go binary包
binary包使用与详解
最近在看一个第三方包的库源码,bigcache,发现其中用到了binary 里面的函数,所以准备研究一下。
可以看到binary 包位于encoding/binary,也就是表示这个包的作用是编辑码作用的,看到文档给出的解释是
用于数字和字节序的转换以及变长值的编解码。
Uvarint
从buf解码一个uint64,返回该数字和读取的字节长度,如果发生了错误,该数字为0而读取长度n返回值的意思是:
n == 0 buf 太小了,没读到
n < 0 值太大了,64 bit 装不下,-n 为可以读到的字节数
看以下这个函数,我们不论这个函数是干啥的,我们只用关注
blockSize, n := binary.Uvarint(q.array[index:])
return q.array[index+n : index+int(blockSize)], int(blockSize), nil
从array 中index 的位置之后解析一个unit64, blockSize 为这个值,n 表示读到的字节数
什么意思呢?
比方说我设置了一个package 的一个大小,500byte,我把这个500这个数字编码到byte buf中,这个时候我们通过binary.Uvarint 这个解码出来的有两个值,按照这个方法,blockSize 这个就是500,n 表示编码这个500 占的字节数
那么通过这个peek 方法,实际上我们返回的值就是,从array这个byte buf中取从index+这个编码 之后到packeage的大小字符。说白了就是packege的数据。
// peek returns the data from index and the number of bytes to encode the length of the data in uvarint format
func (q *BytesQueue) peek(index int) ([]byte, int, error) {
err := q.peekCheckErr(index)
if err != nil {
return nil, 0, err
}
blockSize, n := binary.Uvarint(q.array[index:])
return q.array[index+n : index+int(blockSize)], int(blockSize), nil
}
PutUvarint
同样的,我们看下面的函数,我们不用考虑这个函数具体作用,只用分析
headerEntrySize := binary.PutUvarint(q.headerBuffer, uint64(len))
PutUvarint 编码,将什么编码呢,将这个uint64的长度这个数字进行编码,最终放在了q.headerBuffer这个[]byte中,返回的headerEntrySize 这值是什么呢,这个值就是编码用了多少字节。
func (q *BytesQueue) push(data []byte, len int) {
headerEntrySize := binary.PutUvarint(q.headerBuffer, uint64(len))
q.copy(q.headerBuffer, headerEntrySize)
q.copy(data, len-headerEntrySize)
if q.tail > q.head {
q.rightMargin = q.tail
}
if q.tail == q.head {
q.full = true
}
q.count++
}
PutUint64
同样的,我们不去管这个函数做了什么(实际上也很好理解),我们具体看
binary.LittleEndian.PutUint64(blob, timestamp)
binary.LittleEndian.PutUint64(blob[timestampSizeInBytes:], hash)
binary.LittleEndian.PutUint16(blob[timestampSizeInBytes+hashSizeInBytes:], uint16(keyLength))
事实上这个就是把timestamp hash keyLength的长度,这三个数字,给他放到blob 这个[]byte中,很明显这三个占了18字节
func wrapEntry(timestamp uint64, hash uint64, key string, entry []byte, buffer *[]byte) []byte {
keyLength := len(key)
blobLength := len(entry) + headersSizeInBytes + keyLength
if blobLength > len(*buffer) {
*buffer = make([]byte, blobLength)
}
blob := *buffer
binary.LittleEndian.PutUint64(blob, timestamp)
binary.LittleEndian.PutUint64(blob[timestampSizeInBytes:], hash)
binary.LittleEndian.PutUint16(blob[timestampSizeInBytes+hashSizeInBytes:], uint16(keyLength))
copy(blob[headersSizeInBytes:], key)
copy(blob[headersSizeInBytes+keyLength:], entry)
return blob[:blobLength]
}
Uint64
同样的,我们选择其中一个readEntry 的函数看看,是如何解码的,很简单
length := binary.LittleEndian.Uint16(data[timestampSizeInBytes+hashSizeInBytes:])
length就是我们前面设置的key 的长度
func readEntry(data []byte) []byte {
length := binary.LittleEndian.Uint16(data[timestampSizeInBytes+hashSizeInBytes:])
// copy on read
dst := make([]byte, len(data)-int(headersSizeInBytes+length))
copy(dst, data[headersSizeInBytes+length:])
return dst
}
封装一个[]byte
考虑一下,我们的网络通信过程中,假设我们需要进行封包的操作。

假设我么利用上述的方法,对自己的协议进行自定义。
我们看看应用如何实现
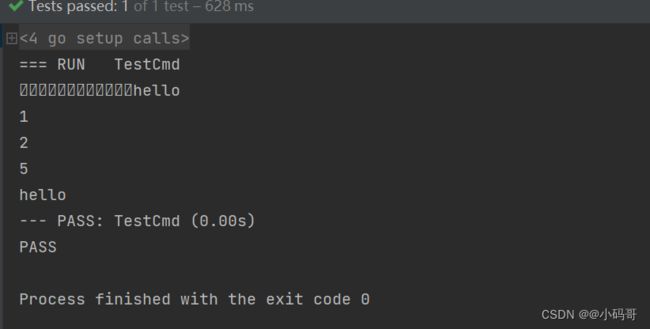
func TestCmd(t *testing.T) {
b := "hello"
bb := []byte(b)
encodeB := encode(ICmd{id: 1,cmd: 2,pLen: 5,message: bb})
fmt.Println(string(encodeB))
icmd := decode(encodeB)
fmt.Println(icmd.id)
fmt.Println(icmd.cmd)
fmt.Println(icmd.pLen)
fmt.Println(string(icmd.message))
}
type ICmd struct {
id uint32
cmd uint32
pLen uint32
message []byte
}
//然后我们在进行encode 和 decode 操作
const (
idFixSize = 4
cmdFixSize = 4
pLenFixSize = 4
SumIdCmdPLenSize = idFixSize+cmdFixSize+pLenFixSize
)
func encode(icmd ICmd) []byte {
newBuf := make([]byte,len(icmd.message)+SumIdCmdPLenSize)
binary.LittleEndian.PutUint32(newBuf,icmd.id)
binary.LittleEndian.PutUint32(newBuf[cmdFixSize:],icmd.cmd)
binary.LittleEndian.PutUint32(newBuf[idFixSize+cmdFixSize:],icmd.pLen)
copy(newBuf[SumIdCmdPLenSize:],icmd.message)
return newBuf
}
func decode(data []byte) ICmd{
icmd := ICmd{}
icmd.id = binary.LittleEndian.Uint32(data[:idFixSize])
icmd.cmd = binary.LittleEndian.Uint32(data[idFixSize:idFixSize+cmdFixSize])
icmd.pLen = binary.LittleEndian.Uint32(data[idFixSize+cmdFixSize:SumIdCmdPLenSize])
icmd.message = data[SumIdCmdPLenSize:]
return icmd
}