Postgresql内部缓存与OS缓存的关系
postgresql内部缓存与OS缓存
1 pgsql数据与日志刷盘
mysql通常使用odirect使数据绕过OS缓冲区落盘,wal还是使用系统缓冲。这样数据的写盘不会造成系统刷脏抖动。在pgsql中数据是与OS缓冲绑定的,自己没有做字节对齐,也不使用odirect的方式直写设备,社区对数据直写的态度也一直很悲观,原因是之前也做过很多探索,结果都不是很好:
link
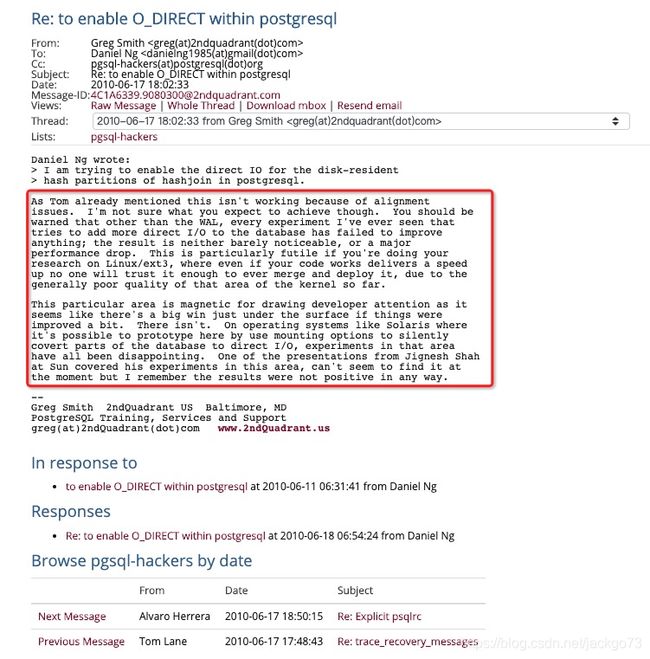
在pgsql中数据到磁盘上会经历两层缓存:
对比下mysql来看,数据绕过VFS缓存,日志使用VFS缓存

2 pgsql查看内部缓存和OS缓存
使用缓存的原因肯定是因为磁盘慢,参考下面数据有个直观的感受
http://blog.codinghorror.com/the-infinite-space-between-words/
| access | computer time | arbitrary seconds |
|---|---|---|
| 1 CPU cycle | 0.3 ns | 1 s |
| Level 1 cache access | 0.9 ns | 3 s |
| Level 2 cache access | 2.8 ns | 9 s |
| Level 3 cache access | 12.9 ns | 43 s |
| Main memory access | 120 ns | 6 min |
| Solid-state disk I/O | 50-150 μs | 2-6 days |
| Rotational disk I/O | 1-10 ms | 1-12 months |
| Internet: SF to NYC | 40 ms | 4 years |
| Internet: SF to UK | 81 ms | 8 years |
| Internet: SF to Australia | 183 ms | 19 years |
| OS virtualization reboot | 4 s | 423 years |
| SCSI command time-out | 30 s | 3000 years |
| Hardware virtualization reboot | 40 s | 4000 years |
| Physical system reboot | 5 m | 32 millenia |
下面我们来看看如何在pgsql中查看缓存情况:
2.1 安装pg_buffercache/pgfincore
(请事先配好PG的环境变量)
cd /home/mingjie.gmj/projects/postgresql-10.7/contrib
git clone git://git.postgresql.org/git/pgfincore.git
cd pgfincore
make
make install
cd /home/mingjie.gmj/projects/postgresql-10.7/contrib/pg_buffercache
make
make install
psql
postgres=# CREATE EXTENSION pg_buffercache;
CREATE EXTENSION
postgres=# CREATE EXTENSION pgfincore;
CREATE EXTENSION
CREATE EXTENSION pg_buffercache;
CREATE EXTENSION pgfincore;
2.2 OLTP测试中内存使用情况
测试SQL
\set aid random(1, 100000 * :scale)
\set bid random(1, 1 * :scale)
\set tid random(1, 10 * :scale)
\set delta random(-5000, 5000)
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
测试命令
pgbench -M prepared -r -c8 -j8 -T 60 -P1 benchdb
重启数据库后确认缓冲区清空
select c.relname,pg_size_pretty(count(*) * 8192) as pg_buffered,
round(100.0 * count(*) /
(select setting
from pg_settings
where name='shared_buffers')::integer,1)
as pgbuffer_percent,
round(100.0*count(*)*8192 / pg_table_size(c.oid),1) as percent_of_relation,
( select round( sum(pages_mem) * 4 /1024,0 )
from pgfincore(c.relname::text) )
as os_cache_MB ,
round(100 * (
select sum(pages_mem)*4096
from pgfincore(c.relname::text) )/ pg_table_size(c.oid),1)
