d. 更换SVT/LVT(速度快于HVT的电压阈值的单元库)的Cell
办法三:增大T_delay2,但是相应的会减小保持时间
办法四:缩短触发器内部延时Tck2q:
换成更快的时序逻辑单元,花钱!
- 对于保持时间异常:保持时间=T_delay1-T_delay2
办法一: 增加T_dp组合逻辑延时,(组合逻辑深度的增加会增加芯片的面积、布线资源、功耗,可能产生在慢速工艺库条件下建立时间违例)
办法二: 减小T_delay2,但是相应的会增大建立时间
可以看出,保持时间和建立时间有一些矛盾
3.ISE
ISE的全称为Integrated Software Environment,即“集成软件环境”,是Xilinx公司的硬件设计工具。一般用的都是vivado,看了一下ISE的仿真、综合和实现,感觉和vivado很相似。
4.DMA
DMA(Direct Memory Access,直接存储器访问)是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于 CPU 的大量中断负载。否则,CPU 需要从来源把每一片段的资料复制到暂存器,然后把它们再次写回到新的地方。在这个时间中,CPU对于其他的工作来说就无法使用。
(1) PS通过AXI-lite向AXI DMA发送指令,
(2) AXI DMA通过HP通路和DDR交换数据,
(3) PL通过AXI-S读写DMA的数据。
PS和PL数据交互网站
5.仿真器
根据执行仿真的不同方法,Verilog仿真器可以分为以下3种类型:
(1) 解释型的仿真器。
解释型仿真器读入Verilog代码,在计算机的内存中生成数据结构,然后解释性地运行仿真,每次运行仿真时,进行一次编译,编译通常很快就可以完成。Cadence公司的Verilog-XL仿真器就是一种解释型的仿真器。
(2) 编译型的仿真器。
编译型的仿真器读入Verilog代码,然后把它转换为相应的C代码(或其他编程语言的代码)。接下来,用标准C编译器将该C代码编译成二进制可执行代码。执行这个二进制代码,就可以执行仿真器。编译型的仿真器的编译时间通常比较长,但其执行速度一般来说比解释型的仿真器快。Synopsys公司的VCS仿真器就是一种编译型的仿真器。
(3) 本地编译型的仿真器。
本地编译型的仿真器读入Verilog代码,然后把它直接转换成能在指定的机器平台上运行的二进制代码,机器的平台不同,编译的优化和调整过程也不同。这就是说,能在Sun工作站上运行的本地编译仿真器,不能在HP工作站上运行,反之亦然。Cadence公司的Verilog-NC仿真器就是这种本地编译型的仿真器。
6.标识符
标识符( identifier)用于定义模块名、端口名、信号名等。
Verilog HDL 中的标识符( identifier)可以是任意一组字母、数字、 $符号和_(下划线)符号的组合,但标识符的第一个字符必须是字母或者下划线。另外,标识符是区分大小写的。
HDL知识点,WAIT语句有4种格式:WAIT,WAIT ON,WAIT UNTIL,WAIT FOR
![]()
7.可综合电路的语句
时间变量time和实数变量real不能被综合
并行块fork···join不可综合,并行块的语义在电路中不能被转化。
8.缺省值
寄存器未做赋值操作的话,其值是未知,在Verilog中用x表示;
线网类型可以理解为导线,其值是高阻,在Verilog中用z表示。
9.系统设计优化
分为资源优化(面积优化)和速度优化

10.带宽计算
参考的题目是:

理论带宽 = 内存核心频率 × 内存总线位数 × 倍增系数 / 位字转换 = (1066/8) * 32 * 8 / 8
应用端带宽=应用端时钟 × 数据位宽 / 位字转换 = 200 * 128 / 8 = 3200 MB/s
DDR/DDR2/DDR3的区别:
- DDR采用时钟脉冲上升、下降沿各传一次数据,1个时钟信号可以传输2倍于SDRAM的数据,所以又称为双倍速率SDRAM。它的倍增系数就是2。
- DDR2仍然采用时钟脉冲上升、下降支各传一次数据的技术(不是传2次),但是一次预读4bit数据,是DDR一次预读2bit的2倍,因此,它的倍增系数是2X2=4。
- DDR3作为DDR2的升级版,最重要的改变是一次预读8bit,是DDR2的2倍,DDR的4倍,所以,它的倍增系数是2X2X2=8。
内存的频率指标
-
核心频率:即为内存Cell阵列(Memory Cell Array)的工作频率,它是内存的真实运行频率; -
时钟频率:即I/O Buffer(输入/输出缓存)的传输频率; -
有效数据:传输频率则是指数据传送的频率。
DDR3-1066蕴含的信息
DDR3代表内存一次从存储单元取8bit数据。
1066指有效数据传输频率,除以8才是核心频率。
DDR在FPGA中如何运用?主要调用了MIG IP核