as os_cache_percent_of_relation,
pg_size_pretty(pg_table_size(c.oid)) as rel_size
from pg_class c
inner join pg_buffercache b on b.relfilenode=c.relfilenode
inner join pg_database d on (b.reldatabase=d.oid and d.datname=current_database()
and c.relnamespace=(select oid from pg_namespace where nspname='public'))
group by c.oid,c.relname
order by 3 desc limit 30;
压测完成后,缓冲区情况
relname | pg_buffered | pgbuffer_percent | percent_of_relation | os_cache_mb | os_cache_percent_of_relation | rel_size
-----------------------+-------------+------------------+---------------------+-------------+------------------------------+----------
pgbench_accounts_pkey | 64 MB | 49.8 | 29.7 | 214 | 100.0 | 214 MB
pgbench_accounts | 62 MB | 48.7 | 4.8 | 1296 | 100.0 | 1296 MB
pgbench_history | 1192 kB | 0.9 | 21.9 | 5 | 99.6 | 5448 kB
pgbench_branches | 80 kB | 0.1 | 20.4 | 0 | 91.8 | 392 kB
pgbench_tellers | 112 kB | 0.1 | 40.0 | 0 | 88.6 | 280 kB
pgbench_tellers_pkey | 48 kB | 0.0 | 85.7 | 0 | 100.0 | 56 kB
pgbench_branches_pkey | 8192 bytes | 0.0 | 50.0 | 0 | 100.0 | 16 kB
在执行全表查询,PG缓冲区把表的所有数据加载到sharedbuffer
-[ RECORD 1 ]----------------+-----------------
relname | pgbench_accounts
pg_buffered | 127 MB
pgbuffer_percent | 99.3
percent_of_relation | 9.8
os_cache_mb | 1296
os_cache_percent_of_relation | 100.0
rel_size | 1296 MB
2.3 查看OS缓存
如果只关注系统OS缓存,重启数据库查询,OS缓存不变
select c.relname, (select round( sum(pages_mem) * 4 /1024,0 ) from pgfincore(c.relname::text)) as os_cache_MB from pg_class c where relname like 'pgbench%';
relname | os_cache_mb
-----------------------+-------------
pgbench_accounts | 1296
pgbench_accounts_pkey | 214
pgbench_branches | 0
pgbench_branches_pkey | 0
pgbench_history | 5
pgbench_tellers | 0
pgbench_tellers_pkey | 0
刷buffer清空page cache
sync; echo 1 > /proc/sys/vm/drop_caches
重新查看OS缓存
select c.relname, (select round( sum(pages_mem) * 4 /1024,0 ) from pgfincore(c.relname::text)) as os_cache_MB from pg_class c where relname like 'pgbench%';
relname | os_cache_mb
-----------------------+-------------
pgbench_accounts | 0
pgbench_accounts_pkey | 0
pgbench_branches | 0
pgbench_branches_pkey | 0
pgbench_history | 0
pgbench_tellers | 0
pgbench_tellers_pkey | 0
执行count重新加载数据到OS缓存
select count(*) from pgbench_accounts;
select c.relname, (select round( sum(pages_mem) * 4 /1024,0 ) from pgfincore(c.relname::text)) as os_cache_MB from pg_class c where relname like 'pgbench%';
relname | os_cache_mb
-----------------------+-------------
pgbench_accounts | 324
pgbench_accounts_pkey | 58
relname | os_cache_mb
-----------------------+-------------
pgbench_accounts | 687
pgbench_accounts_pkey | 120
relname | os_cache_mb
-----------------------+-------------
pgbench_accounts | 1295
pgbench_accounts_pkey | 214
3 pgsql缓存策略
从上面结果可以看到,数据和索引都会装载进入sharedbuffer和os page cache,pgsql在查询数据时首先在sharedbuffers中搜索,如果找到就不再向系统请求。
PG使用时钟扫描算法实现缓冲区的换入换出,先看下传统算法LRU:
LRU

-
第四步页面需要访问页面7,然后就会去遍历该链表,发现找到了7号页面,而且此时页面没有全部用满,那么将页面7提到表头(通过更改双向链表的指针指向实现),
-
页面1被读到缓冲区
-
读取页面0,遍历链表找到了页面0并将页面0提到表头,其他步骤类似
-
置换:比如最后一步,读取页面6,遍历链表后发现页面6没有找到,此时缓冲区已满,这时需要从缓冲区中置换掉链表最尾部(最近最少使用)的页面4进行淘汰,并且把页面6放在表头。
CLOCK
Clock算法为每页设置一位访问标识usage_tag,内存中的所有页面以链表的形式组成一个环形队列。当某页被访问时,其访问标识u就被置1。
Clock在需要进行页面淘汰时会循环地扫描环形队列的页面,如果发现页面访问位u=0,就选择该页换出;若u=1,则重新将它置0,这样该页面本次就不会被换出,有了第二次驻留内存的机会,再继续检查下一个页面。当检查到队列中的最后一个页面时,若其访问位仍为1,则再返回到队首去检查第一个页面,本轮检查就一定有u=0的页面了,然后会将第一个u=0的页面换出。
Clock算法实现起来更简单,性能也接近LRU,在clock的基础上又有改进的clock算法。
改进的clock算法
改进的clock算法是在clock算法的基础上再增加一个一个修改位modify_tag,标识该页面是否被修改。为什么增加修改位m呢,因为被修改的页面(也称为脏页)如果被替换出去必须要先强制刷盘,所以我们的原则是尽量优先替换未被修改过的页面。所以改进的clock算法页面替换原则顺序如下:
①先替换最近未被访问,也未被修改的页(u=0, m=0)。
②再替换最近被访问,但未被修改的页(u=1, m=0)。
③再替换最近未被访问,但被修改的页(u=0, m=1)。
④最后替换最近被访问,被修改的页(u=1, m=1)。
PostgreSQL中的clock算法
PG作为学术派数据库在改进的时钟扫描算法上又做了进一步创新,将usage_tag从一个布尔值的标识位改为usage_count的数值位,u代表了该页面被使用的次数,而不再是是否被使用。通过下面这个图看看PG的时钟扫描算法过程。当然pg缓冲区的三层结构不再介绍了,毕竟不是研发人员,了解下原理就行。

- 受害者指针指向第一个描述符(buffer_id=1),发现它的状态是pinned(被钉住m=1,可以理解为modify_tag=1),故跳过该描述符。
- 受害者指针指向第二个描述符(buffer_id=2),发现此描述符的状态是unpinned(未被钉住m=0)但其usage_count为2,此时将usage_count减1,受害者指针继续前进。
- 受害者指针指向第三个描述符(buffer_id=3),状态描述符为unpinned(m=0),而且usage_count=0,所以该描述符被选为本轮的受害者进行替换。
从上面的过程可以看出,每当循环扫描缓冲区时,如果存在未被修改的页面,该页面的usage_count就会减少1。所以,如果缓冲池中存在未被修改的页面时,此算法始终可以通过若干次扫描找到usage_count=0的页面。
PG中的时钟扫描算法相比两标识位的时钟扫描更加精细,相当于为每个最近被使用的页面增加了权重,使用越频繁越不容易被替换出去,更加符合真实的场景。
4 PAGECACHE缓存策略
硬盘的扇区大小为512bytes,而文件系统比如说ext4默认是以4k对齐,也就是说文件系统的一个inode对应了disk的8个sectors,与此同时linux大部分的虚拟内存页和物理内存帧也都是4k大小。
Page cache缓存文件的页以优化文件IO。Buffer cache缓存块设备的块以优化块设备IO。
在linux kernel 2.4之前,这两个cache是不同的:file在page cache中,disk block在buffer cache中。考虑到大多数的文件是由disk上的文件系统表示的,数据会在系统中有两份缓存,一份在page cache中,一份在buffer cache中。许多类unix系统都是这种模式。
这种实现是很简单,但是明显的低效和冗余。在linux kernel 2.4之后,这两种caches统一了。虚拟内存子系统通过page cache驱动IO。如果数据同时在page cache和buffer cache中,buffer cache会简单的指向page cache,数据只会在内存中保有一份。Page cache就是你所知道的disk在内存中的缓存:它会加快文件访问速度。
无论如何内核要对块设备执行基于块的IO而不是虚拟内存page。由于绝大部分的块表示文件的数据部,所以大部分的buffer cache都可由page cache表达,但是有少量的比如文件元数据仍然是保留在buffer cache中来缓存。
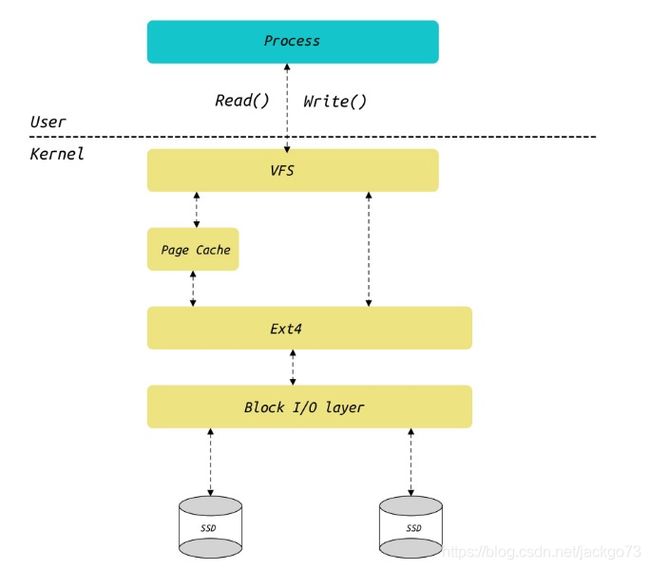
文件系统架构
文件系统架构抽象
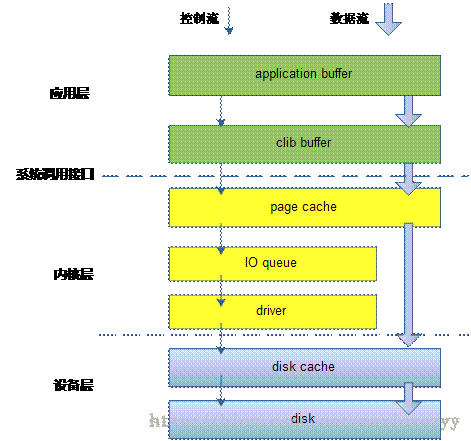
-
在PgSQL中,读写数据文件不使用
O_DIRECT,数据文件落盘依赖OS的缓冲区,与自身SHAREDBUFFER形成两层缓冲的架构。 -
在MySQL的设计实现中,读写数据文件使用了
O_DIRECT标志,其目的是使用自身Buffer Pool的缓存算法。
Page Cache是内核与存储介质的重要缓存结构,当我们使用write()或者read()读写文件时,假如不使用O_DIRECT标志位打开文件,我们均需要经过Page Cache来帮助我们提高文件读写速度。
参考一些PAGECACHE分析
4.1 Page Cache的插入
- 判断查找的
Page是否存在于Page Cache,存在即直接返回 - 分配一个空闲的Page.
- 将
Page插入Page Cache,即插入address_space的i_pages. - 调用
address_space的readpage()来读取指定offset的Page.
4.2 Page Cache的回写
假如Page Cache中的Page经过了修改,它的flags会被置为PG_dirty. 类似于MySQL的缓存结构Buffer Pool,修改过的脏页都需要落盘。在Linux内核中,假如没有打开O_DIRECT标志,写操作实际上会被延迟,以下几种策略可以将脏页刷盘:
- 手动调用
fsync()或者sync强制落盘 - 脏页占用比率过高,超过了设定的阈值,导致内存空间不足,触发刷盘(强制回写).
- 脏页驻留时间过长,触发刷盘(周期回写).
在这里我们仅仅分析周期回写和强制回写
- 周期回写
- 周期回写的时间单位是0.01s,默认为5s,可以通过
/proc/sys/vm/dirty_writeback_centisecs调节: Page驻留为dirty状态的时间单位也为0.01s,默认为30s,可以通过/proc/sys/vm/dirty_expire_centisecs来调节:
- 周期回写的时间单位是0.01s,默认为5s,可以通过
- 强制回写
- 后台线程强制回写:检查脏页的数量是否超过了设定的阈值
- 用户进程触发回写:假如用户调用
write()或者其他写文件接口时,在写文件的过程中,产生了脏页后会调用balance_dirty_pages调节平衡脏页的状态. 假如脏页的数量超过了**(后台回写设定的阈值+ 进程主动回写设定的阈值) / 2** ,即(background_thresh + dirty_thresh) / 2会强制进行脏页回写. 用户线程进行的强制回写仍然是触发后台线程进行回写
4.3 总结
触发Page Cache的几个条件如下:
- 周期回写,可以通过设置
/proc/sys/vm/dirty_writeback_centisecs调节周期. - 当后台回写阈值是脏页占可用内存大小的比例或者脏页的字节数超过了设定的阈值会触发后台线程回写.
- 当用户进程写文件时会进行脏页检查假如超过了阈值会触发回写,从而调用后台线程完成回写.
Page的写回操作是文件系统的封装,即address_space的writepage操作.
参考源
https://blog.csdn.net/maxlovezyy/article/details/70332720
https://blog.csdn.net/maxlovezyy/article/details/70344857
https://blog.csdn.net/maxlovezyy/article/details/70231804
http://www.leviathan.vip/2019/06/01/Linux%E5%86%85%E6%A0%B8%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90-Page-Cache%E5%8E%9F%E7%90%86%E5%88%86%E6%9E%90
https://jin-yang.github.io/post/linux-monitor-memory.html
http://fibrevillage.com/database/128-postgresql-database-buffer-cache-and-os-cache